汇总服务会根据原始可汇总报告生成摘要报告,其中包含详细的转化数据和覆盖面衡量结果。作为广告技术平台,您可以使用 Attribution Reporting API 和 Private Aggregation API(客户端上的两个主要汇总入口点)将报告汇总到 Aggregation Service,并收到回复摘要报告。
本页面假定您是经验丰富的广告技术平台。其中介绍了以下内容:
实现状态
- 汇总服务现已正式发布。
- Aggregation Service 可与 Attribution Reporting API 和 Private Aggregation API 搭配使用,以便使用 Protected Audience API 和 Shared Storage API。
可用性
| 提案 | 状态 |
|---|---|
| 跨云隐私预算服务
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 的 Google Cloud 汇总服务支持 说明 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。如需汇总多个来源,这些来源必须属于同一网站。
GitHub 上的常见问题解答 Site aggregation API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持在 64 以内的范围内,以便对不同的参数进行实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小样本误差反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知生态系统。 |
| 为汇总服务查询提供了更灵活的贡献过滤功能
解说 |
可用 |
| 灾难发生后(错误、配置错误等)预算恢复流程
说明 |
可用 机制,用于查看广告技术平台使用预算恢复功能恢复的共享 ID 的百分比,并暂停计划在 2025 年上半年过度恢复的未来恢复 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 作为 Google Cloud 协调者之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
关键术语和概念
如果您正在考虑为工作流引入汇总服务,不妨通过以下术语和概念深入了解这项新的汇总流程可以为您的团队提供哪些帮助。
术语词汇表
- 可汇总的报告
-
可汇总的报告是从单个用户设备发送的经过加密的报告。这些报告包含有关跨网站用户行为和转化的数据。转化(有时称为归因触发器事件)和相关指标由广告客户或广告技术平台定义。每个报告均已加密,以防止各方访问底层数据。
- 可汇总报告的会计核算
-
分布式账本,位于两个协调者中,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是位于协调器中并在其中运行的隐私保护机制,可确保没有任何报告在通过汇总服务时超出分配的隐私预算。
- 可汇总报告的会计核算预算
-
对预算的引用,用于确保不会对单个报告进行多次处理。
- 汇总服务
-
由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。
- 证明
-
一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务提案,认证会将广告技术平台运营的汇总服务中运行的代码与开源代码进行匹配。
- 贡献债券
- 协调者
-
负责密钥管理和汇总报告会计核算的实体。协调者会维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。
- 噪声和缩放
-
在汇总过程中向摘要报告添加的统计噪声,用于保护隐私并确保最终报告提供匿名化衡量信息。
- 举报来源
-
接收可汇总报告的实体,也就是您或调用了 Attribution Reporting API 的广告技术平台。可汇总的报告会从用户设备发送到与报告来源关联的知名网址。报告来源是在注册期间指定的。
- 共享 ID
-
计算值,由
shared_info、reporting_origin、destination_site(仅限 Attribution Reporting API)、source_registration-time(仅限 Attribution Reporting API)、scheduled_report_time和版本组成。如果多个报告在
shared_info字段中具有相同的属性,则应具有相同的共享 ID。共享 ID 在可汇总报告的会计核算中发挥着重要作用。 - 汇总报告
-
Attribution Reporting API 和 Private Aggregation API 报告类型。摘要报告包含汇总的用户数据,并且可能包含添加了噪声的详细转化数据。摘要报告由汇总报告组成。与事件级报告相比,这些报告具有更高的灵活性,并提供更丰富的数据模型,对于转化价值等某些用例尤其如此。
- 可信执行环境 (TEE)
-
计算机硬件和软件的安全配置,可让外部方验证机器上运行的软件的确切版本,而无需担心信息泄露。通过 TEE,外部方可以确认软件的行为和功能与其制造商声称的完全一致,不多不少。
如需详细了解用于 Privacy Sandbox 方案的 TEE,请参阅 Protected Audience API 服务说明文档和汇总服务说明文档。
汇总用例
请考虑以下广告效果衡量开发者历程及其对应的衡量客户端库。
| 使用场景 | 入口点 | 说明 |
|---|---|---|
| 出价优化 | Attribution Reporting API (Chrome 和 Android) | 使用汇总报告提取转化信号,以便进行出价优化。 |
| 跨平台衡量 | Attribution Reporting API (Chrome 和 Android) | 使用跨网站和应用衡量功能,了解在 Chrome 和 Android 设备上的效果。 |
| 转化报告 | Attribution Reporting API (Chrome 和 Android) | 根据客户的广告系列需求(包括 CTC 和 VTC)创建汇总转化报告。 |
| 广告系列覆盖面衡量 | Shared Storage API 和Private Aggregation API(Chrome) | 使用跨网站广告观看变量衡量广告系列覆盖面。 |
| 受众特征报告 | Shared Storage API 和Private Aggregation API(Chrome) | 使用跨网站广告观看次数和受众特征信息来按受众特征衡量覆盖面。 |
| 转化路径分析 | Shared Storage API 和Private Aggregation API(Chrome) | 存储跨网站广告观看和转化变量,以执行汇总的转化路径分析。 |
| 品牌提升效果和转化量提升情况 | Shared Storage API 和Private Aggregation API(Chrome) | 针对测试组/对照组和投票信息生成报告,以衡量品牌提升效果和增量效果。 |
| 竞价调试 | Protected Audience API 和 Private Aggregation API(Chrome) | 使用汇总报告进行调试。 |
| 出价分布 | Protected Audience API 和 Private Aggregation API(Chrome) | 使用汇总报告来了解竞价出价值的分布情况。 |
端到端流程
下图展示了汇总服务的运作方式。我们将重点关注从从网络和移动设备收到报告到在汇总服务中创建摘要报告的端到端流程。
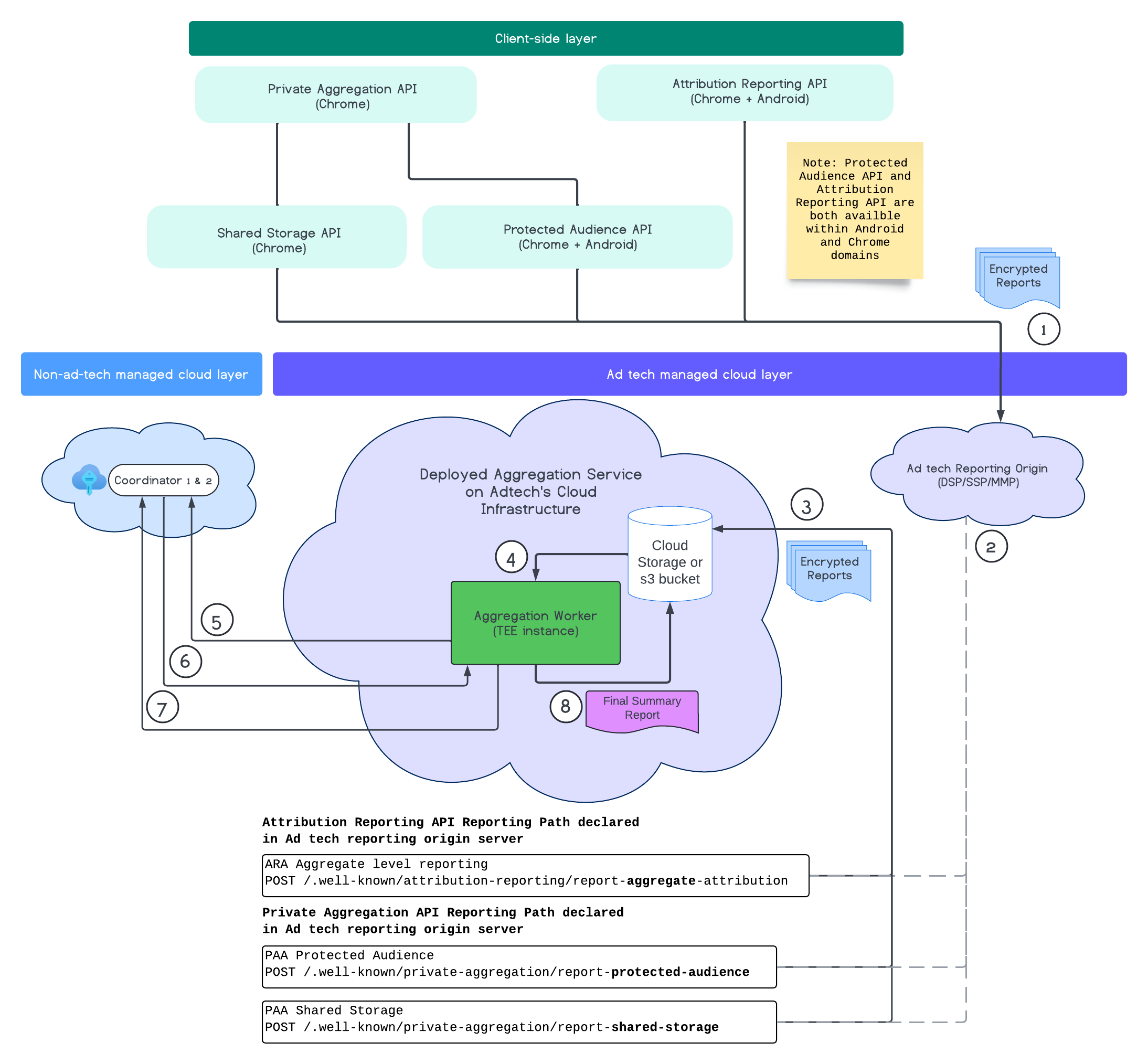
- 提取公钥以生成加密报告。
- 加密的可汇总报告会发送到广告技术平台服务器,以进行收集、转换和批处理。
- 广告技术平台服务器将报告(采用 avro 格式)分批发送到汇总服务。(您必须完成此操作。)
- 汇总工作器会检索要解密的汇总报告。
- 汇总工作器会从协调者检索解密密钥。
- 汇总 Worker 会对报告进行解密,以便进行汇总和添加噪声。
- 可汇总报告会计服务会检查是否有足够的隐私预算来为给定的可汇总报告生成摘要报告。
- 提交最终摘要报告。
该图展示了汇总服务与主要客户端衡量 API(即 Attribution Reporting API、Private Aggregation API 和协调者)之间的概要关系。
该流程从效果衡量 API(例如 Attribution Reporting API 或 Private Aggregation API)开始,从多个浏览器实例生成报告。Chrome 会从协调器中的密钥托管服务获取公钥,以便在将报告发送到您的广告技术平台报告来源之前对其进行加密。公钥每 7 天轮替一次。
您应将广告技术平台报告来源配置为收集传入报告并将其转换为 avro 格式,然后将其发送到汇总服务(如批处理策略中所述)。
准备好批量数据后,您可以向汇总服务发送批量请求。汇总服务从密钥托管服务中提取解密密钥,解密报告,然后对其进行汇总和噪声处理,以生成摘要报告。请注意,这取决于是否有足够的隐私预算来创建这些模型。
您托管用于收集报告的广告技术平台报告来源端点,汇总服务部署在广告技术平台云中。
可汇总报告批处理
如果没有指定的报告来源服务器的帮助,报告流程将无法完成。这是您在注册过程中提交的来源。报告来源负责收集、转换和批量处理收到的可汇总报告,并准备将其发送到 Google Cloud 或 Amazon Web Services 中的汇总服务。详细了解如何准备可汇总的报告。
现在,您已经了解了基本概念,接下来我们可以详细了解在汇总服务中部署的组件。
Cloud 组件
汇总服务由多个云服务组件组成。您可以使用提供的 Terraform 脚本预配和配置所有必要的云服务组件。
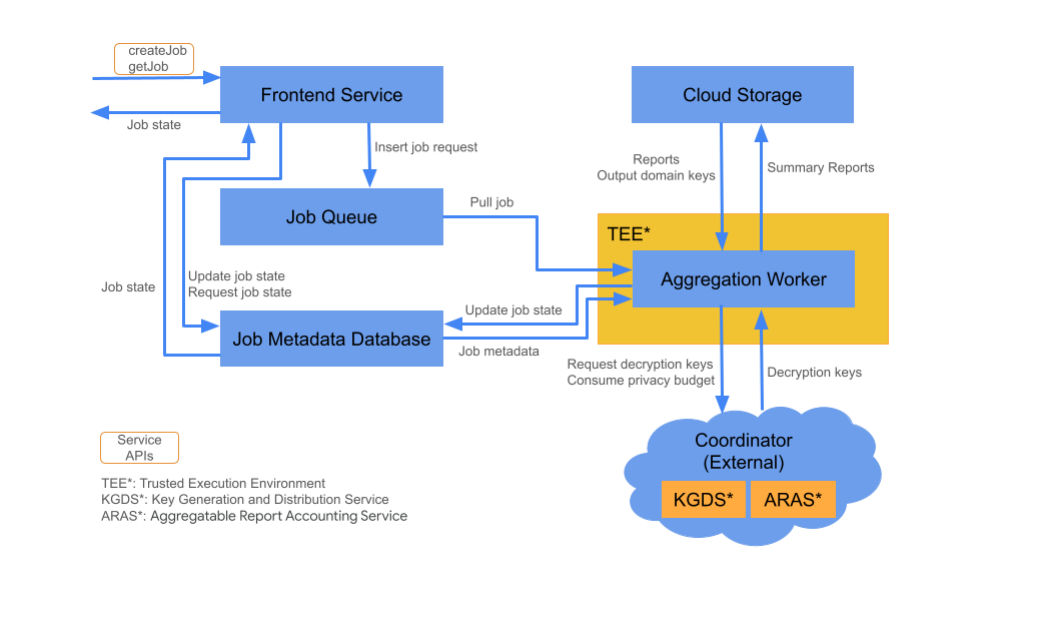
前端服务
托管式云服务:Cloud Functions (Google Cloud) / API Gateway (Amazon Web Services)
前端服务是一种无服务器网关,是用于创建作业和检索作业状态的 Aggregation API 调用的主入口点。它负责接收来自汇总服务用户的请求、验证输入参数并启动汇总作业调度流程。
前端服务有两个可用 API:
| 端点 | 说明 |
|---|---|
createJob |
此 API 会触发汇总服务作业。它需要作业 ID、输入存储空间详细信息、输出存储空间详细信息、报告来源等信息才能触发作业。 |
getJob |
此 API 会返回具有指定作业 ID 的作业的状态。它提供有关作业状态的信息,例如“已收到”“正在处理”或“已完成”。如果作业已完成,它还会返回作业结果,包括作业执行期间遇到的所有错误消息。 |
查看汇总服务 API 文档。
作业队列
托管式云服务:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
作业队列是一个消息队列,其中包含汇总服务的作业请求。前端服务会将作业请求插入队列,然后汇总工作器会使用这些请求进行处理。
Cloud Storage
托管式云服务:Google Cloud Storage(Google Cloud)/Amazon S3(Amazon Web Services)
汇总服务使用的输入和输出文件(例如加密报告文件和输出摘要报告)会保留在云端存储空间中。
作业元数据数据库
托管式云服务:Spanner(Google Cloud)/DynamoDB(Amazon Web Services)
作业元数据数据库用于存储和跟踪汇总作业的状态。它会记录创建时间、请求时间、更新时间等元数据,以及“已收到”“正在处理”或“已完成”等状态。汇总工作器会随着作业的进度更新作业元数据数据库。
汇总 Worker
受管云服务:具有 Confidential Zone 的 Compute Engine(Google Cloud)/具有 Nitro Enclave 的 Amazon Web Services EC2(Amazon Web Services)
汇总 Worker 会处理作业队列中的作业请求,并使用从协调程序中的密钥生成和分发服务 (KGDS) 提取的密钥解密加密输入。为了尽可能缩短作业处理延迟时间,汇总工作器会将解密密钥缓存 8 小时,并在处理的作业中使用这些密钥。
汇总工作器在可信执行环境 (TEE) 实例中运行。一个工作器一次只能处理一个作业。您可以通过设置自动扩缩配置,将多个工作器配置为并行处理作业。如果使用自动扩缩,系统会根据作业队列中的消息数量动态调整工作器数量。您可以通过 Terraform 环境文件配置自动扩缩的工作器数量下限和上限。如需详细了解自动扩缩,请参阅以下 Terraform 脚本:Amazon Web Services 或 Google Cloud。
汇总 Worker 会调用可汇总报告会计核算服务,以进行可汇总报告会计核算。此服务可确保仅在未超出隐私预算限制时运行作业。(请参阅“不得重复”规则。)如果有预算,系统会使用带噪声的汇总数据生成摘要报告。详细了解可汇总报告会计核算。
汇总 Worker 会更新作业元数据库中的作业元数据。此信息包括作业返回代码和报告错误计数器(如果部分报告失败)。用户可以使用 getJob 作业状态检索 API 提取状态。
如需详细了解汇总服务,请参阅此说明文档。
后续步骤
现在,您已经了解了汇总服务的亮点,接下来就可以通过 Google Cloud 或 Amazon Web Services 部署您自己的汇总服务实例了。请参阅“使用入门”部分,或点击此链接详细了解如何运行汇总服务。
问题排查
如需详细了解错误消息、可能导致您遇到的错误的原因,以及采取的后续缓解措施,请参阅常见错误代码和缓解措施文档。
获取支持和提供反馈
- 如有产品问题、反馈和功能请求,请在我们的 GitHub 代码库中创建问题。
- 如果您在使用汇总服务部署、维护或运行作业时遇到错误,请使用此技术支持表单请求技术问题排查支持。
- 查看公开状态信息中心,了解已知问题。