After you successfully deploy the Aggregation Service, you can use the createJob and getJob endpoints to interact with the service. The following diagram provides a visual representation of the deployment architecture for these two endpoints:
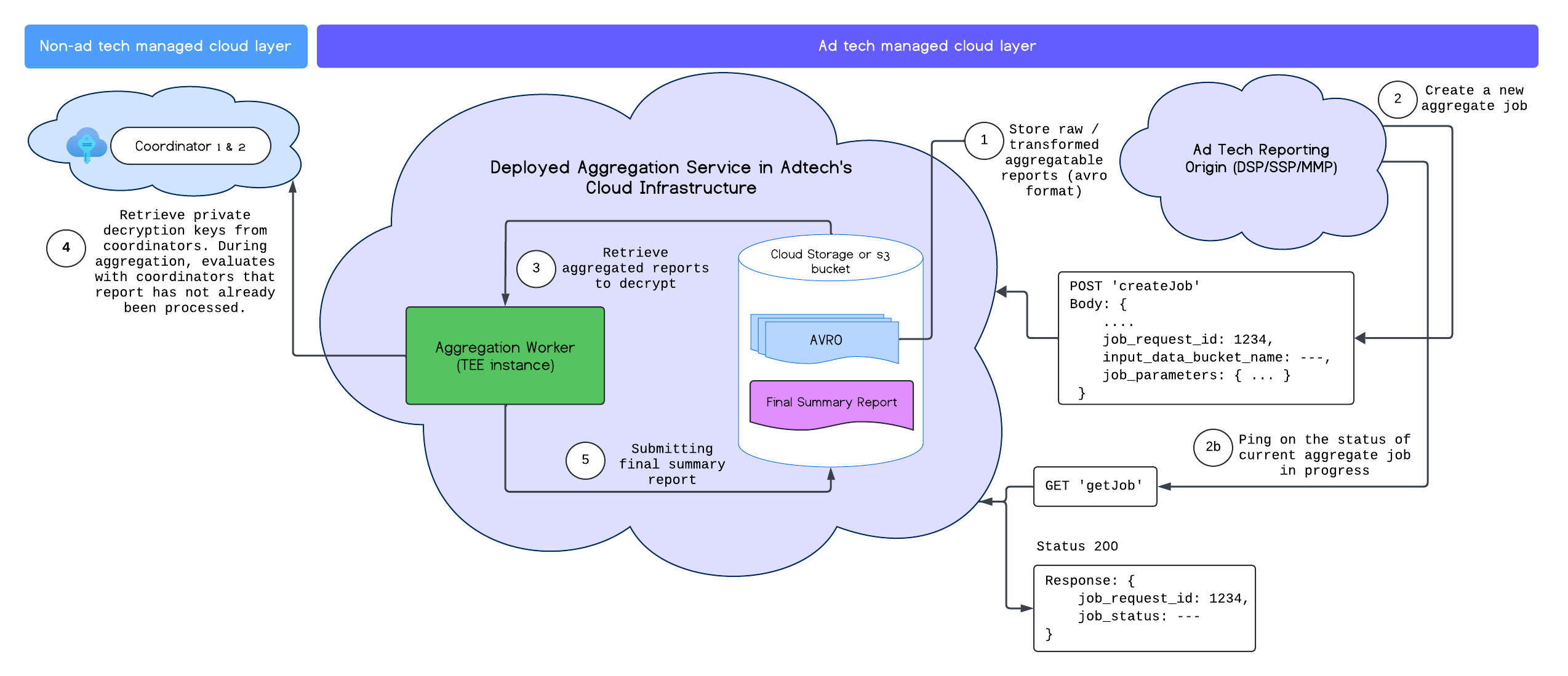
You can read more about the createJob and getJob endpoints in the Aggregation Service API documentation.
Create a job
To create a job, send a POST request to the createJob endpoint.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
An example of the request body for createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
A successful job creation results in a 202 HTTP status code.
Note that reporting_site and attribution_report_to are mutually exclusive and only one is required.
You can also request a debug job by adding debug_run into the job_parameters.
For further information about debug mode, check out our aggregation debug run documentation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Request fields
| Parameter | Type | Description |
|---|---|---|
job_request_id |
String |
This is an ad tech generated unique identifier that should be ASCII letters with 128 characters or less. This identifies the batch job request and takes all the aggregatable AVRO reports specified in the `input_data_blob_prefix` from the input bucket specified in the `input_data_bucket_name` that is hosted on the ad tech's cloud storage.
Characters: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
String |
This is the bucket path. For single files, you can use the path. For multiple files, you can use the prefix in the path.
Example: The folder/file collects all reports from folder/file1.avro, folder/file/file1.avro, and folder/file1/test/file2.avro. |
input_data_bucket_name |
String | This is the storage bucket for the input data or aggregatable reports. This is on the ad tech's cloud storage. |
output_data_blob_prefix |
String | This is the output path in the bucket. A single output file is supported. |
output_data_bucket_name |
String |
This is the storage bucket where the output_data is sent. This exists on the ad tech's cloud storage.
|
job_parameters |
Dictionary |
Required field. This field contains the different fields such as:
|
job_parameters.output_domain_blob_prefix |
String |
Similar to input_data_blob_prefix, this is the path in the output_domain_bucket_name where your output domain AVRO is located. For multiple files, you can use the prefix in the path. Once the Aggregation Service completes the batch, the summary report is created and placed in the output bucket output_data_bucket_name with the output_data_blob_prefix name.
|
job_parameters.output_domain_bucket_name |
String | This is the storage bucket for your output domain AVRO file. This is on the ad tech's cloud storage. |
job_parameters.attribution_report_to |
String | This value is mutually exclusive to the `reporting_site`. This is the reporting URL or reporting origin where the report was received. The site origin is registered in the Aggregation Service Onboarding. |
job_parameters.reporting_site |
String |
Mutually exclusive to attribution_report_to. This is the hostname of the reporting URL or reporting origin where the report was received. The site origin is registered in the Aggregation Service Onboarding.
Note: You may submit multiple reports with different origins within a single request, provided that all origins belong to the same reporting site specified in this parameter.
|
job_parameters.debug_privacy_epsilon |
Floating point, Double | Optional field. If no value is passed, the default value is 10. A value of from 0 to 64 can be used. |
job_parameters.report_error_threshold_percentage |
Double | Optional field. This is the maximum percentage of failed reports allowed before the job fails. If left empty, the default value is 10%. |
job_parameters.input_report_count |
long value |
Optional field. The total number of reports provided as input data for the job. This value, in conjunction with report_error_threshold_percentage enables early job failure when reports are excluded due to errors.
|
job_parameters.filtering_ids |
String |
Optional field. A list of unsigned filtering IDs separated by a comma. All the contributions other than the matching filtering ID are filtered out. (e.g."filtering_ids": "12345,34455,12"). The default value is 0.
|
job_parameters.debug_run |
Boolean |
Optional field. When executing a debug run, noised and un-noised debug summary reports and annotations are added to indicate which keys are present in the domain input and/or reports. Additionally, duplicates across batches are also not enforced. Note that the debug run only considers reports that have the flag "debug_mode": "enabled". As of v2.10.0, debug runs do not consume privacy budget.
|
Get a job
When an ad tech wants to know the status of a requested batch they can call the getJob endpoint. The getJob endpoint is called using an HTTPS GET request along with the job_request_id parameter.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
You should get a response that returns the job status along with any error messages:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Response fields
| Parameter | Type | Description |
|---|---|---|
job_request_id |
String |
This is the unique job/batch ID that was specified in the createJob request.
|
job_status |
String | This is the status of the job request. |
request_received_at |
String | The time that the request was received. |
request_updated_at |
String | The time the job was last updated. |
input_data_blob_prefix |
String |
This is the input data prefix that was set at createJob.
|
input_data_bucket_name |
String |
This is the ad tech's input data bucket where the aggregatable reports are stored. This field is set at createJob.
|
output_data_blob_prefix |
String |
This is the output data prefix that was set at createJob.
|
output_data_bucket_name |
String |
This is the ad tech's output data bucket where the generated summary reports are stored. This field is set at createJob.
|
request_processing_started_at |
String |
The time when the latest processing attempt has started. This excludes the time waiting in the job queue.
(Total processing time = request_updated_at - request_processing_started_at)
|
result_info |
Dictionary |
This is the result of the createJob request and consists of all the of information that is available.
This shows the return_code, return_message, finished_at and error_summary values.
|
result_info.return_code |
String | The job result return code. This information is needed for troubleshooting if there is an issue in the Aggregation Service. |
result_info.return_message |
String | Either the success or failure message returned as a result of the job. This information is also needed for troubleshooting Aggregation Service issues. |
result_info.error_summary |
Dictionary | The errors that return from the job. This contains the number of reports along with the type of errors that were encountered. |
result_info.finished_at |
Timestamp | The timestamp indicating job completion. |
result_info.error_summary.error_counts |
List |
This returns a list of the error messages along with the number of reports that failed with the same error message. Each error counts contain a category, error_count,and description.
|
result_info.error_summary.error_messages |
List | This returns a list of the error messages from reports that failed to process. |
job_parameters |
Dictionary |
This contains the job parameters provided in the createJob request. Relevant properties such as `output_domain_blob_prefix` and `output_domain_bucket_name`.
|
job_parameters.attribution_report_to |
String |
Mutually exclusive to reporting_site. This is the reporting URL or the origin of where the report was received. The origin is part of the site that is registered in Aggregation Service Onboarding. This is specified in the createJob request.
|
job_parameters.reporting_site |
String |
Mutually exclusive to attribution_report_to. This is the hostname of the reporting URL or the origin of where the report was received. The origin is part of the site that is registered in Aggregation Service Onboarding. Note that you may submit reports with multiple reporting origins in the same request as long as all reporting origins belong to the same site mentioned in this parameter. This is specified in the createJob request. Additionally, ensure that the bucket only contains the reports that you want aggregated at the time of job creation. Any reports added to the input data bucket with reporting origins matching the reporting site specified in the job parameter is processed.
The Aggregation Service only considers reports within the data bucket that match the job's registered reporting origin. For example, if the registered origin is https://exampleabc.com, only reports from https://exampleabc.com are included, even if the bucket contains reports from subdomains (https://1.exampleabc.com, etc.) or entirely different domains (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
Floating point, Double |
Optional field. If no value passed, the default value of 10 is used. Values can be from 0 to 64. This value is specified in the createJob request.
|
job_parameters.report_error_threshold_percentage |
Double |
Optional field. This is the threshold percentage of reports that can fail before job failure. If no value is assigned, the default value of 10% is used. This is specified in the createJob request.
|
job_parameters.input_report_count |
Long value | Optional field. The total number of reports provided as input data for this job. The `report_error_threshold_percentage`, combined with this value, triggers early job failure if a significant number of reports are excluded due to errors. This setting is specified in the `createJob` request. |
job_parameters.filtering_ids |
String |
Optional field. A list of unsigned filtering IDs separated by comma. All the contributions other than the matching filtering ID is filtered out. This is specified in the createJob request.
(e.g. "filtering_ids":"12345,34455,12". Default value is "0".)
|