批量处理可汇总报告时,请务必优化批处理策略,以免超出隐私权限制。以下是向汇总服务发送批量报告的一些推荐策略。
收集报告
收集要包含在批处理中的报告时,请注意以下事项:
报告上传重试次数
注意:重试条件可能会发生变化。在这种情况下,本部分中的信息将会更新。
在网站和操作系统平台上,平台都会尝试发送三次报告,但如果第三次尝试后仍未发送报告,则也不会发送报告。无论何时能够发送报告,系统都会保留原始的 scheduled_report_time 值。重试时间表因平台而异:
- 网络浏览器会在浏览器处于联机状态时发送报告。如果报告发送失败,系统会等待 5 分钟进行第二次重试,然后等待 15 分钟进行第三次重试。如果浏览器离线,将在浏览器恢复在线状态一分钟后重试。在网络上发送报告没有延迟上限;这意味着,如果浏览器离线,无论报告生成多久,只要浏览器重新上线,就会尝试根据重试政策发送报告。
- Android 手机具有稳定的网络连接。因此,它将每小时运行一次作业来发送报告。这意味着,如果报告发送失败,系统会在下一个小时重试,然后在下一个小时再次重试。如果设备未连接到网络,则会在设备重新连接到网络后,通过下一个运行的报告作业重试发送报告。最长延迟为 28 天,这意味着设备不会发送在 28 天之前生成的报告。
等待报告
建议您在收集报告以进行批处理时,等待迟到的报告。您可以通过将 scheduled_report_time 值与收到报告的时间进行对比,确定报告是否延迟。这些报告之间的时间差异有助于确定您可能需要等待多长时间才能收到迟到的报告。例如,在收集延迟报告时,请查看 scheduled_report_time 字段,并记录在收到 90%、95% 和 99% 的报告时所经历的时延(以小时为单位)。这些数据可用于确定等待迟到的报告需要多长时间。
即时汇总报告可用于降低报告延迟的几率。
以下图表显示了延迟生成的报告会根据安排的报告时间存储在相应的批次中。批处理 T 表示 scheduled_report_time,T+X 表示等待延迟报告的时间。这会生成一个摘要报告,其中包含批处理中包含的大多数报告,这些报告对应的是其定期生成报告的时间。
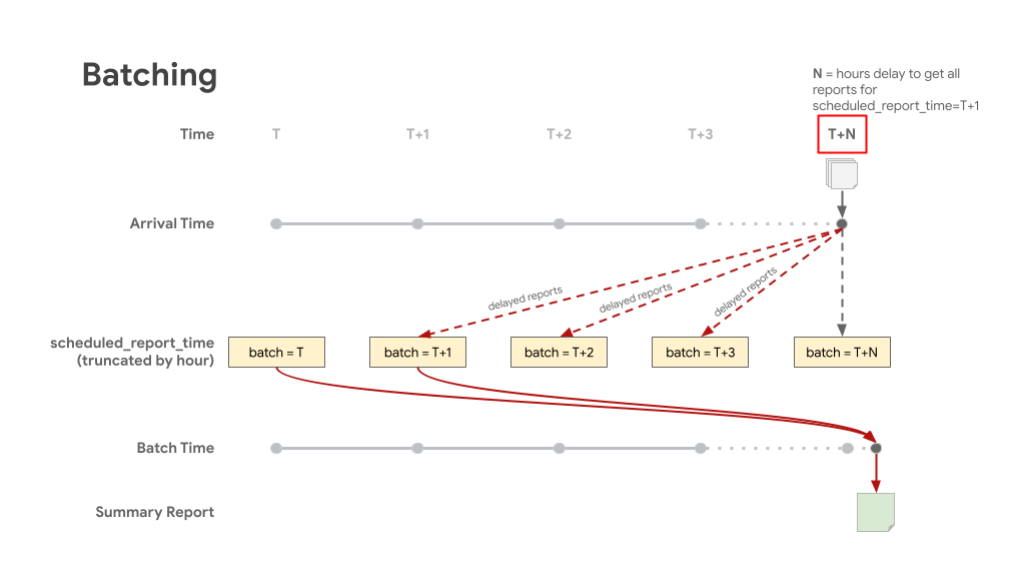
可汇总报告的会计核算
汇总服务会维护“无重复”规则。此规则强制规定,具有相同共享 ID 的所有可汇总报告都必须包含在同一批次中。
收集到报告后,应将它们进行批量处理,以确保具有相同共享 ID 的所有报告都属于一个批次。
如果某个报告已在另一个批处理中处理过,则再次处理该报告可能会导致隐私预算耗尽错误。正确地批量处理报告有助于防止因“无重复”规则而导致批量遭拒。
共享 ID 是系统为每份报告生成的键,用于跟踪可汇总的报告会计。共享 ID 可确保具有相同共享 ID 的报告仅会纳入到一个摘要报告中。这意味着,映射到一个共享 ID 的报告必须全部包含在一个批次中。例如,如果报告 X 和报告 Y 具有相同的共享 ID,则它们必须归入同一批次,以免报告因重复而被删除。
下图展示了要一起进行哈希处理以生成共享 ID 的 shared_info 组件。
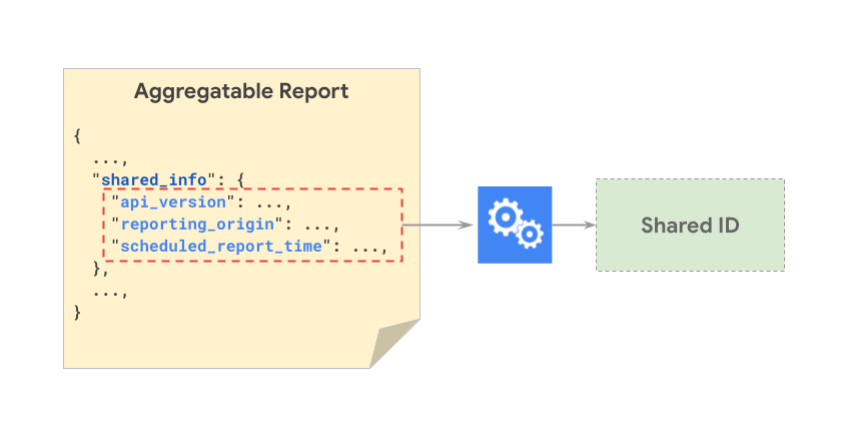
下图演示了两种不同的报告如何具有相同的共享 ID:

注意:scheduled_report_time 按小时截断,source_registration_time 按天截断。此外,在创建共享 ID 时不会使用 report_id。时间精确度未来可能会更新。
批量报告中存在重复报告
可汇总报告的 shared_info 字段中的 report_id 字段包含一个 UUID,用于识别批处理中的重复报告。如果一个批次中有多个报告具有相同的 report_id,则只有第一个报告将被汇总,其他报告将被视为重复并被静默删除;聚合将照常进行,并且不会发送任何错误。虽然这不是必需的,但广告技术平台可以先滤除具有相同报告 ID 的重复报告,然后再进行汇总,这样有望提升效果。
report_id 对每个报告都是唯一的。
批次之间存在重复报告
每个报告都分配有一个共享 ID,该 ID 是根据来自报告 shared_info 字段的组合数据点生成的 ID。多个报告可以具有相同的共享 ID,并且每个批次可以包含多个共享 ID。具有相同共享 ID 的所有报告必须归入同一批次。如果具有相同共享 ID 的报告最终分为多个批次,系统只会接受第一个批次,并将其他批次视为重复内容而拒绝。为避免这种情况,必须正确创建批次。
下图显示了一个示例,不同批次中具有相同共享 ID 的报告可能会导致后续批次失败。在图中,您可以看到,具有相同共享 ID e679aa 的两个或更多个报告被分批到不同的批次 #1 和 #2。由于共享 ID 为 e679aa 的所有报告的预算都在生成批次 1 的摘要报告期间使用,因此不允许批次 2,并且批次 2 将失败并显示错误。
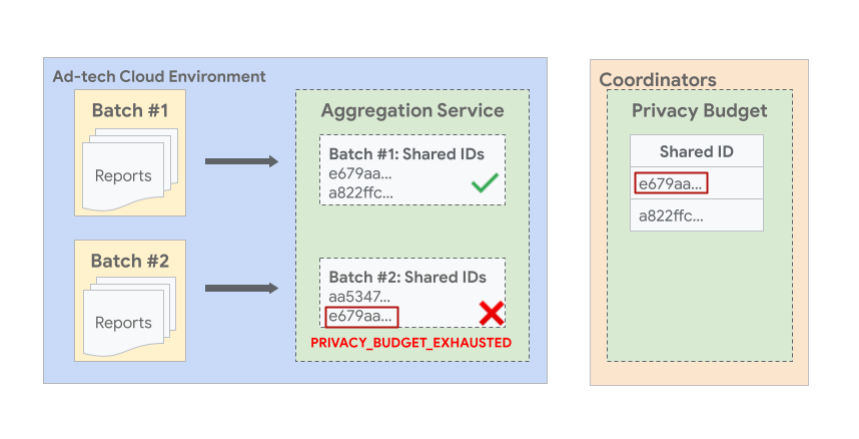
批量报告
建议采用以下方法来批量处理报告,以避免重复并优化汇总报告会计。
按广告客户批量处理
注意:此策略仅适用于归因报告汇总。
不公开汇总不含 attribution_destination 字段(即广告客户)。建议按广告客户批量处理,也就是说,将属于单个广告客户的报告包含在同一批次中,以免达到每个批次可汇总报告的账号限制。“广告客户”是在生成共享 ID 时考虑的一个字段,因此包含同一广告客户的报表也可以具有相同的共享 ID,这就需要它们属于同一批次,以免出错。
按时间分批
建议在批量处理时考虑报告的定期生成时间 (shared_info.scheduled_report_time)。在生成共享 ID 时,系统会将安排的报告时间截断为小时,因此报告至少应按小时批量处理,也就是说,所有安排的报告时间在同一小时内的报告都应归入同一批次,以避免多个批次中包含具有相同共享 ID 的报告,这会导致作业出错。
批处理频率和噪声
建议考虑噪声对可汇总报告的处理频率的影响。如果对可汇总报告进行更频繁的批处理(例如,纳入报告的事件数会少一个小时一次),那么报告会得到处理一次,因此噪声相对影响会更大。如果降低频率,且每周处理一次报告,则噪声的相对影响会较小。如需更好地了解噪声对批处理的影响,请使用噪声实验室进行实验。