No momento, com o serviço de agregação, é possível processar algumas medições em cadências diferentes usando IDs de filtragem. Agora, os IDs de filtragem podem ser transmitidos na criação de jobs no Serviço de agregação, desta forma:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Para usar essa implementação de filtragem, é recomendável começar com as APIs do cliente de medição (API Attribution Reporting ou API Private Aggregation) e transmitir seus IDs de filtragem. Elas serão transmitidas ao serviço de agregação implantado para que o relatório de resumo final seja retornado com os resultados filtrados esperados.
Se você estiver preocupado com o impacto disso no seu orçamento, saiba que o orçamento agregado da conta de relatórios será consumido apenas para filtrar IDs especificados no job_parameters para relatórios. Assim, você poderá executar novamente os jobs para os mesmos relatórios especificando IDs de filtragem diferentes sem encontrar erros de esgotamento do orçamento.
O fluxo a seguir mostra como você pode usar isso na API Private Aggregation, na API Shared Storage e no serviço de agregação na sua nuvem pública.
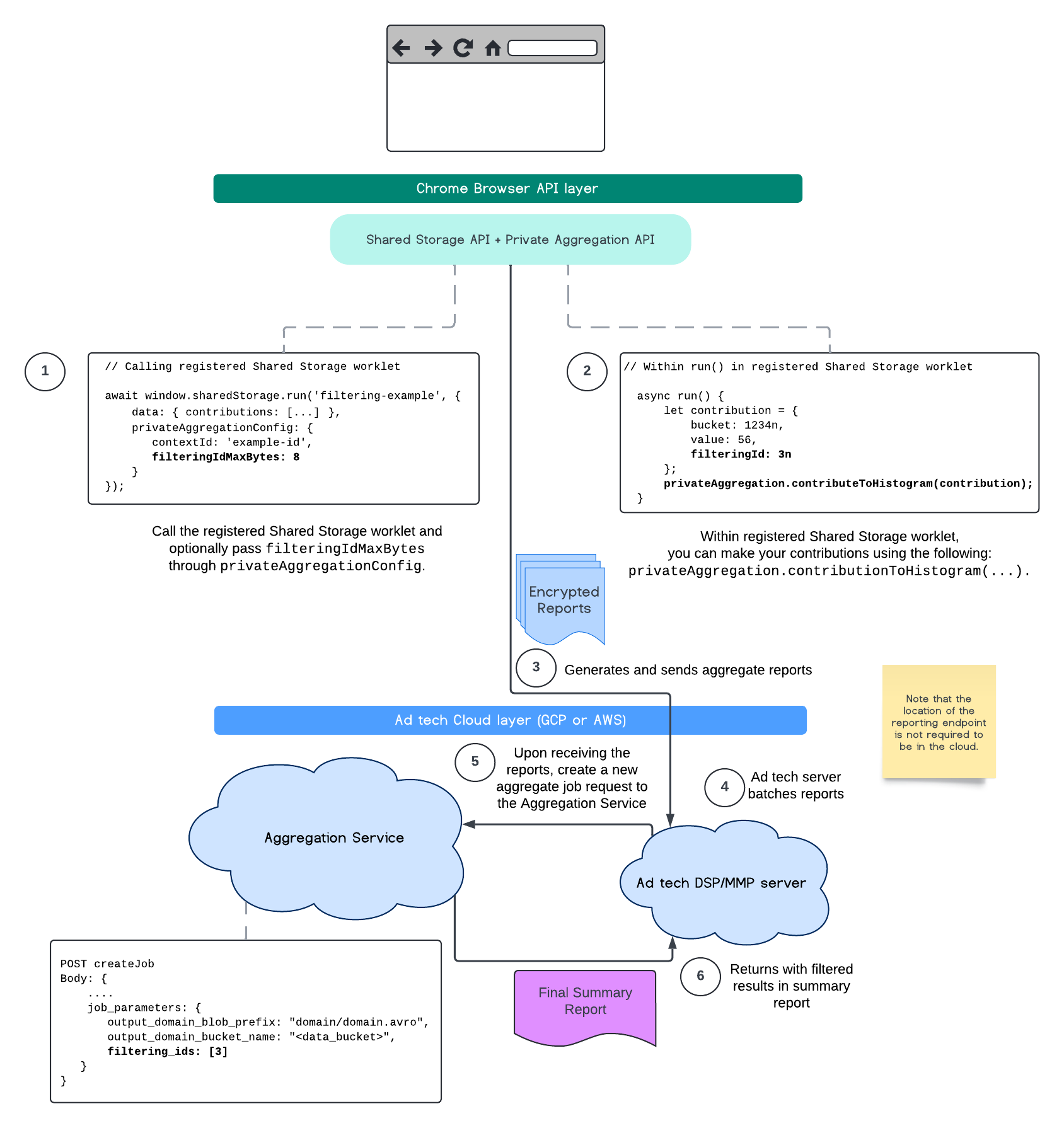
Este fluxo mostra como usar IDs de filtragem com a API Attribution Reporting e o serviço de agregação na sua nuvem pública.

Para mais informações, consulte a explicação da API Attribution Reporting e da API Private Aggregation, além da proposta inicial.
Continue para as seções API Attribution Reporting ou API Private Aggregation para ler uma conta mais detalhada. Leia mais sobre os endpoints createJob e getJob na documentação da API Aggregation Service.