מושגים מרכזיים של Private Aggregation API
למי המסמך הזה מיועד?
Private Aggregation API מאפשר איסוף נתונים מצטברים מ-worklets עם גישה לנתונים באתרים שונים. המושגים שמפורטים כאן חשובים למפתחים שמפתחים פונקציות דיווח ב-Shared Storage וב-Protected Audience API.
- אם אתם מפתחים שמפתחים מערכת דיווח למדידת ביצועים בכמה אתרים.
- אם אתם משווקים, מדעני נתונים או צרכנים אחרים של דוחות סיכום, הבנת המנגנונים האלה תעזור לכם לקבל החלטות עיצוב כדי לאחזר דוח סיכום מותאם אישית.
מונחי מפתח
לפני שתקראו את המסמך הזה, כדאי שתכירו את המונחים והמושגים המרכזיים. כל אחד מהמונחים האלה יתאר כאן לעומק.
- מפתח צבירת נתונים (נקרא גם קטגוריה) הוא אוסף מוגדר מראש של נקודות נתונים. לדוגמה, יכול להיות שתרצו לאסוף קטגוריה של נתוני מיקום שבה הדפדפן מדווח על שם המדינה. מפתח צביר יכול להכיל יותר ממאפיין אחד (לדוגמה, מדינה ומזהה של ווידג'ט התוכן).
- ערך שניתן לצבור הוא נקודת נתונים בודדת שנאספת במפתח צביר. אם רוצים למדוד כמה משתמשים מצרפת צפו בתוכן, הערך
Franceהוא מאפיין במפתח הצבירה, והערךviewCountשל1הוא הערך שאפשר לצבור. - דוחות שניתן לצבור נוצרים ומצפינים בדפדפן. ב-Private Aggregation API, הנתונים האלה מכילים נתונים על אירוע יחיד.
- שירות הצבירה מעבד נתונים מדוחות שאפשר לצבור כדי ליצור דוח סיכום.
- דוח סיכום הוא הפלט הסופי של שירות האגרגציה, והוא מכיל נתוני משתמשים נצברים עם רעש ונתוני המרות מפורטים.
- worklet הוא רכיב תשתית שמאפשר להריץ פונקציות ספציפיות של JavaScript ולהחזיר מידע לבקשה. בתוך רכיב worklet אפשר להריץ JavaScript, אבל אי אפשר לבצע אינטראקציה או לתקשר עם הדף החיצוני.
תהליך העבודה של Private Aggregation
כשקוראים ל-Private Aggregation API עם מפתח צבירה וערך שניתן לצבור, הדפדפן יוצר דוח שניתן לצבור. הדוחות נשלחים לשרת שלכם, שמקבץ אותם. המערכת מעבדת את הדוחות בקבוצות מאוחר יותר באמצעות שירות הצבירה, ויוצרת דוח סיכום.
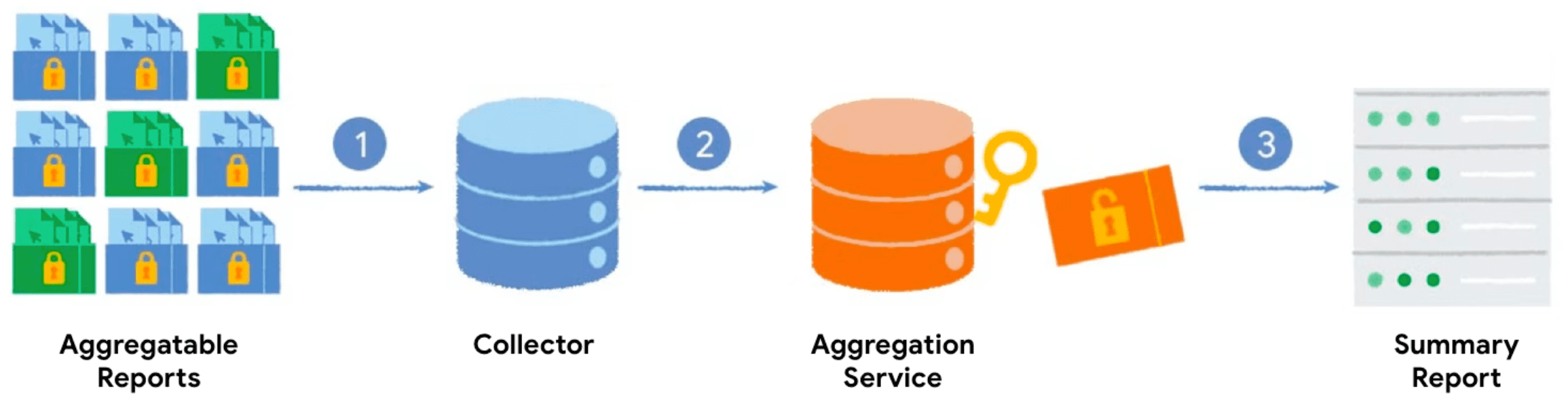
- כשאתם קוראים ל-Private Aggregation API, הלקוח (הדפדפן) יוצר את הדוח שאפשר לצבור ומעביר אותו לשרת שלכם כדי שייאסף.
- השרת אוסף את הדוחות מהלקוחות ומקבץ אותם לקבוצות כדי לשלוח אותן לשירות הצבירה.
- אחרי שאוספים מספיק דוחות, אוספים אותם בקבוצה ושולחים אותם ל-Aggregation Service, שפועל בסביבת הפעלה מהימנה, כדי ליצור דוח סיכום.
תהליך העבודה שמתואר בקטע הזה דומה ל-Attribution Reporting API. עם זאת, דיווח על שיוך (Attribution) משייך נתונים שנאספו מאירוע חשיפה ומאירוע המרה, שמתרחשים בזמנים שונים. באמצעות צבירת נתונים פרטית אפשר למדוד אירוע יחיד באתרים שונים.
מפתח צבירה
מפתח צבירת נתונים (או 'מפתח' בקיצור) מייצג את הקטגוריה שבה יתצברו הערכים שאפשר לצבור. אפשר לקודד מאפיינים אחד או יותר במפתח. מאפיין מייצג היבט מסוים שרוצים לקבל עליו תובנות נוספות, כמו קבוצת הגיל של המשתמשים או מספר החשיפות בקמפיין פרסום.
לדוגמה, יכול להיות שיש לכם ווידג'ט שמוטמע בכמה אתרים ואתם רוצים לנתח את המדינה של המשתמשים שראו את הווידג'ט. אתם רוצים לקבל תשובות לשאלות כמו "כמה מהמשתמשים שראו את הווידג'ט שלי הם ממדינה X?" כדי לדווח על השאלה הזו, אפשר להגדיר מפתח צבירת נתונים שמקודד שני מאפיינים: מזהה הווידג'ט ומזהה המדינה.
המפתח שסופק ל-Private Aggregation API הוא BigInt, שמורכב מכמה מאפיינים. בדוגמה הזו, המאפיינים הם מזהה הווידג'ט ומזהה המדינה. נניח שמזהה הווידג'ט יכול להכיל עד 4 ספרות, כמו 1234, וכל מדינה ממופה למספר לפי סדר אלפביתי, למשל: אפגניסטן היא 1, צרפת היא 61 וזימבאבואה היא 195.
לכן, המפתח שאפשר לצבור אותו יהיה באורך 7 ספרות, כאשר 4 התווים הראשונים שמוגדרים ל-WidgetID ו-3 התווים האחרונים שמוגדרים ל-CountryID.
נניח שהמפתח מייצג את מספר המשתמשים מצרפת (מזהה המדינה 061) שראו את מזהה הווידג'ט 3276. מפתח הצבירה הוא 3276061.
| מפתח צבירה | |
| מזהה הווידג'ט | מזהה מדינה |
| 3276 | 061 |
אפשר גם ליצור את מפתח הצבירה באמצעות מנגנון גיבוב, כמו SHA-256. לדוגמה, אפשר לבצע גיבוב של המחרוזת {"WidgetId":3276,"CountryID":67} ואז להמיר אותה לערך BigInt של 42943797454801331377966796057547478208888578253058197330928948081739249096287n.
אם ערך הגיבוב מכיל יותר מ-128 ביט, אפשר לקצר אותו כדי לוודא שהוא לא חורג מהערך המקסימלי המותר בקטגוריה, שהוא 2^128−1.
בתוך worklet של Shared Storage, אפשר לגשת למודולים crypto ו-TextEncoder שיכולים לעזור לכם ליצור גיבוב. מידע נוסף על יצירת גיבוב זמין במאמר SubtleCrypto.digest() ב-MDN.
בדוגמה הבאה מוסבר איך ליצור מפתח לקטגוריה מערך גיבוב:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
ערך שניתן לצבור
ערכים שאפשר לצבור מתווספים לפי מפתח בקרב משתמשים רבים כדי ליצור תובנות מצטברות בצורת ערכים של סיכומים בדוחות סיכום.
עכשיו אפשר לחזור לשאלה לדוגמה שהצגנו קודם: "כמה מהמשתמשים שראו את הווידג'ט שלי הם מצרפת?" התשובה לשאלה הזו תיראה בערך כך: "כ-4,881 משתמשים שראו את הווידג'ט מספר 3276 שלי הם מצרפת". הערך aggregatable הוא 1 לכל משתמש, והערך '4,881 משתמשים' הוא הערך aggregated, שהוא הסכום של כל הערכים aggregatable באותו מפתח צבירה.
| מפתח צבירה | ערך שניתן לצבור | |
| מזהה הווידג'ט | מזהה מדינה | מספר צפיות |
| 3276 | 061 | 1 |
בדוגמה הזו, אנחנו מוסיפים לערך 1 לכל משתמש שרואה את הווידג'ט. בפועל, אפשר לשנות את הערך שאפשר לצבור כדי לשפר את יחס האות לרעש.
תקציב התרומה
כל קריאה ל-Private Aggregation API נקראת תרומה. כדי להגן על פרטיות המשתמשים, מספר התרומות שאפשר לקבל מאדם מסוים מוגבל.
כשמסכמים את כל הערכים שניתנים לצבירה בכל מפתחות הצבירה, הסכום חייב להיות נמוך מתקציב התרומה. התקציב מוגדר לכל מקור של worklet, לכל יום, והוא נפרד ל-Protected Audience API ול-worklets של Shared Storage. המערכת משתמשת בחלון נע של כ-24 השעות האחרונות. אם דוח חדש שניתן לצבור נתונים ממנו יגרום לחריגה מהתקציב, הדוח לא נוצר.
תקציב התרומות מיוצג על ידי הפרמטר L1, והוא מוגדר ל-216 (65,536) לכל עשר דקות ביום, עם ערך מגובה של 220 (1,048,576). במאמר הזה מוסבר בהרחבה על הפרמטרים האלה.
הערך של תקציב התרומה הוא שרירותי, אבל רמת הרעש מותאמת אליו. אפשר להשתמש בתקציב הזה כדי למקסם את יחס האות לרעש בערכים הסיכומיים (מידע נוסף זמין בקטע רעש ושינוי קנה מידה).
מידע נוסף על תקציבים לתרומות זמין במאמר הזה. מומלץ גם לעיין במאמר תקציב התרומות לקבלת הנחיות נוספות.
מגבלת התכנים שאפשר לצרף לכל דוח
מגבלת התרומה עשויה להשתנות בהתאם למבצע הקריאה. בשלב זה, הדוחות שנוצרים למפעילי Shared Storage API מוגבלים ל-20 תרומות לכל דוח. לעומת זאת, למבצעים של קריאות ל-Protected Audience API מוקצית מכסה של 100 תרומות לכל דוח. המגבלות האלה נבחרו כדי לאזן בין מספר התכנים שאפשר להטמיע לבין גודל המטען הייעודי.
באחסון משותף, תרומות שבוצעו במסגרת פעולה אחת של run() או selectURL() מקובצות בדוח אחד. ב-Protected Audience, תרומות שמקורות שונים תורמים במכרז מסוים מקובצות יחד.
תרומות עם תוספת שטח
התרומות משתנות עוד יותר באמצעות תכונת מילוי. הוספת נתונים לתוכן הייעודי (payload) מגינה על המידע לגבי המספר האמיתי של התרומות שמוטמעות בדוח שאפשר לצבור. כדי להגיע לאורך קבוע, המרווח מוסיף לעומס התועלת null ערכים (כלומר ערך של 0).
דוחות שאפשר לצבור
אחרי שהמשתמש מפעיל את Private Aggregation API, הדפדפן יוצר דוחות שניתן לצבור, כדי ששירות הצבירה יעבד אותם בשלב מאוחר יותר ויצור דוחות סיכום. דוח שניתן לצבור הוא בפורמט JSON ומכיל רשימה מוצפנת של תרומות, שכל אחת מהן היא זוג {aggregation key, aggregatable value}.
דוחות שאפשר לצבור נשלחים עם עיכוב אקראי של עד שעה.
התכנים שנוספו מוצפנים ואי אפשר לקרוא אותם מחוץ ל-Aggregation Service. שירות הצבירה מפענח את הדוחות ויוצר דוח סיכום. מפתח ההצפנה לדפדפן ומפתח הפענוח לשירות האגרגציה מונפקים על ידי התאם, שמתפקד כשירות ניהול המפתחות. התיאום שומר רשימה של גיבוב בינאריים של קובץ האימג' של השירות כדי לוודא שמבצע הקריאה החוזרת מורשה לקבל את מפתח הפענוח.
דוגמה לדוח שניתן לצבור עם מצב ניפוי באגים מופעל:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
אפשר לבדוק את הדוחות שאפשר לצבור בדף chrome://private-aggregation-internals:

למטרות בדיקה, אפשר להשתמש בלחצן 'שליחת הדוחות שנבחרו' כדי לשלוח את הדוח לשרת באופן מיידי.
איסוף דוחות שניתן לצבור אותם בקבוצות
הדפדפן שולח את הדוחות שאפשר לצבור למקור של ה-worklet שמכיל את הקריאה ל-Private Aggregation API, באמצעות הנתיב הידוע הבא:
- לאחסון משותף:
/.well-known/private-aggregation/report-shared-storage - לקהל מוגן:
/.well-known/private-aggregation/report-protected-audience
בנקודות הקצה האלה, תצטרכו להפעיל שרת – שמשמש כקולקטור – שמקבל את הדוחות שאפשר לצבור שנשלחים מהלקוחות.
לאחר מכן השרת אמור לקבץ את הדוחות ולשלוח את האוסף לשירות הצבירה. יוצרים קבוצות על סמך המידע שזמין במטען הייעודי (payload) הלא מוצפן של הדוח שאפשר לצבור, כמו השדה shared_info. מומלץ שהקבוצות יכילו 100 דוחות או יותר.
אתם יכולים לבחור לאסוף את הבקשות בקבוצות על בסיס יומי או שבועי. זוהי שיטה גמישה, ואפשר לשנות את שיטת הקיבוץ לאירועים ספציפיים שבהם צפוי נפח גדול יותר – לדוגמה, ימים בשנה שבהם צפויות יותר חשיפות. רצוי שהקבוצות יכללו דוחות מאותה גרסת API, מאותו מקור דיווח ומאותה שעה מתוזמנת לדיווח.
סינון מזהים
באמצעות Private Aggregation API ו-Aggregation Service אפשר להשתמש במזהי סינון כדי לעבד מדידות ברמה פרטנית יותר, למשל לכל קמפיין פרסום, במקום לעבד את התוצאות בשאילתות גדולות יותר.

כדי להתחיל להשתמש באפשרות הזו כבר היום, ריכזנו כאן כמה שלבים שאפשר ליישם בהטמעה הנוכחית שלכם.
השלבים של Shared Storage
אם אתם משתמשים ב-Shared Storage API בתהליך:
מגדירים איפה רוצים להצהיר על המודול החדש של Shared Storage ולהריץ אותו. בדוגמה הבאה, קראנו לקובץ המודול
filtering-worklet.js, והוא רשום כ-filtering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();חשוב לזכור שאפשר להגדיר את
filteringIdMaxBytesלכל דוח, ואם לא מגדירים אותו, הערך שמוגדר כברירת מחדל הוא 1. ערך ברירת המחדל הזה נועד למנוע הגדלה מיותרת של גודל המטען השימושי, וכך להפחית את עלויות האחסון והעיבוד. מידע נוסף זמין במאמר הסבר על תרומות גמישות.בקובץ שבו השתמשתם למעלה, במקרה הזה
filtering-worklet.js, כשאתם מעבירים תרומה אלprivateAggregation.contributeToHistogram(...)בתוך ה-worklet של האחסון המשותף, אתם יכולים לציין מזהה סינון.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);דוחות שאפשר לצבור יישלחו לאן שהגדרתם את נקודת הקצה
/.well-known/private-aggregation/report-shared-storage. ממשיכים לקרוא את המדריך לסינון מזהי כדי לקבל מידע על השינויים הנדרשים בפרמטרים של משימות Aggregation Service.
אחרי שהאצווה תושלם ותישלח לשירות הצבירה שנפרס, התוצאות המסוננות אמורות להופיע בדוח הסיכום הסופי.
שלבים ליצירת Protected Audience
אם אתם משתמשים ב-Protected Audience API בתהליך:
בהטמעה הנוכחית של 'קהל מוגן', אפשר להגדיר את האפשרויות הבאות כדי לקשר אותן לצבירה פרטית. בניגוד לאחסון משותף, עדיין לא ניתן להגדיר את הגודל המקסימלי של מזהה הסינון. כברירת מחדל, הגודל המקסימלי של מזהה הסינון הוא 1 בייט והוא יוגדר כ-
0n. חשוב לזכור שהן יוגדרו ב[פונקציות הדיווח על קהל מוגן](פונקציות הדיווח על קהל מוגן (למשלreportResult()אוgenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);דוחות שאפשר לצבור יישלחו לאן שהגדרתם את נקודת הקצה
/.well-known/private-aggregation/report-protected-audience. אחרי שהאצווה תושלם ותישלח לשירות הצבירה שנפרס, התוצאות המסוננות אמורות להופיע בדוח הסיכום הסופי. תוכלו לעיין בהסברים הבאים על Attribution Reporting API ועל Private Aggregation API, וגם בהצעה הראשונית.
אפשר להמשיך למדריך לסינון מזהי בשירות הצבירה, או לעבור לקטע Attribution Reporting API כדי לקרוא הסבר מפורט יותר.
Aggregation Service
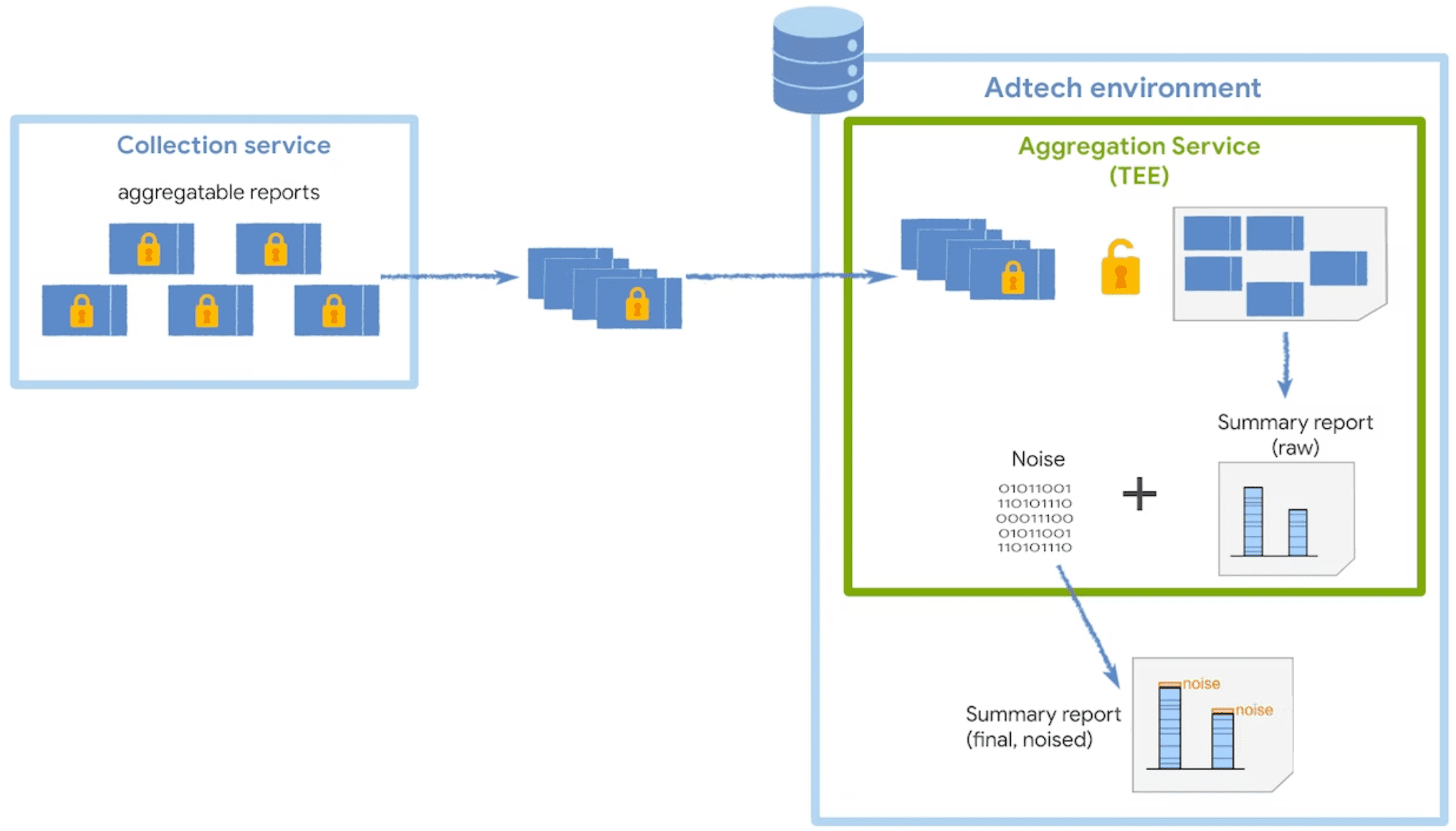
שירות האגרגציה מקבל מהאוסף דוחות מוצפנים שניתן לצבור אותם ויוצר דוחות סיכום. במדריך האצווה מפורטות אסטרטגיות נוספות לאיסוף דוחות שניתנים לצבירה באוסף.
השירות פועל בסביבת מחשוב אמינה (TEE), שמספקת רמה מסוימת של ודאות לגבי תקינות הנתונים, הסודיות שלהם ותקינות הקוד. כדי לקבל מידע נוסף על האופן שבו נעשה שימוש במתאמים לצד סביבות TEE, כדאי לקרוא על התפקיד והמטרה שלהם.
דוחות סיכום
דוחות סיכום מאפשרים לכם לראות את הנתונים שאספתם עם הוספת רעש. אפשר לבקש דוחות סיכום של קבוצת מפתחות נתונה.
דוח סיכום מכיל קבוצה של צמדי מפתח-ערך בסגנון מילון JSON. כל זוג מכיל:
bucket: מפתח הצבירה כמחרוזת של מספר בינארי. אם מפתח הסיכום שבו נעשה שימוש הוא '123', הקטגוריה תהיה '1111011'.value: הערך הסיכום של יעד מדידה נתון, שמצטבר מכל הדוחות הזמינים שאפשר לצבור, עם הוספת רעש.
לדוגמה:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
רעש ושינוי גודל
כדי לשמור על פרטיות המשתמשים, שירות הצבירה מוסיף רעש פעם אחת לכל ערך סיכום בכל פעם שמתבצעת בקשה לדוח סיכום. ערכי הרעש נשלפים באופן אקראי מהתפלגות ההסתברות של Laplace. אין לכם שליטה ישירה על הדרכים שבהן נוסף הרעש, אבל אתם יכולים להשפיע על ההשפעה של הרעש על נתוני המדידה שלו.
התפלגות הרעש זהה ללא קשר לסכום של כל הערכים שאפשר לצבור. לכן, ככל שהערכים שאפשר לצבור גדולים יותר, כך קטן הסיכוי שהרעש ישפיע עליהם.
לדוגמה, נניח שלחלוקה של הרעש יש סטיית תקן של 100 והיא ממוקמת במרכז האפס. אם הערך שנאסף בדוח שאפשר לצבור (או 'ערך שאפשר לצבור') הוא רק 200, סטיית התקן של הרעש תהיה 50% מהערך המצטבר. לעומת זאת, אם הערך שאפשר לצבור הוא 20,000, סטיית התקן של הרעש תהיה רק 0.5% מהערך המצטבר. לכן, לערך המצטבר של 20,000 יהיה יחס אות/רעש גבוה בהרבה.
לכן, הכפלת הערך שאפשר לצבור בגורם שינוי יכולה לעזור לצמצם את הרעש. גורם לקביעת קנה מידה מייצג את מידת השינוי שרוצים לבצע בערך נתון שאפשר לצבור.

הגדלת הערכים על ידי בחירה בגורם גדול יותר לקביעת קנה מידה מפחיתה את הרעש היחסי. עם זאת, הפעולה הזו גורמת לכך שהסכום של כל התרומות בכל הקטגוריות יגיע למגבלת התקציב של התרומות מהר יותר. התאמת הערכים למטה על ידי בחירה בערך קבוע קטן יותר של גורם ההתאמה מגדילה את הרעש היחסי, אבל מפחיתה את הסיכון להגיע למגבלת התקציב.
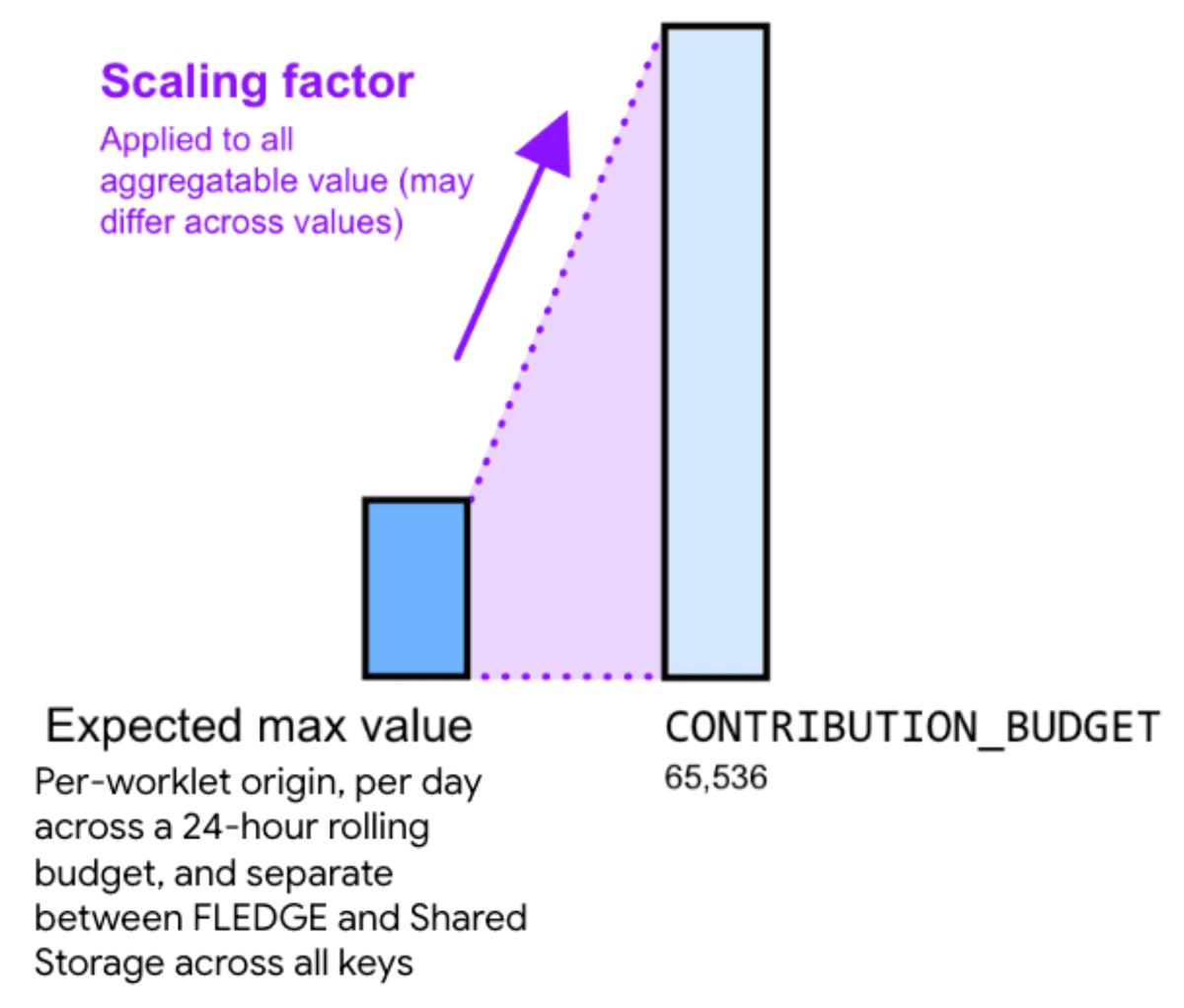
כדי לחשב גורם התאמה מתאים, צריך לחלק את תקציב התרומה בסכום המקסימלי של ערכים שאפשר לצבור מכל המפתחות.
מידע נוסף זמין במסמכי העזרה בנושא תקציב תרומות.
יצירת מעורבות ושיתוף משוב
אנחנו עדיין בוחנים את Private Aggregation API ועשויים לשנות אותו בעתיד. אם תנסו את ה-API הזה ותהיה לכם משוב, נשמח לשמוע אותו.
- GitHub: קוראים את הסבר, שואלים שאלות ומשתתפים בדיון.
- תמיכה למפתחים: אפשר לשאול שאלות ולהצטרף לדיוני המאגר של תמיכת המפתחים של ארגז החול לפרטיות.
- כדי לקבל את ההודעות האחרונות שקשורות לצבירה פרטית, כדאי להצטרף לקבוצה Shared Storage API ולקבוצה Protected Audience API.