Usługa agregacji generuje raporty podsumowujące szczegółowych danych o konwersjach i danych dotyczących zasięgu na podstawie nieprzetworzonych raportów podlegających agregacji. Dostawcy technologii reklam mają 2 główne punkty wejścia po stronie klienta, które umożliwiają przekazywanie raportów do usługi agregacji. Mogą to zrobić za pomocą interfejsu Attribution Reporting API lub Private Aggregation API.
Stan wdrożenia
- Usługa agregacji jest teraz ogólnie dostępna.
- Usługa agregacji może być używana z interfejsem Attribution Reporting API i interfejsem Private Aggregation API w przypadku interfejsu Protected Audience API i interfejsu Shared Storage API.
Dostępność
| Propozycja | Stan |
|---|---|
| Obsługa usługi agregacji w Amazon Web Services (AWS) w ramach interfejsów Attribution Reporting API i Private Aggregation API Wprowadzenie |
Dostępna |
| Obsługa Google Cloud w ramach interfejsu Attribution Reporting API i interfejsu Private Aggregation API Wyjaśnienie |
Dostępna |
| Rejestracja witryny w usłudze do agregacji i agregacja wieloźródłowa. Rejestrowanie witryny obejmuje mapowanie witryny na konta w chmurze (AWS lub GCP). Aby agregować wiele źródeł, muszą one należeć do tej samej witryny.
Najczęstsze pytania na GitHubie Dokumentacja interfejsu API agregacji witryn |
Dostępna |
| Wartość ypsilon usługi agregacji będzie przechowywana w zakresie do 64, aby ułatwić eksperymentowanie i uzyskiwanie informacji na temat różnych parametrów.
Prześlij opinię na temat epsilona w ARA. Prześlij opinię na temat ypsilon PAA. |
Dostępne Zanim zaktualizujemy wartości zakresów ypsilon, powiadomimy o tym ekosystem z wyprzedzeniem. |
| Bardziej elastyczne filtrowanie treści udziału w zapytaniach dotyczących usługi agregacji
Wyjaśnienie |
Dostępna |
| Proces odzyskiwania budżetu po katastrofie (błędy, nieprawidłowe konfiguracje itp.) Wyjaśnienie |
Dostępne mechanizm pozwalający na przywrócenie odsetka udostępnionych identyfikatorów odzyskanych przez technologię reklamową za pomocą przywrócenia budżetu i zawieszenie możliwości odzyskania w przyszłości przypadków nadmiernych operacji przywracania w pierwszej połowie 2025 r. |
| Accenture działający jako jeden z koordynatorów w AWS Blog dla deweloperów |
Dostępna |
| Niezależna strona działająca jako jeden z koordynatorów Google Cloud
Blog dla deweloperów |
Dostępna |
| Obsługa usługi agregacji w przypadku zbiorczych raportów debugowania w interfejsie Attribution Reporting API
Wyjaśnienie |
Dostępna |
Kluczowe terminy i pojęcia
Jeśli rozważasz użycie usługi agregacji w swojej pracy nad technologiami reklamowymi, zapoznaj się z tymi terminami i koncepcjami, które pomogą Ci lepiej zrozumieć, jak nowy proces agregacji może pomóc Twojemu zespołowi:
| Term | Description |
|---|---|
| Aggregation Service | An ad tech-operated service that processes aggregatable reports to create a summary report. |
| Aggregatable Reports |
Raporty zbiorcze to zaszyfrowane raporty wysyłane z urządzeń poszczególnych użytkowników. Raporty te zawierają dane o zachowaniach użytkowników i konwersjach w różnych witrynach. Konwersje (nazywane też zdarzeniami powodującymi atrybucję) i powiązane z nimi dane są definiowane przez reklamodawcę lub technologię reklamową. Każdy raport jest zaszyfrowany, aby uniemożliwić różnym podmiotom dostęp do danych źródłowych. Learn more about aggregatable reports. |
| Aggregatable Report Accounting | A distributed ledger located in both coordinators that tracks allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures that no report passes through Aggregation Service beyond the allocated privacy budget. Read more on batching strategies on how it relates to aggregatable reports. |
| Aggregatable Report Accounting Budget | References to the budget that ensures reports are not processed more than once. |
| Trusted Execution Environment (TEE) |
Zaufane środowisko wykonawcze to specjalna konfiguracja sprzętu i oprogramowania komputerowego, która umożliwia weryfikacji dokładnych wersji oprogramowania działającego na komputerze. Środowiska TEE umożliwiają podmiotom zewnętrznym sprawdzenie, czy oprogramowanie działa dokładnie tak, jak twierdzi deweloper, i nic więcej. Aby dowiedzieć się więcej o TEE wykorzystywanych w ofertach pakietowych Piaskownicy prywatności, przeczytaj Wyjaśnienie usług Protected Audience API i objaśnienie usługi agregacji. |
| Coordinators |
协调者是负责密钥管理和可汇总报告的会计核算的实体。协调者维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。 |
| Shared ID |
Computed value that consists of: shared_info, reporting_origin, destination_site (available for Attribution Reporting API only), source_registration-time (available for Attribution Reporting API only), scheduled_report_time, version.
This means that multiple reports belong to the same shared ID should they share the same attributes of the shared_info field. This plays an important role within Aggregatable Report Accounting.
Read more about Trusted Servers.
|
| Summary Report |
Raport podsumowujący to typy raportów interfejsów Attribution Reporting API i Private Aggregation API. Podsumowanie zawiera zbiorcze dane o użytkownikach, które mogą zawierać szczegółowe dane o konwersjach (bez szumu). Raporty podsumowujące składają się z raportów zbiorczych. Raporty podsumowania zapewniają większą elastyczność i bogatszy model danych niż raportowanie na poziomie zdarzenia, zwłaszcza w przypadku niektórych zastosowań, np. wartości konwersji. |
| Reporting Origin |
Źródło raportowania to podmiot, który otrzymuje raporty podlegające agregacji, czyli inaczej technologia reklamowa, która wywołała interfejs Attribution Reporting API. Raporty podlegające agregacji są wysyłane z urządzeń użytkowników na znany adres URL powiązany z miejscem pochodzenia raportu. To źródło raportowania należy określić podczas rejestracji. |
| Contribution Bonding | Aggregatable reports may contain an arbitrary number of counter increments. For example, a report may contain a count of products that a user has viewed on an advertiser's site. The sum of increments in all aggregatable reports related to a single source event must not exceed a given limit, `L1=2^16`. Learn more in the aggregatable reports explainer. |
| Noise & Scaling | A certain amount of statistical noise is added to summary reports as a part of the aggregation process that also functions to preserve privacy and ensure the final reports provide anonymized measurement information. Read more about additive noise mechanism, which is drawn from Laplace distribution. |
| Attestation |
认证是一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务方案,证明会将广告技术平台运营的汇总服务中运行的代码与开放源代码进行匹配。 Read more about attestation. |
Więcej informacji o usłudze agregacji znajdziesz w tym artykule oraz w pełnej wersji warunków.
Przypadki użycia agregacji
Zapoznaj się z tymi ścieżkami dla programistów dotyczącymi pomiaru reklam i odpowiednimi bibliotekami klienta pomiarów.
| Przypadek użycia | Punkt wejścia | Opis |
|---|---|---|
| Optymalizacja stawek | Attribution Reporting API (Chrome i Android) | Korzystaj z raportów zbiorczych, aby pozyskiwać sygnały konwersji na potrzeby optymalizacji stawek. |
| Pomiar na wielu platformach | Attribution Reporting API (Chrome i Android) | Korzystaj z możliwości pomiaru skuteczności w internecie i aplikacjach, aby mieć wgląd w skuteczność w Chrome i na Androidzie. |
| Raportowanie konwersji | Attribution Reporting API (Chrome i Android) | tworzenie raportów o konwersjach zbiorczych dostosowanych do potrzeb kampanii klientów (w tym CTC i VTC); |
| Pomiar zasięgu kampanii | Shared Storage API i Private Aggregation API (Chrome) | Używaj zmiennych widoku reklamy w wielu witrynach do pomiaru zasięgu kampanii. |
| Raportowanie danych demograficznych | Shared Storage API i Private Aggregation API (Chrome) | Używaj danych o wyświetleniach reklam w wielu witrynach i danych demograficznych do pomiaru zasięgu według danych demograficznych. |
| Analiza ścieżki konwersji | Shared Storage API i Private Aggregation API (Chrome) | Przechowuj zmienne widoku reklamy w wielu witrynach i konwersji, aby przeprowadzać zbiorczą analizę ścieżki konwersji. |
| Wyniki marki i zwiększenie liczby konwersji | Shared Storage API i Private Aggregation API (Chrome) | Raportowanie dotyczące grup testowych i kontrolnych oraz informacji o głosowaniu na potrzeby pomiaru wzrostu skuteczności marki i przyrostu wartości. |
| Debugowanie aukcji | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych na potrzeby debugowania. |
| Rozkład stawek | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych, aby rejestrować rozkład wartości stawek w aukcjach. |
Cały proces
Poniższy diagram pokazuje działanie usługi agregacji. Skupimy się na pełnym procesie od otrzymywania raportów z sieci i urządzeń mobilnych do tworzenia raportów podsumowania w usłudze agregacji.
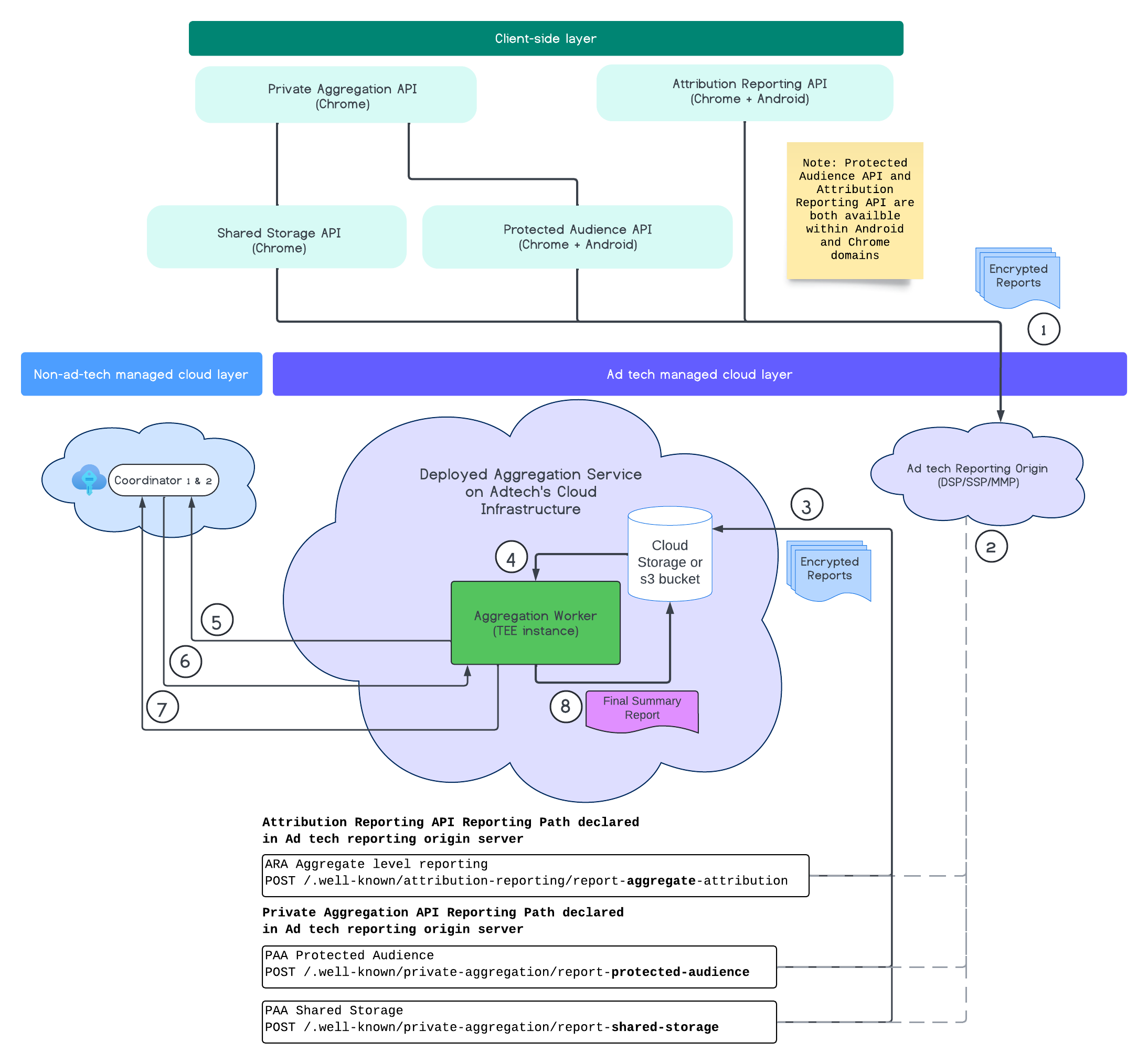
- Pobierz klucz publiczny, aby generować zaszyfrowane raporty.
- Szyfrowane raporty nadające się do agregacji wysyłane na serwery technologii reklamowych w celu zebrania, przekształcenia i zbiorowego przetwarzania.
- Serwer AdTech grupowo wysyła raporty (w formacie avro) do wdrożonej usługi agregacji. (musi zostać wypełniony przez dostawcę technologii reklamowych).
- Pobierz raporty zbiorcze, aby je odszyfrować.
- Pobieranie kluczy odszyfrowywania od koordynatorów.
- Usługa do agregacji odszyfrowuje raporty na potrzeby agregacji i dodawania szumu.
- Usługa księgowania raportów możliwych do zsumowania sprawdza, czy pozostał budżet na ochronę prywatności, aby wygenerować raport podsumowania dla podanych raportów możliwych do zsumowania.
- Prześlij końcowy raport podsumowujący.
Na diagramie widać ogólne relacje usługi agregacji z głównymi interfejsami API pomiarów klienta: Attribution Reporting API, Private Aggregation API i koordynatorami.
Proces rozpoczyna się od różnych interfejsów Measurement API, takich jak Attribution Reporting API czy Private Aggregation API, które generują raporty z wielu instancji przeglądarki. Chrome pobiera klucz publiczny z usługi hostingu kluczy w koordynatorze, aby szyfrować raporty przed ich wysłaniem do źródła raportowania technologii reklamowej. Klucze publiczne są poddawane rotacji co 7 dni.
Gdy usługa raportowania otrzyma te raporty, powinna je zbierać i konwertować na format avro, a potem wysyłać do wdrożonej instancji usługi Aggregation Service. Zapoznaj się z strategiami zbiorczego ustalania stawek.
Gdy usługa reklamowa jest gotowa do przetwarzania zbiorczego, tworzy żądanie zbiorcze do usługi agregacji, w której raporty są odszyfrowywane przez odszyfrowywanie kluczy z usługi hostingu kluczy, a następnie są agregowane i zaciemniane, aby utworzyć raport podsumowujący. Pamiętaj, że zależy to od tego, czy masz wystarczający budżet na prywatność, aby wygenerować końcowe raporty podsumowania.
Punkt końcowy pochodzenia raportów technologii reklamowych, w którym są zbierane raporty, jest hostowany przez tę technologię, a usługa agregacji jest wdrażana w chmurze tej technologii.
grupowanie raportów zbiorczych.
Proces raportowania nie byłby kompletny bez pomocy wyznaczonego serwera pochodzenia raportów. To jest źródło, które firma zajmująca się technologią reklamową przesłałaby w ramach procesu rejestracji. Główne działania, za które jest odpowiedzialne źródło raportowania, to zbieranie, przekształcanie i grupowanie otrzymanych raportów podlegających agregacji oraz przygotowywanie ich do wysłania do zaimplementowanej usługi agregacji w Google Cloud lub Amazon Web Services. Dowiedz się więcej o przygotowywaniu raportów możliwych do zsumowania.
Teraz, gdy znasz już ogólną koncepcję, przyjrzyj się bliżej komponentom, które zostaną wdrożone w usłudze agregacji.
Komponenty Cloud
Usługa agregacji składa się z różnych komponentów usług w chmurze. Dostarczone skrypty Terraform zapewniają i konfigurują wszystkie niezbędne komponenty usługi w chmurze.
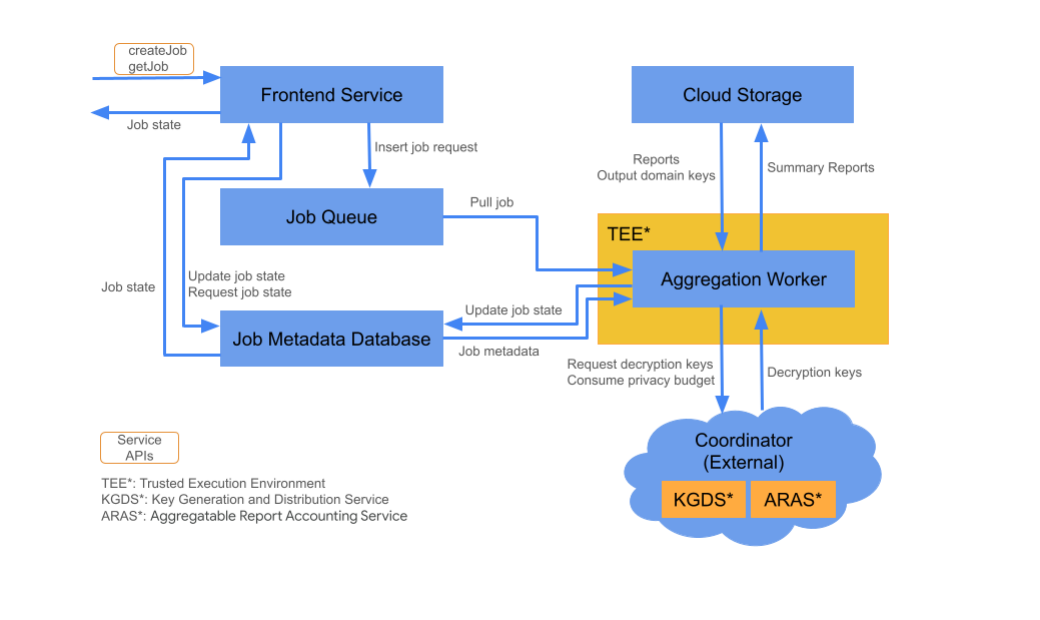
Usługa frontendu
Zarządzana usługa w chmurze: Cloud Functions (Google Cloud) / API Gateway (Amazon Web Services)
Usługa frontendu to bezserwerowa brama, która służy jako punkt wejścia do wywołań interfejsu Aggregation API służących do tworzenia zadań i pobierania ich stanu. Odpowiada on za otrzymywanie żądań od użytkowników usługi agregacji, sprawdzanie parametrów wejściowych i inicjowanie procesu planowania zadania agregacji.
W usłudze frontendu dostępne są 2 interfejsy API:
| Punkt końcowy | Opis |
|---|---|
createJob |
Ten interfejs API uruchamia zadanie usługi do agregacji. Wymaga ona informacji, które umożliwiają uruchomienie zadania, takich jak identyfikator zadania, szczegóły miejsca przechowywania danych wejściowych, szczegóły miejsca przechowywania danych wyjściowych, źródło raportu itp. |
getJob |
Ten interfejs API zwraca stan zadania o określonym identyfikatorze. Zawiera informacje o stanie zadania, takie jak „Otrzymano”, „W toku” lub „Ukończono”. Dodatkowo, jeśli zadanie zostało ukończone, wyświetla jego wynik, w tym komunikaty o błędach, które wystąpiły podczas jego wykonywania. |
Zapoznaj się z dokumentacją interfejsu API usługi do agregacji.
Kolejka zadań
Zarządzana usługa w chmurze: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
Kolejka zadań to kolejka wiadomości, która przechowuje żądania zadań dla usługi agregacji. Usługa frontendu wstawia do kolejki wiadomości z zapytaniami o zadanie, które są następnie wykorzystywane przez instancję roboczą agregacji do przetwarzania zapytania o zadanie.
Cloud Storage
Zarządzana usługa w chmurze: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) Pamięć w chmurze służy do przechowywania plików wejściowych i wyjściowych używanych przez usługę agregacji (np. zaszyfrowane pliki raportów, podsumowania wyjściowe itp.).
Baza danych metadanych zadania
Zarządzana usługa w chmurze: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Baza danych metadanych zadań przechowuje stan zadań agregacji i śledzi go. Baza danych rejestruje metadane, takie jak czas utworzenia, czas zgłoszenia, czas aktualizacji i stan (np. Otrzymano, W toku, Zakończono itp.). Procesor agregacji aktualizuje bazę danych metadanych zadań w miarę wykonywania zadania.
Zasób roboczy agregacji
Zarządzana usługa w chmurze: Compute Engine z Confidential space (Google Cloud) lub Amazon Web Services EC2 z Nitro Enclave (Amazon Web Services).
Proces agregacji przetwarza żądania zadań rozpoczęte przez żądanie zadania w kole zadań, odszyfrowując zaszyfrowane dane wejściowe za pomocą kluczy pobranych z usługi generowania i rozpowszechniania kluczy (KGDS) w koordynatorze. Aby zminimalizować opóźnienie przetwarzania zadania, klucze odszyfrowywania są przechowywane w pamięci podręcznej w instancji roboczej agregacji przez 8 godzin i mogą być używane w przypadku zadań przetwarzanych przez tę instancję roboczą.
Pracownik działa w środowisku Trusted Execution Environment (TEE). Każdy pracownik obsługuje tylko jedno zadanie naraz. Technologia reklamowa może skonfigurować wiele instancji roboczych do przetwarzania zadań równolegle, ustawiając konfigurację automatycznego skalowania. Dzięki automatycznemu skalowaniu liczba instancji roboczych jest dostosowywana dynamicznie do liczby wiadomości pozostających w kolejce zadań. Minimalną i maksymalną liczbę instancji roboczych do automatycznego skalowania można skonfigurować w pliku środowiska Terraform. Więcej informacji o autoskalowaniu znajdziesz w tych skryptach terraforma. [Amazon Web Services / Google Cloud]
Zasób roboczy agregacji wywołuje usługę księgowania raportów agregacji w celu księgowania raportów agregacji. Usługa księgowania raportów umożliwiająca agregację zapewni, że zadania będą wykonywane tylko do momentu przekroczenia limitu budżetu na potrzeby prywatności. (zobacz regułę „Brak duplikatów”). Jeśli budżet jest dostępny, na podstawie zbiorczych danych o wysokiej zmienności jest generowany raport podsumowujący. Dowiedz się więcej o rachunkowości w raportach możliwych do zsumowania.
Proces agregacji aktualizuje metadane zadania w bazie danych metadanych zadań, w tym odpowiednie kody zwracane przez zadanie i liczniki błędów raportów w przypadku częściowych błędów raportów. Użytkownicy mogą pobrać stan za pomocą interfejsu API do pobierania stanu zadania (getJob).
Bardziej szczegółowy opis usługi agregacji znajdziesz w tym artykule.
Dalsze kroki
Teraz, gdy znasz najważniejsze informacje o usłudze agregacji, możesz wdrożyć własną instancję tej usługi za pomocą Google Cloud lub Amazon Web Services. Zapoznaj się z sekcją Wprowadzenie. Jeśli potrzebujesz więcej informacji o działaniu wdrożonej usługi agregacji, kliknij ten link, aby dowiedzieć się więcej o działaniu usługi agregacji.
Rozwiązywanie problemów
Więcej informacji o komunikatach o błędach, ich przyczynach i sposobach ich rozwiązania znajdziesz w artykule Typowe kody błędów i sposoby ich rozwiązania.
Uzyskiwanie pomocy i przesyłanie opinii
- Aby zadać pytanie o usługę, przekazać opinię lub zgłosić prośbę o dodanie funkcji, utwórz zgłoszenie w naszym repozytorium GitHub.
- Jeśli podczas wdrażania, utrzymywania lub wykonywania zadań za pomocą usługi agregacji wystąpił błąd, możesz poprosić o pomoc techniczną, korzystając z tego formularza.
- Sprawdź panel stanu usługi Google Analytics, aby dowiedzieć się, czy wystąpiły znane problemy.