Le service d'agrégation génère des rapports récapitulatifs contenant des données de conversion détaillées et des mesures de couverture à partir de rapports bruts agrégables. Les technologies publicitaires disposent de deux principaux points d'entrée agrégés côté client pour acheminer les rapports vers le service d'agrégation, via l'API Attribution Reporting ou l'API Private Aggregation.
État de l'implémentation
- Le service d'agrégation est désormais en disponibilité générale.
- Le service d'agrégation peut être utilisé avec l'API Attribution Reporting et l'API Private Aggregation pour l'API Protected Audience et l'API Shared Storage.
Disponibilité
| 提案 | 状态 |
|---|---|
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 跨 Attribution Reporting API、Private Aggregation API 为 Google Cloud 提供汇总服务支持 说明文档 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。若要汇总多个源站,这些源站必须属于同一个网站。
GitHub 上的常见问题解答 网站汇总 API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持一个不超过 64 的范围,以方便对不同参数的实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小数值反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知整个生态系统。 |
| 为汇总服务查询提供更灵活的贡献过滤功能
解说 |
可用 |
| 灾难后(错误、配置错误等)的预算恢复流程
解说 |
提供 机制,用于审核广告技术平台使用预算挽回功能找回的共享 ID 所占百分比,以及针对 2025 年上半年计划恢复的过多账号恢复请求暂停未来恢复机制 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 担任 Google Cloud 协调员之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
Termes et concepts clés
Si vous envisagez d'utiliser le service d'agrégation dans votre workflow de technologie publicitaire, les termes et concepts suivants devraient vous en dire plus sur ce que ce nouveau flux d'agrégation peut apporter à votre équipe :
| Terme | Description |
|---|---|
| Service d'agrégation | Service géré par une technologie publicitaire qui traite les rapports agrégables pour créer un rapport récapitulatif. |
| Rapports agrégables |
Les rapports agrégables sont des rapports chiffrés envoyés depuis les appareils des utilisateurs. Ces rapports contiennent des données sur le comportement et les conversions des utilisateurs sur plusieurs sites. Les conversions (parfois appelées événements déclencheurs d'attribution) et les métriques associées sont définies par l'annonceur ou la technologie publicitaire. Chaque rapport est chiffré pour empêcher plusieurs parties d'accéder aux données sous-jacentes. En savoir plus sur les rapports agrégables |
| Comptabilité des rapports agrégables | Un grand livre distribué situé dans les deux coordinateurs qui suit le budget de confidentialité alloué et applique la règle "Pas de doublons". Il s'agit du mécanisme de protection de la confidentialité, situé et exécuté dans les coordinateurs, qui garantit qu'aucun rapport ne passe par le service d'agrégation au-delà du budget de confidentialité alloué. En savoir plus sur les stratégies de traitement par lot en lien avec les rapports agrégables |
| Budget comptable des rapports agrégables | Références au budget qui garantissent que les rapports ne sont pas traités plusieurs fois. |
| Environnement d'exécution sécurisé (TEE) |
Un environnement d'exécution fiable est une configuration spéciale de matériel et de logiciels informatiques qui permet tiers pour vérifier les versions exactes des logiciels qui fonctionnent sur l’ordinateur. Les TEE permettent aux parties externes de vérifier que le logiciel fait exactement ce que le fabricant affirme qu'il fait, ni plus ni moins. Pour en savoir plus sur les TEE utilisés pour les propositions de la Privacy Sandbox, consultez les Explication des services de l'API Protected Audience et la présentation du service d'agrégation. |
| Coordinateurs |
Un coordinateur est une entité responsable de la gestion des clés et de la comptabilisation des rapports agrégables. Le coordinateur conserve une liste de hachages des configurations de services d'agrégation approuvées et configure l'accès aux clés de déchiffrement. |
| ID partagé |
Valeur calculée composée de : shared_info, reporting_origin, destination_site (disponible pour l'API Attribution Reporting uniquement), source_registration-time (disponible pour l'API Attribution Reporting uniquement), scheduled_report_time et version.
Cela signifie que plusieurs rapports appartiennent au même ID partagé s'ils partagent les mêmes attributs du champ shared_info. Cela joue un rôle important dans la traçabilité des rapports agrégables.
En savoir plus sur les serveurs approuvés
|
| Rapport récapitulatif |
摘要报告是一种 Attribution Reporting API 和 Private Aggregation API 报告类型。摘要报告包含汇总的用户数据,并且可能包含添加了噪声的详细转化数据。摘要报告由汇总报告组成。与事件级报告相比,摘要报告具有更大的灵活性和数据模型,尤其是对于某些应用场景(例如转化价值)。 |
| Origine du signalement |
L'origine des rapports est l'entité qui reçoit les rapports agrégables. En d'autres termes, la technologie publicitaire qui a appelé l'API Attribution Reporting. Les rapports agrégables sont envoyés depuis les appareils des utilisateurs vers une URL connue associée à l'origine des rapports. Cette origine de création de rapports doit être désignée lors de l'inscription. |
| Engagement de contribution | Les rapports cumulables peuvent contenir un nombre arbitraire d'incréments de compteur. Par exemple, un rapport peut contenir le nombre de produits qu'un utilisateur a consultés sur le site d'un annonceur. La somme des incréments de tous les rapports agrégables liés à un seul événement source ne doit pas dépasser une limite donnée, "L1=2^16". En savoir plus sur les rapports agrégables |
| Bruit et Scaling | Une certaine quantité de bruit statistique est ajoutée aux rapports récapitulatifs dans le cadre du processus d'agrégation, qui sert également à préserver la confidentialité et à s'assurer que les rapports finaux fournissent des informations de mesure anonymisées. En savoir plus sur le mécanisme du bruit additif, issu de la distribution de Laplace |
| Attestation |
L'attestation est un mécanisme permettant d'authentifier l'identité logicielle, généralement au moyen de hachages cryptographiques ou de signatures. Pour la proposition de service d'agrégation, l'attestation fait correspondre le code exécuté dans le service d'agrégation géré par une technologie publicitaire avec le code Open Source. En savoir plus sur l'attestation |
Pour en savoir plus sur l'histoire du service d'agrégation, consultez notre explication et la liste complète des conditions d'utilisation.
Cas d'utilisation de l'agrégation
Examinez les parcours de développement suivants pour la mesure des annonces et les bibliothèques clientes de mesure correspondantes.
| Cas d'utilisation | Point d'entrée | Description |
|---|---|---|
| Optimisation des enchères | API Attribution Reporting (Chrome et Android) | Utilisez des rapports agrégés pour ingérer les signaux de conversion afin d'optimiser les enchères. |
| Mesures multiplates-formes | API Attribution Reporting (Chrome et Android) | Utilisez les fonctionnalités de mesure multi-applications et Web pour obtenir une visibilité sur les performances sur Chrome et Android. |
| Rapports sur les conversions | API Attribution Reporting (Chrome et Android) | Créez des rapports de conversion agrégables adaptés aux besoins des campagnes des clients (y compris les conversions après clic et les conversions après visionnage). |
| Mesure de la couverture de la campagne | API Shared Storage et API Private Aggregation (Chrome) | Utiliser des variables intersites pour les visionnages d'annonces afin de mesurer la couverture de la campagne. |
| Rapports démographiques | API Shared Storage et API Private Aggregation (Chrome) | Utilisez les données sur les vues d'annonces intersites et les données démographiques pour mesurer la couverture par catégorie démographique. |
| Analyse des chemins de conversion | API Shared Storage et API Private Aggregation (Chrome) | Stockez les variables de visionnage d'annonces et de conversion entre sites pour effectuer une analyse agrégée du chemin de conversion. |
| Brand lift et conversion lift | API Shared Storage et API Private Aggregation (Chrome) | Rapports sur les groupes de test/contrôle et informations de sondage pour mesurer le brand lift et l'incrémentalité |
| Débogage des enchères | API Protected Audience et API Private Aggregation (Chrome) | Utilisez des rapports agrégés pour le débogage. |
| Répartition des enchères | API Protected Audience et API Private Aggregation (Chrome) | Utilisez des rapports agrégés pour capturer la répartition des valeurs des enchères lors des mises aux enchères. |
Flux de bout en bout
Le schéma suivant illustre le service d'agrégation en action. Nous allons nous concentrer sur le flux de bout en bout, de la réception des rapports depuis le Web et le mobile à la création des rapports récapitulatifs dans le service d'agrégation.
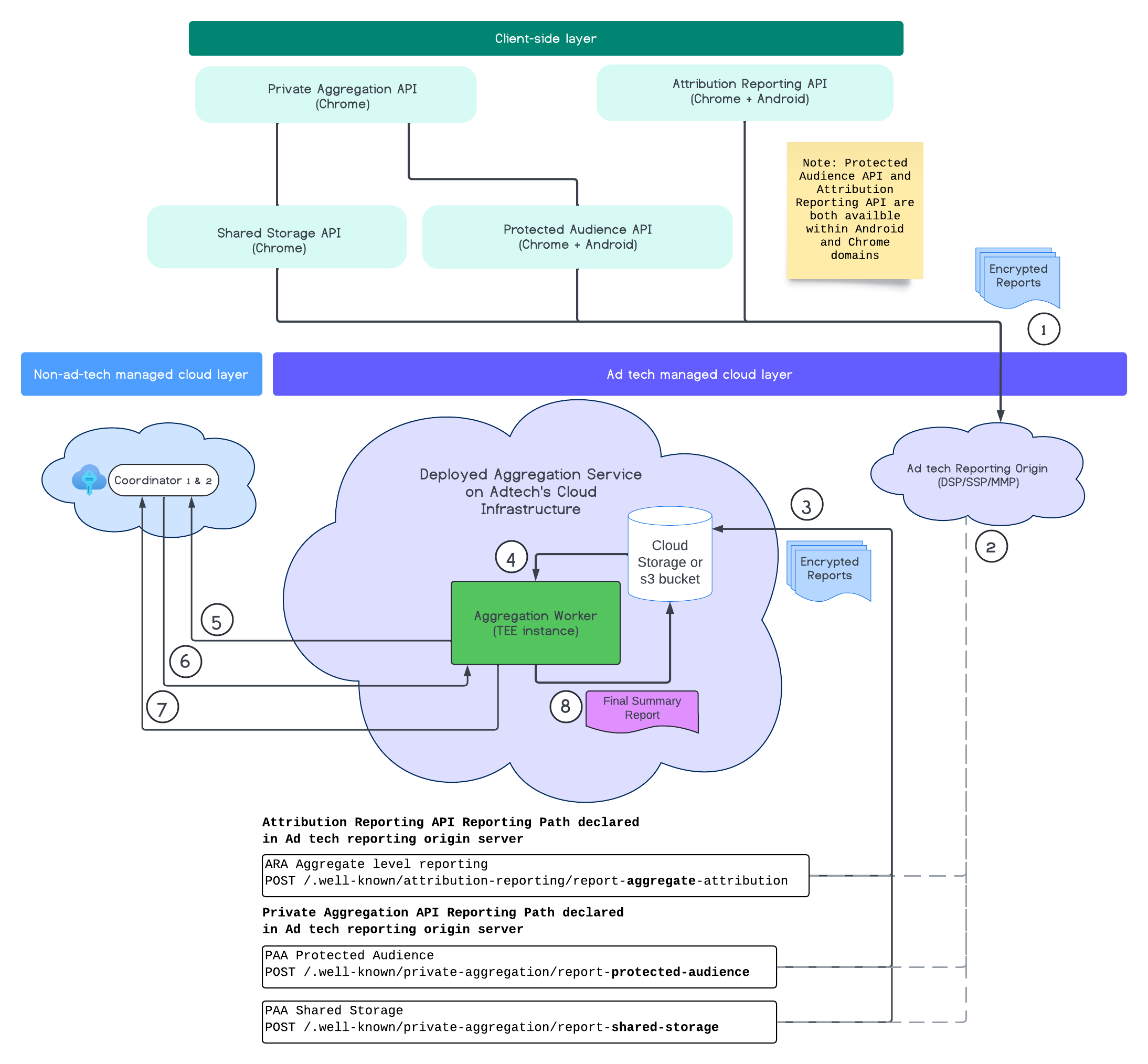
- Récupérez la clé publique pour générer des rapports chiffrés.
- Rapports agrégables chiffrés envoyés aux serveurs de technologie publicitaire pour être collectés, transformés et regroupés.
- Le serveur de technologie publicitaire regroupe les rapports par lot (au format Avro) et les envoie au service d'agrégation déployé. (doit être effectué par la technologie publicitaire).
- Récupérez les rapports agrégés à déchiffrer.
- Récupérer les clés de déchiffrement auprès des coordinateurs
- Le service d'agrégation déchiffre les rapports pour l'agrégation et le bruitage.
- Le service de comptabilité des rapports agrégables vérifie s'il reste un budget de confidentialité pour générer un rapport récapitulatif pour les rapports agrégables donnés.
- Envoyez le rapport récapitulatif final.
Le diagramme montre la relation globale du service d'agrégation avec les principales API de mesure client, à savoir l'API Attribution Reporting, l'API Private Aggregation et les coordinateurs.
Le flux commence par différentes API de mesure, comme l'API Attribution Reporting ou l'API Private Aggregation, qui génèrent des rapports à partir de plusieurs instances de navigateur. Chrome utilise la clé publique du service d'hébergement de clés du coordinateur pour chiffrer les rapports avant qu'ils ne soient envoyés à l'origine de création de rapports de la technologie publicitaire. Les clés publiques sont alternées tous les sept jours.
Une fois que l'origine des rapports de la technologie publicitaire a reçu ces rapports, elle doit être configurée pour les collecter et les convertir au format Avro, puis les envoyer à l'instance de service d'agrégation déployée. Découvrez les stratégies de traitement par lots.
Une fois que la technologie publicitaire est prête à effectuer un traitement par lot, elle crée une requête par lot au service d'agrégation, où les rapports sont déchiffrés en récupérant les clés de déchiffrement du service d'hébergement de clés, puis agrégés et masqués pour créer un rapport récapitulatif. N'oubliez pas que cela dépend du budget de confidentialité disponible pour générer les rapports récapitulatifs finaux.
Le point de terminaison de l'origine des rapports de la technologie publicitaire où les rapports sont collectés est hébergé par la technologie publicitaire, et le service d'agrégation est déployé dans le cloud de la technologie publicitaire.
Traitement par lot des rapports agrégables
Le flux de création de rapports ne serait pas complet sans l'aide du serveur d'origine des rapports désigné. Il s'agit de l'origine qu'une technologie publicitaire aurait envoyée lors du processus d'enregistrement. Les principales actions de l'origine des rapports seraient la collecte, la transformation et le traitement par lot des rapports agrégables reçus, puis leur préparation pour qu'ils soient envoyés au service d'agrégation déployé de la technologie publicitaire dans Google Cloud ou Amazon Web Services. Découvrez comment préparer vos rapports agrégables.
Maintenant que vous connaissez le concept général, examinons de plus près les composants qui seront déployés dans votre service d'agrégation.
Composants Cloud
Le service d'agrégation se compose de différents composants de service cloud. Les scripts Terraform fournis provisionnent et configurent tous les composants de service cloud nécessaires.
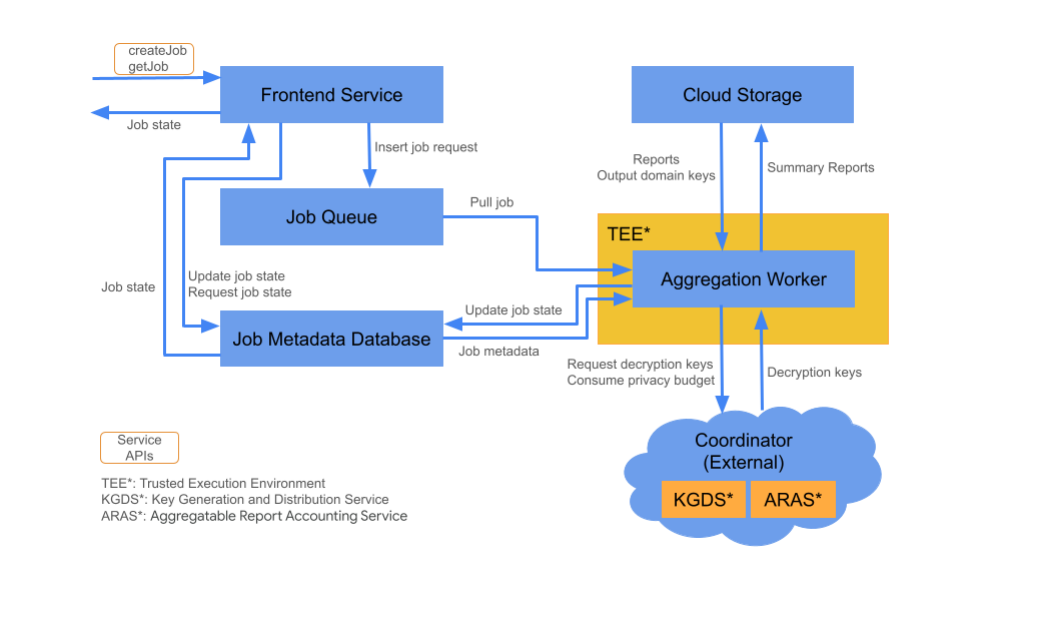
Service frontend
Service cloud géré : Cloud Function (Google Cloud)/API Gateway (Amazon Web Services)
Le service d'interface est une passerelle sans serveur qui sert de point d'entrée aux appels d'API Aggregation pour la création de tâches et la récupération de l'état des tâches. Il est chargé de recevoir les requêtes des utilisateurs du service d'agrégation, de valider les paramètres d'entrée et de lancer le processus de planification des jobs d'agrégation.
Deux API sont disponibles dans le service d'interface:
| Point de terminaison | Description |
|---|---|
createJob |
Cette API déclenche un job de service d'agrégation. Pour déclencher une tâche, il a besoin d'informations telles que l'ID de la tâche, les informations sur l'espace de stockage en entrée et l'espace de stockage en sortie, l'origine des rapports, etc. |
getJob |
Cette API renvoie l'état d'une tâche pour un ID de tâche spécifié. Elle fournit des informations sur l'état du projet, telles que "Reçu", "En cours" ou "Terminé". De plus, si le job est terminé, son résultat s'affiche, y compris les messages d'erreur rencontrés lors de son exécution. |
Consultez la documentation de l'API du service d'agrégation.
File d'attente de tâches
Service cloud géré:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
La file d'attente de tâches est une file de messages qui stocke les requêtes de tâches pour le service d'agrégation. Le service de front-end insère des messages de requête de tâche dans la file d'attente, qui sont ensuite consommés par le nœud de calcul d'agrégation pour traiter la requête de tâche.
Cloud Storage
Service cloud géré:Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) Le stockage cloud est utilisé pour stocker les fichiers d'entrée et de sortie utilisés par le service d'agrégation (exemples: fichiers de rapports chiffrés, rapports récapitulatifs de sortie, etc.).
Base de données de métadonnées de tâche
Service cloud géré : Spanner (Google Cloud)/DynamoDB (Amazon Web Services)
La base de données de métadonnées de tâche stocke et suit l'état des tâches d'agrégation. La base de données enregistre des métadonnées telles que l'heure de création, l'heure demandée, l'heure de mise à jour et l'état (exemples: Reçu, En cours, Terminé, etc.). Le nœud de calcul d'agrégation met à jour la base de données de métadonnées de la tâche au fur et à mesure de sa progression.
Nœud de calcul d'agrégation
Service cloud géré : Compute Engine avec espace confidentiel (Google Cloud)/Amazon Web Services EC2 avec Nitro Enclave (Amazon Web Services)
Le nœud de calcul d'agrégation traite les requêtes de tâche initiées par une requête de tâche dans la file d'attente de tâches, en déchiffrer les entrées chiffrées à l'aide de clés extraites du service de génération et de distribution de clés (KGDS) dans Coordinators. Pour réduire la latence de traitement des tâches, les clés de déchiffrement sont mises en cache dans le nœud de calcul d'agrégation pendant huit heures. Elles peuvent être utilisées pour toutes les tâches traitées par cette instance de nœud de calcul.
Le nœud de calcul opère au sein d'une instance d'environnement d'exécution sécurisé (TEE). Chaque nœud de calcul ne gère qu'une seule tâche à la fois. La technologie publicitaire peut configurer plusieurs nœuds de calcul pour traiter les tâches en parallèle en définissant la configuration d'autoscaling. Grâce à l'autoscaling, le nombre de nœuds de calcul est ajusté de manière dynamique en fonction du nombre de messages restants dans la file d'attente de tâches. Le nombre minimal et maximal de nœuds de calcul pour l'autoscaling peut être configuré via le fichier d'environnement Terraform. Vous trouverez plus d'informations sur l'autoscaling dans les scripts Terraform suivants. [Amazon Web Services / Google Cloud]
Le nœud de calcul d'agrégation appelle le service de comptabilité des rapports agrégables pour la comptabilité des rapports agrégables. Le service de comptabilisation des rapports agrégables garantit que les tâches ne sont exécutées que tant qu'il n'a pas dépassé la limite du budget pour la confidentialité. (voir la règle "Pas de doublons"). Si le budget est disponible, un rapport récapitulatif est généré à l'aide des agrégats bruyants. En savoir plus sur la comptabilisation des rapports agrégables
Le nœud de calcul d'agrégation met à jour les métadonnées de la tâche dans la base de données de métadonnées de la tâche, y compris les codes de retour de tâche appropriés et les compteurs d'erreur de rapport en cas d'échec partiel du rapport. Les utilisateurs peuvent récupérer l'état à l'aide de l'API de récupération de l'état d'une tâche (getJob).
Pour obtenir une description plus détaillée du service d'agrégation, consultez notre explication.
Étapes suivantes
Maintenant que vous connaissez les principales fonctionnalités du service d'agrégation, il est temps de déployer votre propre instance du service d'agrégation via Google Cloud ou Amazon Web Services. Consultez la section Premiers pas. Si vous souhaitez en savoir plus sur l'utilisation d'un service d'agrégation déployé, suivez ce lien pour en savoir plus sur l'utilisation du service d'agrégation.
Dépannage
Consultez notre document Codes d'erreur courants et mesures d'atténuation pour obtenir une description plus détaillée des messages d'erreur, connaître la cause potentielle de l'erreur que vous rencontrez et connaître les mesures à prendre pour y remédier.
Obtenir de l'aide et envoyer des commentaires
- Pour signaler des problèmes techniques, poser des questions sur le produit, envoyer des commentaires ou demander l'ajout de fonctionnalités, créez un problème dans notre dépôt GitHub.
- Si vous avez besoin de fournir des informations sensibles ou propriétaires à des fins de dépannage, contactez aggregation-service-support@google.com.
- Consultez la page Public Status Dashboard pour connaître les problèmes connus.