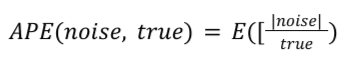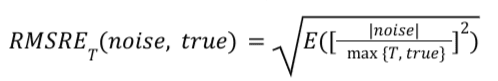Comprendre les stratégies à créer avant de générer des rapports récapitulatifs
Découvrir Noise Lab, un outil qui vous aide à comprendre les effets de différents paramètres de bruit, et qui permet d'examiner et d'évaluer rapidement différentes stratégies de gestion du bruit
Noise Lab
Envoyer des commentaires
Bien que ce document résume quelques principes
à utiliser avec les rapports de synthèse,
Il existe plusieurs approches de la gestion du bruit qui peuvent ne pas être prises en compte
ici. Vos suggestions, ajouts et questions sont les bienvenus !
Pour transmettre des commentaires au public sur les stratégies de gestion du bruit, sur
l'utilité ou la confidentialité de l'API (epsilon), et de partager vos observations lorsque
avec Noise Lab:
Commenter ce problème
Pour donner un avis public sur Noise Lab (poser une question, signaler un bug,
demander une fonctionnalité):
Signaler un problème ici
Il existe des différences fondamentales entre le fonctionnement des cookies tiers et celui des rapports récapitulatifs. L'une des différences majeures
bruit ajouté aux données de mesure dans les rapports récapitulatifs. Un autre aspect concerne la planification des rapports.
Pour accéder aux données de mesure des rapports récapitulatifs avec un niveau de signal sur bruit plus élevé
ratios, les plates-formes côté demande (DSP) et les fournisseurs de solutions de mesure des annonces devront
collaborent avec leurs annonceurs pour élaborer des stratégies de gestion du bruit. Pour développer ces stratégies, les DSP et les fournisseurs de solutions de mesure doivent prendre des décisions de conception. Ces décisions s'articulent autour d'un concept essentiel:
Bien que les valeurs de bruit de la distribution soient tirées, à proprement parler, uniquement de deux paramètres ⏤epsilon et du budget de contribution⏤, vous disposez d'un certain nombre d'autres contrôles qui auront un impact sur
rapport signal/bruit de vos données de mesure de sortie.
Bien que nous nous attendions à ce qu'un processus itératif mène aux meilleures décisions, chaque variation de ces décisions
peuvent entraîner une implémentation légèrement différente. Vous devez donc prendre ces décisions avant d'écrire chaque itération de code (et avant de diffuser les annonces).
Décision: Précision des dimensions
Faites un essai dans Noise Lab
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez "Vos données de conversion".
Respectez les paramètres par défaut. Par défaut, la valeur quotidienne de TOTAL
le nombre de conversions attribuables est de 1 000. Cela représente environ 40 par
bucket si vous utilisez la configuration par défaut (dimensions par défaut, nombre de
valeurs possibles différentes pour chaque dimension, stratégie clé A). Notez que
la valeur est de 40 dans le nombre moyen de conversions attribuables par jour d'entrée
PAR BUCKET.
Cliquez sur "Simuler" pour exécuter une simulation avec les paramètres par défaut.
Dans le panneau latéral "Paramètres", recherchez "Dimensions". Renommer
Définissez le champ Geography (Zone géographique) sur City (Ville), puis définissez le nombre de valeurs différentes possibles sur 50.
Observez l'évolution du nombre moyen de conversions attribuables quotidiennes
PAR BUCKET. Elle est désormais bien inférieure. En effet, si vous augmentez
le nombre de valeurs possibles dans cette dimension sans la modifier
vous augmentez le nombre total de buckets sans modifier
le nombre d'événements de conversion qui appartiendront à chaque segment.
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue. Ils sont
soit supérieur à celui de la simulation précédente.
Compte tenu du principe de conception de base, les petites valeurs récapitulatives sont susceptibles d'être
plus bruyante que
les grandes valeurs de résumé. Par conséquent, votre choix de configuration
détermine le nombre d'événements de conversion attribués qui se retrouvent dans chaque segment
(appelée clé d'agrégation) et que cette quantité a un impact sur le bruit
les rapports de
récapitulatifs de sortie finale.
Une décision de conception qui a un impact sur le nombre d'événements de conversion attribués
au sein d'un même bucket est la précision des dimensions. Voici quelques exemples :
des clés d'agrégation et de leurs dimensions:
Approche 1: une structure clé avec des dimensions approximatives: pays x campagne publicitaire (ou la campagne la plus importante)
bucket d'agrégation) x Type de produit (sur 10 types de produits possibles)
Approche 2: une structure de clés avec des dimensions précises: Ville x ID de la création x Produit (sur 100 produits possibles)
Ville est une dimension plus précise que Pays. L'ID de la création est plus précis.
que Campaign ; et Product est plus précis que Product type. Par conséquent,
La méthode 2 générera un nombre inférieur d'événements (conversions) par bucket (= par
clé) dans son rapport de synthèse que la méthode 1. Étant donné que le bruit ajouté à
le résultat est indépendant du nombre d'événements dans le bucket, des données de mesure
dans les rapports récapitulatifs seront plus bruyantes avec l'approche 2. Pour chaque annonceur, testez différents
des compromis de granularité dans la conception de la clé afin de bénéficier d'une utilité maximale
les résultats.
Décision: structures clés
Faites un essai dans Noise Lab
En mode simple, la structure de clé par défaut est utilisée. Dans la section
vous pouvez tester différentes structures de clés. Exemples de dimensions
sont incluses ; vous pouvez également les modifier.
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez "Stratégie de clé". Observer
que la stratégie par défaut, nommée A dans l'outil, utilise une clé précise
structure qui inclut toutes les dimensions: Zone géographique x ID de campagne x Produit
catégorie.
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue.
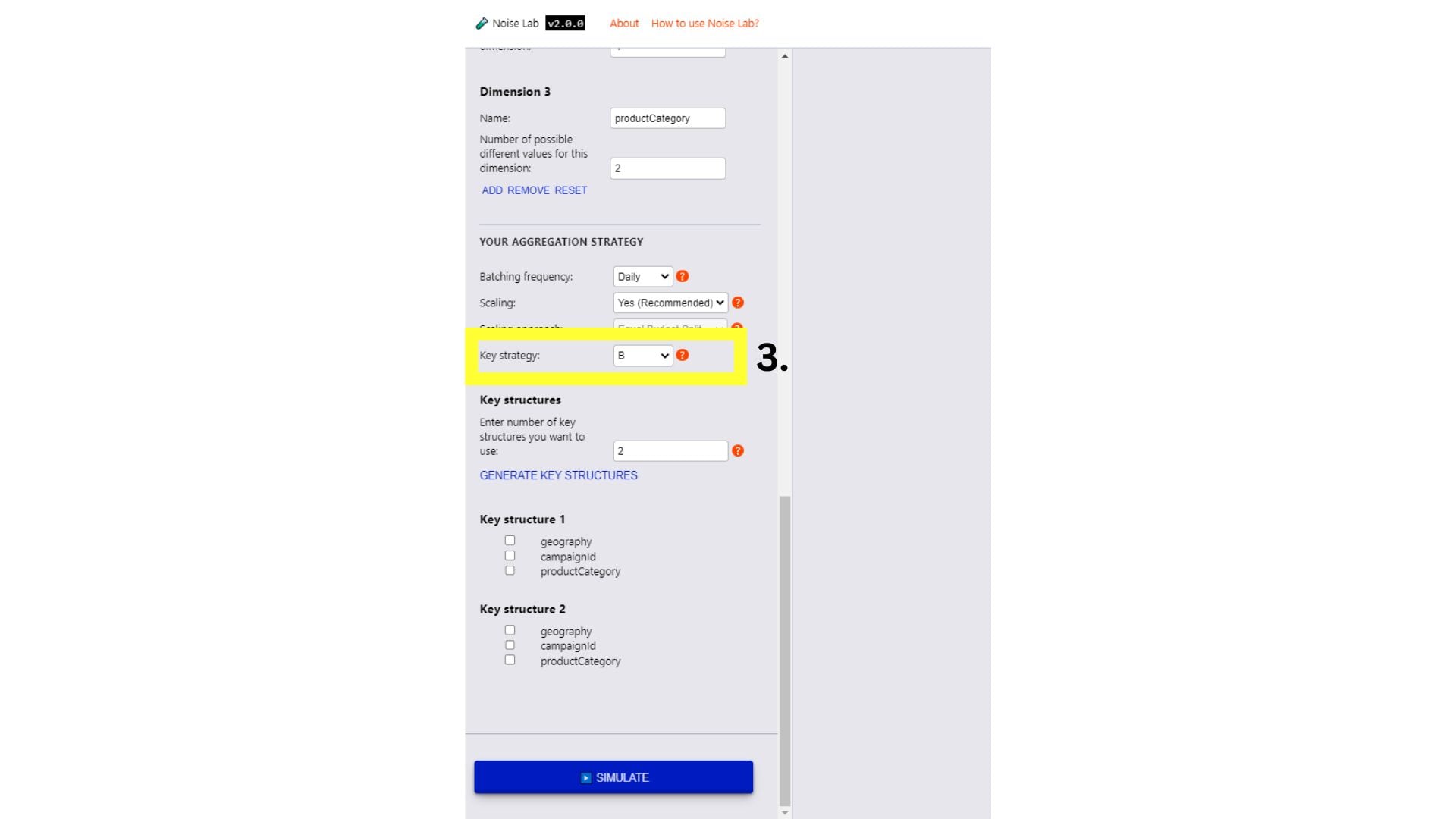
Définissez la stratégie de clés sur B. Des commandes supplémentaires s'affichent
pour configurer votre structure de clés.
Configurez la structure de vos clés, par exemple comme suit:
<ph type="x-smartling-placeholder"></ph>
Nombre de structures de clés: 2
Structure de la clé 1 = Zone géographique x Catégorie de produit
Structure de clé 2 = ID de campagne x catégorie de produit
Cliquez sur "Simuler".
Notez que vous obtenez désormais deux rapports récapitulatifs par type d'objectif de mesure.
(deux pour le nombre d'achats et deux pour la valeur des achats), étant donné que vous utilisez
deux structures clés distinctes. Observez leurs rapports de bruit.
Vous pouvez également essayer avec vos propres dimensions personnalisées. Pour ce faire,
pour les données dont vous souhaitez effectuer le suivi: dimensions. Envisager de supprimer l'exemple
et créer les vôtres à l'aide du bouton Ajouter/Supprimer/Réinitialiser
sous la dernière dimension.
Autre décision liée à la conception qui aura un impact sur le nombre de conversions attribuées
d'événements d'un même bucket est
structures clés
que vous décidez d'utiliser. Voici quelques exemples de clés d'agrégation:
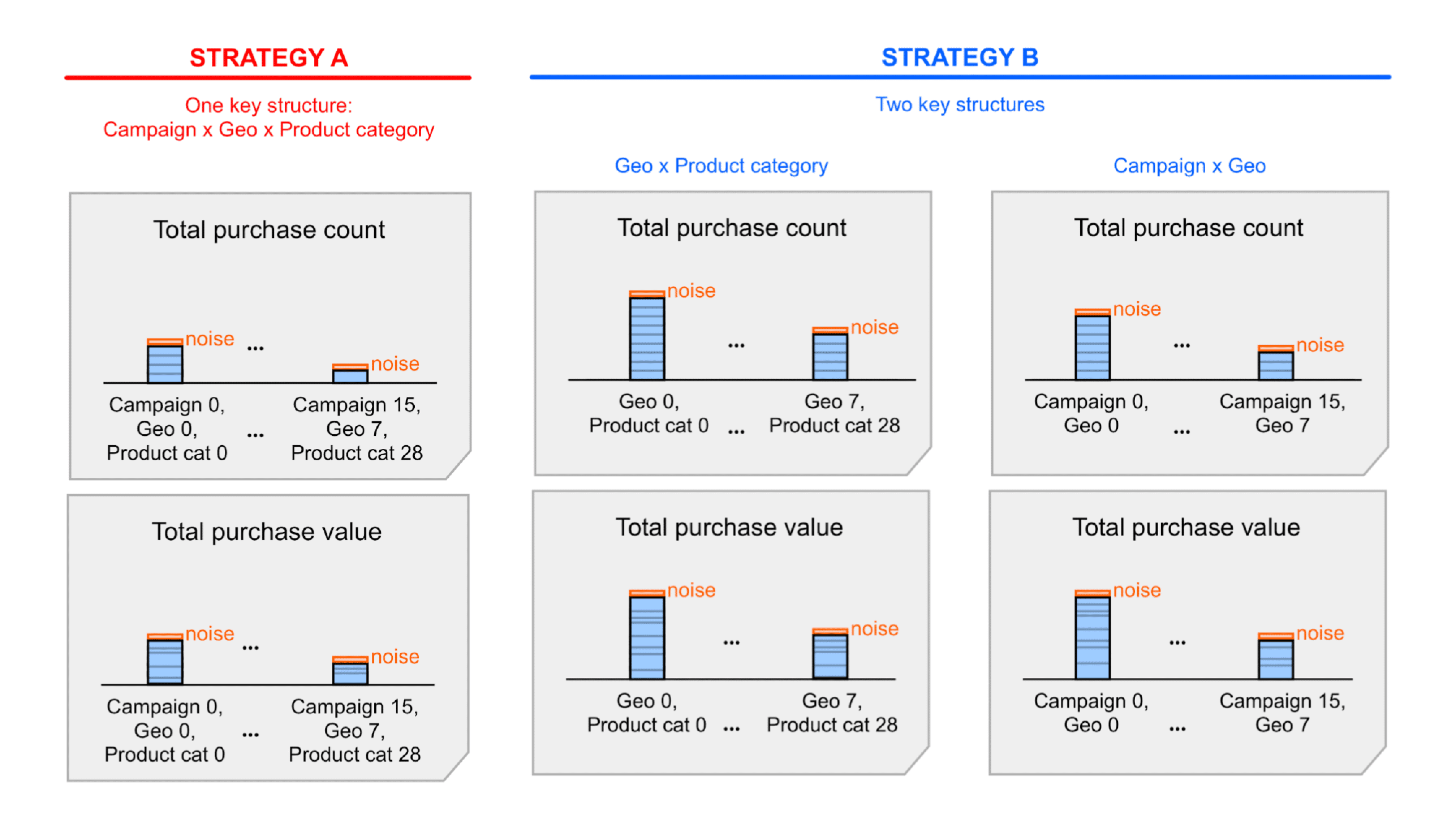
Une structure clé avec toutes les dimensions : que nous appellerons
cette stratégie clé A.
deux structures clés, chacune avec un sous-ensemble de dimensions ; Appelons-la
Stratégie clé B.
La stratégie A est plus simple, mais vous devrez peut-être cumuler (somme) les valeurs récapitulatives bruitées incluses dans les rapports de synthèse pour accéder à certaines informations. En additionnant ces valeurs, vous additionnez également le bruit.
Avec la stratégie B, les valeurs récapitulatives sont exposées dans le récapitulatif.
vous apportent peut-être déjà les informations dont vous avez besoin. Cela signifie que la stratégie B
générera probablement de meilleurs rapports signal/bruit que la stratégie A. Toutefois,
le bruit est peut-être déjà acceptable pour la stratégie A. Vous pouvez donc
La stratégie A pour la simplicité.
Pour en savoir plus, consultez l'exemple détaillé qui présente ces deux stratégies.
La gestion des clés est un sujet profond. Un certain nombre de
techniques élaborées peuvent être
pour améliorer le rapport signal/bruit. L'une d'elles est décrite dans la section
gestion de la sécurité.
Décision: Fréquence de traitement par lot
Faites un essai dans Noise Lab
Accédez au mode simple (ou au mode avancé). Les deux modes fonctionnent
de la même manière pour la fréquence de traitement par lot)
Dans le panneau latéral "Paramètres", recherchez Votre stratégie d'agrégation > Fréquence de traitement par lot. Il s'agit de la fréquence de traitement par lot
des rapports agrégables traités avec le service d'agrégation
un seul job.
Observez la fréquence de traitement par lot par défaut: une fréquence
la fréquence est simulée.
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue.
Définissez la fréquence de traitement par lot sur hebdomadaire.
Observez les rapports de bruit de la simulation obtenue. Ils sont
est maintenant inférieure (meilleure) que celle de la simulation précédente.
Autre décision liée à la conception qui aura un impact sur le nombre de conversions attribuées
dans un même bucket correspond à la fréquence de traitement par lot que vous décidez d'utiliser. La
la fréquence de traitement par lot est la fréquence
à laquelle vous traitez des rapports agrégables.
Un rapport dont l'agrégation est planifiée plus souvent (toutes les heures, par exemple)
incluent moins d'événements de conversion que le même rapport, mais
(chaque semaine, par exemple). Le rapport horaire inclura donc plus de bruit.```
incluent moins d'événements de conversion que le même rapport, mais
(chaque semaine, par exemple). Par conséquent, le rapport horaire comporte
un rapport signal/bruit inférieur à celui du rapport hebdomadaire, tous les autres paramètres étant identiques. Testez les exigences de reporting à différentes fréquences et évaluez les rapports signal/bruit pour chacune d'elles.
Décision: variables de campagne ayant une incidence sur les conversions attribuables
Faites un essai dans Noise Lab
Bien que cela puisse être difficile à prévoir
et qu'il puisse varier considérablement
en plus des effets de saisonnalité, essayez d'estimer le nombre d'appels
conversions attribuables au toucher unique à la puissance la plus proche de 10: 10, 100,
1 000 ou 10 000.
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez "Vos données de conversion".
Respectez les paramètres par défaut. Par défaut, la valeur quotidienne de TOTAL
le nombre de conversions attribuables est de 1 000. Cela représente environ 40 par
bucket si vous utilisez la configuration par défaut (dimensions par défaut, nombre de
valeurs possibles différentes pour chaque dimension, stratégie clé A). Notez que
la valeur est de 40 dans le nombre moyen de conversions attribuables par jour d'entrée
PAR BUCKET.
Cliquez sur "Simuler" pour exécuter une simulation avec les paramètres par défaut.
Observez les rapports de bruit de la simulation obtenue.
À présent, définissez le nombre total de conversions attribuables par jour sur 100.
Notez que cela réduit la valeur de la moyenne quotidienne attribuable
nombre de conversions PAR BUCKET.
Cliquez sur "Simuler".
Notez que les rapports de bruit sont
maintenant plus élevés, car lorsque vous
moins de conversions par segment, plus de bruit est appliqué pour maintenir
confidentialité.
Il est important de distinguer le nombre total de conversions possibles
annonceur par rapport au nombre total de conversions attribuées possibles. La
Enfin, ce sont les bruits dans les rapports récapitulatifs. Attribuée
Les conversions représentent un sous-ensemble du nombre total de conversions susceptibles de générer
telles que le budget et le ciblage des annonces. Par exemple, on peut s'attendre à ce qu'un
de conversions attribuées en plus pour une campagne publicitaire de 10 millions € par rapport à une annonce de 10 000 €
campagne, toutes les autres conditions étant égales.
Tenez compte des remarques suivantes :
Évaluer les conversions attribuées en fonction d'un seul contact sur le même appareil
d'attribution, car ceux-ci entrent dans le cadre des rapports récapitulatifs
collectées avec l'API Attribution Reporting.
Considérez à la fois le nombre du pire des scénarios et le nombre du meilleur scénario.
pour les conversions attribuées. Par exemple, toutes les autres valeurs étant égales,
les budgets de campagne minimaux et maximaux possibles pour un annonceur,
projeter les conversions attribuables pour les deux résultats comme données d'entrée
et la simulation.
Si vous envisagez d'utiliser le
Privacy Sandbox sur Android
tenir compte des conversions attribuées
multiplate-forme dans le calcul
Décision: utilisation du scaling
Faites un essai dans Noise Lab
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez Votre stratégie d'agrégation > Scaling. Par défaut, il est défini sur Oui.
Afin de comprendre les effets positifs de la mise à l'échelle sur le bruit
par défaut, définissez d'abord "Mise à l'échelle" sur "Non".
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue.
Définissez le scaling sur "Oui". Notez que Noise Lab calcule automatiquement
facteurs de scaling à utiliser en fonction des plages (valeurs moyennes et maximales) de
les objectifs de mesure
de votre scénario. Dans un système réel ou une phase d'évaluation
vous devez implémenter votre propre calcul pour les facteurs de scaling.
Cliquez sur "Simuler".
Notez que les rapports de bruit sont maintenant plus bas (meilleurs) pendant cette seconde
et la simulation. En effet, vous utilisez le scaling.
Par conséquent, pour augmenter les rapports signal/bruit, vous pouvez décider de transformer
collectées lors d'un événement de conversion en les ajustant par rapport
du budget de contribution (et son dégradation après le regroupement). Utilisez la mise à l'échelle pour augmenter les rapports signal/bruit.
Décision: Nombre d'objectifs de mesure et répartition du budget pour la confidentialité
Un objectif de mesure est un point de données distinct collecté dans les événements de conversion.
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez les données que vous souhaitez suivre:
Objectifs de mesure. Par défaut, vous avez deux objectifs de mesure: les achats
et le nombre d'achats.
Cliquez sur "Simuler" pour exécuter une simulation avec les objectifs par défaut.
Cliquez sur "Supprimer". Le dernier objectif de mesure (achat
dans ce cas).
Cliquez sur "Simuler".
Notez que les rapports de bruit pour la valeur d'achat sont maintenant inférieurs
(mieux) pour cette deuxième simulation. En effet, vous avez moins de
objectifs de mesure. Votre objectif de mesure comprend donc
le budget de contribution.
Cliquez sur "Réinitialiser". Vous avez à nouveau deux objectifs de mesure: les achats
et le nombre d'achats. Notez que Noise Lab calcule automatiquement
facteurs de mise à l'échelle à utiliser compte tenu des plages (valeurs moyennes et maximales) des
les objectifs de mesure
de votre scénario. Par défaut, Noise Lab divise le
le même budget pour tous les objectifs de mesure.
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue. Prenez note du
les facteurs de scaling
affichés dans la simulation.
Nous allons maintenant personnaliser la répartition
du budget pour la confidentialité
rapports signal/bruit.
Modifiez le pourcentage de budget attribué à chaque objectif de mesure. Compte tenu de la valeur par défaut
l'objectif de mesure 1, à savoir la valeur des achats,
plus large (entre 0 et 1 000) que l'objectif de mesure 2, soit
le nombre d'achats (entre 1 et 1, c'est-à-dire toujours égal à 1). En raison de
elle a besoin de « plus d'espace pour évoluer » : il serait idéal d'attribuer plus
la contribution du budget à l'objectif de mesure 1 plutôt qu'à l'objectif de mesure 2, de sorte que
il peut être étendu plus efficacement (voir "Scaling").
Attribuez 70% du budget à l'objectif de mesure 1. Attribuer 30% à la mesure
objectif 2.
Cliquez sur "Simuler".
Observez les rapports de bruit de la simulation obtenue. Achat
, les rapports de bruit sont désormais nettement inférieurs (meilleurs)
et la simulation. En ce qui concerne le nombre d'achats, ils restent à peu près les mêmes.
Continuez à ajuster la répartition du budget entre les métriques. Observez l'impact
bruit.
Notez que vous pouvez définir vos propres objectifs de mesure personnalisés à l'aide du
Boutons "Ajouter", "Supprimer" et "Réinitialiser"
Si vous mesurez un point de données (objectif de mesure) pour un événement de conversion, par exemple
le nombre de conversions, ce point de données peut recevoir l'intégralité du budget de contribution (65 536). Si vous définissez plusieurs objectifs
de mesure sur un événement de conversion,
comme le nombre de conversions et la valeur des achats, ces points de données devront
partager le budget de contribution. Vous avez donc moins de marge de manœuvre pour augmenter
valeurs.
Par conséquent, plus vous avez d'objectifs de mesure, plus le rapport signal/bruit est faible.
les plus probables (bruit plus important).
Une autre décision à prendre concernant les objectifs de mesure est la répartition du budget. Si vous répartissez le budget de contribution équitablement entre deux points de données, chaque point de données reçoit une
budget de 65536/2 = 32768. Cela peut être optimal ou non, en fonction du
la valeur maximale possible pour chaque point de données. Par exemple, si vous mesurez
le nombre d'achats avec une valeur maximale de 1 et la valeur d'achat avec un
entre 1 et 120, la valeur des achats aurait tout intérêt à avoir
"plus d'espace" à la hausse, c'est-à-dire qu'une plus grande proportion
le budget de contribution. Vous verrez si certains objectifs de mesure doivent être prioritaires
par rapport à l'impact du bruit.
Décision: Gestion des anomalies
Faites un essai dans Noise Lab
Un objectif de mesure est un point de données distinct collecté dans les événements de conversion.
Accédez au mode avancé.
Dans le panneau latéral "Paramètres", recherchez Votre stratégie d'agrégation > Scaling.
Assurez-vous que le scaling est défini sur "Oui". Notez que Noise Lab
calcule automatiquement les facteurs de scaling à utiliser, en fonction
(valeurs moyennes et maximales) que vous avez définies pour les objectifs de mesure.
Supposons que l'achat le plus important jamais effectué s'élève à 2 000 €, mais que
la plupart des achats sont compris
entre 10 et 120 $. Voyons d'abord ce qui se passe
si nous utilisons une approche de mise à l'échelle littérale (non recommandé): saisissez 2 000 $comme valeur
la valeur maximale de purchaseValue.
Cliquez sur "Simuler".
Notez que les rapports de bruit sont élevés. En effet, notre scaling
est actuellement calculé sur la base de 2 000 USD, alors qu'en réalité
la valeur des achats sera
nettement inférieure à cette valeur.
Maintenant, utilisons une approche de mise
à l'échelle plus pragmatique. Modifier le maximum
à 120 $.
Cliquez sur "Simuler".
Notez que les rapports de bruit sont plus faibles (meilleurs) dans cette deuxième simulation.
Pour implémenter le scaling, vous calculez généralement un facteur de scaling basé sur
la valeur maximale d'un événement de conversion donné ;
Pour en savoir plus, consultez cet exemple.
Cependant, évitez d'utiliser une valeur maximale littérale pour calculer ce facteur de scaling,
car cela aggraverait vos rapports signal/bruit. Supprimez plutôt les anomalies et
utilisez une valeur maximale pragmatique.
La gestion des anomalies est un sujet profond. Un certain nombre de
techniques élaborées peuvent être
pour améliorer le rapport signal/bruit. L'un est décrit dans
Gestion avancée des anomalies :
Étapes suivantes
Maintenant que vous avez évalué différentes stratégies de gestion du bruit pour votre cas d'utilisation,
vous pouvez tester les rapports de synthèse en collectant des données réelles
des données de mesure via une phase d'évaluation. Consultez les guides et conseils pour essayer l'API.
Annexe
Visite rapide de Noise Lab
Noise Lab vous aide rapidement
d'évaluer et de comparer
les stratégies de gestion du bruit. Utilisez-la pour :
Identifiez les principaux paramètres pouvant avoir une incidence sur le bruit
l'effet escompté.
Simuler l'effet du bruit sur les données de mesure de sortie données
différentes décisions de conception. Modifiez les paramètres de conception jusqu'à atteindre
rapport signal/bruit adapté à votre cas d'utilisation.
Faites-nous part de vos commentaires sur l'utilité des rapports de synthèse :
les valeurs des paramètres de bruit et epsilon, lesquelles ne fonctionnent pas ? Où se trouvent
les points d'inflexion ?
Considérez cela comme une étape de préparation. Labo de bruit
génère des données de mesure pour simuler les résultats des rapports récapitulatifs en fonction de vos
saisie. Il ne conserve pas de données et ne les partage pas.
Il existe deux modes différents dans Noise Lab:
Mode simple: découvrez les principes de base des commandes dont vous disposez
sur le bruit.
Mode avancé: testez différentes stratégies de gestion du bruit et évaluez
laquelle permet d'obtenir le meilleur rapport signal/bruit pour vos cas d'utilisation.
Cliquez sur les boutons du menu supérieur pour passer de l'un à l'autre.
(voir la capture d'écran ci-dessous).
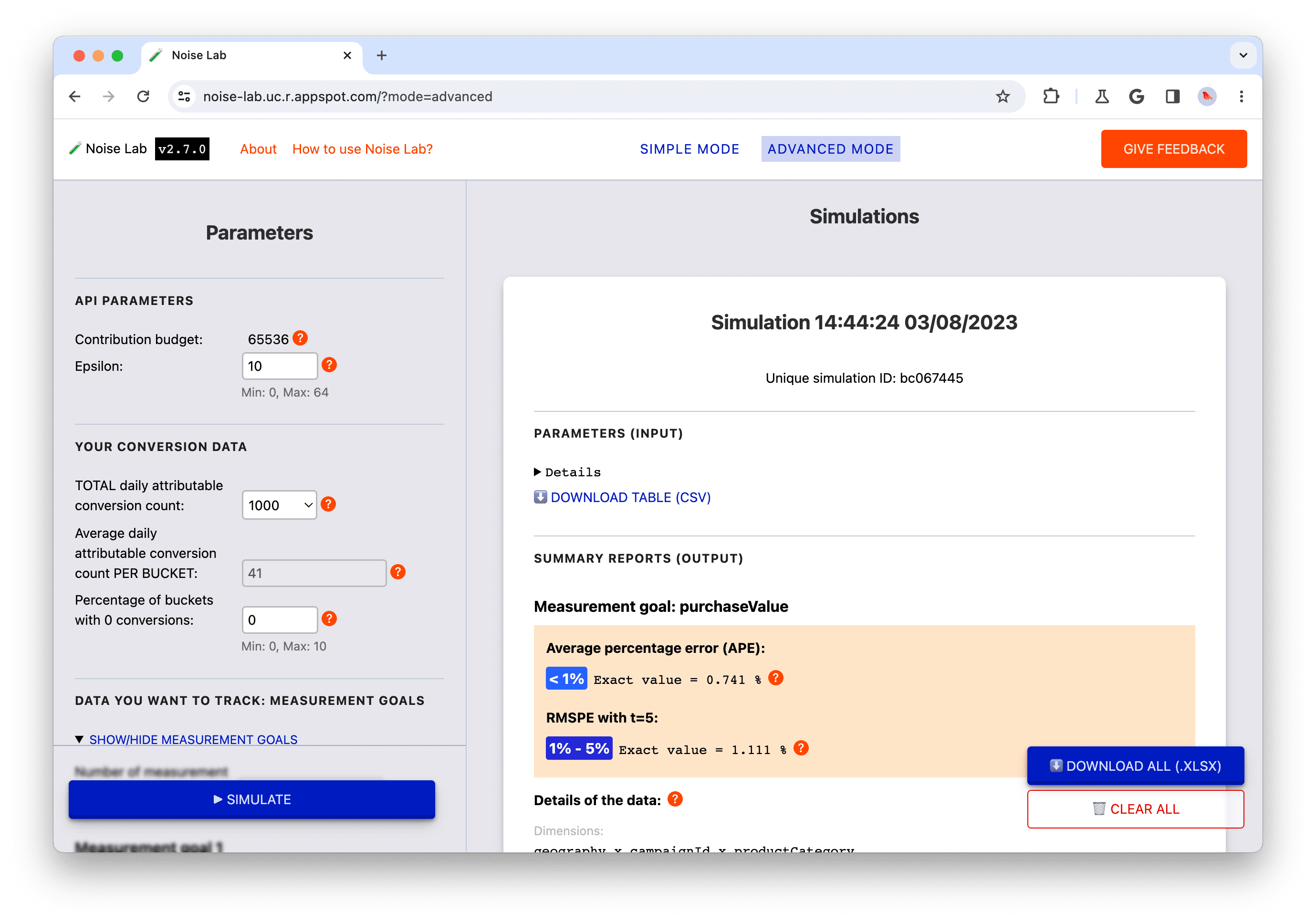
Mode simple
En mode simple, vous contrôlez les paramètres (situés à gauche de l'écran)
ou #2. dans la capture d'écran ci-dessous), comme Epsilon, pour voir leur impact sur le bruit.
Chaque paramètre est associé à une info-bulle (bouton "?"). Cliquez sur ces éléments pour afficher
une explication de chaque paramètre (n° 3 dans la capture d'écran ci-dessous) ;
Pour commencer, cliquez sur le bouton "Simuler" bouton et observez la sortie
par exemple (#4. dans la capture d'écran ci-dessous).
La section "Output" (Sortie) contient de nombreux détails. Un peu
sont précédés d'un "?". Prenez le temps de cliquer sur chaque "?" pour afficher un
une explication des
différentes informations.
Dans la section "Output" (Sortie), cliquez sur le bouton "Details" (Détails).
pour afficher une version développée du tableau (n° 5 dans la capture d'écran ci-dessous) ;
Sous chaque tableau de données dans la section "Output" (Résultats), une option
pour télécharger le tableau afin de l'utiliser hors connexion. De plus, en bas de la page
Dans l'angle droit, une option permet de télécharger tous les tableaux de données (n°6 : dans
la capture d'écran ci-dessous)
Testez différents paramètres dans la section "Paramètres".
et cliquez sur "Simuler" pour voir leur impact sur le résultat:
<ph type="x-smartling-placeholder"></ph>
Interface Noise Lab pour le mode Simple.
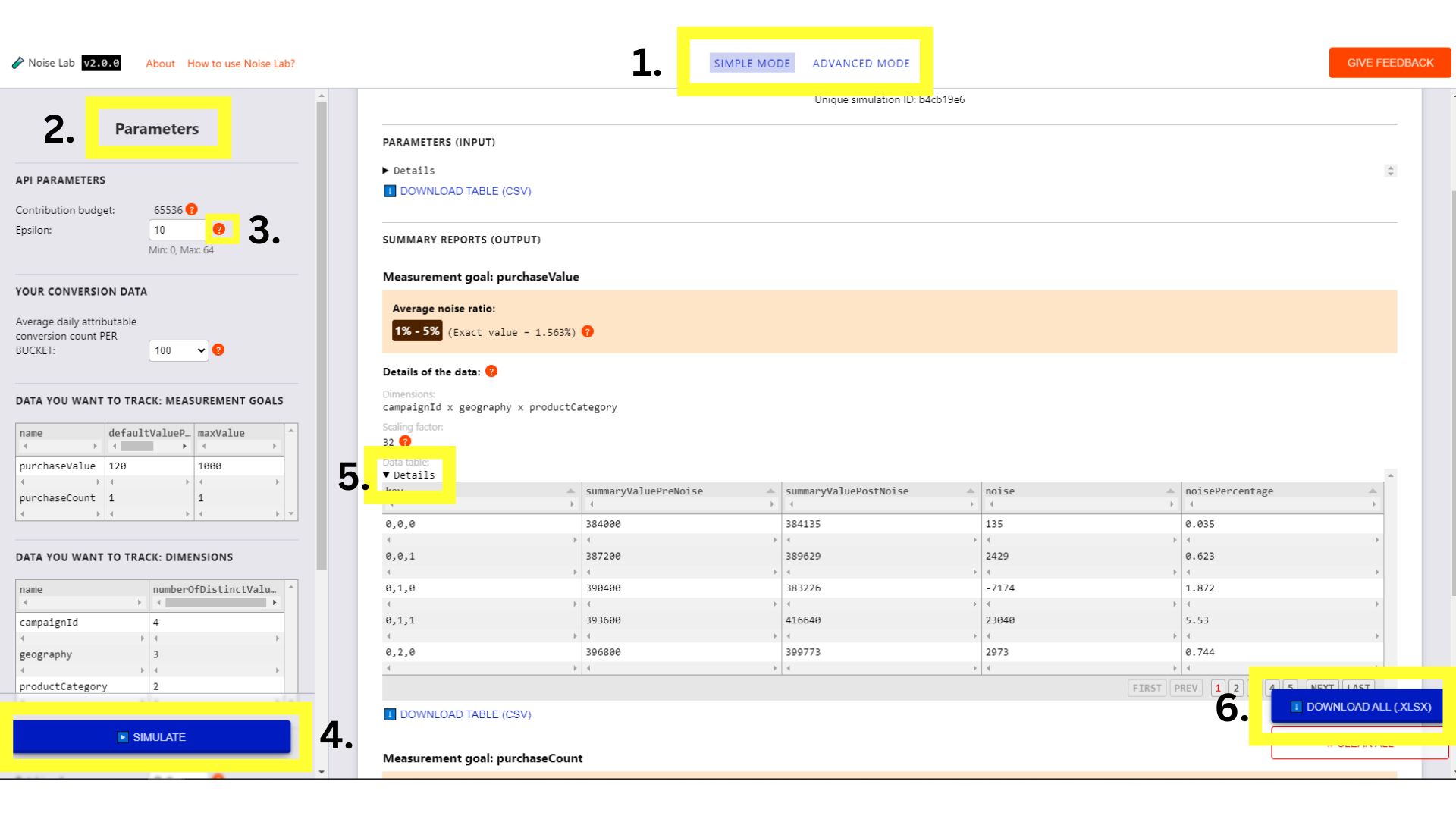
Mode avancé
En mode avancé, vous avez plus de contrôle sur les paramètres. Toi
vous pouvez ajouter des dimensions et des objectifs de mesure personnalisés (n° 1. et n° 2 dans la capture d'écran
ci-dessous)
Faites défiler la section "Paramètres" vers le bas,
Stratégie. Cela permet de tester différentes structures de clés
(N° 3 dans la capture d'écran ci-dessous)
<ph type="x-smartling-placeholder">
</ph>
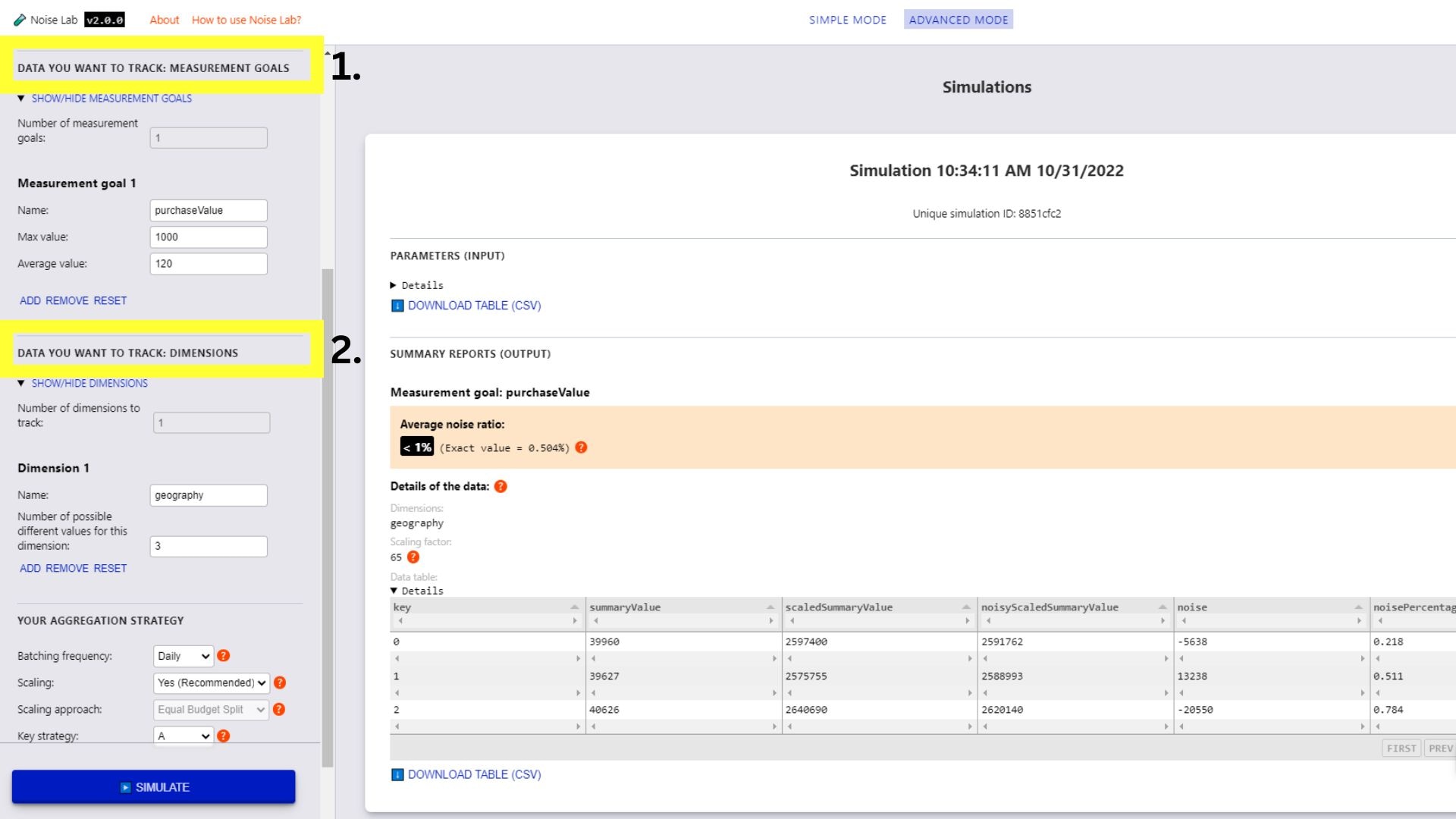
Pour tester différentes structures de clés, définissez la stratégie sur "B"
Saisissez le nombre de structures de clés différentes que vous souhaitez utiliser
(la valeur par défaut est "2")
Cliquez sur "Generate Key Structures" (Générer des structures de clés).
Des options permettant de spécifier les structures de clés s'affichent en cliquant sur
les cases à cocher à côté des clés que vous souhaitez inclure pour chaque structure de clés.
Cliquez sur "Simuler" pour afficher le résultat.
<ph type="x-smartling-placeholder"></ph>
Interface Noise Lab pour le mode avancé.Interface Noise Lab pour le mode avancé.
Métriques de bruit
Concept clé
Du bruit est ajouté afin de protéger la confidentialité de chaque utilisateur.
Une valeur de bruit élevée indique que les buckets/clés sont creux et
qui contiennent des contributions provenant d'un nombre limité d'événements sensibles. C'est fait
automatiquement par Noise Lab, pour
permettre aux individus de « se cacher dans la foule », ou dans
d'autres termes, protège ces personnes limitées la confidentialité
avec une plus grande quantité
de bruit supplémentaire.
Une valeur de bruit faible indique que la configuration des données a été conçue
une manière qui permet déjà aux individus
de « se cacher dans la foule ». Cela signifie que
les buckets contiennent les contributions d'un nombre suffisant d'événements pour garantir que
la vie privée des
utilisateurs individuels est protégée.
Cette affirmation s'applique à la fois au pourcentage d'erreur moyen (APE)
et RMSRE_T (erreur relative racine carrée du carré avec un seuil).
APE (erreur en pourcentage moyen)
L'APE correspond au ratio entre le bruit et le signal, à savoir la valeur récapitulative réelle.p>
Des valeurs APE plus faibles signifient de meilleurs rapports signal/bruit.
Formule
Pour un rapport récapitulatif donné, l'APE est calculé comme suit:
<ph type="x-smartling-placeholder"></ph>
L'équation pour APE. Des valeurs absolues sont obligatoires, car le bruit peut être négatif.
True est la véritable valeur de résumé. L'APE correspond à la moyenne du bruit sur chaque
valeur récapitulative réelle, moyenne calculée à partir de toutes les entrées d'un rapport récapitulatif.
Dans Noise Lab, ce chiffre est ensuite multiplié par 100 pour obtenir un pourcentage.
Avantages et inconvénients
Les buckets de plus petite taille ont un impact disproportionné sur la valeur finale de l'APE. Cela pourrait être trompeur lors de l'évaluation du bruit. C'est pourquoi nous avons ajouté une autre métrique, RMSRE_T, afin d'atténuer cette limitation de l'APE. Consultez les exemples pour en savoir plus.
RMSRE_T (erreur relative racine carrée de l'erreur quadratique moyenne avec un seuil)
La RMSRE_T (racine-moyenne quadratique relative avec un seuil) est une autre mesure du bruit.
Interpréter RMSRE_T
Des valeurs RMSRE_T plus faibles signifient de meilleurs rapports signal/bruit.
Par exemple, si un rapport de bruit acceptable pour votre cas d'utilisation est de 20 % et que la valeur RMSRE_T est de 0,2, vous pouvez être sûr que les niveaux de bruit se situent dans votre plage acceptable.
Formule
Pour un rapport récapitulatif donné, le RMSRE_T est calculé comme suit:
<ph type="x-smartling-placeholder"></ph>
L'équation pour RMSRE_T. Des valeurs absolues sont obligatoires, car le bruit peut être négatif.
Avantages et inconvénients
RMSRE_T est un peu plus complexe à comprendre qu'APE. Cependant, il présente quelques avantages qui en font, dans certains cas, plus adapté que l'APE pour analyser le bruit dans les rapports récapitulatifs:
RMSRE_T est plus stable. "M" est un seuil. "M" permet d'accorder moins de poids dans le calcul RMSRE_T aux buckets qui enregistrent moins de conversions et qui sont donc plus sensibles au bruit en raison de leur petite taille. Avec l'indicateur T, la métrique n'augmente pas sur les buckets avec peu de conversions. Si T est égal à 5, une valeur de bruit aussi faible que 1 sur un ensemble contenant 0 conversion ne sera pas affichée comme étant supérieure à 1. Au lieu de cela, il sera plafonné à 0,2, ce qui équivaut à 1/5, puisque T est égal à 5. En donnant moins de poids aux petits buckets, qui sont donc plus sensibles au bruit, cette métrique est plus stable et facilite la comparaison entre deux simulations.
RMSRE_T permet une agrégation facile. Connaître la valeur RMSRE_T de plusieurs buckets, ainsi que leurs décomptes réels, vous permet de calculer le RMSRE_T de leur somme. Cela vous permet également d'optimiser RMSRE_T pour ces valeurs combinées.
Bien que l'agrégation soit possible pour l'APE, la formule est assez compliquée, car elle implique la valeur absolue de la somme des bruits de Laplace. Cela complique l'optimisation de l'APE.
Une DSP ou une société d'évaluation des annonces peut diffuser des milliers de publicités mondiales
clients, couvrant plusieurs secteurs, devises et prix d'achat
potentiels. Cela signifie que la création et la gestion d'une clé d'agrégation
l'annonceur ne sera probablement pas pratique. De plus, il s'agira
il est difficile de choisir une valeur agrégable et un budget d'agrégation maximaux
limiter l'impact du bruit sur ces milliers d'annonceurs mondiaux. À la place,
examinons les scénarios suivants:
Stratégie clé A
Le fournisseur de technologie publicitaire décide de créer et de gérer une clé pour l'ensemble de
publicitaires. Pour tous les annonceurs et toutes les devises, la plage de
Les achats varient des achats de faible volume, haut de gamme, à des achats de volume élevé, bas de gamme
des achats. Vous obtenez la clé suivante:
Clé (plusieurs devises)
Valeur agrégable maximale
5 000 000
Plage de valeur des achats
[120 - 5000000]
Stratégie clé B
Le fournisseur de technologie publicitaire décide de créer et de gérer deux clés pour l'ensemble de
publicitaires. Il décide de séparer les clés par devise. Dans l'ensemble
et toutes les devises, les achats varient d'un volume faible,
les achats haut de gamme aux
achats haut de gamme, bas de gamme. En séparant par devise,
ils créent deux clés:
Clé 1 (USD)
Clé 2 (¥)
Valeur agrégable maximale
40 000 $
5 000 000 ¥
Plage de valeur des achats
[120 – 40 000]
[15 000 - 5 000 000]
Le résultat de la stratégie clé B sera moins bruyant que celui de la stratégie clé A, car
les valeurs monétaires ne sont pas réparties uniformément entre les devises. Par exemple :
examinez la manière dont les achats sont libellés en ¥ et associés aux achats libellés en
le dollar américain altère les données sous-jacentes, ce qui génère du bruit dans la sortie.
Stratégie clé C
Le fournisseur de technologie publicitaire décide de créer et de gérer quatre clés pour l'ensemble
ses clients annonceurs, et les séparer par Devise x Annonceur
secteur:
Clé 1
(USD x annonceurs spécialisés dans la bijouterie haut de gamme)
Clé 2
(¥ x annonceurs de bijoux haut de gamme)
Clé 3
(USD x annonceurs marchands de vêtements)
Clé 4
(¥ x annonceurs marchands de vêtements)
Valeur agrégable maximale
40 000 $
5 000 000 ¥
500 €
65 000 ¥
Plage de valeur des achats
[10 000 – 40 000]
[1 250 000 - 5 000 000]
[120 - 500]
[15 000 – 65 000]
Le résultat de la stratégie clé C sera moins bruyant que celui de la stratégie clé B, car
les valeurs d'achat des annonceurs ne sont pas réparties uniformément entre les annonceurs. Pour
Prenons l'exemple de la façon dont les achats de bijoux haut de gamme coïncident avec les achats
pour les casquettes de base-ball modifie les données sous-jacentes et génère du bruit.
Envisagez de créer des valeurs agrégées maximales partagées et des facteurs de scaling partagés
pour identifier les points communs entre plusieurs annonceurs, afin de réduire le bruit
de sortie. Par exemple, vous pouvez tester différentes stratégies ci-dessous pour
vos annonceurs:
Une stratégie séparée par devise (USD, ¥, CAD, etc.)
Une stratégie séparée par secteur d'activité (assurance, automobile,
Commerce, etc.)
Une stratégie séparée par des plages de valeurs d'achat similaires ([100],
[1 000], [10 000], etc.)
En créant des stratégies clés qui s'articulent autour des points communs des annonceurs, des clés et des
du code correspondant sont plus faciles à gérer, et le rapport signal/bruit devient
plus élevée. Testez différentes stratégies avec différents annonceurs
points d'inflexion permettant de maximiser l'impact du bruit par rapport au code
gestion de la sécurité.
Gestion avancée des anomalies
Prenons l'exemple de deux annonceurs:
Annonceur A:
Sur tous les produits du site de l'annonceur A, le prix d'achat
les possibilités sont comprises entre [$120 - $1,000] , pour une fourchette de $880.
Les prix d'achat sont répartis uniformément sur la gamme de 880 $
sans aucune anomalie en dehors de deux écarts types par rapport au prix d'achat médian.
Annonceur B:
Pour tous les produits du site de l'annonceur B, le prix d'achat
les possibilités sont comprises entre [$120 - $1,000] , pour une fourchette de $880.
Les prix d'achat varient fortement
vers la fourchette de 120 à 500 $,
seulement 5% des achats sont compris entre 500 et 1 000 $.
Étant donné le
exigences concernant le budget des contributions
et la méthodologie avec laquelle le bruit est appliqué aux résultats finaux, l'annonceur B aura, par défaut, un résultat plus bruyant que
L'annonceur A, car il est plus susceptible d'avoir des anomalies
des calculs sous-jacents.
Il est possible de limiter ce risque en configurant une clé spécifique. Tester des stratégies clés
qui aident à gérer les données aberrantes et à répartir plus équitablement les valeurs des achats
sur toute la plage d'achat de la clé.
Pour l'annonceur B, vous pouvez créer deux clés distinctes afin de capturer deux clés différentes
de valeurs d'achat. Dans cet exemple, la technologie publicitaire a remarqué que les anomalies
s'affichent au-dessus de la valeur d'achat de 500 €. Essayez d'implémenter
deux clés distinctes pour
cet annonceur:
Structure clé 1 : clé qui ne capture que les achats effectués entre
compris entre 120 € et 500 € (couvrant environ 95% du volume total des achats).
Structure clé 2: clé ne capturant que les achats supérieurs à 500 $
(couvrant environ 5% du volume total des achats).
La mise en œuvre de cette stratégie clé devrait permettre de mieux gérer le bruit pour l'annonceur B et
afin de maximiser leur utilité
dans les rapports de synthèse. Étant donné le nouveau
plages, la clé A et la clé B devraient maintenant avoir une distribution plus uniforme des données
sur chaque clé
respectivement que pour la clé unique précédente. Cela se traduira par
moins de bruit dans la sortie de chaque clé
que pour la clé précédente.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2023/03/08 (UTC).
[null,null,["Dernière mise à jour le 2023/03/08 (UTC)."],[[["Attribution Reporting uses noise to protect user privacy, requiring strategic report configuration to maximize data utility."],["Key decisions include dimension granularity, key structures, and batching frequency, each impacting the signal-to-noise ratio."],["The Noise Lab tool allows you to simulate different configurations and observe the resulting noise levels for optimization."],["Effective key management, like using multiple keys based on data characteristics, minimizes noise, especially for large platforms."],["Carefully managing outliers through separate keys for outlier ranges further enhances signal-to-noise ratios and data utility."]]],[]]