Concepts clés de l'API Private Aggregation
À qui s'adresse ce document ?
L'API Private Aggregation permet de collecter des données agrégées à partir de worklets ayant accès à des données intersites. Les concepts présentés ici sont importants pour les développeurs qui créent des fonctions de création de rapports dans l'API Shared Storage et Protected Audience.
- Si vous êtes développeur et que vous créez un système de reporting pour les mesures intersites,
- Si vous êtes marketeur, data scientist ou autre consommateur de rapports récapitulatifs, comprendre ces mécanismes vous aidera à prendre des décisions de conception pour récupérer un rapport récapitulatif optimisé.
Termes clés
Avant de lire ce document, il est utile de vous familiariser avec les termes et concepts clés. Chacun de ces termes sera décrit en détail ici.
- Une clé d'agrégation (également appelée "bucket") est une collection prédéterminée de points de données. Par exemple, vous pouvez collecter un bucket de données de localisation dans lequel le navigateur indique le nom du pays. Une clé d'agrégation peut contenir plusieurs dimensions (par exemple, le pays et l'ID de votre widget de contenu).
- Une valeur agrégable est un point de données individuel collecté dans une clé d'agrégation. Si vous souhaitez mesurer le nombre d'utilisateurs français qui ont vu votre contenu,
Franceest une dimension dans la clé d'agrégation, et leviewCountde1est la valeur agrégable. - Les rapports agrégables sont générés et chiffrés dans un navigateur. Pour l'API Private Aggregation, il contient des données sur un seul événement.
- Le service d'agrégation traite les données des rapports cumulables pour créer un rapport récapitulatif.
- Un rapport récapitulatif est le résultat final du service d'agrégation. Il contient des données utilisateur agrégées et des données de conversion détaillées.
- Un worklet est un élément d'infrastructure qui vous permet d'exécuter des fonctions JavaScript spécifiques et de renvoyer des informations à l'utilisateur à l'origine de la requête. Dans un worklet, vous pouvez exécuter du code JavaScript, mais vous ne pouvez pas interagir ni communiquer avec la page externe.
Workflow Private Aggregation
Lorsque vous appelez l'API Private Aggregation avec une clé d'agrégation et une valeur agrégable, le navigateur génère un rapport agrégable. Les rapports sont envoyés à votre serveur, qui les regroupe. Les rapports groupés sont ensuite traités par le service d'agrégation, et un rapport récapitulatif est généré.
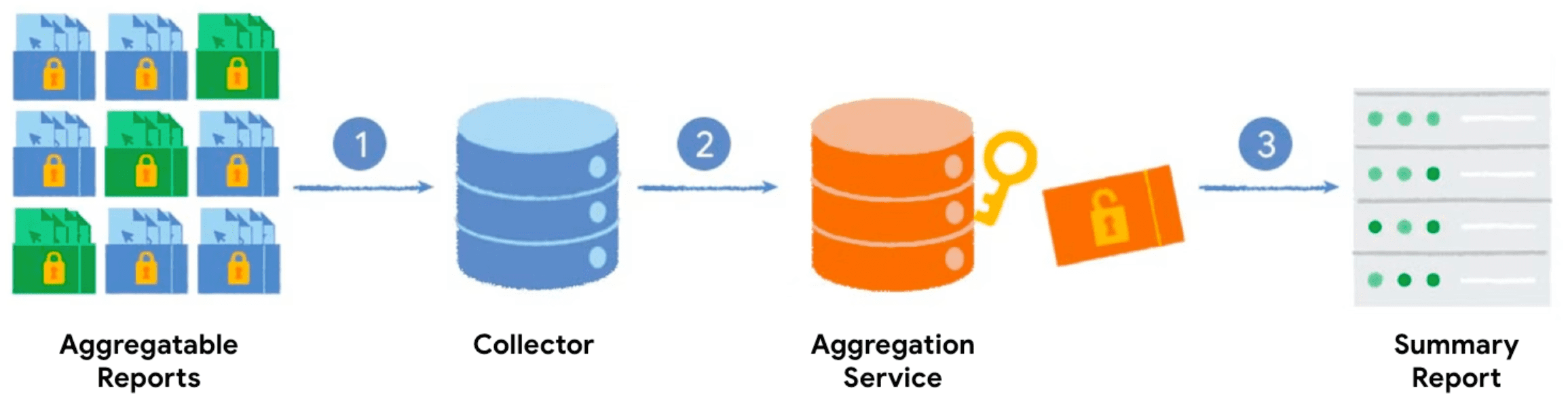
- Lorsque vous appelez l'API Private Aggregation, le client (navigateur) génère et envoie le rapport agrégable à votre serveur pour qu'il soit collecté.
- Votre serveur collecte les rapports des clients et les regroupe pour les envoyer au service d'agrégation.
- Une fois que vous avez collecté suffisamment de rapports, vous les regroupez et les envoyez au service d'agrégation, qui s'exécute dans un environnement d'exécution sécurisé, pour générer un rapport récapitulatif.
Le workflow décrit dans cette section est semblable à celui de l'API Attribution Reporting. Toutefois, les rapports sur l'attribution associent les données collectées à partir d'un événement d'impression et d'un événement de conversion, qui se produisent à des moments différents. Private Aggregation mesure un seul événement intersites.
Clé d'agrégation
Une clé d'agrégation ("clé" pour faire court) représente le bucket dans lequel les valeurs agrégables seront accumulées. Une ou plusieurs dimensions peuvent être encodées dans la clé. Une dimension représente un aspect sur lequel vous souhaitez obtenir plus d'insights, comme le groupe d'âge des utilisateurs ou le nombre d'impressions d'une campagne publicitaire.
Par exemple, vous pouvez avoir un widget intégré sur plusieurs sites et souhaiter analyser le pays des utilisateurs qui l'ont vu. Vous souhaitez répondre à des questions telles que "Combien d'utilisateurs qui ont vu mon widget sont originaires du pays X ?". Pour créer un rapport sur cette question, vous pouvez configurer une clé d'agrégation qui encode deux dimensions: l'ID du widget et l'ID du pays.
La clé fournie à l'API Private Aggregation est un BigInt, qui se compose de plusieurs dimensions. Dans cet exemple, les dimensions sont l'ID du widget et l'ID du pays. Supposons que l'ID du widget puisse comporter jusqu'à quatre chiffres, par exemple 1234, et que chaque pays soit associé à un nombre par ordre alphabétique, par exemple l'Afghanistan est associé au nombre 1, la France au nombre 61 et le Zimbabwe au nombre 195.
Par conséquent, la clé agrégable comporte sept chiffres, dont les quatre premiers sont réservés à WidgetID et les trois derniers à CountryID.
Supposons que la clé représente le nombre d'utilisateurs de France (ID de pays 061) ayant vu l'ID de widget 3276. La clé d'agrégation est 3276061.
| Clé d'agrégation | |
| ID du widget | Identifiant du pays |
| 3276 | 061 |
La clé d'agrégation peut également être générée à l'aide d'un mécanisme de hachage, tel que SHA-256. Par exemple, la chaîne {"WidgetId":3276,"CountryID":67} peut être hachée, puis convertie en valeur BigInt de 42943797454801331377966796057547478208888578253058197330928948081739249096287n.
Si la valeur de hachage comporte plus de 128 bits, vous pouvez la tronquer pour vous assurer qu'elle ne dépasse pas la valeur maximale autorisée de 2^128−1.
Dans un worklet Shared Storage, vous pouvez accéder aux modules crypto et TextEncoder qui peuvent vous aider à générer un hachage. Pour en savoir plus sur la génération d'un hachage, consultez la page SubtleCrypto.digest() sur le MDN.
L'exemple suivant décrit comment générer une clé de bucket à partir d'une valeur hachée:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Valeur agrégable
Les valeurs agrégables sont additionnées par clé pour de nombreux utilisateurs afin de générer des insights agrégés sous forme de valeurs récapitulatives dans les rapports récapitulatifs.
Revenez maintenant à l'exemple de question posée précédemment: "Combien d'utilisateurs qui ont vu mon widget sont français ?". La réponse à cette question se présente comme suit : "Environ 4 881 utilisateurs qui ont vu mon widget ID 3276 sont situés en France." La valeur agrégable est de 1 pour chaque utilisateur, et "4 881 utilisateurs" est la valeur agrégée, qui correspond à la somme de toutes les valeurs agrégables pour cette clé d'agrégation.
| Clé d'agrégation | Valeur agrégable | |
| ID du widget | Identifiant du pays | Nombre de vues |
| 3276 | 061 | 1 |
Dans cet exemple, nous augmentons la valeur de 1 pour chaque utilisateur qui voit le widget. En pratique, la valeur agrégable peut être mise à l'échelle pour améliorer le rapport signal/bruit.
Budget de contribution
Chaque appel à l'API Private Aggregation est appelé une contribution. Pour protéger la confidentialité des utilisateurs, le nombre de contributions pouvant être collectées auprès d'une personne est limité.
Lorsque vous additionnez toutes les valeurs agrégables pour toutes les clés d'agrégation, la somme doit être inférieure au budget de contribution. Le budget est défini par origine de travaillet et par jour, et est distinct pour les travaillets de l'API Protected Audience et de Shared Storage. Une fenêtre glissante d'environ 24 heures est utilisée pour la journée. Si un nouveau rapport agrégable entraînerait un dépassement du budget, il n'est pas créé.
Le budget de contribution est représenté par le paramètre L1 et est défini sur 216 (65 536) toutes les dix minutes par jour, avec un seuil de sauvegarde de 220 (1 048 576). Pour en savoir plus sur ces paramètres, consultez la présentation.
La valeur du budget de contribution est arbitraire, mais le bruit est mis à l'échelle. Vous pouvez utiliser ce budget pour maximiser le rapport signal/bruit sur les valeurs récapitulatives (voir la section Bruit et mise à l'échelle).
Pour en savoir plus sur les budgets de contribution, consultez la vidéo explicative. Pour en savoir plus, consultez également la section Budget de contribution.
Limite de contribution par rapport
La limite de contribution peut varier selon l'appelant. Pour le moment, les rapports générés pour les appelants de l'API Shared Storage sont limités à 20 contributions par rapport. En revanche, les appelants de l'API Protected Audience sont limités à 100 contributions par rapport. Ces limites ont été choisies pour équilibrer le nombre de contributions pouvant être intégrées avec la taille de la charge utile.
Pour le stockage partagé, les contributions effectuées dans une seule opération run() ou selectURL() sont regroupées dans un seul rapport. Pour Protected Audience, les contributions d'une seule origine dans une enchère sont regroupées.
Contributions avec marge intérieure
Les contributions sont également modifiées avec une fonctionnalité de marge intérieure. Le remplissage de la charge utile protège les informations sur le nombre réel de contributions intégrées au rapport agrégable. Le remplissage augmente la charge utile avec des contributions null (c'est-à-dire avec une valeur de 0) pour atteindre une longueur fixe.
Rapports agrégables
Une fois que l'utilisateur appelle l'API Private Aggregation, le navigateur génère des rapports agrégables à traiter par le service d'agrégation ultérieurement afin de générer des rapports récapitulatifs. Un rapport agrégable est au format JSON et contient une liste chiffrée de contributions, chacune étant une paire {aggregation key, aggregatable value}.
Les rapports agrégables sont envoyés avec un délai aléatoire pouvant aller jusqu'à une heure.
Les contributions sont chiffrées et illisibles en dehors du service d'agrégation. Le service d'agrégation déchiffre les rapports et génère un rapport récapitulatif. La clé de chiffrement du navigateur et la clé de déchiffrement du service d'agrégation sont émises par le coordinateur, qui sert de service de gestion des clés. Le coordinateur conserve une liste de hachages binaires de l'image du service pour vérifier que l'appelant est autorisé à recevoir la clé de déchiffrement.
Exemple de rapport agrégable avec le mode débogage activé:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Vous pouvez inspecter les rapports agrégables depuis la page chrome://private-aggregation-internals:

À des fins de test, vous pouvez utiliser le bouton "Envoyer les rapports sélectionnés" pour envoyer immédiatement le rapport au serveur.
Collecter et traiter par lot des rapports agrégables
Le navigateur envoie les rapports agrégables à l'origine du worklet contenant l'appel de l'API Private Aggregation, à l'aide du chemin bien connu listé:
- Pour Shared Storage:
/.well-known/private-aggregation/report-shared-storage - Pour Protected Audience :
/.well-known/private-aggregation/report-protected-audience
Sur ces points de terminaison, vous devrez exploiter un serveur (qui joue le rôle de collecteur) qui reçoit les rapports cumulables envoyés par les clients.
Le serveur doit ensuite regrouper les rapports et les envoyer au service d'agrégation. Créez des lots en fonction des informations disponibles dans la charge utile non chiffrée du rapport agrégable, comme le champ shared_info. Idéalement, les lots doivent contenir au moins 100 rapports chacun.
Vous pouvez choisir de créer des lots quotidiens ou hebdomadaires. Cette stratégie est flexible. Vous pouvez modifier votre stratégie de traitement par lot pour des événements spécifiques pour lesquels vous prévoyez un volume plus important (par exemple, les jours de l'année où vous prévoyez plus d'impressions). Les lots doivent inclure des rapports de la même version d'API, de la même origine de création de rapports et de la même heure de planification des rapports.
Filtrer les ID
L'API et le service d'agrégation privée vous permettent d'utiliser des ID de filtrage pour traiter les mesures à un niveau plus précis (par campagne publicitaire, par exemple) plutôt que de traiter les résultats dans des requêtes plus volumineuses.

Pour commencer à utiliser cette fonctionnalité dès aujourd'hui, voici quelques étapes à suivre pour votre implémentation actuelle.
Étapes de stockage partagé
Si vous utilisez l'API Shared Storage dans votre flux:
Définissez l'emplacement où vous déclarerez et exécuterez votre nouveau module de stockage partagé. Dans l'exemple suivant, nous avons nommé le fichier de module
filtering-worklet.js, enregistré sousfiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();Notez que
filteringIdMaxBytesest configurable par rapport et que, s'il n'est pas défini, sa valeur par défaut est 1. Cette valeur par défaut permet d'éviter d'augmenter inutilement la taille de la charge utile, et donc les coûts de stockage et de traitement. Pour en savoir plus, consultez la présentation de la contribution flexible.Dans le fichier que vous avez utilisé ci-dessus,
filtering-worklet.js, lorsque vous transmettez une contribution àprivateAggregation.contributeToHistogram(...)dans le worklet de stockage partagé, vous pouvez spécifier un ID de filtrage.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Les rapports agrégables seront envoyés à l'emplacement où vous avez défini le point de terminaison
/.well-known/private-aggregation/report-shared-storage. Consultez le guide de filtrage des ID pour en savoir plus sur les modifications à apporter aux paramètres de tâche du service d'agrégation.
Une fois le traitement par lot terminé et envoyé à votre service d'agrégation déployé, vos résultats filtrés devraient apparaître dans votre rapport récapitulatif final.
Étapes à suivre pour utiliser Protected Audience
Si vous utilisez l'API Protected Audience dans votre flux:
Dans votre implémentation actuelle de Protected Audience, vous pouvez définir les éléments suivants pour vous connecter à l'agrégation privée. Contrairement à Shared Storage, il n'est pas encore possible de configurer la taille maximale de l'ID de filtrage. Par défaut, la taille maximale de l'ID de filtrage est de 1 octet et est définie sur
0n. N'oubliez pas que ces valeurs sont définies dans vos [fonctions de création de rapports Protected Audience](fonctions de création de rapports Protected Audience (par exemple,reportResult()ougenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Les rapports agrégables seront envoyés à l'emplacement où vous avez défini le point de terminaison
/.well-known/private-aggregation/report-protected-audience. Une fois le traitement par lot terminé et envoyé à votre service d'agrégation déployé, vos résultats filtrés devraient apparaître dans votre rapport récapitulatif final. Les explications suivantes sur l'API Attribution Reporting et l'API Private Aggregation sont disponibles, ainsi que la proposition initiale.
Pour en savoir plus, consultez notre guide de filtrage des ID dans le service d'agrégation ou les sections API Attribution Reporting.
Service d'agrégation
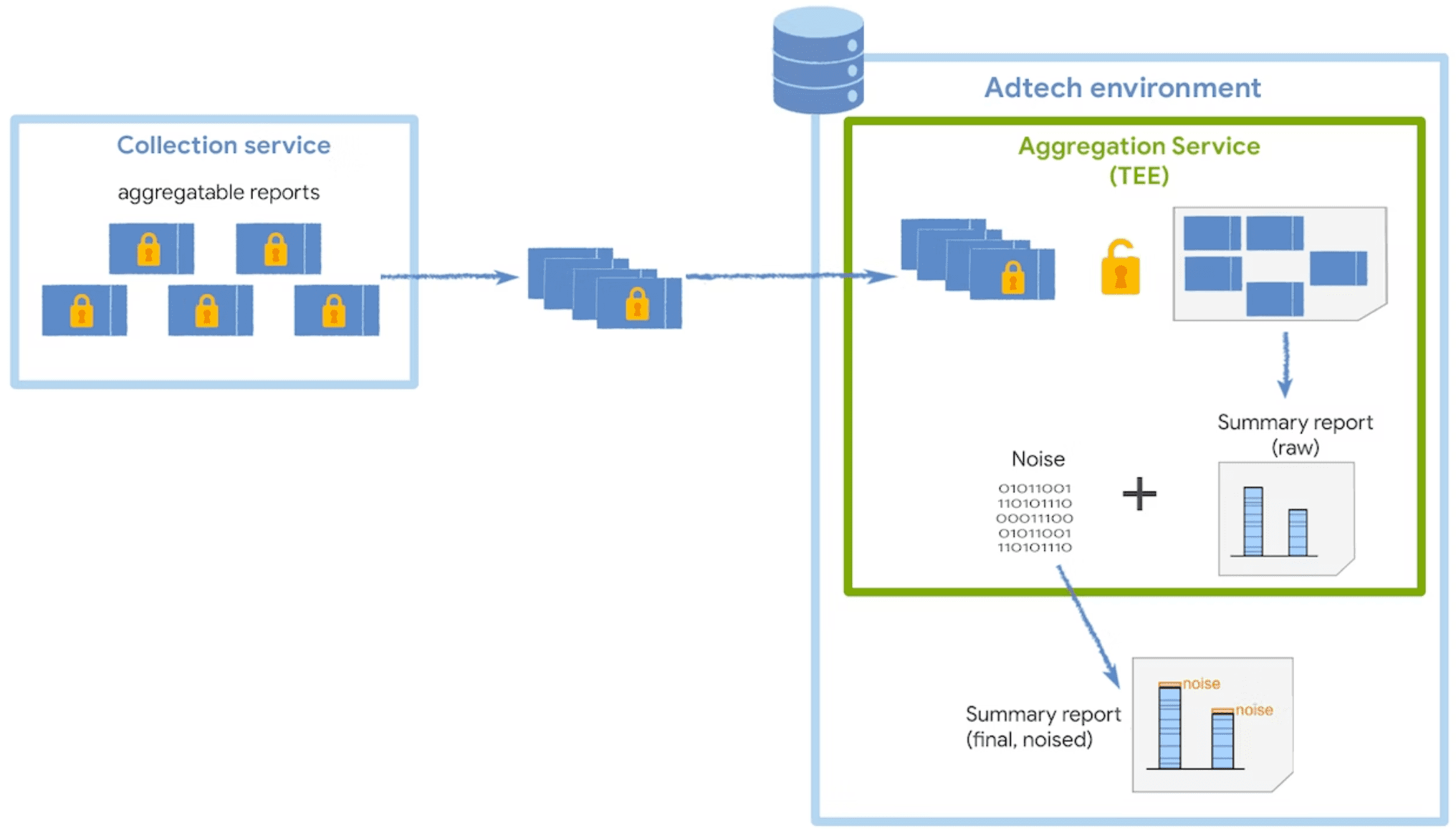
Le service d'agrégation reçoit des rapports agrégables chiffrés du collecteur et génère des rapports récapitulatifs. Pour découvrir d'autres stratégies d'agrégation des rapports dans votre collecteur, consultez notre guide sur l'envoi de requêtes par lot.
Le service s'exécute dans un environnement d'exécution sécurisé (TEE), qui offre un niveau d'assurance pour l'intégrité, la confidentialité et l'intégrité du code des données. Pour en savoir plus sur l'utilisation des coordinateurs avec les TEE, consultez leur rôle et leur objectif.
Rapports récapitulatifs
Les rapports récapitulatifs vous permettent de consulter les données que vous avez collectées avec du bruit ajouté. Vous pouvez demander des rapports récapitulatifs pour un ensemble de clés donné.
Un rapport récapitulatif contient un ensemble de paires clé-valeur de type dictionnaire JSON. Chaque paire contient les éléments suivants:
bucket: clé d'agrégation sous forme de chaîne de nombres binaires. Si la clé d'agrégation utilisée est "123", le bucket est "1111011".value: valeur récapitulative d'un objectif de mesure donné, résumée à partir de tous les rapports agrégables disponibles avec du bruit ajouté.
Exemple :
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Bruit et scaling
Pour préserver la confidentialité des utilisateurs, le service d'agrégation ajoute du bruit une fois à chaque valeur récapitulative chaque fois qu'un rapport récapitulatif est demandé. Les valeurs de bruit sont tirées de manière aléatoire d'une distribution de probabilité de Laplace. Bien que vous n'ayez pas le contrôle direct des méthodes d'ajout du bruit, vous pouvez influencer son impact sur les données de mesure.
La distribution du bruit est la même, quelle que soit la somme de toutes les valeurs agrégables. Par conséquent, plus les valeurs agrégables sont élevées, moins le bruit est susceptible d'avoir un impact.
Par exemple, supposons que la distribution du bruit ait un écart-type de 100 et qu'elle soit centrée sur zéro. Si la valeur de rapport agrégable collectée (ou "valeur agrégable") n'est que de 200, l'écart type du bruit sera de 50% de la valeur agrégée. Toutefois, si la valeur agrégable est de 20 000,l'écart type du bruit ne représentera que 0, 5% de la valeur agrégée. Par conséquent, la valeur agrégable de 20 000 donnerait un rapport signal/bruit beaucoup plus élevé.
Par conséquent, multiplier votre valeur agrégable par un facteur de scaling peut contribuer à réduire le bruit. Le facteur de mise à l'échelle représente l'échelle que vous souhaitez appliquer à une valeur agrégable donnée.

L'augmentation des valeurs en choisissant un facteur de scaling plus élevé réduit le bruit relatif. Cependant, cela entraîne également une augmentation plus rapide de la somme de toutes les contributions dans tous les buckets jusqu'à atteindre la limite du budget de contributions. Si vous diminuez les valeurs en choisissant une constante de facteur de scaling plus faible, le bruit relatif augmente, mais le risque d'atteindre la limite de budget est réduit.
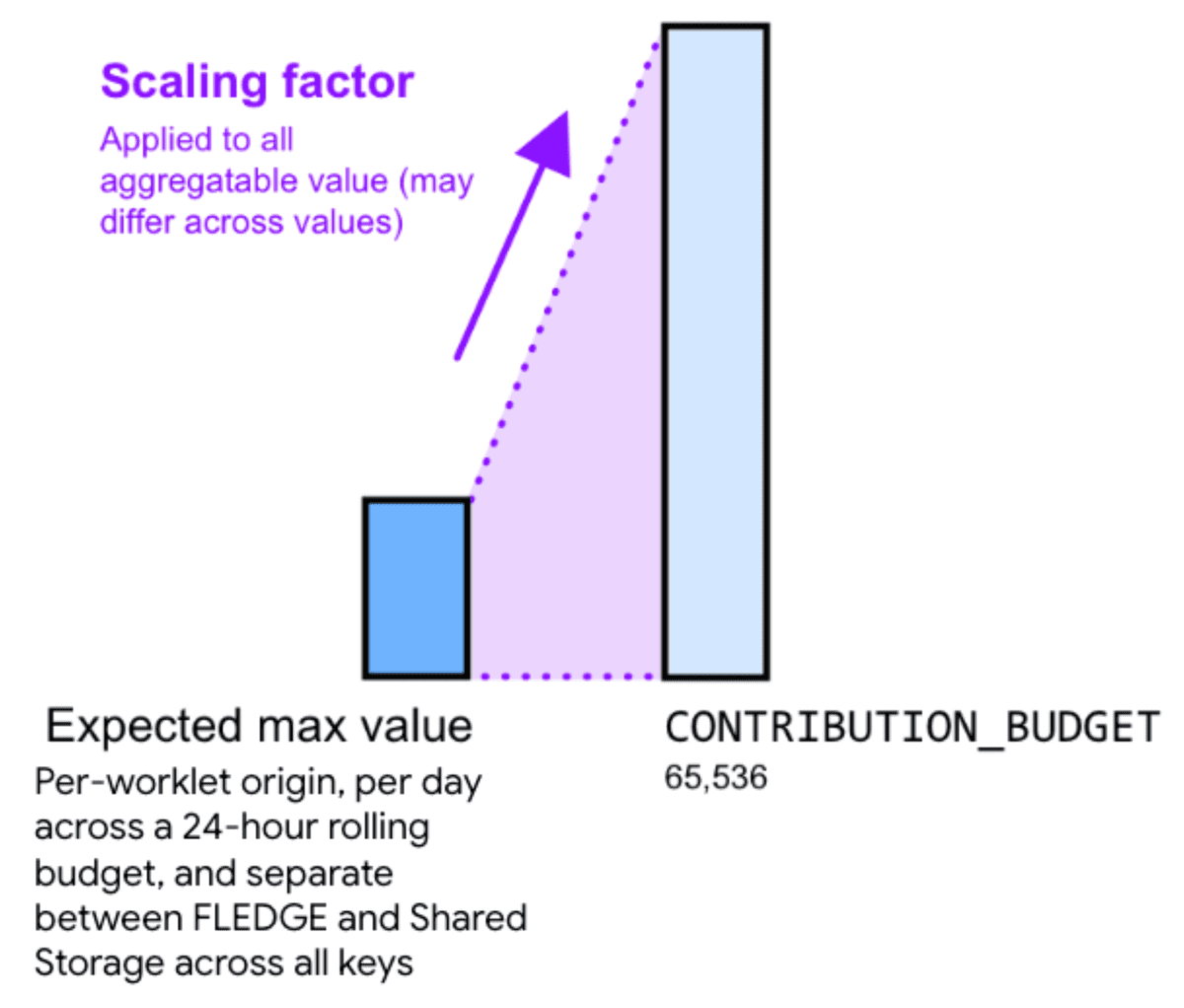
Pour calculer un facteur de mise à l'échelle approprié, divisez le budget de contribution par la somme maximale des valeurs agrégables pour toutes les clés.
Pour en savoir plus, consultez la documentation sur le budget de contribution.
Interagir et envoyer des commentaires
L'API Private Aggregation est en cours de discussion et est susceptible d'être modifiée à l'avenir. Si vous essayez cette API et que vous avez des commentaires à nous faire, nous serions ravis de les recevoir.
- GitHub: lisez la présentation, posez des questions et participez aux discussions.
- Assistance pour les développeurs: posez des questions et participez aux discussions sur le dépôt d'assistance pour les développeurs de la Privacy Sandbox.
- Rejoignez le groupe de l'API Shared Storage et le groupe de l'API Protected Audience pour recevoir les dernières annonces concernant l'agrégation privée.