Najważniejsze pojęcia związane z interfejsem Private Aggregation API
Dla kogo jest przeznaczony ten dokument?
Interfejs Private Aggregation API umożliwia zbieranie danych zbiorczych z workletów z dostępem do danych z wielu witryn. Opisane tu zagadnienia są ważne dla programistów tworzących funkcje raportowania w interfejsie Shared Storage i Protected Audience API.
- Jeśli jesteś programistą i tworzysz system raportowania do pomiarów w wielu witrynach.
- Jeśli jesteś marketerem, analitykiem danych lub innym użytkownikiem raportów zbiorczych, zrozumienie tych mechanizmów pomoże Ci podejmować decyzje projektowe, aby pobierać zoptymalizowane raporty zbiorcze.
Kluczowe terminy
Zanim zaczniesz czytać ten dokument, zapoznaj się z kluczowymi terminami i pojęciami. Poniżej szczegółowo omówimy każdy z tych warunków.
- Klucz agregacji (zwany też zbiorem) to z góry określona kolekcja punktów danych. Możesz na przykład zbierać zbiorczy zestaw danych o lokalizacji, w którym przeglądarka podaje nazwę kraju. Klucz agregacji może zawierać więcej niż 1 wymiar (np. kraj i identyfikator widgeta treści).
- Wartość możliwa do zsumowania to pojedynczy punkt danych zebrany w kluczu agregacji. Jeśli chcesz mierzyć, ilu użytkowników z Francji widziało Twoje treści, wymiar
Francejest wymiarem w kluczu agregacji, a wartośćviewCountw elementach1jest wartością podlegającą agregacji. - Raporty zbiorcze są generowane i szyfrowane w przeglądarce. W przypadku interfejsu Private Aggregation API zawiera on dane o pojedynczym zdarzeniu.
- Usługa agregacji przetwarza dane z raportów, które można agregować, aby utworzyć raport podsumowujący.
- Raport podsumowujący to końcowy wynik usługi agregacji. Zawiera on niespójny zbiorczy zbiór danych o użytkownikach i szczegółowe dane o konwersjach.
- Worklet to element infrastruktury, który umożliwia uruchamianie określonych funkcji JavaScript i zwracanie informacji do osoby, która je zażądała. W ramach workleta możesz wykonywać instrukcje JavaScript, ale nie możesz wchodzić w interakcje z zewnętrzną stroną ani z nią komunikować.
Proces agregacji prywatnej
Gdy wywołasz interfejs Private Aggregation API z kluczem agregacji i wartością podlegającą agregacji, przeglądarka generuje raport podlegający agregacji. Raporty są wysyłane na serwer, który tworzy ich zbiorcze zestawienie. Raporty zbiorcze są później przetwarzane przez usługę agregacji, która generuje raport podsumowujący.
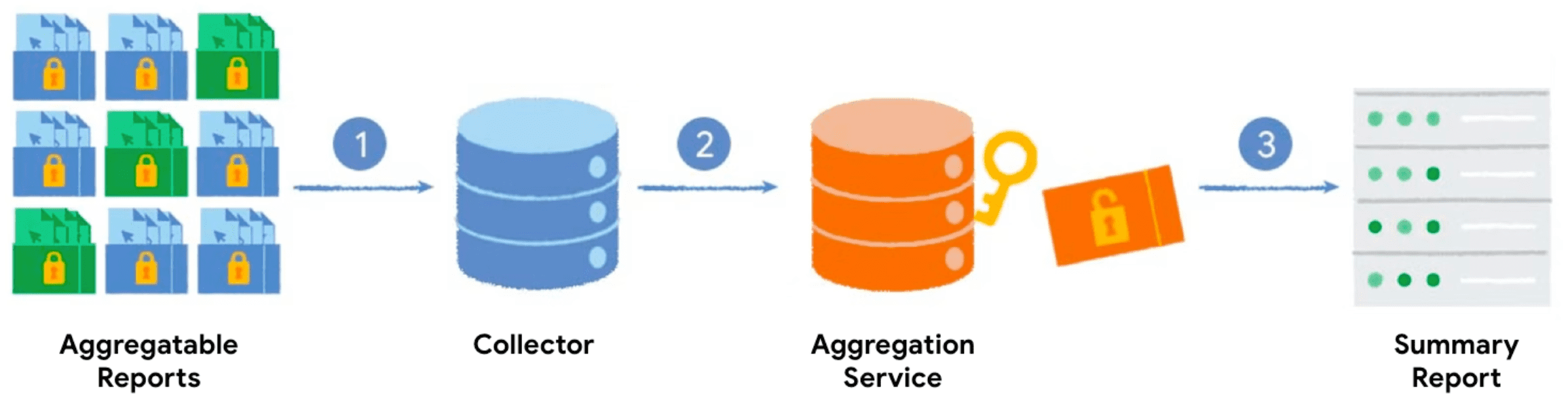
- Gdy wywołasz interfejs Private Aggregation API, klient (przeglądarka) generuje i wysyła do zebrania na serwer raport, który można agregować.
- Twój serwer zbiera raporty od klientów i przesyła je zbiorczo do usługi agregacji.
- Po zebraniu wystarczającej liczby raportów zostaną one zagregowane i przesłane do usługi agregacji działającej w zaufanym środowisku wykonania w celu wygenerowania raportu podsumowania.
Proces opisany w tej sekcji jest podobny do interfejsu Attribution Reporting API. Raportowanie atrybucji łączy jednak dane zebrane ze zdarzenia wyświetlenia i zdarzenia konwersji, które występują w różnych momentach. Prywatna agregacja mierzy pojedyncze zdarzenie między witrynami.
Klucz agregacji
Klucz agregacji (w skrócie „klucz”) reprezentuje zbiór, w którym będą gromadzone wartości podlegające agregacji. W kluczu można zakodować co najmniej 1 wymiar. Wymiar reprezentuje pewien aspekt, na temat którego chcesz uzyskać więcej statystyk, np. grupę wiekową użytkowników lub liczbę wyświetleń w kampanii reklamowej.
Możesz np. mieć widżet umieszczony w kilku witrynach i chcesz analizować kraj użytkowników, którzy go widzieli. Chcesz uzyskać odpowiedzi na pytania w rodzaju „Ilu użytkowników, którzy widzieli mój widget, pochodzi z kraju X?”. Aby tworzyć raporty na podstawie tego pytania, możesz skonfigurować klucz agregacji, który koduje 2 wymiary: identyfikator widżetu i identyfikator kraju.
Klucz przekazany do interfejsu Private Aggregation API to BigInt, który składa się z wielu wymiarów. W tym przykładzie wymiarami są identyfikator widgetu i identyfikator kraju. Załóżmy, że identyfikator widżetu może mieć maksymalnie 4 cyfry, np. 1234, a każdy kraj jest powiązany z numerem w kolejności alfabetycznej, np. Afganistan to 1, Francja to 61, a Zimbabwe to 195.
Dlatego klucz do agregacji będzie miał 7 cyfr, z których pierwsze 4 są zarezerwowane dla WidgetID, a ostatnie 3 dla CountryID.
Załóżmy, że klucz reprezentuje liczbę użytkowników z Francji (identyfikator kraju 061), którzy widzieli widget o identyfikatorze 3276. Klucz agregacji to 3276061.
| Klucz agregacji | |
| Identyfikator widżetu | Identyfikator kraju |
| 3276 | 061 |
Klucz agregacji może być też generowany za pomocą mechanizmu szyfrowania, np. SHA-256. Na przykład ciąg znaków {"WidgetId":3276,"CountryID":67} można zamienić na wartość BigInt, która jest równa 42943797454801331377966796057547478208888578253058197330928948081739249096287n.
Jeśli wartość funkcji szyfrującej ma więcej niż 128 bitów, możesz ją obciąć, aby nie przekraczała maksymalnej dozwolonej wartości zbiornika, która wynosi 2^128−1.
W ramach modułu Shared Storage możesz uzyskać dostęp do modułów crypto i TextEncoder, które pomogą Ci wygenerować hasz. Więcej informacji o generowaniu hasha znajdziesz w SubtleCrypto.digest() na stronie MDN.
Z przykładu poniżej dowiesz się, jak wygenerować klucz zasobnika na podstawie wartości zaszyfrowanej:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Wartość możliwa do zsumowania
Wartości, które można zliczać, są sumowane według klucza dla wielu użytkowników, aby generować zbiorcze statystyki w postaci wartości podsumowania w raportach podsumowań.
Wróć teraz do przykładowego pytania, które zostało zadane wcześniej: „Ilu użytkowników, którzy widzieli mój widget, pochodzi z Francji?”. Odpowiedź na to pytanie będzie wyglądać mniej więcej tak: „Około 4881 użytkowników, którzy widzieli mój widget o identyfikatorze 3276, pochodzi z Francji”. Wartość agregowalna wynosi 1 dla każdego użytkownika, a „4881 użytkowników” to wartość zagregowana, która jest sumą wszystkich wartości agregowalnych dla tego klucza agregacji.
| Klucz agregacji | Wartość możliwa do zsumowania | |
| Identyfikator widżetu | Identyfikator kraju | Liczba wyświetleń |
| 3276 | 061 | 1 |
W tym przykładzie zwiększamy wartość o 1 w przypadku każdego użytkownika, który widzi widżet. W praktyce wartość możliwa do zsumowania może być skalowana w celu poprawy stosunku sygnału do szumu.
Budżet na udział
Każde wywołanie interfejsu Private Aggregation API jest nazywane wkładem. Aby chronić prywatność użytkowników, liczba wkładów, które można zebrać od danej osoby, jest ograniczona.
Gdy zsumujesz wszystkie wartości podlegające agregacji we wszystkich kluczach agregacji, suma musi być mniejsza od budżetu udziału. Budżet jest ograniczony do origin workletu i dobowego okresu rozliczeniowego. Jest oddzielny dla workletów Protected Audience API i Shared Storage. Do określania dnia używa się przesuwanego okna obejmującego około 24 godziny. Jeśli nowy raport możliwy do zsumowania spowodowałby przekroczenie budżetu, nie zostanie on utworzony.
Budżet na udział jest reprezentowany przez parametr L1 i jest ustawiony na 216 (65 536) na 10 minut dziennie z zabezpieczeniem 220 (1 048 576). Więcej informacji o tych parametrach znajdziesz w tym artykule.
Wartość budżetu na udział jest dowolna, ale szum jest do niej dostosowywany. Możesz użyć tego budżetu, aby zmaksymalizować stosunek sygnału do szumu w przypadku wartości podanych w podsumowaniu (omówiony w sekcji Szum i skalowanie).
Więcej informacji o budżetach na udział znajdziesz w tym artykule. Więcej wskazówek znajdziesz też w budżecie na wkłady.
Limit publikowanych treści na raport
W zależności od dzwoniącego limit wpłat może się różnić. Obecnie raporty generowane przez wywołujących interfejs API Shared Storage są ograniczone do 20 współtworzonych danych na raport. Z drugiej strony, w przypadku wywołań interfejsu Protected Audience API obowiązuje limit 100 dostaw na raport. Te limity zostały wybrane, aby zachować równowagę między liczbą wkładów, które można osadzić, a rozmiarem ładunku.
W przypadku współdzielonego miejsca na dane w raportach zbiorczych są uwzględniane dane z pojedynczej operacji run() lub selectURL(). W przypadku Protected Audience udziały w aukcji pochodzące z pojedynczego źródła są grupowane.
Wkłady z wypełnieniem
Wkłady są dodatkowo modyfikowane za pomocą funkcji wypełniania. Dodanie danych do ładunku zabezpiecza informacje o rzeczywistej liczbie wkładów zawartych w raporcie możliwym do zsumowania. Wypełnienie zwiększa ładunek o wartości null (czyli o wartość 0), aby osiągnąć stałą długość.
Raporty zbiorcze
Gdy użytkownik wywoła interfejs Private Aggregation API, przeglądarka wygeneruje raporty podlegające agregacji, które zostaną przetworzone przez usługę agregacji w późniejszym czasie, aby wygenerować raporty zbiorcze. Raport możliwy do zsumowania jest w formacie JSON i zawiera zaszyfrowaną listę udziałów, z których każdy jest parą {aggregation key, aggregatable value}.
Raporty podlegające agregacji są wysyłane z losowym opóźnieniem do 1 godziny.
Dane są zaszyfrowane i nieczytelne poza usługą agregacji. Usługa agregacji odszyfrowuje raporty i generuje raport podsumowujący. Klucz szyfrowania przeglądarki i klucz odszyfrowywania usługi agregacji są wydawane przez koordynatora, który pełni rolę usługi zarządzania kluczami. Koordynator przechowuje listę haszy binarnych obrazu usługi, aby sprawdzić, czy wywołujący ma uprawnienia do otrzymania klucza odszyfrowywania.
Przykład raportu podlegającego agregacji z włączonym trybem debugowania:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Raporty zbiorcze można przeglądać na stronie chrome://private-aggregation-internals:

W celu przetestowania możesz użyć przycisku „Wyślij wybrane raporty”, aby natychmiast wysłać raport na serwer.
Zbieranie i grupowanie raportów możliwych do zagregowania
Przeglądarka wysyła raporty podlegające agregacji do źródła workleta zawierającego wywołanie interfejsu Private Aggregation API, korzystając z poniżej wymienionej dobrze znanej ścieżki:
- W przypadku Shared Storage:
/.well-known/private-aggregation/report-shared-storage - W przypadku listy Protected Audience:
/.well-known/private-aggregation/report-protected-audience
W przypadku tych punktów końcowych musisz obsługiwać serwer działający jako kolektor, który odbiera raporty nadawane przez klientów i umożliwiające ich agregację.
Następnie serwer powinien grupować raporty i przesyłać je do usługi agregacji. Tworzenie partii na podstawie informacji dostępnych w niezaszyfrowanym ładunku raportu podlegającego agregacji, np. pola shared_info. W idealnej sytuacji partie powinny zawierać co najmniej 100 raportów.
Możesz tworzyć partie codziennie lub co tydzień. Ta strategia jest elastyczna i możesz zmienić strategię grupowania na potrzeby konkretnych wydarzeń, w których przypadku spodziewasz się większego wolumenu, np. w okresie, w którym zwykle występuje więcej wyświetleń. Partie powinny zawierać raporty z tej samej wersji interfejsu API, z tego samego źródła raportowania i o tym samym czasie zaplanowanego raportu.
Filtrowanie identyfikatorów
Interfejs API prywatnego agregatora i usługa agregacji umożliwiają użycie filtrowania identyfikatorów do przetwarzania pomiarów na bardziej szczegółowym poziomie, np. według kampanii reklamowej, zamiast przetwarzania wyników w większych zapytaniach.

Aby zacząć korzystać z tych funkcji już dziś, wykonaj te czynności w ramach swojej obecnej implementacji.
Kroki dotyczące pamięci współdzielonej
Jeśli w swoim procesie używasz interfejsu Shared Storage API:
Określ, gdzie chcesz zadeklarować i uruchamiać nowy moduł pamięci współdzielonej. W tym przykładzie plik modułu ma nazwę
filtering-worklet.js, zarejestrowaną pod nazwąfiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();Pamiętaj, że parametr
filteringIdMaxBytesmożna konfigurować w poszczególnych raportach, a jeśli nie jest ustawiony, jego domyślna wartość to 1. Ta domyślna wartość ma zapobiec niepotrzebnemu zwiększaniu rozmiaru ładunku, a tym samym kosztom przechowywania i przetwarzania. Więcej informacji znajdziesz w artykule wyjaśniającym elastyczne wpłaty.W pliku, którego użyliśmy powyżej (w tym przypadku
filtering-worklet.js), gdy przekazujesz dane do funkcjiprivateAggregation.contributeToHistogram(...)w ramach modułu Shared Storage, możesz podać identyfikator filtrowania.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Raporty zbiorcze będą wysyłane na adres zdefiniowany przez Ciebie jako punkt końcowy
/.well-known/private-aggregation/report-shared-storage. Aby dowiedzieć się więcej o zmianach wymaganych w parametrach zlecenia usługi Aggregation Service, przejdź do przewodnika po filtrowaniu identyfikatorów.
Po zakończeniu grupowania i przesłaniu danych do zaimplementowanej usługi agregacji zfiltrowane wyniki powinny być widoczne w końcowym raporcie podsumowania.
Protected Audience API
Jeśli w swojej ścieżce korzystasz z interfejsu Protected Audience API:
W ramach obecnej implementacji chronionych list odbiorców możesz skonfigurować te ustawienia, aby połączyć je z prywatną agregacją. W przeciwieństwie do pamięci współdzielonej nie można jeszcze skonfigurować maksymalnego rozmiaru identyfikatora filtrowania. Domyślnie maksymalny rozmiar identyfikatora filtrowania to 1 bajt i zostanie ustawiony na
0n. Pamiętaj, że te wartości są ustawiane w funkcjach raportowania Protected Audience API (np.reportResult()lubgenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Raporty zbiorcze będą wysyłane na adres zdefiniowany przez Ciebie jako punkt końcowy
/.well-known/private-aggregation/report-protected-audience. Po zakończeniu grupowania i przesłaniu danych do zaimplementowanej usługi agregacji zfiltrowane wyniki powinny być widoczne w końcowym raporcie podsumowania. Dostępne są te objaśnienia dotyczące interfejsów Attribution Reporting API i Private Aggregation API, a także początkowa propozycja.
Aby uzyskać więcej informacji, zapoznaj się z przewodnikiem po filtrowaniu identyfikatorów w usłudze agregacji lub przejdź do sekcji interfejsu Attribution Reporting API.
Usługa do agregacji
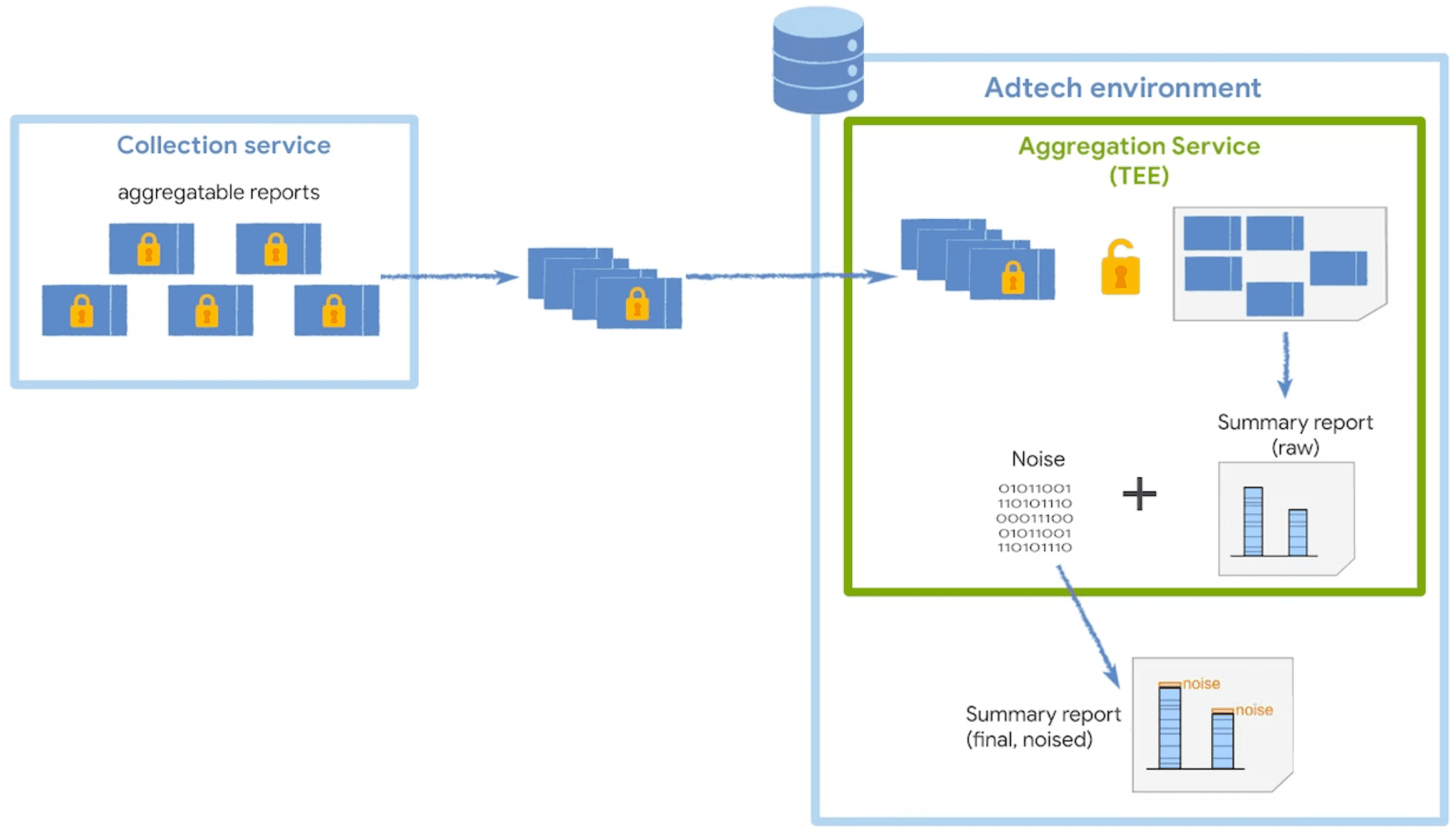
Usługa agregacji otrzymuje zaszyfrowane raporty podlegające agregacji od kolektora i generuje raporty podsumowujące. Więcej informacji o strategiach zbiorczego agregowania raportów w Twoim kolektorze znajdziesz w przewodniku dotyczącym zbiorczego agregowania raportów.
Usługa działa w zaufanym środowisku wykonawczym (TEE), co zapewnia pewien poziom integralności danych, poufności danych i integralności kodu. Jeśli chcesz dowiedzieć się więcej o tym, jak koordynatorzy są używani w połączeniu z TEE, przeczytaj więcej o ich roli i celu.
Raporty podsumowujące
Raporty podsumowujące pozwalają wyświetlić zebrane dane z dodatkowym hałasem. Możesz poprosić o raporty podsumowania dotyczące danego zbioru kluczy.
Raport podsumowania zawiera zestaw par klucz-wartość w formie słownika JSON. Każda para zawiera:
bucket: klucz agregacji pod postacią ciągu liczby binarnej. Jeśli użyty klucz agregacji to „123”, to grupa to „1111011”.value: wartość zbiorcza dla danego celu pomiaru, zsumowana z wszystkich dostępnych raportów możliwych do agregacji z dodatkiem szumu.
Na przykład:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Szum i skalowanie
Aby chronić prywatność użytkowników, usługa agregacji dodaje szum do każdej wartości podsumowania za każdym razem, gdy zostanie wysłane żądanie raportu podsumowania. Wartości szumu są losowo pobierane z rozkładu prawdopodobieństwa Laplace’a. Chociaż nie masz bezpośredniej kontroli nad sposobem dodawania szumu, możesz wpływać na wpływ szumu na dane pomiarowe.
Rozkład szumu jest taki sam niezależnie od sumy wszystkich wartości możliwych do zgrupowania. Dlatego im wyższe wartości można zsumować, tym mniejszy wpływ będzie miał szum.
Załóżmy na przykład, że rozkład szumu ma odchylenie standardowe 100 i jest wyśrodkowany na zero. Jeśli zebrana wartość raportu możliwa do agregacji (czyli „wartość możliwa do agregacji”) wynosi tylko 200, odchylenie standardowe szumu będzie równe 50% wartości zagregowanej. Jeśli jednak wartość podlegająca agregacji wynosi 20 tys., odchylenie standardowe szumu będzie stanowić tylko 0,5% wartości zagregowanej. Dlatego wartość agregowana 20 tys. będzie miała znacznie wyższy stosunek sygnału do szumu.
Dlatego mnożenie wartości agregowanej przez współczynnik skalowania może pomóc w zredukowaniu szumu. Współczynnik skalowania określa, jak bardzo chcesz skalować daną wartość agregowalną.

Przeskalowywanie wartości przez wybranie większego współczynnika skalowania zmniejsza względny szum. Spowoduje to jednak, że suma wszystkich wkładów we wszystkich zbiornikach szybciej osiągnie limit budżetu na wkłady. Obniżenie wartości przez wybranie mniejszej stałej skalowania zwiększa względny szum, ale zmniejsza ryzyko osiągnięcia limitu budżetu.
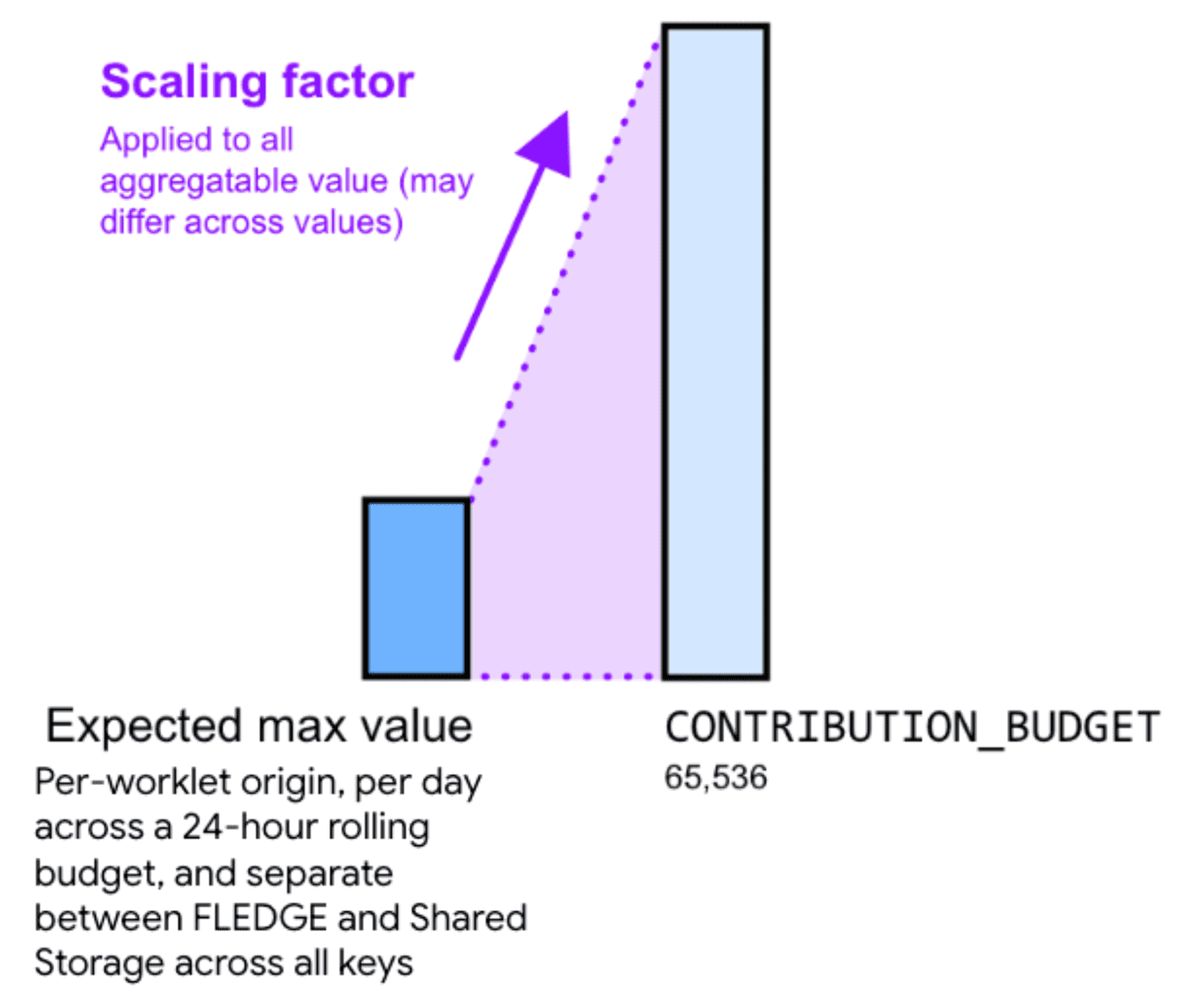
Aby obliczyć odpowiedni współczynnik skalowania, podziel budżet na potrzeby udziału przez maksymalną sumę wartości możliwych do zsumowania we wszystkich kluczach.
Więcej informacji znajdziesz w dokumentacji dotyczącej budżetu na wkłady.
Angażowanie użytkowników i przesyłanie opinii
Interfejs Private Aggregation API jest obecnie przedmiotem dyskusji i może ulec zmianie w przyszłości. Jeśli wypróbujesz ten interfejs API i masz opinię na jego temat, chętnie ją poznamy.
- GitHub przeczytaj informacje, zadawaj pytania i uczestnicz w dyskusji.
- Pomoc dla deweloperów: zadawaj pytania i ucz się na podstawie dyskusji w repozytorium Piaskownicy prywatności dla deweloperów.
- Dołącz do grupy Storage API i Protected Audience API, aby otrzymywać najnowsze ogłoszenia dotyczące prywatnej agregacji.