About this document
By reading this document, you will:
- Understand what strategies to create before generating summary reports.
- Be introduced to Noise Lab, a tool that helps grasp the effects of various noise parameters, and that enables quick exploration and assessment of various noise management strategies.
Share your feedback
While this document summarizes a few principles to work with summary reports, there are multiple approaches to noise management that may not be reflected here. Your suggestions, additions, and questions are welcome!
- To give public feedback on noise management strategies, on utility or privacy of the API (epsilon), and to share your observations when simulating with Noise Lab: Comment on this issue
- To give public feedback on Noise Lab (ask a question, report a bug, request a feature): Create a new issue here
- To give public feedback on another aspect of the API: Create a new issue here
Before you start
- Read Attribution Reporting: summary reports and Attribution Reporting full system overview for an introduction.
- Scan Understanding noise and Understanding aggregation keys to make best use of this guide.
Design decisions
Core design principle
There are foundational differences between how third-party cookies and summary reports operate. One key difference is the noise added to measurement data in summary reports. Another is how reports are scheduled.
To access summary report measurement data with higher signal-to-noise ratios, demand-side platforms (DSPs) and ad measurement providers will need to work with their advertisers to develop noise management strategies. To develop these strategies, DSPs and measurement providers need to make design decisions. These decisions revolve around one essential concept:
While the distribution noise values are drawn from, absolutely speaking, only depends on two parameters⏤epsilon and the contribution budget⏤you have a number of other controls at your disposal that will impact the signal-to-noise ratios of your output measurement data.
While we expect an iterative process will lead to the best decisions, each variation on these decisions will lead to a slightly different implementation—thus these decisions must be taken before writing each code iteration (and before running ads).
Decision: Dimension granularity
Try it out in Noise Lab
- Go to Advanced mode.
- In the Parameters side panel, look for Your conversion data.
- Observe the default parameters. By default, the TOTAL daily attributable conversion count is 1000. This averages to roughly 40 per bucket if you use the default setup (default dimensions, default number of possible different values for each dimension, Key strategy A). Observe that the value is 40 in the input Average daily attributable conversion count PER BUCKET.
- Click Simulate to run a simulation with the default parameters.
- In the Parameters side panel, look for Dimensions. Rename Geography to City and change the number of possible different values to 50.
- Observe how this changes the Average daily attributable conversion count PER BUCKET. It's now much lower. This is because if you increase the number of possible values within this dimension without changing anything else, you increase the total number of buckets without changing how many conversion events will fall in each bucket.
- Click Simulate.
- Observe the noise ratios of the resulting simulation: noise ratios are now higher than for the previous simulation.
Given the core design principle, small summary values are likely to be more noisy than large summary values. Therefore, your configuration choice impacts how many attributed conversion events end up in each bucket (otherwise referred to as your aggregation key), and that quantity impacts noise in the final output summary reports.
One design decision that impacts the number of attributed conversion events within a single bucket is dimension granularity. Consider the following examples of aggregation keys and their dimensions:
- Approach 1: one key structure with coarse dimensions: Country x Ad Campaign (or the largest campaign aggregation bucket) x Product Type (out of 10 possible product types)
- Approach 2: one key structure with granular dimensions: City x Creative ID x Product (out of 100 possible products)
City is a more granular dimension than Country; Creative ID is more granular than Campaign; and Product is more granular than Product type. Therefore, Approach 2 will have a lower number of events (conversions) per bucket (= per key) in its summary report output than Approach 1. Given that the noise added to the output is agnostic to the number of events in the bucket, measurement data in summary reports will be more noisy with Approach 2. For each advertiser, experiment with various granularity tradeoffs in the key's design in order to have maximum utility in the results.
Decision: Key structures
Try it out in Noise Lab
In the Simple mode, the default key structure is used. In the Advanced mode, you can experiment with different key structures. Some example dimensions are included; you can also modify these.
- Go to Advanced mode.
- In the Parameters side panel, look for Key strategy. Observe that the default strategy, named A in the tool, uses one granular key structure that includes all dimensions: Geography x Campaign ID x Product category.
- Click Simulate.
- Observe the noise ratios of the resulting simulation.
- Change the Key strategy to B. This displays additional controls for you to configure your key structure.
- Configure your key structure e.g. as follows:
- Number of key structures: 2
- Key structure 1 = Geography x Product category.
- Key structure 2 = Campaign ID x Product category.
- Click Simulate.
- Observe that you now get two summary reports per measurement goal type (two for purchase count, two for purchase value), given that you're using two distinct key structures. Observe their noise ratios.
- You can also try this with your own custom dimensions. To do so, look for Data you want to track: Dimensions. Consider removing the example dimensions, and creating your own using the Add/Remove/Reset buttons below the last dimension.
Another design decision that will impact the number of attributed conversion events within a single bucket is the key structures you decide to use. Consider the following examples of aggregation keys:
- One key structure with all dimensions; let's call this Key Strategy A.
- Two key structures, each with a subset of dimensions; let's call this Key Strategy B.
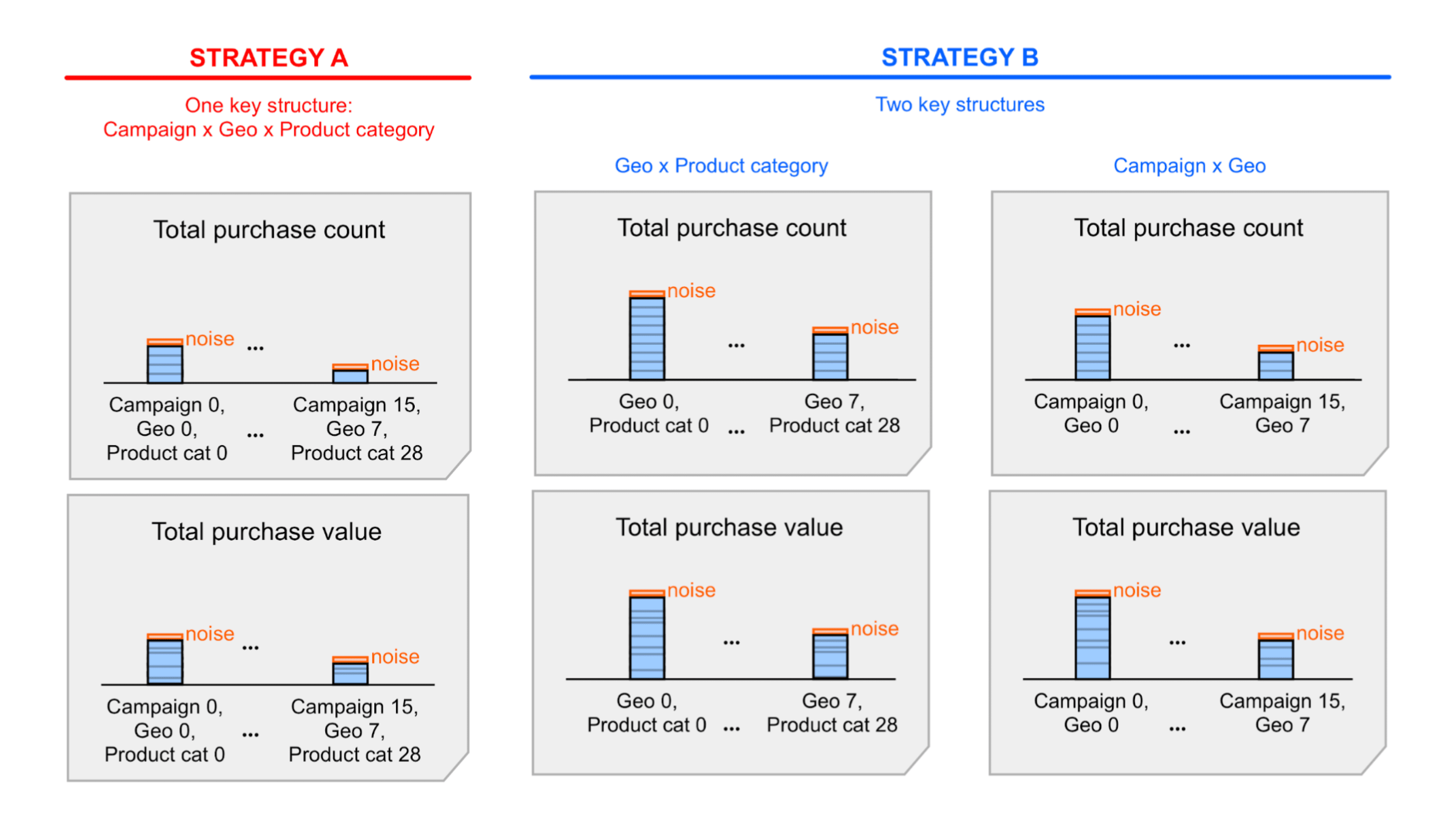
Strategy A is simpler—but you may need to roll up (sum) the noisy summary values included summary reports to access certain insights. By summing up these values, you're also summing the noise. With Strategy B, summary values exposed in the summary reports may already give you the information you need. This means that Strategy B will likely lead to better signal-to-noise ratios than Strategy A. However, the noise may already be acceptable with Strategy A, so you may still decide to favor Strategy A for simplicity. Learn more in the detailed example outlining these two strategies.
Key management is a deep topic. A number of elaborate techniques can be considered to improve signal-to-noise ratios. One is described in Advanced key management.
Decision: Batching frequency
Try it out in Noise Lab
- Go to the Simple mode (or Advanced mode — both modes work the same way when it comes to batching frequency)
- In the Parameters side panel, look for Your aggregation strategy > Batching frequency. This refers to the batching frequency of aggregatable reports that is processed with the aggregation service in a single job.
- Observe the default batching frequency: by default, a daily batching frequency is simulated.
- Click Simulate.
- Observe the noise ratios of the resulting simulation.
- Change the batching frequency to weekly.
- Observe the noise ratios of the resulting simulation: noise ratios are now lower (better) than for the previous simulation.
Another design decision that will impact the number of attributed conversion events within a single bucket is the batching frequency you decide to use. The batching frequency is how often you process aggregatable reports.
A report that is scheduled for aggregation more frequently (e.g. each hour) will have fewer conversion events included than the same report with a less frequent aggregation schedule (e.g. each week). As a result, the hourly report will include more noise.``` have fewer conversion events included than the same report with a less frequent aggregation schedule (e.g. each week). As a result, the hourly report will have a lower signal-to-noise ratio than the weekly report, all else being equal. Experiment with reporting requirements at various frequencies, and assess signal-to-noise ratios for each.
Learn more in Batching and Aggregating over longer time periods.
Decision: Campaign variables that affect attributable conversions
Try it out in Noise Lab
While this can be difficult to predict and can have significant variations in addition to seasonality effects, try and estimate the number of daily single-touch attributable conversions to the closest power of 10: 10, 100, 1,000, or 10,000.
- Go to Advanced mode.
- In the Parameters side panel, look for Your conversion data.
- Observe the default parameters. By default, the TOTAL daily attributable conversion count is 1000. This averages to roughly 40 per bucket if you use the default setup (default dimensions, default number of possible different values for each dimension, Key strategy A). Observe that the value is 40 in the input Average daily attributable conversion count PER BUCKET.
- Click Simulate to run a simulation with the default parameters.
- Observe the noise ratios of the resulting simulation.
- Now set the TOTAL daily attributable conversion count to 100. Observe that this lowers the value of Average daily attributable conversion count PER BUCKET.
- Click Simulate.
- Observe that the noise ratios are now higher: this is because when you have fewer conversions per bucket, more noise is applied to maintain privacy.
An important distinction is the total number of possible conversions for an advertiser, vs. the total number of possible attributed conversions. The latter is what ultimately impacts noise in summary reports. Attributed conversions are a subset of total conversions that are prone to campaign variables, such as ad budget and ad targeting. For example, you would expect a higher number of attributed conversions for a $10M ad campaign vs. a $10K ad campaign, all else being equal.
Things to consider:
- Assess attributed conversions against a single-touch, same device attribution model, as these are within the scope of summary reports collected with the Attribution Reporting API.
- Consider both a worst-case scenario count and a best-case scenario count for attributed conversions. For example, all else being equal, consider the minimum and maximum possible campaign budgets for an advertiser, then project attributable conversions for both outcomes as inputs into your simulation.
- If you're considering using the Android Privacy Sandbox, consider cross-platform attributed conversions in the calculation.
Decision: Using scaling
Try it out in Noise Lab
- Go to Advanced mode.
- In the Parameters side panel, look for Your aggregation strategy > Scaling. It's set to Yes by default.
- For the sake of understanding the positive effects of scaling on noise ratio, first set Scaling to No.
- Click Simulate.
- Observe the noise ratios of the resulting simulation.
- Set Scaling to Yes. Note that Noise Lab automatically calculates the scaling factors to be used given the ranges (average and max values) of the measurement goals for your scenario. In a real system or origin trial setup, you'd want to implement your own calculation for scaling factors.
- Click Simulate.
- Observe that the noise ratios are now lower (better) in this second simulation. This is because you're using scaling.
Given the core design principle, the noise added is a function of the contribution budget.
Therefore, to increase signal-to-noise ratios, you can decide to transform values collected during a conversion event by scaling them against the contribution budget (and de-scaling them after aggregation). Use scaling to increase signal-to-noise ratios.
Decision: Number of measurement goals, and privacy budget split
This relates to Scaling; make sure to read Using scaling.
Try it out in Noise Lab
A measurement goal is a distinct data point collected in conversion events.
- Go to Advanced mode.
- In the Parameters side panel, look for Data you want to track: Measurement goals. By default, you have two measurement goals: purchase value and purchase count.
- Click Simulate to run a simulation with the default goals.
- Click Remove. This will remove the last measurement goal (purchase count in that case).
- Click Simulate.
- Observe that the noise ratios for the purchase value are now lower (better) for this second simulation. This is because you have less measurement goals, so your one measurement goal now gets all of the contribution budget.
- Click Reset. You now have again two measurement goals: purchase value and purchase count. Note that Noise Lab automatically calculates the scaling factors to be used given the ranges (average and max values) of the measurement goals for your scenario. By default, Noise Lab splits the budget equally across measurement goals.
- Click Simulate.
- Observe the noise ratios of the resulting simulation. Take note of the scaling factors displayed on the simulation.
- Now, let's customize the privacy budget split to achieve better signal-to-noise ratios.
- Tweak the Budget % assigned for each measurement goal. Given the default parameters, Measurement goal 1, namely purchase value, has a much wider range (between 0 and 1000) than Measurement goal 2, namely purchase count (between 1 and 1 i.e. always equal to 1). Because of this, it needs "more space to scale": it would be ideal to assign more contribution budget to Measurement goal 1 than Measurement goal 2, so that it can be scaled up more efficiently (see Scaling), and hence
- Assign 70% of the budget to Measurement goal 1. Assign 30% to Measurement goal 2.
- Click Simulate.
- Observe the noise ratios of the resulting simulation. For purchase value, noise ratios are now notably lower (better) than for the previous simulation. For purchase count, they're roughly unchanged.
- Keep tweaking the budget split across metrics. Observe how this impacts noise.
Note that you can set your own custom measurement goals with the Add/Remove/Reset buttons.
If you measure one data point (measurement goal) on a conversion event, such as conversion count, that data point can get all the contribution budget (65536). If you set multiple measurement goals on a conversion event, such as conversion count and purchase value, then those data points will need to share the contribution budget. This means you have less leeway to scale up your values.
Therefore, the more measurement goals you have, the lower signal-to-noise ratios are likely to be (higher noise).
Another decision to make regarding measurement goals is the budget split. If you split the contribution budget equally across two data points, each data point gets a budget of 65536/2 = 32768. This may or may not be optimal depending on the maximum possible value for each data point. For example, if you're measuring purchase count that has a maximum value of 1, and purchase value with a minimum of 1 and a maximum of 120, the purchase value would benefit from having "more space" to be scaled up—that is, to be given a larger proportion of the contribution budget. You'll see if some measurement goals should be prioritized over others in relation to the impact of noise.
Decision: Outlier management
Try it out in Noise Lab
A measurement goal is a distinct data point collected in conversion events.
- Go to Advanced mode.
- In the Parameters side panel, look for Your aggregation strategy > Scaling.
- Make sure Scaling is set to Yes. Note that Noise Lab automatically calculates the scaling factors to be used, based on the ranges (average and max values) you have given for the measurement goals.
- Let's assume that the largest purchase ever made was $2000, but that most purchases happen in the range $10-$120. First, let's see what happens if we use a literal scaling approach (not recommended): enter $2000 as the max value for purchaseValue.
- Click Simulate.
- Observe that the noise ratios are high. This is because our scaling factor is currently calculated based on $2000, when in reality most purchase values will be notably lower than that.
- Now, let's use a more pragmatic scaling approach. Change the max purchase value to $120.
- Click Simulate.
- Observe that the noise ratios are lower (better) in this second simulation.
To implement scaling, you would typically calculate a scaling factor based on the maximum possible value for a given conversion event (learn more in this example).
However, avoid using a literal maximum value to calculate that scaling factor, as this would worsen your signal-to-noise ratios. Instead, remove outliers and use a pragmatic maximum value.
Outlier management is a deep topic. A number of elaborate techniques can be considered to improve signal-to-noise ratios. One is described in Advanced outlier management.
Next steps
Now that you've assessed various noise management strategies for your use case, you're ready to start experimenting with summary reports by collecting real measurement data via an origin trial. Review guides and tips to Try the API.
Appendix
Noise Lab quick tour
Noise Lab helps you quickly assess and compare noise management strategies. Use it to:
- Understand the main parameters that can impact noise, and the effect they have.
- Simulate the effect of noise on the output measurement data given different design decisions. Tweak design parameters until you reach a signal-to-noise ratio that works for your use case.
- Share your feedback on the utility of the summary reports: which values of epsilon and noise parameters work for you, which don't? Where are the inflection points?
Think of this as a preparation step. Noise Lab generates measurement data to simulate summary report outputs based on your input. It does not persist or share any data.
There are two different modes in Noise Lab:
- Simple mode: understand the fundamentals of the controls you have on noise.
- Advanced mode: test different noise management strategies and assess which one leads to the best signal-to-noise ratios for your use cases.
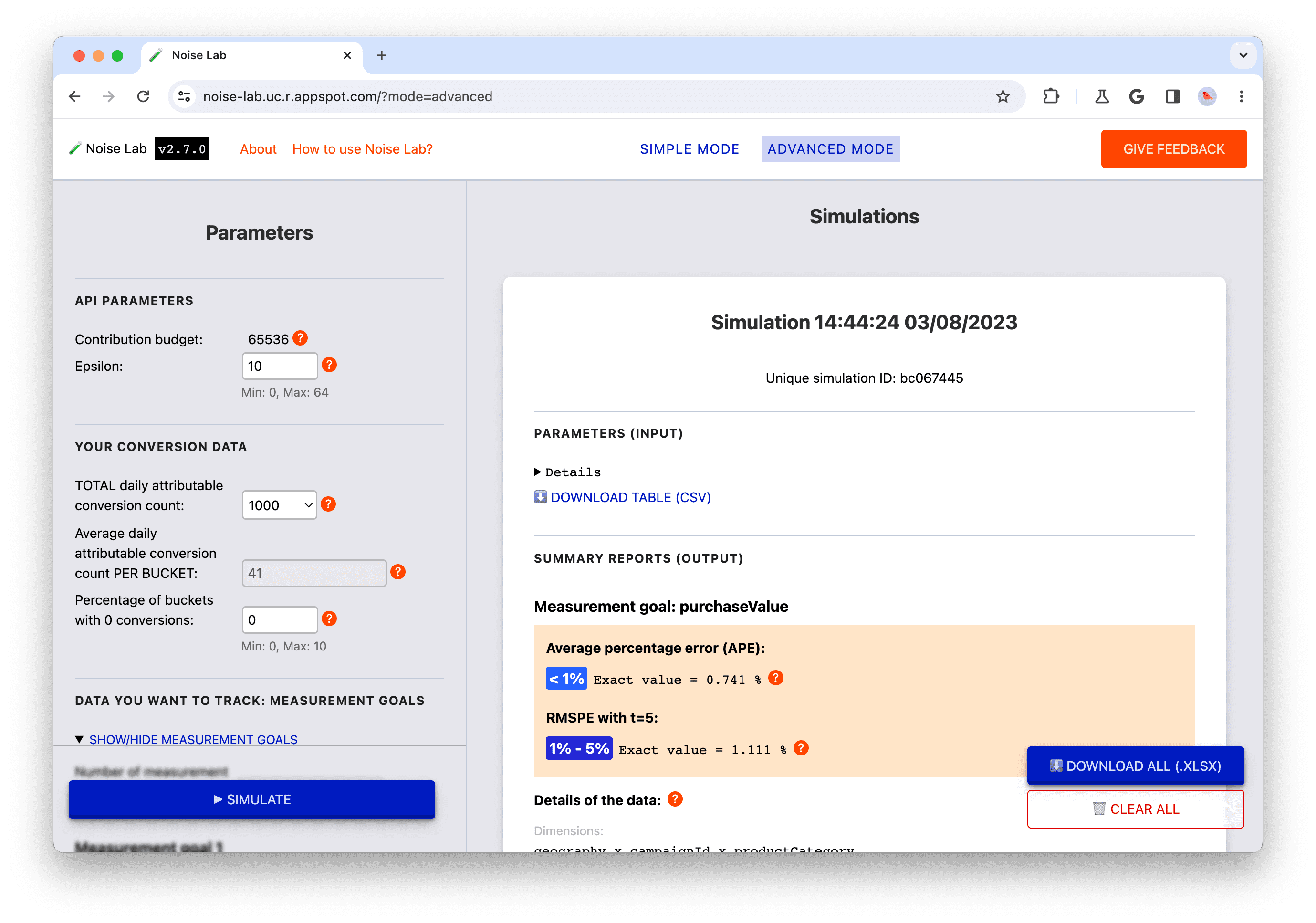
Click on the buttons in the top menu to toggle between the two modes (#1. in the screenshot below).
Simple mode
- With Simple mode, you control Parameters (found on the left-hand side, or #2. in the screenshot below) such as Epsilon, and see how they impact noise.
- Each parameter has a tooltip (a `?` button). Click these to see an explanation of each parameter (#3. in the screenshot below)
- To start, click the "Simulate" button and observe what the output looks like (#4. in the screenshot below)
- In the Output section you can see a variety of details. Some elements have a `?` next to it. Take the time to click each `?` to see an explanation of the various pieces of information.
- Within the Output section, click on the Details toggle if you want to see an expanded version of the table (#5. in the screenshot below)
- Below each data table in the output section, there is an option to download the table for offline usage. Additionally, in the bottom right corner there is an option to download all data tables (#6. in the screenshot below)
- Test different settings for the parameters in the Parameters section
and click Simulate to see how they impact the output:
Noise Lab interface for Simple mode.
Advanced mode
- In Advanced mode, you have more control over the Parameters. You can add custom Measurement Goals and Dimensions (#1. and #2. in the screenshot below)
- Scroll further down in the Parameters section and see the Key
Strategy option. This can be used to test out different key structures
(#3. in the screenshot below)
- To test out different Key Structures, switch Key Strategy to "B"
- Input the number of different key structures you want to use (default is set to "2")
- Click Generate Key Structures
- You will see options to specify your key structures by clicking the checkboxes next to the keys you want to include for each key structure
- Click Simulate to see the output.
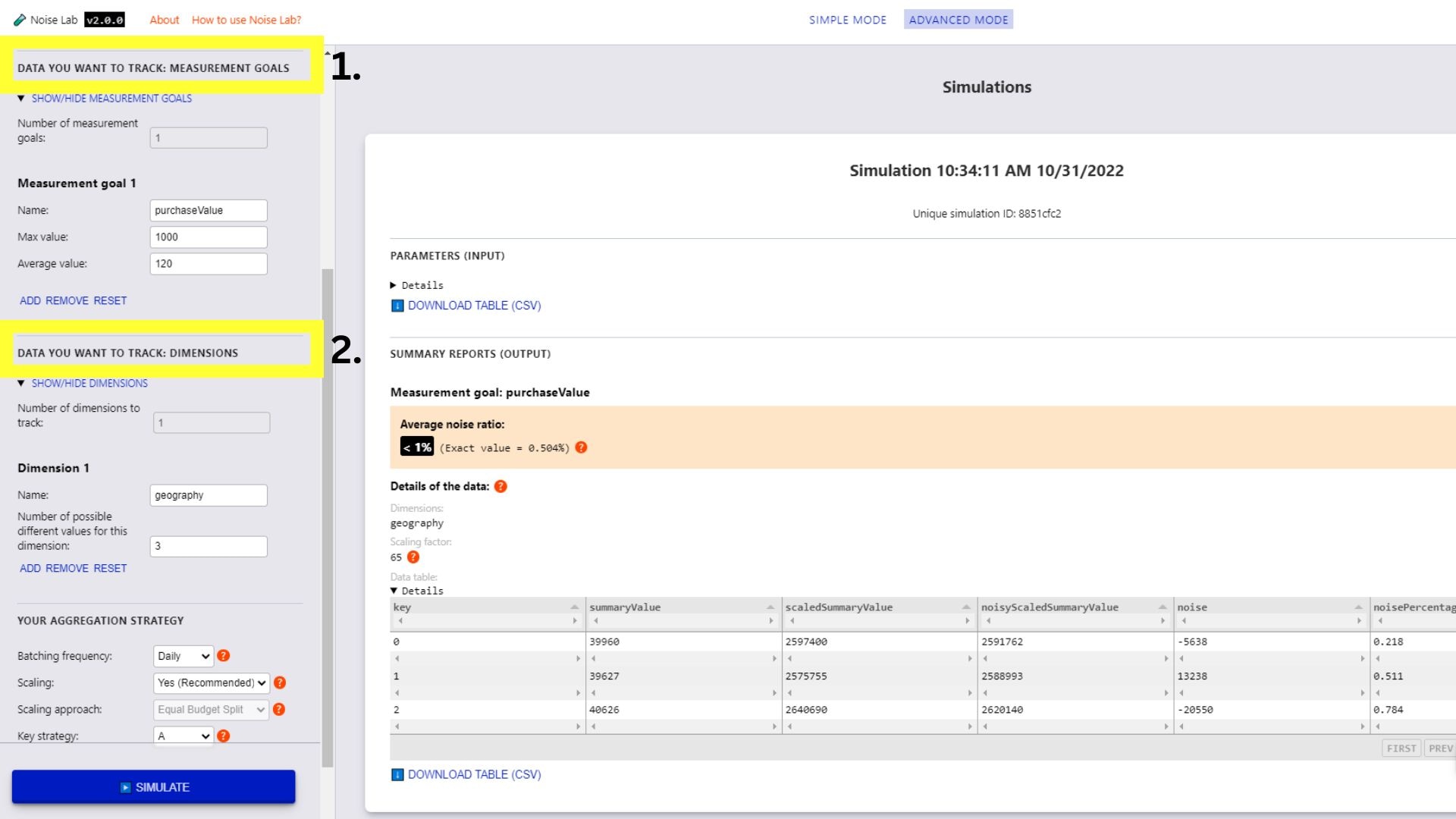
Noise Lab interface for Advanced mode. 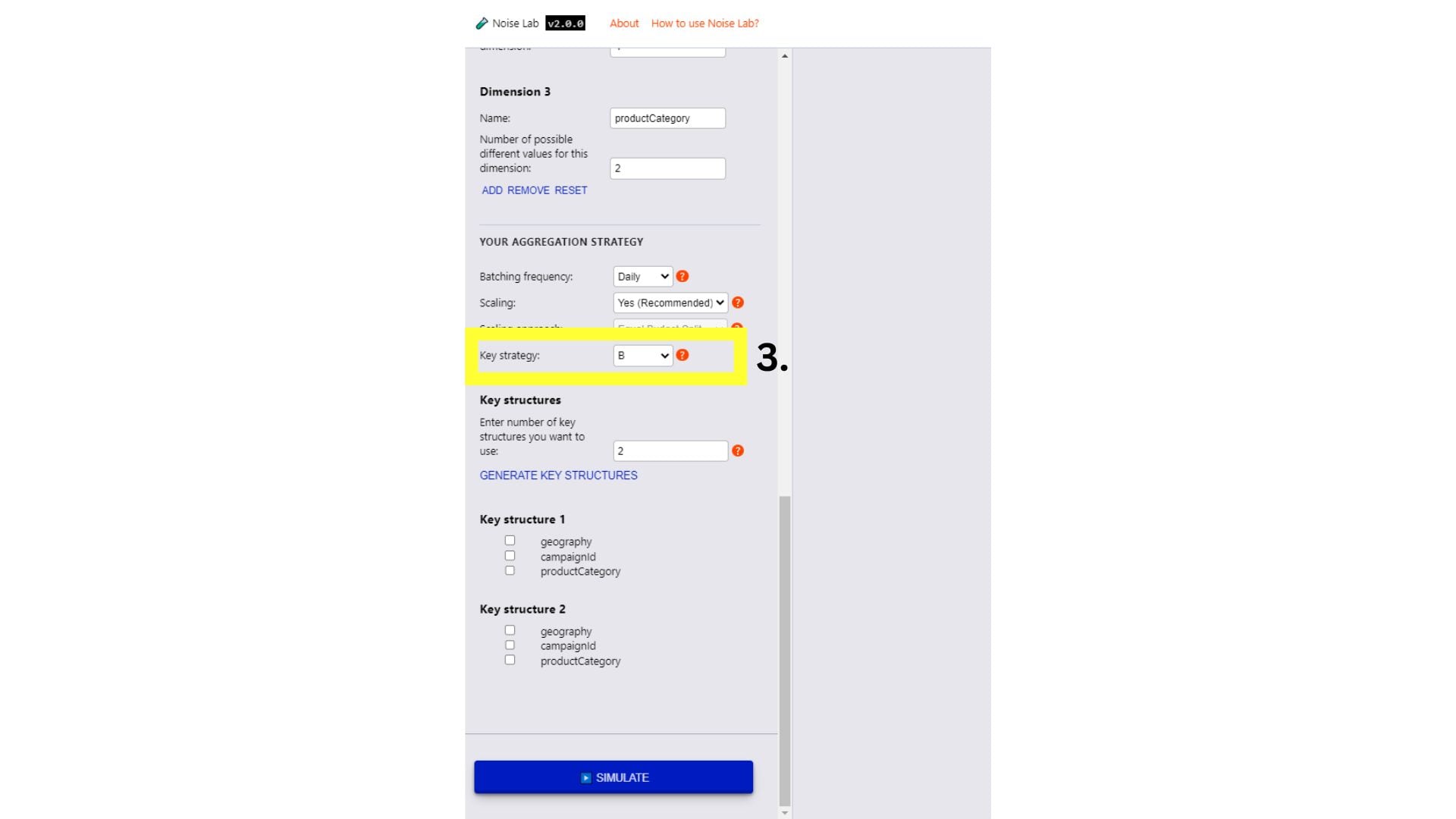
Noise Lab interface for Advanced mode.
Noise metrics
Core concept
Noise is added to protect individual user privacy.
A high noise value indicates that buckets/keys are sparse and contain contributions from a limited number of sensitive events. This is done automatically by Noise Lab, to allow individuals to "hide in the crowd," or in other words, protects these limited individuals' privacy with a larger amount of added noise.
A low noise value indicates that the data setup was designed in such a way that already allows individuals to "hide in the crowd." This means the buckets contain contributions from a sufficient number of events to ensure that individual user privacy is protected.
This statement holds true for both the average percentage error (APE) and RMSRE_T (root-mean-square relative error with a threshold).
APE (average percentage error)
APE is the ratio of the noise over the signal, namely the true summary value.p> Lower APE values mean better signal-to-noise ratios.
What does it mean if APE is Infinity? It means that the true summary value was 0, i.e. that at least one bucket was empty. Read more in the [examples section](#noise-examples).
Formula
For a given summary report, APE is calculated as follows:

True is the true summary value. APE is the average of the noise over each true summary value, averaged over all entries in a summary report. In Noise Lab, this is then multiplied by 100 to give a percentage.
Pros and Cons
Buckets with smaller sizes have a disproportionate impact on the final value of APE. That could be misleading when assessing noise. This is why we've added another metric, RMSRE_T, that is designed to mitigate this limitation of APE. Review the examples for details.
Code
Review the source code for APE calculation.
RMSRE_T (root-mean-square relative error with a threshold)
RMSRE_T (root-mean-square relative error with a threshold) is another measure for noise.
How to interpret RMSRE_T
Lower RMSRE_T values mean better signal-to-noise ratios.
For example, if a noise ratio that's acceptable for your use case is 20%, and RMSRE_T is 0.2, you can be confident that noise levels fall into your acceptable range.
Formula
For a given summary report, RMSRE_T is calculated as follows:
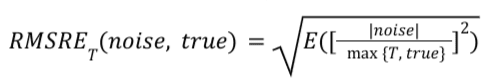
Pros and cons
RMSRE_T is a bit more complex to grasp than APE. However, it has a few advantages that make it in some cases more suitable than APE for analyzing noise in summary reports:
- RMSRE_T is more stable. "T" is a threshold. "T" is used to give less weight in the RMSRE_T calculation to buckets that have less conversions and are therefore more sensitive to noise due to their small size. With T, the metric does not spike on buckets with few conversions. If T is equal to 5, a noise value as small as 1 on a bucket with 0 conversions will not be displayed as way over 1. Instead, it will be capped at 0.2, which is equivalent to 1/5, as T is equal to 5. By giving less weight to smaller buckets which are therefore more sensitive to noise, this metric is more stable, and therefore makes it easier to compare two simulations.
- RMSRE_T allows for easy aggregation. Knowing the RMSRE_T of multiple buckets, together with their true counts, allows you to compute the RMSRE_T of their sum. This also allows you to optimize for RMSRE_T for these combined values.
While aggregation is possible for APE, the formula is quite complicated as it involves the absolute value of sum of Laplace noises. This makes APE harder to optimize.
Code
Review the source code for RMSRE_T calculation.
Examples
Summary report with three buckets:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
Summary report with three buckets:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
Summary report with three buckets:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + Infinity) / 3 = Infinity
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
Advanced key management
A DSP or ad measurement company might have thousands of global advertising customers, spanning multiple industries, currencies, and purchase price potentials. This means that creating and managing one aggregation key per advertiser will likely be highly impractical. Additionally, it will be challenging to select a max aggregatable value and aggregation budget that can limit the impact of noise across these thousands of global advertisers. Instead, let's consider the following scenarios:
Key Strategy A
The ad tech provider decides to create and manage one key across all of its advertising customers. Across all advertisers and all currencies, the range of purchases vary from low volume, high-end purchases to high volume, low-end purchases. This results in the following key:
| Key (multiple currencies) | |
|---|---|
| Max aggregatable value | 5,000,000 |
| Purchase value range | [120 - 5000000] |
Key Strategy B
The ad tech provider decides to create and manage two keys across all of its advertising customers. They decide to separate keys by currency. Across all advertisers and all currencies, the range of purchases vary from low volume, high-end purchases to high volume, low-end purchases. Separating by currency, they create 2 keys:
| Key 1 (USD) | Key 2 (¥) | |
|---|---|---|
| Max aggregatable value | $40,000 | ¥5,000,000 |
| Purchase value range | [120 - 40,000] | [15,000 - 5,000,000] |
Key Strategy B will have less noise in its result than Key Strategy A, because currency values are not uniformly distributed across currencies. For example, consider how purchases denominated in ¥ co-mingled with purchases denominated in USD will alter the underlying data and resulting noisy output.
Key Strategy C
The ad tech provider decides to create and manage four keys across all of its advertising customers, and to separate them by Currency x Advertiser industry:
| Key 1 (USD x High-end jewelry advertisers) |
Key 2 (¥ x High-end jewelry advertisers) |
Key 3 (USD x Clothing retailer advertisers) |
Key 4 (¥ x Clothing retailer advertisers) |
|
|---|---|---|---|---|
| Max aggregatable value | $40,000 | ¥5,000,000 | $500 | ¥65,000 |
| Purchase value range | [10,000 - 40,000] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 - 65,000] |
Key Strategy C will have less noise in its result than Key Strategy B, because advertiser purchase values are not uniformly distributed across advertisers. For example, consider how purchases for high end jewelry co-mingled with purchases for baseball hats will alter the underlying data and resulting noisy output.
Consider creating shared maximum aggregate values and shared scaling factors for commonalities across multiple advertisers in order to reduce noise in the output. For example, you could experiment with different strategies below for your advertisers:
- One strategy separated by currency (USD, ¥, CAD, etc)
- One strategy separated by advertiser industry (Insurance, Auto, Retail, etc)
- One strategy separated by similar purchase value ranges ([100], [1000], [10000], etc)
By creating key strategies around advertiser commonalities, keys and the corresponding code are easier to manage, and the signal-to-noise ratios become higher. Experiment with different strategies with different advertiser commonalities to uncover inflection points in maximizing noise impact vs code management.
Advanced outlier management
Let's consider a scenario across two advertisers:
- Advertiser A:
- Across all products on Advertiser A's site, the purchase price possibilities are between [$120 - $1,000] , for a range of $880.
- Purchase prices are evenly distributed across the $880 range with no outliers outside two standard deviations from the median purchase price.
- Advertiser B:
- Across all products on Advertiser B's site, the purchase price possibilities are between [$120 - $1,000] , for a range of $880.
- Purchase prices heavily skew towards the range of $120 - $500, with only 5% of purchases occurring in the $500 - $1,000 range.
Given the contribution budget requirements and the methodology with which noise is applied to the end results, Advertiser B will, by default, have a noisier output than Advertiser A, as Advertiser B has a higher potential for outliers to impact the underlying calculations.
It's possible to mitigate this with a specific key setup. Test key strategies that help to manage outlier data, and to more evenly distribute purchase values across the purchase range of the key.
For Advertiser B, you could create two separate keys to capture two different purchase value ranges. In this example, the ad tech has noted that outliers appear above the $500 purchase value. Try implementing two separate keys for this advertiser:
- Key Structure 1 : Key that only captures purchases between the range of $120 - $500 (covering ~95% of total purchase volume).
- Key Structure 2: Key that only captures purchases above $500 (covering ~5% of total purchase volume).
Implementing this key strategy should better manage noise for Advertiser B and help to maximize utility for them from summary reports. Given the new smaller ranges, Key A and Key B should now have a more uniform distribution of data across each respective key that for the previous single key. This will result in less noise impact in each key's output that for the previous single key.