שירות הצבירה מפיק דוחות סיכום של נתוני המרות מפורטים ומדידות של היקף החשיפה מדוחות נצברים גולמיים. לטכנולוגיות הפרסום יש שתי נקודות כניסה ראשיות לנתונים מצטברים בצד הלקוח, כדי להעביר דוחות לשירות הצבירה. הנקודות האלה הן Attribution Reporting API או Private Aggregation API.
סטטוס ההטמעה
- שירות הצבירה עבר עכשיו לזמינות לכלל המשתמשים.
- אפשר להשתמש ב-Aggregation Service עם Attribution Reporting API ו-Private Aggregation API עבור Protected Audience API ו-Shared Storage API.
זמינות
| 提案 | 状态 |
|---|---|
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 跨 Attribution Reporting API、Private Aggregation API 为 Google Cloud 提供汇总服务支持 说明文档 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。若要汇总多个源站,这些源站必须属于同一个网站。
GitHub 上的常见问题解答 网站汇总 API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持一个不超过 64 的范围,以方便对不同参数的实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小数值反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知整个生态系统。 |
| 为汇总服务查询提供更灵活的贡献过滤功能
解说 |
可用 |
| 灾难后(错误、配置错误等)的预算恢复流程
解说 |
提供 机制,用于审核广告技术平台使用预算挽回功能找回的共享 ID 所占百分比,以及针对 2025 年上半年计划恢复的过多账号恢复请求暂停未来恢复机制 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 担任 Google Cloud 协调员之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
מונחי מפתח ומושגים מרכזיים
אם אתם שוקלים להשתמש בשירות הצבירה בתהליך העבודה שלכם בתחום טכנולוגיית הפרסום, המונחים והמושגים הבאים יעזרו לכם להבין טוב יותר את היתרונות של תהליך הצבירה החדש הזה לצוות שלכם:
| 术语 | 说明 |
|---|---|
| 汇总服务 | 由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。 |
| 可汇总的报告 |
דוחות נצברים הם דוחות מוצפנים שנשלחים ממכשירים של משתמשים ספציפיים. הדוחות האלה מכילים נתונים לגבי התנהגות והמרות של משתמשים באתרים שונים. ההמרות (שלפעמים נקראים אירועי טריגר של שיוך (Attribution)) והמדדים המשויכים מוגדרים על ידי המפרסם או טכנולוגיית הפרסום. כל דוח מוצפן כדי למנוע מגורמים שונים גישה לנתונים הבסיסיים. 详细了解可汇总的报告。 |
| 可汇总报告的会计核算 | 位于两个协调器中的分布式账本,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是一种隐私保护机制,位于协调者中并在其中运行,可确保通过汇总服务传递的报告不会超出分配的隐私预算。 详细了解批处理策略与可汇总报告的关系。 |
| 可汇总报告的会计核算预算 | 对预算的引用,用于确保报告不会被处理多次。 |
| 可信执行环境 (TEE) |
可信执行环境是计算机硬件和软件的一种特殊配置, 验证计算机上运行的软件的确切版本。TEEs 允许外部各方验证软件是否完全按照 软件制造商声称可以,不多或少。 如需详细了解用于 Privacy Sandbox 提案的 TEE,请参阅 Protected Audience API 服务说明文档 以及汇总服务说明。 |
| 协调员 |
מתאם הוא ישות שאחראית לניהול מפתחות ולחשבונאות דוחות ניתנת לצבירה. המתאם מנהל רשימת גיבובים של הגדרות שירות שאושרו לצבירה ומגדיר את הגישה למפתחות פענוח. |
| 共享 ID |
计算值,由以下各项组成:shared_info、reporting_origin、destination_site(仅适用于 Attribution Reporting API)、source_registration-time(仅适用于 Attribution Reporting API)、scheduled_report_time、version。
这意味着,如果多个报告具有相同的 shared_info 字段属性,则它们属于同一共享 ID。这在可汇总报告会计中起着重要作用。
详细了解可信服务器。
|
| 汇总报告 |
摘要报告是一种 Attribution Reporting API 和 Private Aggregation API 报告类型。摘要报告包含汇总的用户数据,并且可能包含添加了噪声的详细转化数据。摘要报告由汇总报告组成。与事件级报告相比,摘要报告具有更大的灵活性和数据模型,尤其是对于某些应用场景(例如转化价值)。 |
| 举报来源 |
מקור הדיווח הוא הישות שמקבלת דוחות נצברים. במילים אחרות, טכנולוגיית הפרסום שנקרא 'Attribution Reporting API'. דוחות נצברים נשלחים מאת מכשירים של משתמשים לכתובת URL ידועה שמשויכת לדיווח המקור. צריך לציין את מקור הדיווח הזה במהלך הרישום. |
| 贡献债券 | 可汇总的报告可以包含任意数量的计数器增量。例如,报告中可能包含用户在广告客户网站上查看过的商品数量。与单个来源事件相关的所有可汇总报告中的增量之和不得超过给定限制“L1=2^16”。 如需了解详情,请参阅可汇总报告说明。 |
| 噪声和缩放 | 在汇总过程中,系统会向摘要报告添加一定量的统计噪声,这也有助于保护隐私并确保最终报告提供匿名化效果衡量信息。详细了解加法噪声机制,该机制是从拉普拉斯分布中提取的。 |
| 证明 |
אימות (attestation) הוא מנגנון לאימות זהות התוכנה, בדרך כלל באמצעות טביעות אצבע קריפטוגרפיות או חתימות. בהצעה של שירות הצבירה, האימות תואם לקוד שפועל בשירות הצבירה המופעל על-ידי טכנולוגיות פרסום לבין קוד הקוד הפתוח. 详细了解证明。 |
מידע נוסף על הרקע של שירות הצבירה זמין במאמר ההסבר וברשימת התנאים המלאה.
תרחישים לדוגמה לצבירה
נבחן את התהליכים הבאים למפתחים בנושא מדידת ביצועים של מודעות וספריות הלקוח התואמות שלהם למדידת ביצועים.
| תרחיש לדוגמה | נקודת כניסה | תיאור |
|---|---|---|
| אופטימיזציה של הבידינג | Attribution Reporting API (Chrome ו-Android) | שימוש בדוחות מצטברים כדי להטמיע אותות המרה לצורכי אופטימיזציה של הבידינג. |
| מדידה בפלטפורמות שונות | Attribution Reporting API (Chrome ו-Android) | בעזרת היכולות למדידת ביצועים באתרים ובאפליקציות תוכלו לקבל תמונה ברורה יותר של הביצועים ב-Chrome וב-Android. |
| דיווח על המרות | Attribution Reporting API (Chrome ו-Android) | ליצור דוחות המרות מצטברים שמותאמים לצורכי הקמפיינים של הלקוחות (כולל דוחות על המרות מסוג 'המרות מסוג 'קליק להמרה'' ודוחות על המרות מסוג 'קליק להצגת מודעה'). |
| מדידת היקף החשיפה של הקמפיין | Shared Storage API ו-Private Aggregation API (Chrome) | השתמשו במשתנים של צפיות במודעות באתרים שונים כדי למדוד את פוטנציאל החשיפה של הקמפיין. |
| דיווח על מאפיינים דמוגרפיים | Shared Storage API ו-Private Aggregation API (ב-Chrome) | השתמשו בתצוגת מודעות באתרים שונים ובמידע דמוגרפי כדי למדוד את פוטנציאל החשיפה לפי קבוצות דמוגרפיות. |
| ניתוח נתיב ההמרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | אחסון של צפיות במודעות באתרים שונים ומשתנים של המרות כדי לבצע ניתוח מצטבר של נתיבי המרות. |
| התחזקות המותג ועלייה בהמרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | דיווח על קבוצות ניסוי/בקרה ועל נתוני סקרים כדי למדוד את התחזקות המותג ואת העלייה המצטברת. |
| ניפוי באגים במכרזים | Protected Audience API ו-Private Aggregation API (Chrome) | שימוש בדוחות נצברים לניפוי באגים. |
| חלוקת הצעות המחיר | Protected Audience API ו-Private Aggregation API (ב-Chrome) | אפשר להשתמש בדוחות נצברים כדי לתעד את ההתפלגות של ערכי הצעות המחיר במכרזים. |
תהליך מקצה לקצה
בתרשים הבא מוצג שירות הצבירה בפעולה. נתמקד בתהליך מקצה לקצה, החל מקבלת הדוחות מהאינטרנט והנייד ועד ליצירת דוחות הסיכום בשירות הצבירה.
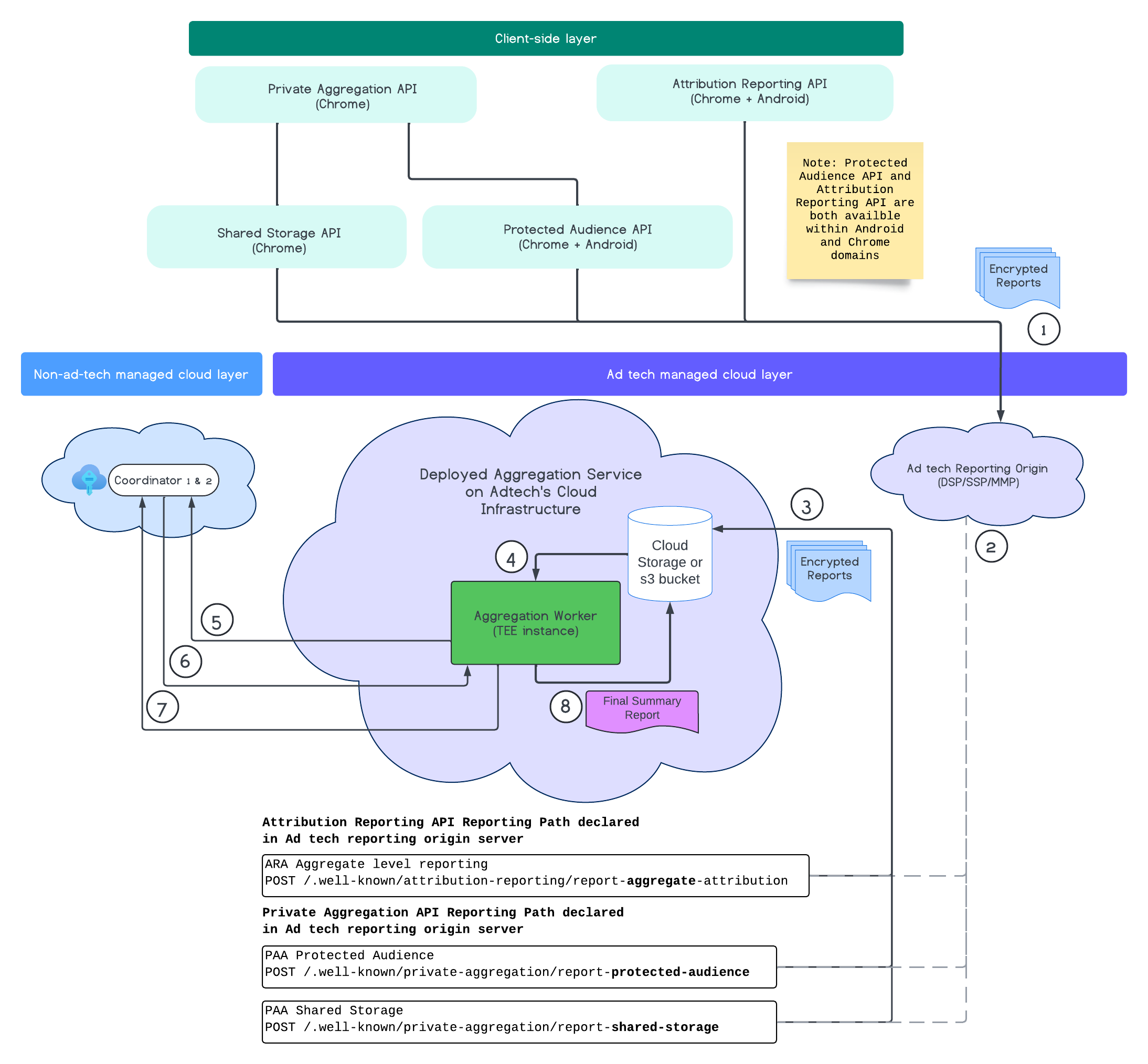
- אחזור מפתח ציבורי ליצירת דוחות מוצפנים.
- דוחות מוצפנים נצברים שנשלחים לשרתים של פרסום דיגיטלי לצורך איסוף, טרנספורמציה וקיבוץ.
- שרת טכנולוגיית הפרסום אוסף דוחות (בפורמט avro) ושולח אותם לשירות האגרגציה שנפרס. (צריך להשלים את השלב של טכנולוגיית הפרסום).
- אחזור דוחות נצברים לצורך פענוח.
- אחזור מפתחות פענוח מהרכזים.
- שירות Aggregation Service מפענח דוחות לצורך צבירה והוספת רעש.
- בדיקות של שירות חשבונאות של דוחות נצברים אם נותר תקציב פרטיות, כדי להפיק דוח סיכום לדוחות המצטברים הנתונים.
- שולחים דוח סיכום סופי.
בתרשים אפשר לראות את הקשר הכולל של שירות האגרגציה עם ממשקי ה-API העיקריים למדידת לקוחות: Attribution Reporting API, Private Aggregation API והתיאמים.
התהליך מתחיל בממשקי API שונים למדידה, כמו Attribution Reporting API או Private Aggregation API, שמייצרים דוחות מכמה מופעים בדפדפן. Chrome לוקח את המפתח הציבורי משירות אירוח המפתחות במרכז התיאום כדי להצפין את הדוחות לפני שהם נשלחים למקור הדיווח של חברת טכנולוגיית הפרסום. המפתחות הציבוריים מבצעים רוטציה מדי 7 ימים.
אחרי שמקור הדיווח של טכנולוגיית הפרסום יקבל את הדוחות האלה, צריך להגדיר את מקור הדיווח כך שיאסוף וימיר את הדוחות האלה לפורמט Avro, וישלח אותם למכונה של Aggregation Service שנפרסה. כדאי לעיין במאמר בנושא שיטות ארגון בקבוצות.
כשמערכת טכנולוגיית הפרסום מוכנה ליצירת קבוצה, היא יוצרת בקשת קבוצה לשירות המצטבר, שבו הדוחות מפענחים על ידי אחזור מפתחות הפענוח משירות אירוח המפתחות, ולאחר מכן הם נצברים ומתווסף להם רעש כדי ליצור דוח סיכום. חשוב לזכור שההחלטה הזו מותנית בשאלה אם תקציב הפרטיות מספיק כדי להפיק את דוחות הסיכום הסופיים.
נקודת הקצה המקורית לדיווח של חברת טכנולוגיית הפרסום, שבה נאספים הדוחות, מתארחת על ידי חברת טכנולוגיית הפרסום, ושירות הצבירה נפרס בענן של חברת טכנולוגיית הפרסום.
קיבוץ דוחות נצברים
תהליך הדיווח לא יושלם ללא עזרה משרת המקור הייעודי לדיווח. זהו המקור שפלטפורמת ה-AdTech הייתה שולחת בתהליך ההרשמה. הפעולות העיקריות שמקור הדיווח אחראי להן יהיו איסוף, טרנספורמציה וקיבוץ של הדוחות המצטברים שהתקבלו, והכנה שלהם לשליחה לשירות האגרגציה שנפרס של טכנולוגיית הפרסום ב-Google Cloud או ב-Amazon Web Services. מידע נוסף על הכנת דוחות שניתן לצבור
עכשיו, אחרי שהבנתם את הקונספט הכללי, נבחן לעומק את הרכיבים שיוצבו בשירות הצבירה.
רכיבי ענן
שירות הצבירה מורכב מרכיבים שונים של שירותי ענן. קובצי הסקריפטים של Terraform שסופקו והגדירו את כל הרכיבים הדרושים של שירותי ענן.
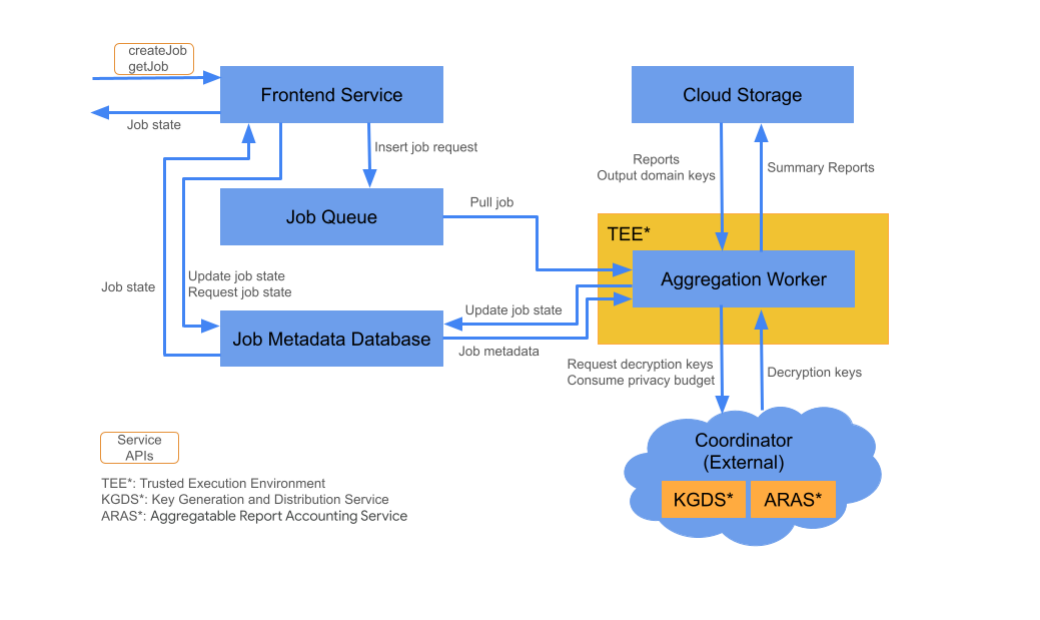
שירות לקצה הקדמי
שירות ענן מנוהל: פונקציה של Cloud Functions (Google Cloud) / שער API (Amazon Web Services)
Frontend Service הוא שער ללא שרת (serverless), שמשמש כנקודת הכניסה לקריאות ל-Aggregation API ליצירת משימות ולאחזור מצב של משימות. הוא אחראי לקבלת בקשות ממשתמשי שירות האגרגציה, לאימות הפרמטרים של הקלט ולהפעלת תהליך תזמון משימות האגרגציה.
שני ממשקי API זמינים ב-Frontend Service:
| נקודת קצה | תיאור |
|---|---|
createJob |
ה-API הזה מפעיל משימה של Aggregation Service. נדרש מידע כדי להפעיל משימה כמו מזהה משימה, פרטי אחסון קלט, פרטי אחסון פלט, מקור הדיווח ועוד. |
getJob |
ממשק ה-API הזה מחזיר את הסטטוס של משימה לפי מזהה משימה ספציפי. הוא מספק מידע על סטטוס המשימה, כמו 'נשלחה', 'בטיפול' או 'הושלמה'. בנוסף, אם המשימה הסתיימה, תופיע תוצאת המשימה, כולל הודעות השגיאה שנתקלו בהן במהלך ביצוע המשימה. |
מסמכי העזרה של Aggregation Service API
Job Queue
שירות ענן מנוהל: Pub/Sub (Google Cloud) או Amazon SQS (Amazon Web Services)
'תור המשימות' הוא תור של הודעות שמאחסן בקשות של משימות לשירות הצבירה. שירות Frontend מוסיף הודעות של בקשות משימה לתור, ואז Aggregation Worker צורכת הודעות כדי לעבד את בקשת המשימה.
אחסון בענן
שירות ענן מנוהל: Google Cloud Storage (Google Cloud) או Amazon S3 (שירותי אינטרנט של Amazon) אחסון בענן משמש לאחסון קובצי קלט ופלט שמשמשים את שירות הצבירה (לדוגמה: קובצי דוחות מוצפנים, דוחות סיכום פלט וכו').
מסד נתונים של מטא-נתונים של משימות
שירות מנוהל בענן: Spanner (Google Cloud) או DynamoDB (Amazon Web Services)
מסד נתונים של Job Metadata מאחסן ועוקב אחר הסטטוס של משימות צבירת נתונים. במסד הנתונים מתועדים מטא-נתונים כמו שעת היצירה, השעה המבוקשת, השעה המעודכנת והמצב (לדוגמה: התקבלו, בתהליך, הסתיים וכו'). Aggregation Worker מעדכן את מסד הנתונים של המשימות לפי התקדמות המשימה.
עובד צבירת נתונים
שירות ענן מנוהל: Compute Engine עם Confidential Space (Google Cloud) או Amazon Web Services EC2 עם Nitro Enclave (Amazon Web Services)
קובץ Aggregation Worker מעבד בקשות למשימות שיזומות בקשת משימה בתור המשימה, ומפענח את הקלט המוצפן באמצעות מפתחות שנשלפו מ-Key Generation and Distribution Service (KGDS) ב-Coordinator. כדי לצמצם את זמן האחזור של עיבוד המשימות, מפתחות ההצפנה נשמרים במטמון ב-Aggregation Worker למשך 8 שעות, וניתן להשתמש בהם במשימות שמעובדות על ידי מכונה עובדת זו.
העובד פועל במכונה של Trusted Execution Environment (TEE). כל עובד מטפל רק במשימה אחת בכל פעם. טכנולוגיית הפרסום יכולה להגדיר כמה עובדים לעיבוד משימות במקביל על ידי הגדרת הגדרות התאמה אוטומטית לעומס. באמצעות התאמה אוטומטית, מספר העובדים משתנה באופן דינמי בהתאם למספר ההודעות שנותרו בתור המשימות. באמצעות קובץ הסביבה של Terraform אפשר להגדיר את מספר העובדים המינימלי והמקסימלי להתאמה לעומס (auto-scaling). מידע נוסף על התאמה לעומס (autoscaling) ניתן למצוא בסקריפטים הבאים של terraform. [Amazon Web Services / Google Cloud]
Aggregation Worker קורא לשירות Aggregatable Report Accounting לגבי הנהלת דוחות נצברים. שירות החשבונאות של הדוחות המצטברים יבטיח שמשימות יופעלו רק כל עוד הוא לא חרג ממגבלת הפרטיות של התקציב. (ראו כלל 'ללא כפילויות'). אם התקציב זמין, המערכת יוצרת דוח סיכום שמבוסס על הנתונים שהצטברו עם הרעש. מידע נוסף על דיווח על דוחות שניתן לצבור
הכלי Aggregation Worker מעדכן את המטא-נתונים של המשימות במסד הנתונים של משימות, כולל קודים מתאימים של החזרת משימות ומוני שגיאות של דוחות במקרה של כשלים חלקיים בדוחות. המשתמשים יכולים לאחזר את המצב באמצעות ממשק ה-API לאחזור מצב המשימה (getJob).
תיאור מפורט יותר של שירות צבירת הנתונים זמין בהסברים שלנו.
השלבים הבאים
אחרי שסיפקנו לכם את הנקודות העיקריות של Aggregation Service, הגיע הזמן לפרוס מכונה משלכם של Aggregation Service דרך Google Cloud או Amazon Web Services. אפשר לעיין בקטע 'תחילת העבודה'. אם אתם צריכים מידע נוסף על הפעלת Aggregation Service שנפרס, תוכלו להיכנס לקישור הזה כדי לקרוא מידע נוסף על הפעלת Aggregation Service.
פתרון בעיות
במסמך קודי שגיאה נפוצים והקלות מפורטים תיאורים מפורטים יותר של הודעות השגיאה, מה יכול להיות שגרם לשגיאה שבה נתקלת והשלבים הבאים להקלה על הבעיה.
קבלת תמיכה ושליחת משוב
- אם יש לכם בעיות טכניות, שאלות לגבי המוצר, משוב או בקשות למאפיינים חדשים, אתם יכולים ליצור דיווח על בעיה במאגר שלנו ב-GitHub.
- אם יש לכם שאלות שבהן אתם צריכים לספק מידע רגיש או קנייני לצורך פתרון בעיות, תוכלו לפנות אלינו בכתובת aggregation-service-support@google.com
- כדאי לבדוק בלוח הבקרה של הסטטוס הציבורי כדי לראות אם יש בעיות ידועות.