目前,借助汇总服务,您现在可以利用过滤 ID 以不同的节奏处理某些衡量结果。现在,您可以在汇总服务中创建作业时传递过滤 ID,如下所示:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
如需使用此过滤实现,建议您从衡量客户端 API(Attribution Reporting API 或 Private Aggregation API)开始,并传入过滤 ID。这些数据将传递给您部署的汇总服务,以便最终摘要报告返回预期的过滤结果。
如果您担心这会对预算产生什么影响,请放心,汇总报告账号预算只会用于过滤在 job_parameters 中为报告指定的 ID。这样,您就可以为同一报告指定不同的过滤 ID 来重新运行作业,而不会遇到预算耗尽错误。
以下流程展示了如何在 Private Aggregation API、Shared Storage API 中使用此功能,以及如何通过公共云中的 Aggregation Service 使用此功能。
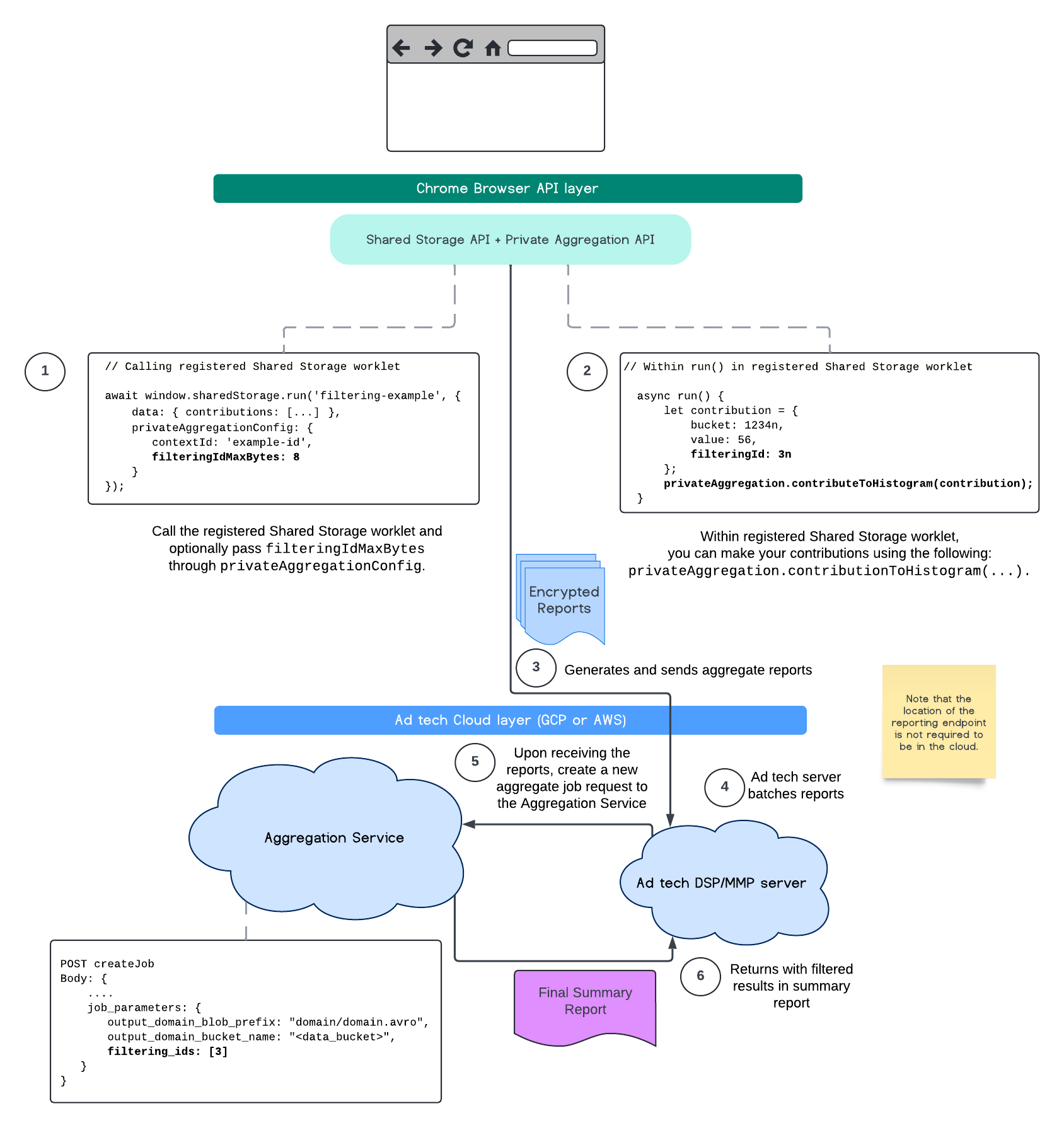
此流程展示了如何使用 Attribution Reporting API 过滤 ID,并将其传递到公共云中的汇总服务。
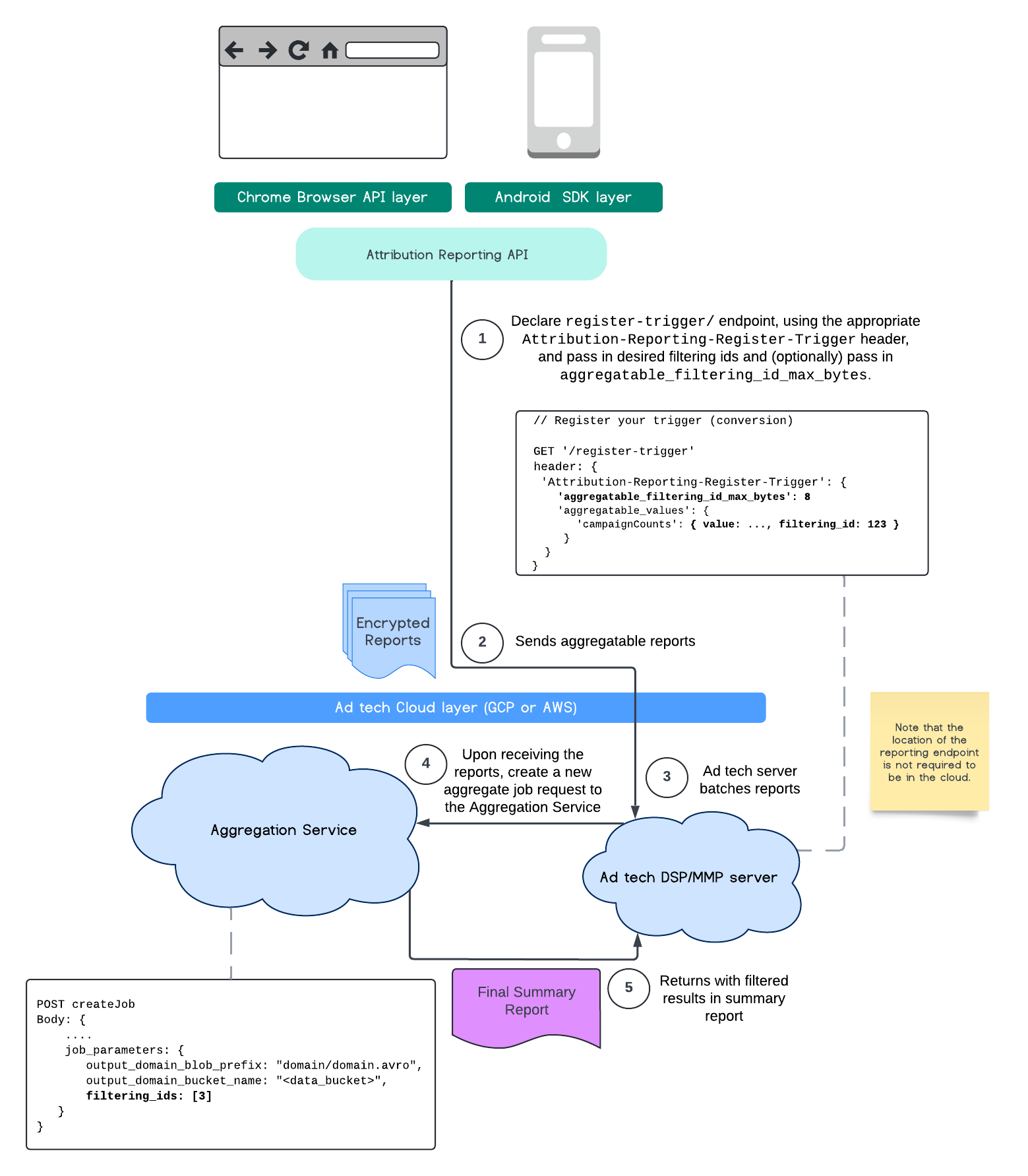
如需进一步了解,请参阅 Attribution Reporting API 说明文档和 Private Aggregation API 说明文档,以及初始提案。
如需了解详情,请继续阅读 Attribution Reporting API 或 Private Aggregation API 部分。如需详细了解 createJob 和 getJob 端点,请参阅 Aggregation Service API 文档。