FHIR 분석
컬렉션을 사용해 정리하기
내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요.
데이터 기반 의료는 신뢰할 수 있고 실행 가능한 통계를 빠르게 생성할 수 있는 능력에 의존합니다.
FHIR 표준은 차세대 디지털 헬스 솔루션을 빌드하는 개발자에게 많은 이점을 제공하지만, 중첩된 구조가 많아 분석에 사용하기 어려울 수 있습니다.
개발자가 FHIR 데이터 작업의 복잡성을 줄이는 솔루션을 더 쉽게 빌드할 수 있도록 Google에서는 리소스를 Parquet-on-FHIR 스키마로 변환하는 ETL 파이프라인, 뷰 정의 레이어, 쿼리 엔진 커넥터 등 도구 모음인 FHIR Data Pipes를 제공합니다.
FHIR Data Pipes는 수평 확장성과 유연한 배포 옵션 (온프레미스 또는 클라우드)을 위해 설계되었습니다. 동시에 단일 머신에 배포할 수도 있습니다.
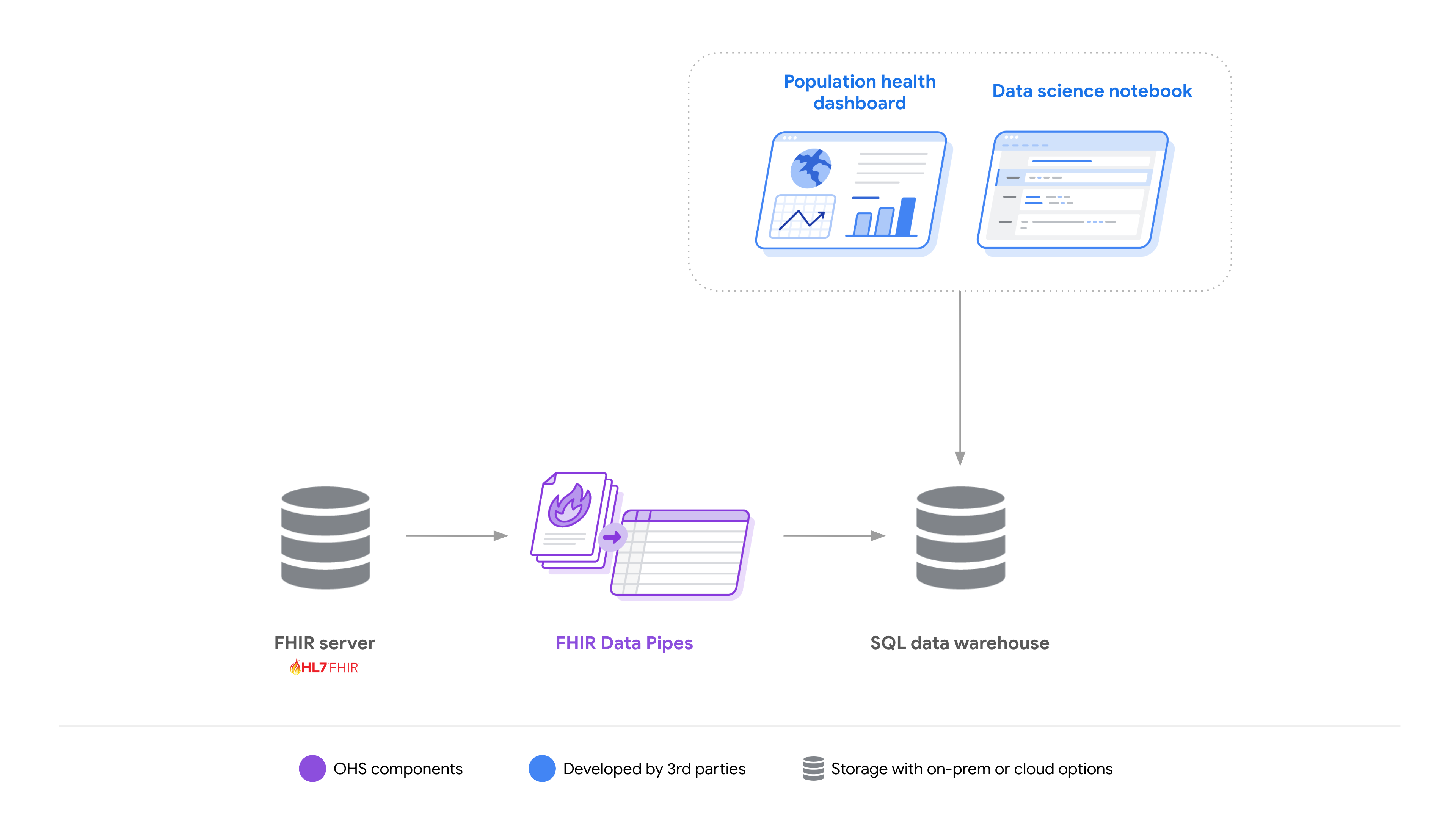
이를 통해 개발자는 다양한 사용 사례에 맞게 다양한 기술을 사용하여 분석 솔루션을 더 쉽게 빌드하고 배포할 수 있습니다.
FHIR 데이터 파이프 및 구성요소에 대해 자세히 알아보세요.
달리 명시되지 않는 한 이 페이지의 콘텐츠에는 Creative Commons Attribution 4.0 라이선스에 따라 라이선스가 부여되며, 코드 샘플에는 Apache 2.0 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 Google Developers 사이트 정책을 참조하세요. 자바는 Oracle 및/또는 Oracle 계열사의 등록 상표입니다.
최종 업데이트: 2025-07-25(UTC)
[null,null,["최종 업데이트: 2025-07-25(UTC)"],[],["FHIR Data Pipes addresses the complexity of analyzing FHIR data by providing tools for developers. It includes ETL pipelines that convert FHIR resources to Parquet-on-FHIR schema, a view definition layer, and query engine connectors. Designed for scalability and flexible deployment, it can run on-premises, in the cloud, or on a single machine. These tools facilitate the development and deployment of analytics solutions across diverse use cases by simplifying FHIR data handling.\n"]]