集計サービスは、集計可能レポートの元データから、詳細なコンバージョン データとリーチ測定の概要レポートを生成します。広告テクノロジー企業は、クライアント側の 2 つの主要な集約エントリ ポイントである Attribution Reporting API と Private Aggregation API を使用して、レポートを集約サービスに送信し、レスポンスとして概要レポートを受け取ることができます。
このページは、広告テクノロジーに精通していることを前提としています。ここでは、次のことを説明します。
実装ステータス
- 集計サービスが一般提供に移行しました。
- Aggregation Service は、Attribution Reporting API と Private Aggregation API(Protected Audience API と Shared Storage API 用)で使用できます。
対象
| 提案 | ステータス |
|---|---|
| Cross Cloud Privacy Budget Service
説明 |
利用可能 |
| Attribution Reporting API と Private Aggregation API での Amazon Web Services(AWS)の Aggregation Service のサポート
説明 |
利用可能 |
| Attribution Reporting API と Private Aggregation API での Google Cloud の Aggregation Service のサポート 説明 |
利用可能 |
| Aggregation Service サイトの登録とマルチオリジン集約。サイトの登録には、サイトとクラウド アカウント(AWS または GCP)のマッピングが含まれます。複数のオリジンを集約するには、同じサイトのオリジンである必要があります。 GitHub のよくある質問 Site Aggregation API のドキュメント |
利用可能 |
| Aggregation Service のε 値は、さまざまなパラメータのテストとフィードバックを容易にするために、最大 64 の範囲で維持されます。
ARA イプシロンのフィードバックを送信する。 PAA イプシロン フィードバックを送信します。 |
利用できます。イプシロン範囲の値が更新される前に、エコシステムに事前にお知らせします。 |
| 集計サービス クエリの貢献度フィルタリングをより柔軟に。
説明 |
利用可能 |
| 障害発生後の予算回復プロセス(エラー、構成ミスなど)
説明 |
利用可能 予算回復を使用して広告テクノロジーが復元した共有 ID の割合を確認するメカニズムと、過剰な復元に対して今後の復元を停止するメカニズムが 2025 年第 1 四半期に予定 |
| AWS のコーディネーターとして活動している Accenture
デベロッパー ブログ |
利用可能 |
| Google Cloud のコーディネーターとして活動する独立した組織
デベロッパー ブログ |
利用可能 |
| Attribution Reporting API の集計デバッグ レポートに対する集計サービスのサポート
説明 |
利用可能 |
主な用語と概念
ワークフローに集計サービスを検討している場合は、次の用語とコンセプトを確認して、この新しい集計フローがチームにどのようなメリットをもたらすかを把握してください。
用語集
- 集計可能レポート
-
集計可能レポートは、個々のユーザーのデバイスから送信される暗号化されたレポートです。これらのレポートには、クロスサイトのユーザー行動とコンバージョンに関するデータが含まれます。コンバージョン(アトリビューション トリガー イベントと呼ばれることもあります)と関連する指標は、広告主または広告テクノロジーによって定義されます。各レポートは暗号化され、さまざまな関係者が基盤となるデータにアクセスできないようにしています。
詳しくは、集計可能なレポートについての記事をご覧ください。
- 集計可能レポートのアカウンティング
-
両方のコーディネーターにある分散レジャー。割り当てられたプライバシー バジェットを追跡し、「重複なし」ルールを適用します。これは、コーディネーター内に配置され、実行されるプライバシー保護メカニズムです。これにより、割り当てられたプライバシー バジェットを超えるレポートが集計サービスに渡されないようにします。
詳しくは、バッチ処理戦略と集計可能なレポートの関係をご覧ください。
- 集計可能レポートのアカウンティング予算
-
個々のレポートが複数回処理されないようにする予算への参照。
- 集計サービス
-
集計可能レポートを処理して概要レポートを作成する、広告テクノロジー運営のサービス。
集約サービスの背景については、説明と利用規約の全文リストをご覧ください。
- 宣誓
-
通常は暗号ハッシュまたは署名を使用して、ソフトウェアの ID を認証するメカニズム。集計サービスの提案では、構成証明は、広告テクノロジーが運用する集計サービスで実行されているコードとオープンソース コードを照合します。
- 拠出型ボンディング
- コーディネーター
-
鍵の管理と集計可能なレポートの処理を担当するエンティティ。コーディネーターは、承認済みの集計サービス構成のハッシュのリストを維持し、復号鍵へのアクセスを構成します。
- ノイズとスケーリング
-
集計プロセス中に概要レポートに追加される統計ノイズ。プライバシーを保護し、最終レポートで匿名化された測定情報を提供できるようにします。
ラプラス分布から取得される加算ノイズ メカニズムの詳細を確認する。
- 報告元
-
集計可能レポートを受信するエンティティ(つまり、Attribution Reporting API を呼び出したお客様または広告テクノロジー)。集計可能レポートは、ユーザー デバイスから、レポート送信元に関連付けられた既知の URL に送信されます。報告元は登録時に指定します。
- 共有 ID
-
shared_info、reporting_origin、destination_site(Attribution Reporting API のみ)、source_registration-time(Attribution Reporting API のみ)、scheduled_report_time、バージョンで構成される計算値。shared_infoフィールドで同じ属性を共有する複数のレポートには、同じ共有 ID を設定する必要があります。共有 ID は、集計可能レポートのアカウンティングで重要な役割を果たします。詳しくは、信頼できるサーバーについての記事をご覧ください。
- 概要レポート
-
Attribution Reporting API と Private Aggregation API のレポート タイプ。サマリー レポートには、集計されたユーザーデータが含まれます。また、ノイズが追加された詳細なコンバージョン データも含まれる場合があります。概要レポートは集計レポートで構成されます。イベントレベル レポートよりも柔軟性が高く、より豊富なデータモデルを提供します。特に、コンバージョン値などのユースケースではその効果が顕著です。
- 高信頼実行環境(TEE)
-
コンピュータのハードウェアとソフトウェアの安全な構成。これにより、外部の関係者は、漏洩を恐れずにマシンで実行されているソフトウェアの正確なバージョンを確認できます。これにより外部関係者は、ソフトウェア メーカーが主張している動作を、ソフトウェアが、それ以上でもそれ以下でもなく正確に実行していることを確認できます。
プライバシー サンドボックスの提案で使用される TEE について詳しくは、Protected Audience API サービスの説明と集計サービスの説明をご覧ください。
集計のユースケース
広告測定のデベロッパー ジャーニーと、対応する測定クライアント ライブラリについて、次の例をご覧ください。
| ユースケース | エントリ ポイント | 説明 |
|---|---|---|
| 入札の最適化 | Attribution Reporting API (Chrome と Android) | 集計レポートを使用して、入札単価の最適化に役立つコンバージョン シグナルを取り込みます。 |
| クロス プラットフォーム測定 | Attribution Reporting API (Chrome と Android) | ウェブとアプリをまたいだ測定機能を使用して、Chrome と Android 全体のパフォーマンスを把握できます。 |
| コンバージョン レポート | Attribution Reporting API (Chrome と Android) | お客様のキャンペーンのニーズに合わせて、コンバージョンの集計レポートを作成します(クリックスルー コンバージョンとビュースルー コンバージョンを含む)。 |
| キャンペーンのリーチ測定 | Shared Storage API とPrivate Aggregation API (Chrome) | クロスサイト広告ビュー変数を使用して、キャンペーンのリーチを測定します。 |
| ユーザー属性レポート | Shared Storage API とPrivate Aggregation API (Chrome) | クロスサイト広告ビューとユーザー属性情報を使用して、ユーザー属性別のリーチを測定します。 |
| コンバージョン経路の分析 | Shared Storage API とPrivate Aggregation API (Chrome) | クロスサイト広告ビューとコンバージョン変数を保存して、コンバージョン経路の集計分析を行います。 |
| ブランド効果とコンバージョン リフト | Shared Storage API とPrivate Aggregation API (Chrome) | テストグループとコントロール グループに関するレポートと、ブランド効果とインクリメンタリティを測定するためのアンケート情報。 |
| オークションのデバッグ | Protected Audience API と Private Aggregation API(Chrome) | 集計レポートを使用してデバッグします。 |
| 入札単価の分布 | Protected Audience API と Private Aggregation API(Chrome) | 集計レポートを使用して、オークションの入札値の分布を把握します。 |
エンドツーエンドのフロー
次の図は、Aggregation Service の動作を示しています。ここでは、ウェブデバイスとモバイル デバイスからレポートが受信されてから、集計サービスで概要レポートが作成されるまでのエンドツーエンドのフローについて説明します。
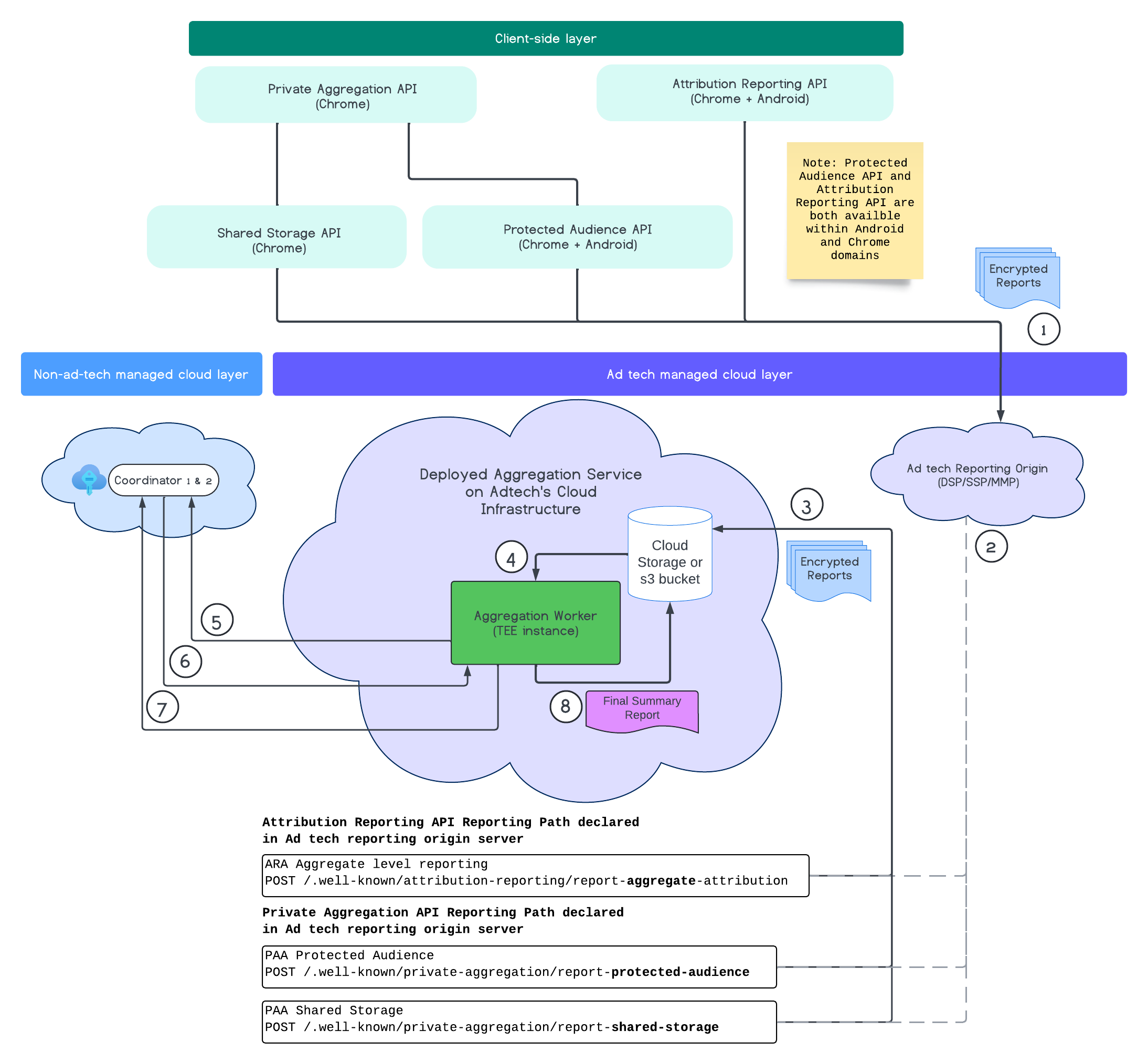
- 暗号化されたレポートを生成するために公開鍵を取得します。
- 暗号化された集計可能レポートは、広告テクノロジー サーバーに送信され、収集、変換、バッチ処理されます。
- 広告テクノロジー サーバーがレポートをバッチ処理(avro 形式)して集計サービスに送信します。(この手順は必須です)。
- 集計ワーカーが集計レポートを取得して復号します。
- 集計ワーカーは、コーディネーターから復号鍵を取得します。
- 集計ワーカーは、集計とノイズ追加のためにレポートを復号します。
- 集計可能レポートのアカウント サービスは、指定された集計可能レポートの概要レポートを生成するのに十分なプライバシー バジェットがあるかどうかを確認します。
- 最終的な概要レポートを提出します。
この図は、集計サービスと主なクライアント測定 API(Attribution Reporting API、Private Aggregation API、コーディネーター)との大まかな関係を示しています。
フローでは、Attribution Reporting API や Private Aggregation API などの測定 API を使用して、複数のブラウザ インスタンスからレポートを生成します。Chrome は、コーディネータの鍵ホスティング サービスから公開鍵を取得し、レポートを暗号してから広告テクノロジー レポート送信元に送信します。公開鍵は 7 日ごとにローテーションされます。
広告テクノロジーのレポート送信元は、バッチ処理戦略で説明されているように、受信レポートを収集して avro 形式に変換し、集計サービスに送信するように構成する必要があります。
バッチの準備ができたら、集計サービスにバッチ リクエストを送信します。集計サービスは、鍵ホスティング サービスから復号鍵を取得し、レポートを復号して集計し、ノイズを追加して概要レポートを作成します。ただし、作成に十分なプライバシー 予算があることが前提となります。
レポートが収集される広告テクノロジー レポート送信元エンドポイントをホストし、Aggregation Service を広告テクノロジー クラウドにデプロイします。
集計可能レポートのバッチ処理
指定されたレポート送信元サーバーのサポートなしでは、レポート フローは完了しません。これは、登録プロセスで送信したオリジンです。レポート送信元は、受信した集計可能レポートの収集、変換、バッチ処理を行い、Google Cloud または Amazon Web Services の集計サービスに送信する準備を行います。詳しくは、集計可能なレポートの準備方法をご覧ください。
一般的なコンセプトを理解できたところで、Aggregation Service にデプロイされるコンポーネントについて詳しく見てみましょう。
クラウド コンポーネント
集約サービスは、複数のクラウド サービス コンポーネントで構成されています。提供された Terraform スクリプトを使用して、必要なすべてのクラウド サービス コンポーネントをプロビジョニングして構成します。
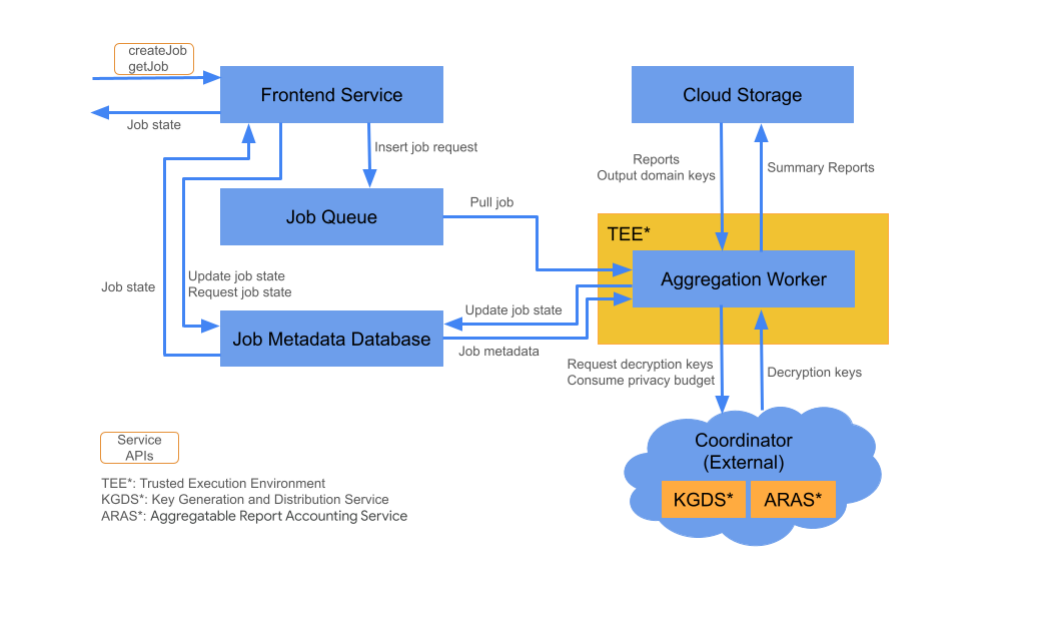
フロントエンド サービス
マネージド クラウド サービス: Cloud Functions(Google Cloud)/ API Gateway(Amazon Web Services)
Frontend Service は、ジョブの作成とジョブ状態の取得のための Aggregation API 呼び出しのメイン エントリ ポイントであるサーバーレス ゲートウェイです。Aggregation Service ユーザーからのリクエストの受信、入力パラメータの検証、集計ジョブのスケジューリング プロセスの開始を行います。
Frontend Service には、次の 2 つの API があります。
| エンドポイント | 説明 |
|---|---|
createJob |
この API は、集計サービス ジョブをトリガーします。ジョブをトリガーするには、ジョブ ID、入力ストレージの詳細、出力ストレージの詳細、レポート送信元などの情報が必要です。 |
getJob |
この API は、指定されたジョブ ID を持つジョブのステータスを返します。ジョブのステータス(「受信済み」、「処理中」、「完了」など)に関する情報を提供します。ジョブが完了すると、ジョブの実行中に発生したエラー メッセージなど、ジョブの結果も返されます。 |
Aggregation Service API のドキュメントを確認する。
ジョブキュー
マネージド クラウド サービス: Pub/Sub(Google Cloud)/ Amazon SQS(Amazon Web Services)
ジョブキューは、集計サービスのジョブリクエストを含むメッセージキューです。フロントエンド サービスは、キューにジョブリクエストを挿入します。このリクエストは、集計ワーカーによって消費され、処理されます。
クラウド ストレージ
マネージド クラウド サービス: Google Cloud Storage(Google Cloud)/ Amazon S3(Amazon Web Services)
Aggregation Service で使用される入力ファイルと出力ファイル(暗号化されたレポート ファイルや出力概要レポートなど)は、Cloud Storage に保存されます。
ジョブのメタデータ データベース
マネージド クラウド サービス: Spanner(Google Cloud)/ DynamoDB(Amazon Web Services)
ジョブ メタデータ データベースは、集計ジョブのステータスの保存と追跡に使用されます。作成日時、リクエスト日時、更新日時、状態(受信済み、進行中、完了済みなど)などのメタデータが記録されます。集計ワーカーは、ジョブの進行に応じてジョブ メタデータ データベースを更新します。
集計ワーカー
マネージド クラウド サービス: Confidential Space を使用した Compute Engine(Google Cloud)/ Nitro Enclave を使用した Amazon Web Services EC2(Amazon Web Services)
集計ワーカーは、ジョブキューでジョブリクエストを処理し、コーディネータの鍵生成と配布サービス(KGDS)から取得した鍵を使用して暗号化された入力を復号します。ジョブ処理のレイテンシを最小限に抑えるために、集計ワーカーは復号キーを 8 時間キャッシュに保存し、処理するジョブ全体で使用します。
集計ワーカーは、高信頼実行環境(TEE)インスタンス内で動作します。ワーカーは一度に 1 つのジョブのみを処理します。自動スケーリング構成を設定することで、ジョブを並行して処理するように複数のワーカーを構成できます。自動スケーリングを使用する場合、自動スケーリングはジョブキュー内のメッセージ数に応じてワーカー数を動的に調整します。自動スケーリングのワーカーの最小数と最大数は、Terraform 環境ファイルで構成できます。自動スケーリングの詳細については、Amazon Web Services または Google Cloud の Terraform スクリプトをご覧ください。
集計ワーカーは、集計可能レポートのアカウンティングのために集計可能レポート アカウンティング サービスを呼び出します。このサービスにより、プライバシー バジェットの上限を超えていない場合にのみジョブが実行されます。(「重複なし」ルールを参照)。予算が利用可能な場合は、ノイズの多い集計値を使用して概要レポートが生成されます。詳しくは、集計可能なレポートのアカウント設定をご覧ください。
集約ワーカーは、ジョブメタデータ データベースでジョブメタデータを更新します。この情報には、ジョブの戻りコードと、レポートの一部が失敗した場合のレポート エラー カウンタが含まれます。ユーザーは、getJob ジョブ状態取得 API を使用して状態を取得できます。
集計サービスの詳細については、こちらの説明をご覧ください。
次のステップ
Aggregation Service のハイライトを確認したので、Google Cloud または Amazon Web Services で Aggregation Service の独自のインスタンスのデプロイに進みましょう。集計サービスの運用について詳しくは、スタートガイドをご覧ください。または、こちらのリンク先をご覧ください。
トラブルシューティング
エラー メッセージの詳細な説明、発生したエラーの原因、緩和のための次のステップについては、一般的なエラーコードと緩和策のドキュメントをご覧ください。
サポートの利用とフィードバック
- プロダクトに関する質問、フィードバック、機能リクエストについては、GitHub リポジトリで問題を作成してください。
- Aggregation Service を使用してジョブのデプロイ、メンテナンス、実行中にエラーが発生した場合は、こちらのテクニカル サポート フォームを使用してテクニカル トラブルシューティング サポートをリクエストしてください。
- 公開ステータス ダッシュボードで既知の問題を確認します。