ノイズとはなにか、どこで付加されるのか、測定の取り組みにどんな影響を及ぼすのかを学びます。
概要レポートは、集計可能レポートの集計結果です。集計可能レポートがコレクタによってバッチ化され、集計サービスによって処理されると、ノイズ(ランダムな量のデータ)が結果の概要レポートに付加されます。ノイズはユーザーのプライバシーを保護するために付加されます。このメカニズムの目標は、差分プライバシーの測定をサポートできるフレームワークを用意することです。
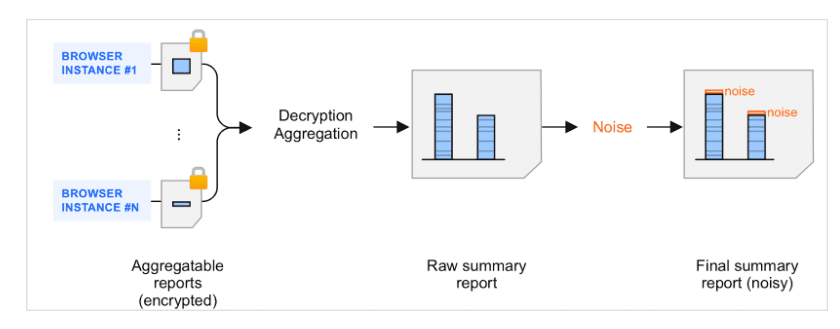
概要レポートにおけるノイズの概要
現在、広告の測定において必ずしもノイズが付加されるわけではありませんが、多くの場合、ノイズを付加したとしても結果の解釈方法が大きく変わることはありません。
次のように考えてみるとわかりやすいかもしれません。あるデータにノイズが付加されていなかったとしても、そのデータに基づいて自信を持って決定を下せるでしょうか?
たとえば、広告主はコンバージョン数がキャンペーン A では 15 件で、キャンペーン B では 16 件だったという事実に基づいて、自信を持ってキャンペーンの戦略や予算を変更できるでしょうか?
もし答えがノーであれば、ノイズは無関係です。
API は次のような方法で使用するように設定する必要があります。
- 上記の質問に対してイエスと答えられる。
- 特定のデータに基づいて意思決定を行う能力に大きな影響が出ないようにノイズを管理する。これは、予想される最低のコンバージョン数に対して収集された指標のノイズをある一定の割合以下に抑えることで達成できます。
ここから先のセクションでは、2 を達成するための戦略について説明します。
基本コンセプト
集計サービスは、概要レポートがリクエストされる度に、それぞれの概要の値に 1 回、つまり鍵ごとに 1 回ノイズを付加します。
これらのノイズ値は、後述する特定の確率分布からランダムに導かれます。
ノイズに影響する要素はすべて、2 つの主要なコンセプトを使用しています。
ノイズ分布(詳細は下記)は概要の値が低くても高くても関係なく同じです。したがって、概要の値が高ければ高いほど、この値に対するノイズの影響は少なくなると考えられます。
たとえば、集計された購入額の合計 $20,000 と、集計された購入額の合計 $200 のどちらにも、同じ分布から選択されたノイズが適用されるとします。
さらに、この分布から導かれるノイズはおよそ -100 から +100 の間で変動するとします。
- 概要の購入額が $20,000 の場合は、ノイズは 0 から 100/20,000=0.5% の間で変動します。
- 概要の購入額が $200 の場合は、ノイズは 0 から 100/200=50% の間で変動します。
したがって、集計された購入額が $20,000 の場合のノイズの影響は、購入額が $200 の場合よりも小さくなると考えられます。相対的に $20,000 の方がノイズが少ない、つまり SN 比が高いといえるでしょう。
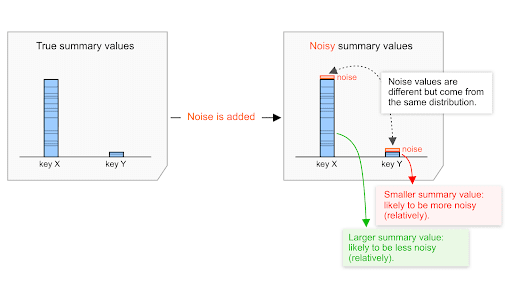
これには実用上の重要な意味があり、この点について次のセクションで説明します。このメカニズムは API の設計に含まれており、実用面でも長期的に関連するものです。広告テクノロジーがさまざまな集計戦略を設計したり評価したりする際に、重要な役割を果たすと思われます。
ノイズは概要の値に関係なく同じ分布から導かれますが、その分布はいくつかのパラメータに基づいています。そのパラメータの一つであるイプシロンは、終了したオリジン トライアルの間に、利便性やプライバシーに関するさまざまな調整を評価するため広告テクノロジーによって変更されている可能性があります。ただ、イプシロンの調整が可能であるのは一時的なものと考えてください。ユースケースやうまく機能するイプシロンの値についてぜひフィードバックをお寄せください。
広告テクノロジー企業はノイズの付加方法を直接制御することはできませんが、測定データのノイズの影響に対して働きかけることはできます。次のセクションでは、実際にどのようにしてノイズに働きかけることができるのかをご紹介します。
その前に、まずはノイズの適用方法について詳しく見ていきましょう。
ズームイン: ノイズの適用方法
1 つのノイズの分布
ノイズはラプラス分布から導かれ、次のパラメータが指定されています。
- 0 の mean(
μ)。これはノイズ値が 0(ノイズが付加されていない)である可能性が最も高いことを意味し、ノイズが付加された値が元の値よりも小さい可能性が、元の値よりも大きい可能性と同じであることを意味します(これは不偏と呼ばれることもあります)。 b = CONTRIBUTION_BUDGET/epsilonのスケール パラメータ。CONTRIBUTION_BUDGETはブラウザで定義されます。epsilonは集計サーバーで固定されます。
次の図は、μ=0、b = 20 であるラプラス分布の確率密度関数を示しています。
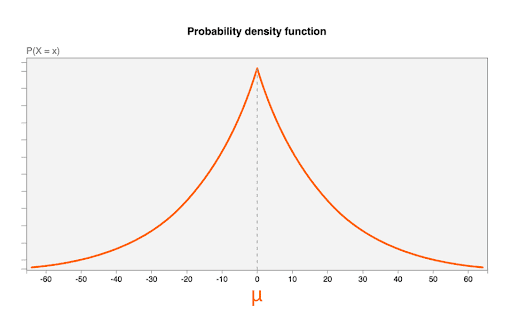
ランダムなノイズ値、1 つのノイズ分布
ある広告テクノロジーが 2 つの集計キー(key1、key2)の概要レポートをリクエストしたとします。
集計サービスは同じノイズ分布に従って 2 つのノイズ値(x1、x2)を選択します。x1 は key1 の概要の値に付加され、x2 は key2 の概要の値に付加されます。
図ではノイズ値を同じとして示しています。これは説明を簡素化するためです、実際にはノイズ値は分布からランダムに導かれるため、それぞれで異なります。
この図は、すべてのノイズ値は同じ分布から導かれ、適用される概要の値からは独立していることを説明したものです。
ノイズのその他のプロパティ
ノイズは、空の値(0)を含むすべての概要の値に適用されます。
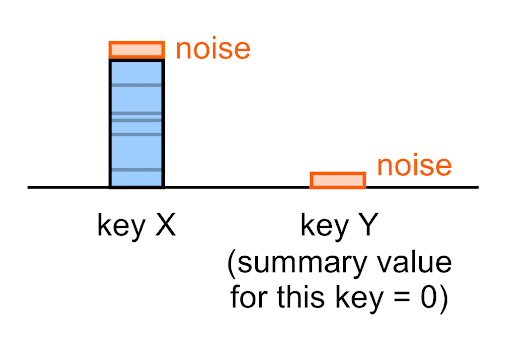
たとえばあるキーの真の概要の値が 0 の場合でも、このキーの概要レポートに表示される、ノイズが付加された概要の値は(ほとんどの場合)0 にはなりません。
ノイズは正の値であることも負の値であることもあります。
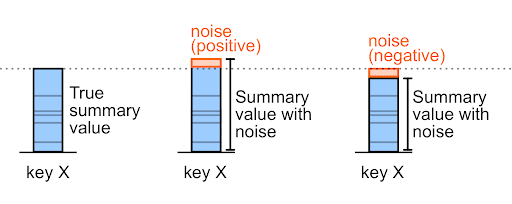
たとえばノイズが付加される前の購入額が 327,000 であった場合、ノイズは +6,000 か -6,000 になる可能性があります(これらは任意の例の値です)。
ノイズの評価
ノイズの標準偏差の計算
ノイズの標準偏差は次のとおりです。
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
例
イプシロン = 10 の場合、ノイズの標準偏差は次のとおりです。
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
測定の差が大きい場合の評価
集計サービスによって出力されたそれぞれの値に付加されたノイズの標準偏差を確認できるので、比較用の適切なしきい値を決定し、確認された差がノイズによるものであるかどうかを判断することができます。
たとえば、値に付加されたノイズがおよそ +/- 10(スケーリングを考慮)であり、2 つのキャンペーンで値に 100 以上の差がある場合、それぞれのキャンペーンで測定された値の差は、ノイズによるものだけではないと考えて問題ないでしょう。
フィードバックを共有
この API に参加して試すことができます。
- 集計可能レポートと集計サービスについて理解し、質問し、フィードバックを提案する。
- アトリビューション レポート ガイド
- プライバシー サンドボックス デベロッパー サポート リポジトリで質問したり、ディスカッションに参加したりできます。
次のステップ
- ノイズの取り扱いを参照し、SN 比を改善するために制御できる変数について確認してください。
- 概要レポートの設計の決定に関するテストを参照し、集計レポート戦略の計画の参考にしてください。
- Noise lab をお試しください。