このドキュメントについて
このドキュメントの内容:
- 概要レポートを生成する前に、どのような戦略を作成すべきかを理解する。
- Noise Lab を紹介します。これは、さまざまなノイズ パラメータの影響を把握するのに役立ち、さまざまなノイズ マネジメント戦略を迅速に調査、評価できるツールです。
フィードバックをお寄せください
このドキュメントでは、概要レポートの使用に関する原則をいくつか要約しますが、 反映されない可能性のあるノイズ管理のアプローチは複数あります 見てみましょう。ご提案、追加、ご質問をぜひお寄せください。
- ノイズ マネジメント戦略について一般の人にフィードバックを提供するには、 API(イプシロン)のユーティリティやプライバシー(イプシロン)に使用したり、 Noise Lab によるシミュレーション: この問題にコメントする
- Noise Lab について公開フィードバックを提供するには(質問、バグの報告、 機能をリクエストする): こちらで新しい問題を作成してください
- API の別の側面について公開フィードバックを送信するには: こちらで新しい問題を作成してください
始める前に
- 概要については、アトリビューション レポート: サマリー レポートとアトリビューション レポートのシステム概要全体をご覧ください。
- このガイドを最大限に活用するには、「ノイズについて」と「集計キーについて」を確認してください。
設計上の意思決定
設計の基本原則
サードパーティ Cookie と概要レポートの動作には、基本的な違いがあります。重要な違いの一つは、 ノイズがサマリー レポートの測定データに追加されます。もう一つは、レポートのスケジュール設定です。
SN 比の高い概要レポートの測定データにアクセスするには デマンドサイド プラットフォーム(DSP)、広告測定プロバイダは、 広告主と協力してノイズ管理戦略を策定する。こうした戦略を策定するには、DSP と測定プロバイダが設計上の決定を行う必要があります。これらの決定は、次の 1 つの基本コンセプトを中心に展開されます。
分布ノイズ値は 2 つのパラメータ「イプシロン」と「寄与予算」に左右されるだけで、 出力された測定データのSN 比
反復的なプロセスが最良の決定につながると期待していますが、その決定のバリエーションは 実装が若干異なるため、これらの決定は、コード イテレーションのたびに(および広告を掲載する前)に行う必要があります。
決定: ディメンションの粒度
Noise Lab で試してみる
- Advanced モードに移動します。
- [パラメータ] サイドパネルで [コンバージョン データ] を探します。
- デフォルトのパラメータを確認します。デフォルトでは、1 日の アトリビューション可能なコンバージョン数は 1,000 ですこれは平均で約 40 (デフォルトのディメンション、デフォルトのサイズ、 キー戦略 A など)に異なる値が設定されます。次のことに注意してください。 入力される 1 日の平均アトリビューション可能なコンバージョン数に 40 が含まれている バケットごと。
- [シミュレーション] をクリックして、デフォルトのパラメータでシミュレーションを実行します。
- [パラメータ] サイドパネルで [ディメンション] を探します。名前を変更 [Geography] を [City] に変更し、選択できる値の数を 50 に変更します。
- これにより、アトリビューション可能な 1 日の平均コンバージョンがどのように変化するかを確認する バケットごとの最大数です。かなり低い数字になっています。これは、リソース使用量の上限を このディメンション内で取り得る値の数(変更なし) バケットの総数は増やさないままに 各バケットに含まれるコンバージョンイベントの数
- [シミュレート] をクリックします。
- 結果のシミュレーションのノイズ比を確認します。ノイズ比は 向上しています
設計の基本原則を考慮すると、小さいサマリー値は、 ノイズが多くなります。そのため構成の選択は 各バケットで貢献度が割り当てられたコンバージョン イベントの数に影響する 集計キーと呼ばれます)、その数量は 概要レポートを作成します
貢献度が割り当てられたコンバージョン イベントの数に影響する、1 つの設計上の決定事項 ディメンションの粒度です。次の例を考えてみましょう。 集計キーとそのディメンションです
- アプローチ 1: 大まかなディメンションを持つ 1 つのキー構造(国 × 広告キャンペーン(または最大のキャンペーン)) 集計バケット)× 商品カテゴリ(10 個の商品カテゴリのうち)
- アプローチ 2: 詳細なディメンションを持つ 1 つの主要構造: 都市 x クリエイティブ ID x 商品(100 個の可能な商品のうち)
[都市] は、[国] よりも詳細なディメンションです。[クリエイティブ ID] がより詳細に Campaign と比較します。[Product] は [Product type] よりも詳細です。したがって、 アプローチ 2 では、バケットあたりのイベント(コンバージョン)の数が少なくなります(つまり、 概要レポートの出力で、アプローチ 1 よりも高速になります。ノイズが加わったとすると、 出力はバケット内のイベント数、測定データ、 ノイズが多くなります。広告主様ごとに、 最大限の有効性を引き出すために、鍵の設計における粒度のトレードオフを 表示されます。
決定: キー構造
Noise Lab で試してみる
シンプル モードでは、デフォルトのキー構造が使用されます。Advanced さまざまなキー構造を試すことができます。ディメンションの例 含まれます。これらを変更することもできます。
- Advanced モードに移動します。
- パラメータ サイドパネルで [キー戦略] を探します。観測 デフォルトの戦略である A では、1 つの詳細なキーが すべてのディメンションを含む構造: 地域 x キャンペーン ID x 商品 あります。
- [シミュレート] をクリックします。
- 結果として得られるシミュレーションのノイズ比を確認します。
- 鍵戦略を B に変更します。ここには 構成する必要があります。
- 鍵の構造を構成します(例:次のとおりです。
<ph type="x-smartling-placeholder">
- </ph>
- キー構造の数: 2
- キー構造 1 = 地域 × 商品カテゴリ。
- キー構造 2 = キャンペーン ID x 商品カテゴリ。
- [シミュレート] をクリックします。
- 測定の目標タイプごとに 2 つのサマリー レポートが表示されることを確認します。 (購入回数に 2 つ、購入額に 2 つ)です。 2 つの異なるキー構造になっています。そのノイズ比を確認します。
- 独自のカスタム ディメンションで試すこともできます。そのためには、 [ディメンション] を選択します。この例を削除して、 [追加/削除/リセット] を使って独自のディメンションを作成したり、 最後のディメンションの下にボタンがあります
貢献度が割り当てられたコンバージョンの数に影響する、もう一つの設計上の決定事項 1 つのバケット内の各イベントには、 重要な構造 指定します。次の集計キーの例を考えてみましょう。
- すべてのディメンションを含む 1 つのキー構造これをキー戦略 A とします
- 2 つの主要な構造。それぞれにディメンションのサブセットがあります。これを 鍵戦略 B.
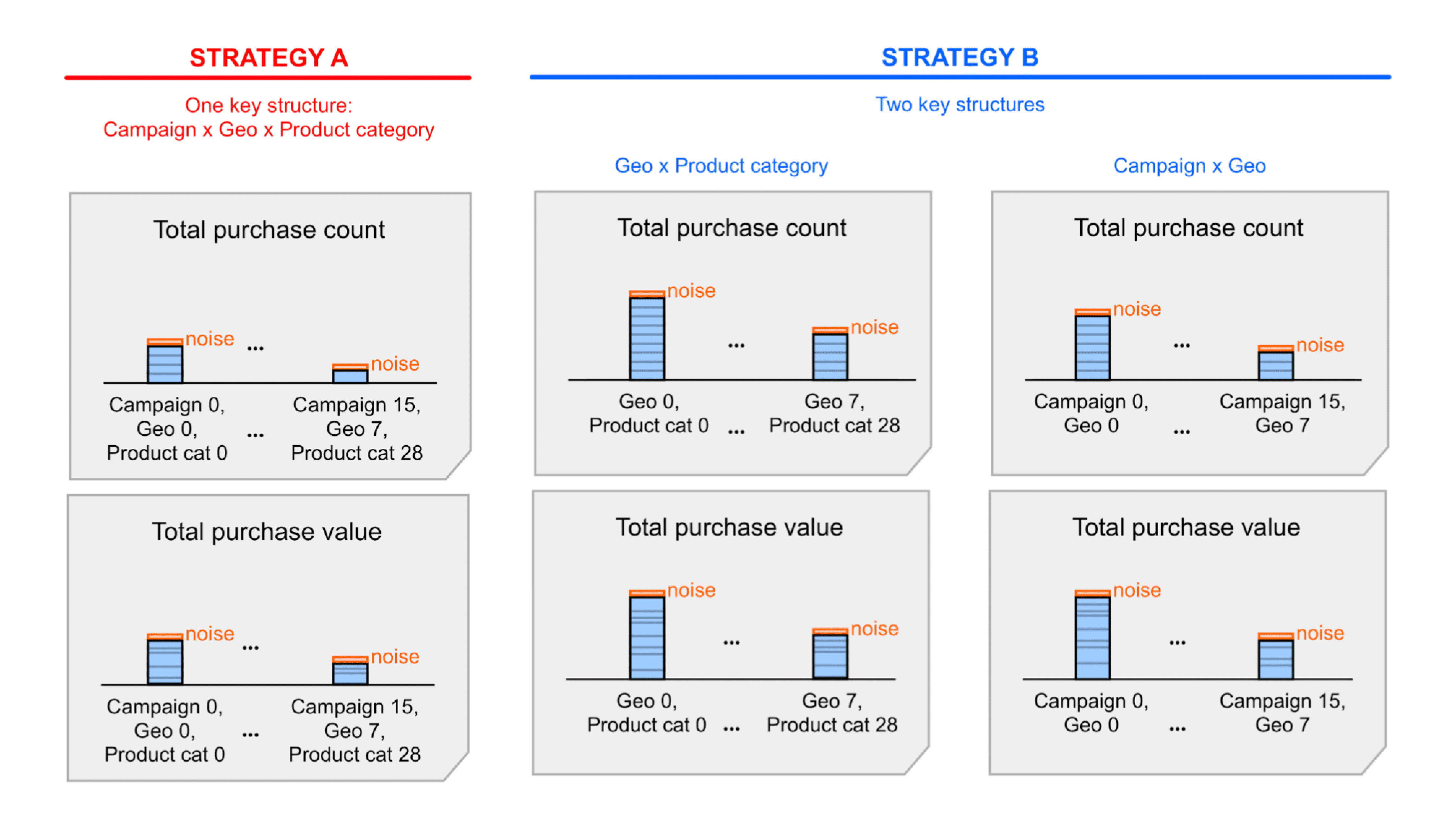
戦略 A はよりシンプルですが、特定の分析情報にアクセスするには、サマリー レポートに含まれるノイズの多いサマリー値をまとめる(合計)必要があります。これらの値を合計すると、ノイズも合計されます。 戦略 B では、サマリーの値がサマリーで公開される 必要な情報がすでにレポートに表示されているかもしれません。つまり戦略 B は 戦略 A よりも SN 比が高くなる傾向があります。ただし、 ノイズを許容できる戦略 A では、 簡素化のための戦略 A これら 2 つの戦略の概要を示す詳細な例で詳細をご確認ください。
鍵管理は深いトピックです。さまざまな巧妙な手法を SN 比を改善すると考えられます1 つは、Advanced Key 管理をご覧ください。
決定: バッチ処理の頻度
Noise Lab で試してみる
- シンプル モード(または詳細モード)に移動します。どちらのモードも (バッチ処理頻度に関しても同様)
- [パラメータ] サイドパネルで [集計方法] を確認する >バッチ処理の頻度。これは Pod のバッチ処理頻度を 集計サービスを使用して処理される集計可能レポート。 できます。
- デフォルトのバッチ処理頻度を確認します(デフォルトでは 1 日 1 回)。 シミュレートされたものです。
- [シミュレート] をクリックします。
- 結果として得られるシミュレーションのノイズ比を確認します。
- バッチ処理頻度を週単位に変更します。
- 結果のシミュレーションのノイズ比を確認します。ノイズ比は 以前のシミュレーションよりも低く(改善されています)
貢献度が割り当てられたコンバージョンの数に影響する、もう一つの設計上の決定事項 使用するバッチ処理頻度です「 バッチ処理頻度は、集計可能レポートを処理する頻度です。
より頻繁に(毎時など)集計するようにスケジュール設定されたレポートは、 含まれているコンバージョン イベント数が、同じレポートより少ない、頻度が低い 集計スケジュール(毎週など)。そのため、時間別レポートにより多くのノイズが含まれます。``` 含まれているコンバージョン イベント数が、同じレポートより少ない、頻度が低い 集計スケジュール(毎週など)。その結果 時間別レポートには 他の条件がすべて同じであれば、SN 比は週次レポートよりも低くなります。さまざまな周波数でレポート要件をテストし、それぞれの信号対雑音比を評価します。
決定事項: アトリビューション可能なコンバージョンに影響するキャンペーン変数
Noise Lab で試してみる
予測は困難で、モデルによって予測に 季節性による影響に加え 1 日あたりの収益を推定して シングルタッチに起因するコンバージョン数を、最も近い 10 のべき乗数(10、100、 1,000 または 10,000 です。
- Advanced モードに移動します。
- [パラメータ] サイドパネルで [コンバージョン データ] を探します。
- デフォルトのパラメータを確認します。デフォルトでは、1 日の アトリビューション可能なコンバージョン数は 1,000 ですこれは平均で約 40 (デフォルトのディメンション、デフォルトのサイズ、 キー戦略 A など)に異なる値が設定されます。次のことに注意してください。 入力される 1 日の平均アトリビューション可能なコンバージョン数に 40 が含まれている バケットごと。
- [シミュレーション] をクリックして、デフォルトのパラメータでシミュレーションを実行します。
- 結果として得られるシミュレーションのノイズ比を確認します。
- 次に、1 日の貢献度が割り当てられたコンバージョンの合計数を 100 に設定します。 これにより、アトリビューション モデルによる バケットあたりのコンバージョン数です
- [シミュレート] をクリックします。
- ノイズ比が高くなっていることがわかります。これは、 バケットあたりのコンバージョン数が少なくなると、維持のために適用されるノイズが増えます プライバシーを保護する。
重要な違いは、1 つのキャンペーンで見込まれるコンバージョンの合計数です。 と、貢献度が割り当てられたコンバージョンの推定合計数との比較。「 後者の場合、最終的に概要レポートのノイズに影響を及ぼします。アトリビューション済み コンバージョンは、キャンペーンにつながる可能性が高い合計コンバージョン数の一部です。 広告予算や広告のターゲット設定といった変数です。たとえば、1 対 1 の 貢献度が割り当てられたコンバージョン数の伸び 他の条件がすべて同じ場合です
注意点:
- 貢献度が割り当てられたコンバージョンを、シングルタッチの同一デバイスと比較する アトリビューション モデル。これらは概要レポートの対象です。 データデータを収集および分析できます
- 最悪のケースのシナリオ数とベストケースのシナリオ数の両方を考慮する 確認できますたとえば他の条件がすべて同じならば 広告主様が設定可能なキャンペーン予算の最低額と最高額 両方の成果のアトリビューション可能なコンバージョンを あります。
- 「新規顧客の獲得」目標を Android 向けプライバシー サンドボックス クロス プラットフォームでも貢献度が割り当てられたコンバージョンを重視する。
決定: スケーリングの使用
Noise Lab で試してみる
- Advanced モードに移動します。
- [パラメータ] サイドパネルで [集計方法] を確認する >スケーリング。デフォルトでは [はい] に設定されています。
- ノイズに対するスケーリングによるプラスの影響を理解するため 最初に [Scaling] を [No] に設定します。
- [シミュレート] をクリックします。
- 結果として得られるシミュレーションのノイズ比を確認します。
- [Scaling] を [Yes] に設定します。なお、Noise Lab は 使用されるスケーリング ファクタ。 シナリオの測定目標を設定します実際のシステム トライアルまたはオリジン トライアル スケーリング ファクタを独自に計算することをおすすめします。
- [シミュレート] をクリックします。
- 2 回目のノイズ比が低減(改善)したことを確認する あります。これはスケーリングを使用しているためです。
設計の基本原則に基づき、追加されるノイズは 資金提供予算の関数で表します
したがって、SN 比を高めるために コンバージョン イベント中に収集された値についてスケーリングを行い、 拠出予算(集計後にデスケーリング)する。スケーリングを使用して信号対雑音比を上げます。
決定事項: 測定目標の数とプライバシー バジェットの配分
これはスケーリングに関連します。必ず スケーリング。
Noise Lab で試してみる
測定目標とは、コンバージョン イベントで収集される個別のデータポイントです。
- Advanced モードに移動します。
- [パラメータ] サイドパネルで、トラッキングするデータを探します。 測定目標デフォルトでは、購入という 2 つの測定目標があります。 購入数などです
- [シミュレーション] をクリックして、デフォルトの目標でシミュレーションを実行します。
- [削除] をクリックします。これにより、最後の測定目標(購入)が削除されます。 カウントされます)。
- [シミュレート] をクリックします。
- 購入額に対するノイズ率が下がったことを確認する (良い)結果です。これは、以前のモデルよりも 1 つの測定目標に すべてのコンバージョンを 拠出予算。
- [リセット] をクリックします。ここでも、測定の目標が 2 つになりました。購入 購入数などですなお、Noise Lab は スケーリング ファクタを使用して、モデルの シナリオに適した測定目標を選択できますデフォルトでは、ノイズラボは 測定目標ごとに予算を均等に配分する
- [シミュレート] をクリックします。
- 結果として得られるシミュレーションのノイズ比を確認します。以下の点に注意してください。 スケーリング ファクタが表示されます。
- 次に、プライバシー バジェットの配分をカスタマイズして、 信号対雑音比
- 各測定目標に割り当てられた予算の割合を微調整する。デフォルトの 「購入額」というパラメータがあり、 範囲(0 ~ 1, 000)が測定目標 2 よりも広い 購入回数(1 ~ 1、つまり常に 1 に等しい)。理由 「スケーリングするスペースがより多く」必要です。より多くのスペースを 測定目標 2 よりも測定目標 1 に貢献度が割り当てられるので、 より効率的にスケールアップできます(「スケーリング」を参照)。したがって、
- 予算の 70% を測定目標 1 に割り当てる。測定に 30% を割り当てる 目標 2.
- [シミュレート] をクリックします。
- 結果として得られるシミュレーションのノイズ比を確認します。購入可能 ノイズ比が以前の 2.5 よりも大幅に低い(改善) あります。購入回数はほぼ変わりません。
- 複数の指標の予算配分を継続的に調整します。これによる影響を観察する ノイズを軽減できます。
なお、 追加/削除/リセットボタン。
コンバージョン イベントについて 1 つのデータポイント(測定目標)を測定する場合 そのデータポイントはすべて、貢献度の高い予算(65536)を取得できます。1 つのコンバージョンイベントに複数の測定目標を設定した場合は コンバージョンの数や購入額などのデータを表示する場合は、 寄付の予算を共有します。つまり、インフラストラクチャを 使用できます。
そのため、測定目標を多く設定するほど、SN 比は低くなる (ノイズの増加)の可能性が高くなります。
測定目標については予算の配分も決める必要があります。資金提供予算を 2 つのデータポイントに均等に分割すると、各データポイントに 65536÷2 = 32768 となります。状況によっては、これが最適な場合もあれば、そうでない場合もあります。 各データポイントの最大可能な値。たとえば 購入回数は 1 で、購入額は 1 です。 最小 1 から最大 120 の範囲で指定すると、 "スペースの拡大"すなわち、実際のイベント数の割合を大きくして、 拠出予算。優先すべき測定目標があるかどうかを確認できる ノイズの影響との関係が明確になります。
決定: 外れ値管理
Noise Lab で試してみる
測定目標とは、コンバージョン イベントで収集される個別のデータポイントです。
- Advanced モードに移動します。
- [パラメータ] サイドパネルで [集計方法] を確認する >スケーリング。
- [スケーリング] が [はい] に設定されていることを確認します。なお、Noise Lab 使用されるスケーリング ファクタは、 測定目標に対して指定した範囲(平均値と最大値)です。
- これまでの最大購入額は 2, 000 ドルでした ほとんどの購入は 10 ~ 120 ドルの範囲で行われています。まずはじめに リテラルのスケーリング アプローチを使用する場合(非推奨): 値として $2000 を入力します。 purchaseValue の最大値。
- [シミュレート] をクリックします。
- ノイズ比が高いことを確認します。これは、Google Cloud の ファクターは現在 2, 000 ドルに基づいて計算されますが、 大幅に低くなっています
- では、より実用的なスケーリング アプローチを使ってみましょう。最大値を変更する 120 ドルになります
- [シミュレート] をクリックします。
- この 2 番目のシミュレーションではノイズ比が低い(良い)ことがわかります。
スケーリングを実装するには、通常、基準値に基づいてスケーリング ファクタを計算します。 特定のコンバージョン イベントの最大値 (こちらの例で詳細をご覧ください)。
ただし、スケーリング ファクタの計算にリテラルの最大値を使用することは避けてください。 信号雑音比が悪化します代わりに、外れ値を削除して、 現実的な最大値を使用します
外れ値の管理は深いトピックです。さまざまな巧妙な手法を SN 比を改善すると考えられます1 つは、 高度な外れ値管理。
次のステップ
ユースケースに対するさまざまなノイズ マネジメント戦略を評価したところで、 実際のデータを収集して 概要レポートを試す準備が整いました オリジン トライアルを介して測定します。API を試すためのガイドとヒントを確認する。
付録
Noise Lab のクイックツアー
Noise Lab は、 ノイズ管理戦略を評価、比較できます。たとえば次のような操作が可能です。
- ノイズに影響を与える可能性のある主なパラメータと、 影響します。
- 指定された出力測定データに対するノイズの影響をシミュレートする さまざまな設計上の決定事項があります。設計パラメータを微調整して 信号対雑音比を選択できます
- 概要レポートの有用性について、ご意見をお聞かせください。 イプシロン パラメータとノイズ パラメータの値は適切ですが、正しくないものはどれでしょうか?現在地 どうすればよいでしょうか。
これは準備のステップだと考えてください。ノイズラボ 概要レポートの出力をシミュレートするために、 表示されます。データは保持されず、共有もされません。
Noise Lab には 2 つのモードがあります。
- シンプル モード: 使用できるコントロールの基礎知識 考えています
- 詳細モード: さまざまなノイズ マネジメント戦略をテストして評価 ユースケースに最適な SN 比が得られます
2 つのオプションを切り替えるには、上部のメニューのボタンをクリックします。 (以下のスクリーンショットの 1 番目)。
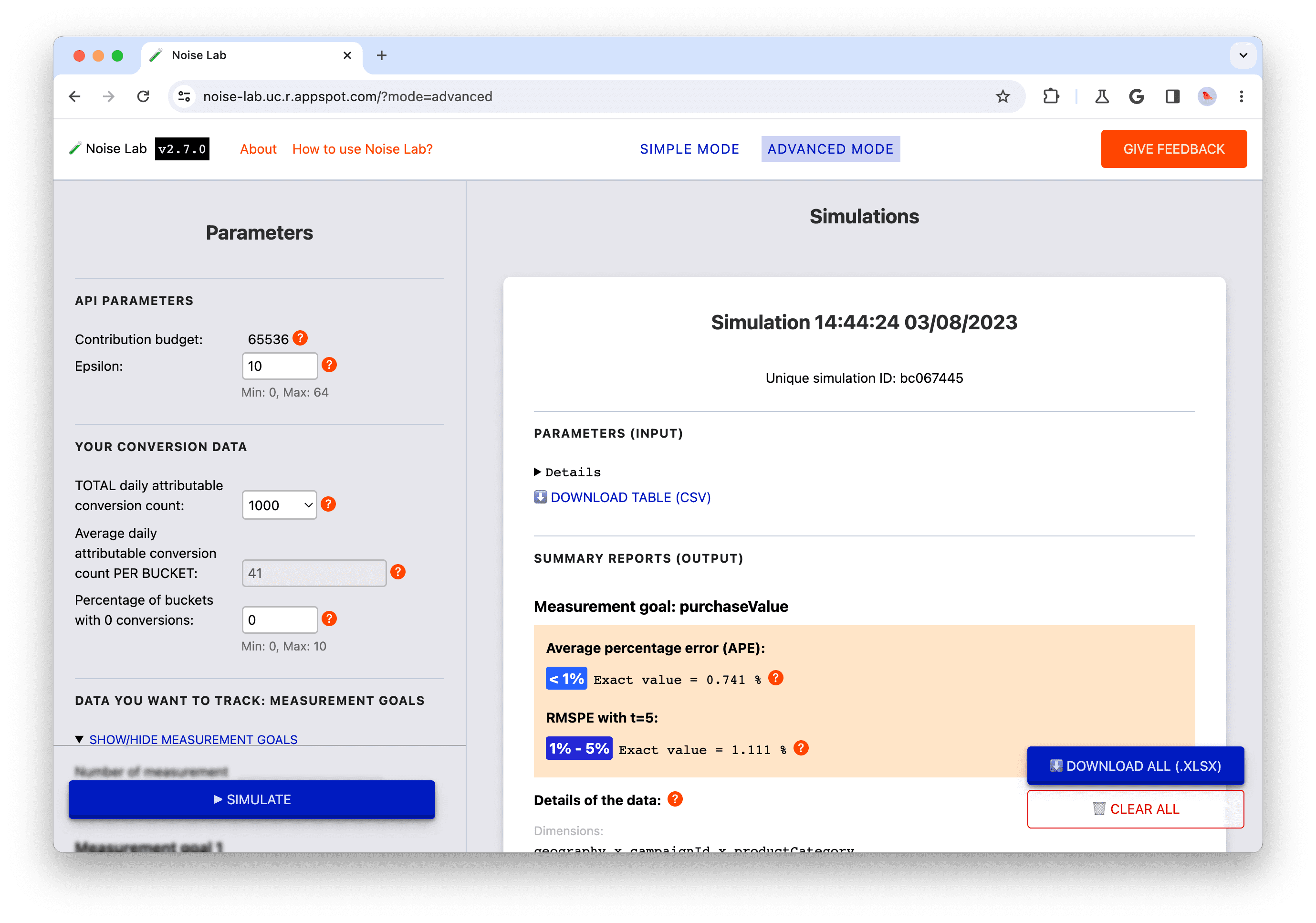
シンプル モード
- シンプル モードでは、画面左側の #2.(以下のスクリーンショット)でテストして、それらがノイズに与える影響を確認してください。
- 各パラメータにはツールチップ(`?` ボタン)があります。ここをクリックすると 各パラメータの説明(以下のスクリーンショットの#3)
- [シミュレーション]をクリックして出力がどうなるかを観察します。 (以下のスクリーンショットの#4)
- [Output(出力)] セクションには、さまざまな詳細が表示されます。一部 要素の横に `?` が付いています。時間をかけて各 `?` をクリックして、 情報の説明が表示されます。
- [Output] セクションで [Details] 切り替えをクリックする 表を展開して表示する場合(下のスクリーンショットの#5)
- output セクションの各データテーブルの下には オフラインで使用するためにテーブルをダウンロードします。また、画面下部には 右隅に、すべてのデータ表(#6. 以下のスクリーンショットを参照してください)
- [パラメータ] セクションでパラメータのさまざまな設定をテストする
[シミュレート] をクリックして出力への影響を確認します。
<ph type="x-smartling-placeholder">
</ph> 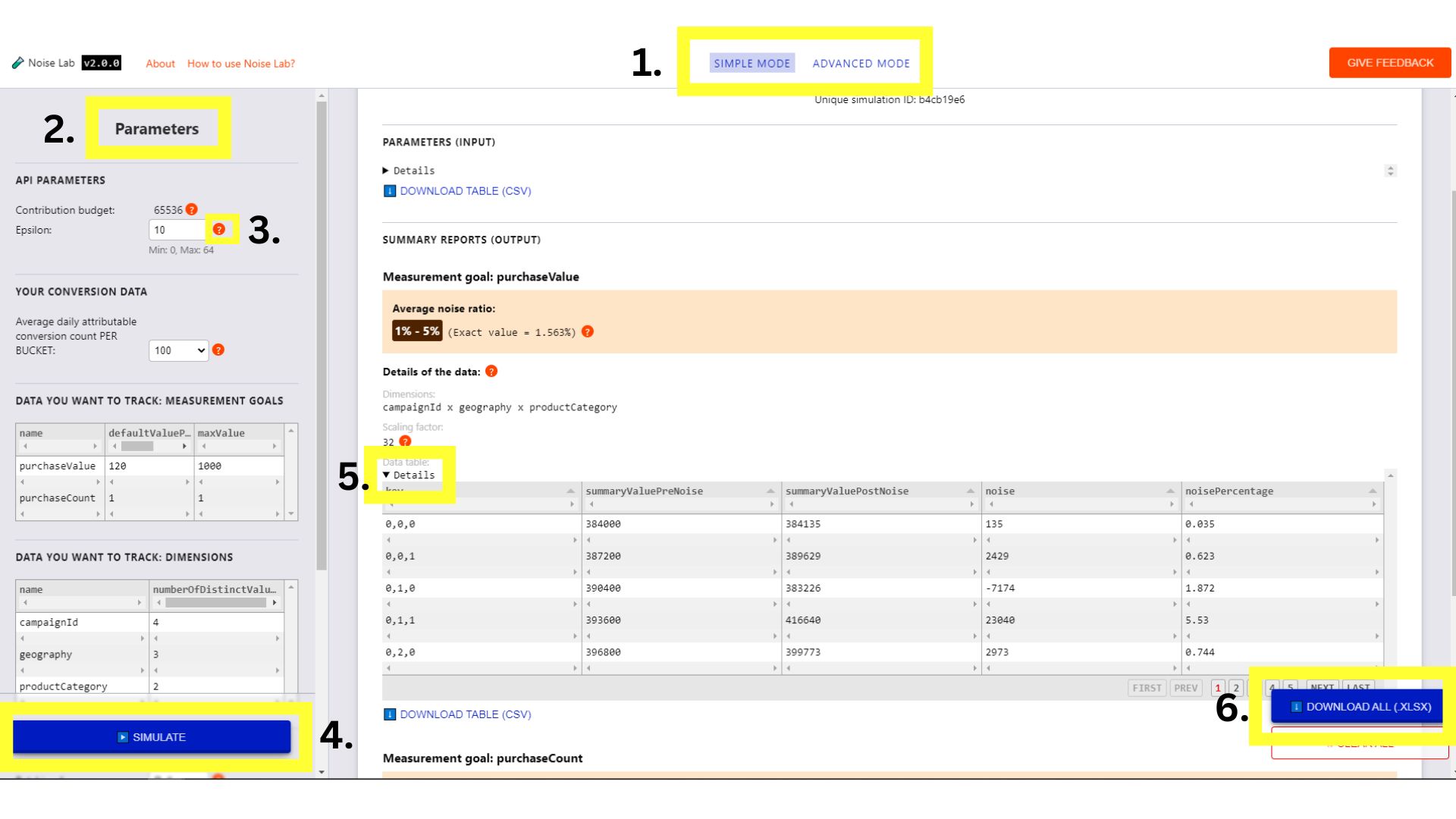
シンプルモードの Noise Lab インターフェース。
上級者モード
- 詳細モードでは、パラメータをより詳細に制御できます。マイページ カスタムの測定目標とディメンションを追加できます(スクリーンショットの #1. と #2.)。 ご覧ください)。
- [パラメータ] セクションを下にスクロールし、[キー] を確認します。
戦略オプション。これを使用して、さまざまなキー構造をテストできます。
(以下のスクリーンショットの#3)。
<ph type="x-smartling-placeholder">
- </ph>
- さまざまなキー構造をテストするには、キー戦略を「B」に切り替えてください
- 使用するさまざまなキー構造の数を入力します (デフォルトは「2」)
- [Generate Key Structures] をクリックします。
- [保存] をクリックすると、キーの構造を指定するオプションが表示されます。 各キー構造に含めるキーの横のチェックボックス
- [シミュレーション] をクリックして出力を確認します。
<ph type="x-smartling-placeholder">
</ph> で確認できます。 <ph type="x-smartling-placeholder">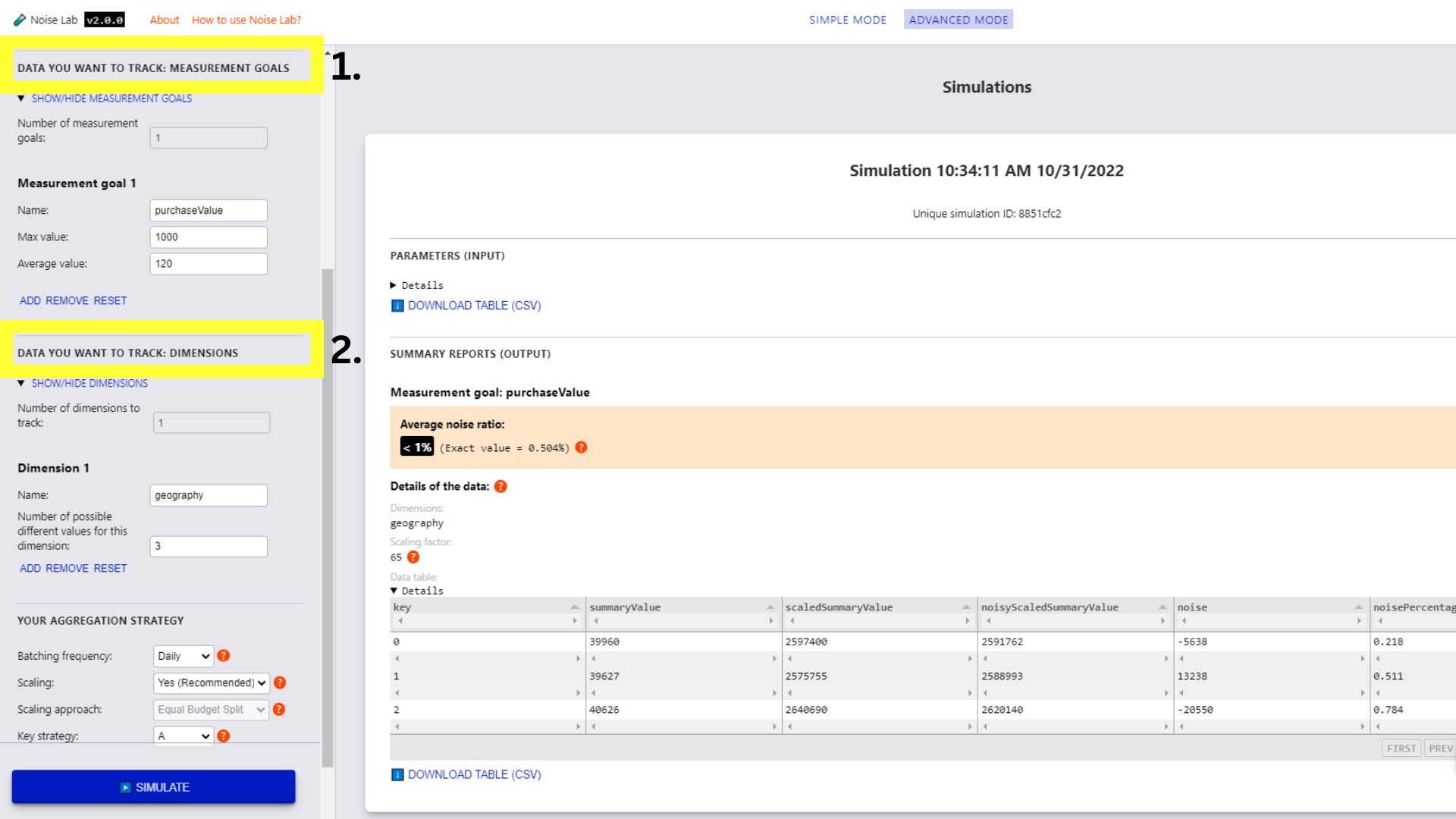
詳細モードの Noise Lab インターフェース。 </ph> ![詳細モードには、サイドバーの [パラメータ] セクションにある [鍵戦略] オプションもあります。](https://developers.google.cn/static/privacy-sandbox/assets/images/advanced-mode-a-key-stra-281e1fb56a289.jpg?authuser=1&hl=ja)
Advanced モードの Noise Lab インターフェース
ノイズ指標
基本コンセプト
個々のユーザーのプライバシーを保護するためにノイズが追加されます。
ノイズ値が高い場合、バケット/キーがスパースで 限られた数のデリケートな事象からの貢献を含みます。完了 個人が「群衆の中に隠れ」できるようにし、または 言い換えると、限られた人々のプライバシーを保護し、プライバシーを保護しながら、 ノイズが追加されます。
ノイズ値が低い場合、データ設定が すでに「群衆の中に隠す」ことができるようなものです。つまり、 バケットには十分な数のイベントからの寄与が含まれており プライバシーが保護されます。
このことは、平均誤差率(APE)と RMSRE_T(しきい値を伴う二乗平均平方根相対誤差)です。
APE(平均誤差率)
APE は、シグナルに対するノイズの比率、つまり真のサマリー値です。p> APE 値が小さいほど、信号雑音比が良くなります。
数式
特定の概要レポートで、APE は次のように計算されます。
<ph type="x-smartling-placeholder">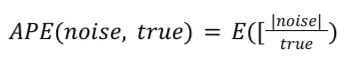
True は実際のサマリー値です。APE は、各ノードでのノイズの平均です。 サマリー レポートの全エントリの平均値。 Noise Lab では、これに 100 を掛けてパーセンテージを算出します。
長所と短所
サイズが小さいバケットは、APE の最終的な値に大きな影響を与えます。ノイズを評価する際に紛らわしい可能性があります。そのため、APE の制限を緩和するために設計された別の指標、RMSRE_T を追加しました。詳しくは、例をご覧ください。
コード
ソースコードを確認する 。
RMSRE_T(しきい値を伴う二乗平均平方根相対誤差)
RMSRE_T(しきい値を伴う二乗平均平方根相対誤差)もノイズの尺度です。
RMSRE_T の解釈方法
RMSRE_T 値が小さいほど、信号対雑音比が優れていることを意味します。
たとえば、ユースケースで許容されるノイズ比が 20% で、RMSRE_T が 0.2 であれば、ノイズレベルが許容範囲内であると確信できます。
数式
概要レポートの RMSRE_T は次のように計算されます。
<ph type="x-smartling-placeholder">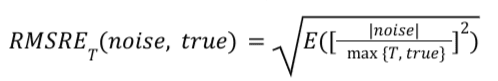
長所と短所
RMSRE_T は、APE よりも把握が少し複雑です。ただし、次のような利点があるため、概要レポートのノイズ分析には APE よりも適している場合もあります。
- RMSRE_T の安定性が向上しました。「T」しきい値です「T」は、RMSRE_T の計算で、コンバージョン数が少なく、サイズが小さいためにノイズの影響を受けやすいバケットに重み付けを小さくするために使用します。「T」の場合、コンバージョン数の少ないバケットで指標は急増しません。T が 5 の場合、コンバージョンが 0 のバケットではノイズ値が 1 でも、ノイズ値は 1 より大きく表示されなくなります。代わりに、T が 5 であるため、0.2 が上限となります。これは 1/5 に相当します。ノイズの影響を受けやすい小さいバケットに重みを小さくすると、この指標の安定性が高まり、2 つのシミュレーションを比較しやすくなります。
- RMSRE_T を使用すると集計が容易になります。複数のバケットの RMSRE_T とその実際の数を知ることで、それらの合計の RMSRE_T を計算できます。これにより、これらの組み合わせた値に対して RMSRE_T を最適化することもできます。
APE では集計が可能ですが、ラプラスノイズの合計の絶対値が関係するため、この数式は非常に複雑です。このため、APE の最適化が難しくなります。
コード
RMSRE_T の計算のソースコードを確認します。
例
3 つのバケットを含む概要レポート:
- バケット 1 = ノイズ: 10、trueSummaryValue: 100
- バケット 2 = ノイズ: 20、trueSummaryValue: 100
- バケット 3 = ノイズ: 20、trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) ÷ 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
3 つのバケットを含む概要レポート:
- バケット 1 = ノイズ: 10、trueSummaryValue: 100
- バケット 2 = ノイズ: 20、trueSummaryValue: 100
- バケット 3 = ノイズ: 20、trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) ÷ 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
3 つのバケットを含む概要レポート:
- バケット 1 = ノイズ: 10、trueSummaryValue: 100
- バケット 2 = ノイズ: 20、trueSummaryValue: 100
- バケット 3 = ノイズ: 20、trueSummaryValue: 0
APE = (0.1 + 0.2 + 無限大) / 3 = 無限大
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
高度な鍵管理
DSP や広告測定会社では、グローバルに数千もの広告を掲載している さまざまな業種、通貨、購入価格に及ぶお客様 向上しますつまり、サービスごとに 1 つの集計キーを作成して 実用性が低い可能性があります。また、 最大集計可能な値と集計予算を選ぶのは グローバルに展開する数千社の広告主様に対するノイズの影響を抑えます。代わりに 次のシナリオを考えてみましょう
主要戦略 A
広告テクノロジー プロバイダが、すべての広告枠で 1 つのキーを作成して管理することに 広告業界のお客様ですすべての広告主とすべての通貨にわたって、 購入額は、ボリュームが少ない価格から高額購入のものからローエンドのものまで多岐にわたります。 購入します。これにより、次のキーが生成されます。
| キー(複数の通貨) | |
|---|---|
| 集計可能な最大値 | 5,000,000 |
| 購入額の範囲 | [120 ~ 5000000] |
主要戦略 B
広告テクノロジー プロバイダが、広告テクノロジーの全域で 2 つのキーを作成して管理することに 広告業界のお客様ですそこで、鍵を通貨別に分けることにしました。全般 広告主、すべての通貨に対応しているため、購入の範囲も少量、 高額な購入をローエンドの高額購入へとつなげています。通貨の区切り、 次の 2 つの鍵が作成されます。
| キー 1(米ドル) | キー 2(¥) | |
|---|---|---|
| 集計可能な最大値 | $40,000 | 5,000,000 円 |
| 購入額の範囲 | [120 ~ 40,000 人] | [15,000 ~ 5,000,000] |
キー戦略 B では、結果のノイズがキー戦略 A よりも少なくなります。これは、 通貨の値が通貨間で均一に分散されるわけではありません。たとえば 米ドル建てと日本円建てでの購入がどのように混在しているのかを考慮します。 USD は基になるデータを変更し、ノイズの多い出力を生成します。
重要戦略 C
広告テクノロジー プロバイダが、広告技術プロバイダ 「通貨 × 広告主」で分類する 業種:
| キー 1 (米ドル × 高級ジュエリーの広告主様) |
キー 2 (¥ × 高級ジュエリーの広告主様) |
キー 3 (米ドル × 衣料品小売業者の広告主様) |
キー 4 (¥ × 衣料品小売業者の広告主) |
|
|---|---|---|---|---|
| 集計可能な最大値 | $40,000 | 5,000,000 円 | $500 | 65,000 円 |
| 購入額の範囲 | [10,000 ~ 40,000 人] | [1,250,000 ~ 5,000,000] | [120 ~ 500] | [15,000 ~ 65,000 人] |
キー戦略 C の結果はキー戦略 B よりもノイズが少なくなります。なぜなら、 広告主の購入額が広告主間で一様に配分されることはない。対象 たとえば 高級ジュエリーの購入と 基になるデータが変更され、ノイズの多い出力が生成されます。
共有される最大集計値と共有スケーリング ファクタを作成することを検討してください 重複を解消してノイズを軽減するために、 出力です。たとえば、特定のキャンペーンを対象とした以下のさまざまな戦略を 次のようなメリットがあります
- 通貨(米ドル、円、カナダドルなど)ごとに分けた 1 つの戦略
- 広告主様の業種(保険、自動車、 小売など)
- 類似した購入額の範囲([100]、 [1000]、[10000] など)
広告主の共通性、キー、 対応するコードが管理しやすくなり、信号雑音比が 高くなります。さまざまな広告主でさまざまな戦略を試す コードと比較してノイズの影響を最大化する際の変曲点を明らかにする共通点 あります。
高度な外れ値管理
次の 2 社の広告主様に関するシナリオを考えてみましょう。
- 広告主 A:
- 広告主 A のサイトのすべての商品における購入価格 可能性は [$120 - $1,000] で、価格帯は $880 です。
- 購入価格は 880 ドルの範囲に均等に配分されている 購入価格の中央値から 2 標準偏差の範囲外に外れ値は生じません。
- 広告主 B:
- 広告主 B のサイトのすべての商品における購入価格 可能性は [$120 - $1,000] で、価格帯は $880 です。
- 購入価格が 120 ~ 500 ドルの範囲に大きく偏っている。 500 ~ 1,000 ドルの範囲内で発生した購入は全体の 5% のみ。
与えられた 資金提供の予算の要件 結果にノイズを適用する方法によって、広告主 B のデフォルトではノイズが 広告主 A。広告主 B は、外れ値によって 基になる計算です。
この問題は、特定の鍵の設定で軽減できます。主要な戦略をテストする 外れ値データの管理と購入額のより均一な配分に役立ちます 鍵の購入範囲全体にわたります
広告主 B では、2 つの異なるキーを作成して、2 つの異なる 購入額の範囲などですこの例では、広告テクノロジーが外れ値が 500 ドルの購入額の上に表示される。アプリケーションごとに 2 つの異なるキーを実装し、 この広告主:
- キー構造 1 : 次の期間の購入のみをキャプチャするキー 120 ~ 500 ドル(合計購入数の約 95% を占める)という価格帯。
- キー構造 2: $500 を超える購入のみをキャプチャするキー (総購入数の約 5% をカバー)。
この重要な戦略を実践すれば、広告主 B と広告主様 概要レポートから最大限に活用できます新しい キー A とキー B のデータの分布が均一になりました その前の単一キーの結果を 返すことができますその結果 前の単一キーよりも、各キーの出力におけるノイズの影響が小さくなる。