Private Aggregation API の主なコンセプト
このドキュメントの対象者
Private Aggregation API を使用すると、クロスサイト データにアクセスできるワークレットから集計データを収集できます。ここで説明するコンセプトは、Shared Storage API と Protected Audience API 内でレポート機能を構築するデベロッパーにとって重要です。
- クロスサイト測定用のレポート システムを構築しているデベロッパー。
- マーケティング担当者、データ サイエンティスト、その他の概要レポートの利用者は、これらのメカニズムを理解することで、最適化された概要レポートを取得するための設計上の決定を下すことができます。
主な用語
このドキュメントを読む前に、重要な用語とコンセプトを理解しておくことをおすすめします。これらの用語について、以下で詳しく説明します。
- 集計キー(バケット)は、事前に定義されたデータポイントの集合です。たとえば、ブラウザが国名を報告する位置情報のバケットを収集できます。集計キーには複数のディメンション(国、コンテンツ ウィジェットの ID など)を含めることができます。
- 集計可能な値は、集計キーに収集される個々のデータポイントです。フランスのユーザーがコンテンツを見た回数を測定する場合、
Franceは集計キーのディメンションで、1のviewCountは集計可能な値です。 - 集計可能レポートは、ブラウザ内で生成され、暗号化されます。Private Aggregation API の場合、単一のイベントに関するデータが含まれます。
- 集計サービスは、集計可能レポートのデータを取り込み、概要レポートを作成します。
- サマリー レポートは、集計サービスの最終的な出力で、ノイズの多い集計されたユーザーデータと詳細なコンバージョン データが含まれています。
- ワークレットは、特定の JavaScript 関数を実行してリクエスト元に情報を返すことができるインフラストラクチャの一部です。ワークレット内では JavaScript を実行できますが、外部ページとのやり取りや通信はできません。
Private Aggregation ワークフロー
集計キーと集計可能な値を指定して Private Aggregation API を呼び出すと、ブラウザは集計可能なレポートを生成します。レポートは、レポートをバッチ処理するサーバーに送信されます。バッチ処理されたレポートは、後で集計サービスによって処理され、概要レポートが生成されます。
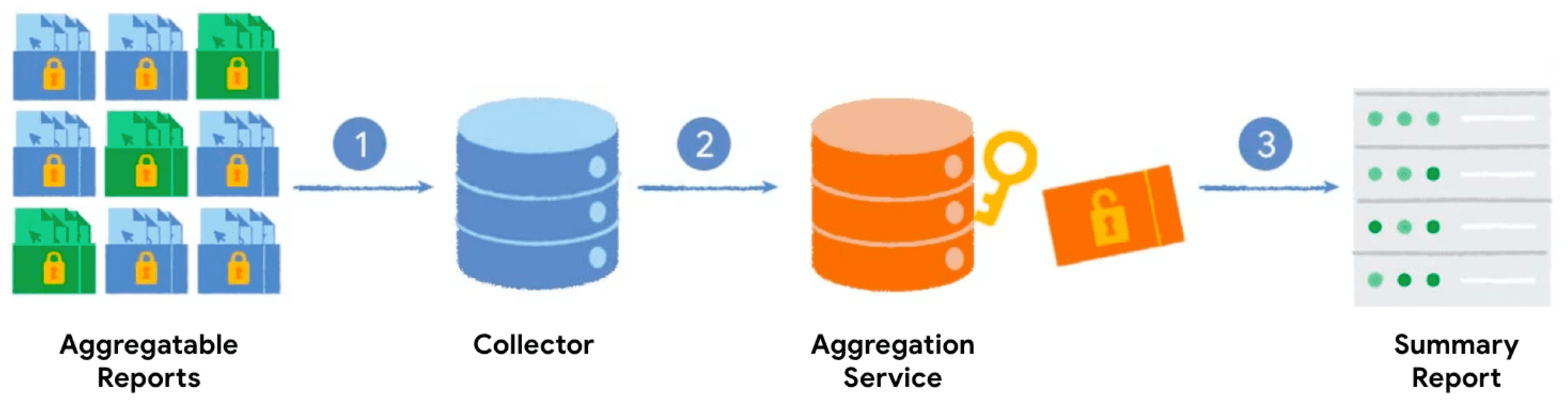
- Private Aggregation API を呼び出すと、クライアント(ブラウザ)が集計可能なレポートを生成し、収集のためにサーバーに送信します。
- サーバーはクライアントからレポートを収集し、バッチ処理して集計サービスに送信します。
- 十分な数のレポートを収集したら、それらをバッチ処理して信頼できる実行環境で実行されている集計サービスに送信し、概要レポートを生成します。
このセクションで説明するワークフローは、Attribution Reporting API に似ています。ただし、アトリビューション レポートでは、発生するタイミングが異なるインプレッション イベントとコンバージョン イベントから収集されたデータが関連付けられます。プライベート アグリゲーションは、単一のクロスサイト イベントを測定します。
集計キー
集計キー(略して「キー」)は、集計可能な値が蓄積されるバケットを表します。1 つ以上のディメンションをキーにエンコードできます。ディメンションは、ユーザーの年齢層や広告キャンペーンのインプレッション数など、詳細な分析情報を得たい項目を表します。
たとえば、複数のサイトに埋め込まれたウィジェットがあり、そのウィジェットが表示されたユーザーの国を分析したい場合などです。「ウィジェットを見たユーザーのうち、国 X のユーザーは何人ですか?」などの質問に回答したい場合。この質問に関するレポートを作成するには、ウィジェット ID と国 ID の 2 つのディメンションをエンコードする集計キーを設定します。
Private Aggregation API に指定するキーは BigInt で、複数のディメンションで構成されます。この例では、ディメンションはウィジェット ID と国 ID です。ウィジェット ID は最大 4 桁(1234 など)で、各国はアルファベット順で番号にマッピングされます(アフガニスタンは 1、フランスは 61、ジンバブエは 195 など)。したがって、集計可能なキーは 7 桁で、最初の 4 桁は WidgetID 用に予約され、最後の 3 桁は CountryID 用に予約されます。
キーが、ウィジェット ID 3276 を見たフランスのユーザー(国 ID 061)の数を表すとします。集計キーは 3276061 です。
| 集計キー | |
| ウィジェット ID | 国 ID |
| 3276 | 061 |
集計キーは、SHA-256 などのハッシュ化メカニズムを使用して生成することもできます。たとえば、文字列 {"WidgetId":3276,"CountryID":67} をハッシュしてから、42943797454801331377966796057547478208888578253058197330928948081739249096287n の BigInt 値に変換できます。ハッシュ値が 128 ビットを超える場合は、バケット値の最大許容値 2^128−1 を超えないように切り捨てることができます。
共有ストレージ ワークレット内では、ハッシュの生成に役立つ crypto モジュールと TextEncoder モジュールにアクセスできます。ハッシュの生成の詳細については、MDN の SubtleCrypto.digest() をご覧ください。
次の例は、ハッシュ化された値からバケットキーを生成する方法を示しています。
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
集計可能な値
集計可能な値は、多くのユーザーのキーごとに合計され、集計レポートの概要値の形で集計された分析情報が生成されます。
前述の例の質問「ウィジェットを見たユーザーのうち、フランスからのユーザーは何人ですか?」に戻りましょう。この質問の回答は、「ウィジェット ID 3276 を見たユーザーのうち、フランスのユーザーは約 4,881 人です」などになります。集計可能な値はユーザーごとに 1 で、「4, 881 ユーザー」は集計値です。これは、その集計キーのすべての集計可能な値の合計です。
| 集計キー | 集計可能な値 | |
| ウィジェット ID | 国 ID | 視聴回数 |
| 3276 | 061 | 1 |
この例では、ウィジェットを表示したユーザーごとに値を 1 ずつ増やします。実際には、集計可能な値をスケーリングして信号対雑音比を改善できます。
拠出予算
Private Aggregation API への呼び出しは、それぞれ「コントリビューション」と呼ばれます。ユーザーのプライバシーを保護するため、個人から収集できる寄付の数には上限があります。
すべての集計キーのすべての集計可能な値を合計した値が、貢献度予算を下回っている必要があります。予算は、ワークレットのオリジンごとに 1 日あたりに設定され、Protected Audience API ワークレットと Shared Storage ワークレットで別々に設定されます。1 日には、過去 24 時間程度のローリング ウィンドウが使用されます。新しい集計レポートによって予算が超過する場合、レポートは作成されません。
コントリビューション バジェットはパラメータ L1 で表され、1 日 10 分あたり 216(65,536)に設定され、220(1,048,576)のバックストップを設定します。これらのパラメータの詳細については、説明をご覧ください。
コントリビューション バジェットの値は任意ですが、ノイズはそれに比例してスケーリングされます。この予算を使用して、サマリー値の信号対雑音比を最大化できます(ノイズとスケーリングのセクションで詳しく説明します)。
コントリビューション バジェットについて詳しくは、説明をご覧ください。また、拠出金予算も参照してください。
レポートあたりの貢献度上限
拠出限度額は、呼び出し元によって異なる場合があります。現在のところ、Shared Storage API 呼び出し元に対して生成されるレポートは、レポートごとに 20 件の投稿に制限されています。一方、Protected Audience API 呼び出し元は、レポートあたり 100 件の貢献に制限されています。これらの上限は、埋め込むことができる投稿の数とペイロードのサイズのバランスを取るために選択されています。
共有ストレージの場合、単一の run() オペレーションまたは selectURL() オペレーション内で行われた貢献は、1 つのレポートにバッチ処理されます。Protected Audience の場合、オークション内の単一のオリジンによる貢献はまとめてバッチ処理されます。
パディングありの投稿
寄付は、パディング機能によってさらに変更されます。ペイロードをパディングすることで、集計可能なレポートに埋め込まれた実際の寄付数に関する情報が保護されます。パディングでは、null のコントリビューション(値 0)でペイロードを拡張して、固定長に達します。
集計可能レポート
ユーザーが Private Aggregation API を呼び出すと、ブラウザは集計可能なレポートを生成します。このレポートは、後で集計サービスによって処理され、サマリー レポートが生成されます。集計可能なレポートは JSON 形式で、暗号化された貢献リストが含まれます。各貢献は {aggregation key, aggregatable value} ペアです。集計可能レポートは、最大 1 時間のランダムな遅延で送信されます。
コントリビューションは暗号化され、Aggregation Service の外部からは読み取れません。集計サービスはレポートを復号し、概要レポートを生成します。ブラウザの暗号鍵と集約サービスの復号鍵は、鍵管理サービスとして機能するコーディネーターによって発行されます。コーディネーターは、サービス イメージのバイナリハッシュのリストを保持し、呼び出し元が復号鍵を受信できることを確認します。
デバッグモードが有効になっている集計可能なレポートの例:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
集計可能なレポートは、chrome://private-aggregation-internals ページで確認できます。

テスト目的で、[選択したレポートを送信] ボタンを使用して、レポートをすぐにサーバーに送信できます。
集計可能レポートを収集してバッチ処理する
ブラウザは、リストに記載されている well-known パスを使用して、集約可能なレポートを Private Aggregation API の呼び出しを含むワークレットのオリジンに送信します。
- 共有ストレージの場合:
/.well-known/private-aggregation/report-shared-storage - Protected Audience の場合:
/.well-known/private-aggregation/report-protected-audience
これらのエンドポイントでは、クライアントから送信された集計可能レポートを受信するコレクタとして機能するサーバーを運用する必要があります。
サーバーはレポートをバッチ処理し、バッチを集計サービスに送信する必要があります。集計可能レポートの暗号化されていないペイロード(shared_info フィールドなど)で利用可能な情報に基づいてバッチを作成します。理想的には、バッチごとに 100 件以上のレポートを含める必要があります。
バッチ処理は、毎日または毎週行うことができます。この戦略は柔軟性があり、インプレッション数の増加が予想される特定のイベント(インプレッション数の増加が予想される日付など)に合わせてバッチ処理戦略を変更できます。バッチには、同じ API バージョン、レポート送信元、スケジュールされたレポート時間のレポートを含める必要があります。
ID のフィルタリング
Private Aggregation API と Aggregation Service では、フィルタ ID を使用して、大規模なクエリで結果を処理するのではなく、広告キャンペーンごとなど、より詳細なレベルで測定を処理できます。

すぐにこの機能を使用できるように、現在の実装に適用する大まかな手順をご紹介します。
共有ストレージの手順
フローで Shared Storage API を使用している場合:
新しい共有ストレージ モジュールを宣言して実行する場所を定義します。次の例では、モジュール ファイルの名前を
filtering-worklet.jsとし、filtering-exampleの下に登録しています。(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();filteringIdMaxBytesはレポートごとに構成可能で、設定されていない場合はデフォルトで 1 になります。このデフォルト値は、ペイロード サイズが不必要に増加し、ストレージと処理のコストが増加しないようにするためのものです。詳しくは、フレキシブル拠出の説明をご覧ください。上記で使用したファイル(この場合は
filtering-worklet.js)で、共有ストレージ ワークレット内のprivateAggregation.contributeToHistogram(...)にコントリビューションを渡すときに、フィルタ ID を指定できます。// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);集計可能レポートは、エンドポイント
/.well-known/private-aggregation/report-shared-storageを定義した場所に送信されます。Aggregation Service ジョブ パラメータで必要な変更については、ID のフィルタリング ガイドをご覧ください。
バッチ処理が完了してデプロイされた集計サービスに送信されると、フィルタされた結果が最終的な概要レポートに反映されます。
Protected Audience の手順
フロー内で Protected Audience API を使用している場合:
Protected Audience の現在の実装内で、次の設定を行うと、プライベート集計にフックできます。共有ストレージとは異なり、フィルタ ID の最大サイズを構成することはできません。デフォルトでは、フィルタ ID の最大サイズは 1 バイトで、
0nに設定されます。これらの値は、Protected Audience レポート関数(reportResult()やgenerateBid()など)で設定されます。const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);集計可能レポートは、エンドポイント
/.well-known/private-aggregation/report-protected-audienceを定義した場所に送信されます。バッチ処理が完了してデプロイされた集計サービスに送信されると、フィルタされた結果が最終的な概要レポートに反映されます。Attribution Reporting API と Private Aggregation API に関する説明と、最初の提案書を以下に示します。
詳しくは、集計サービスのID のフィルタリング ガイドを参照するか、Attribution Reporting API のセクションをご覧ください。
集計サービス
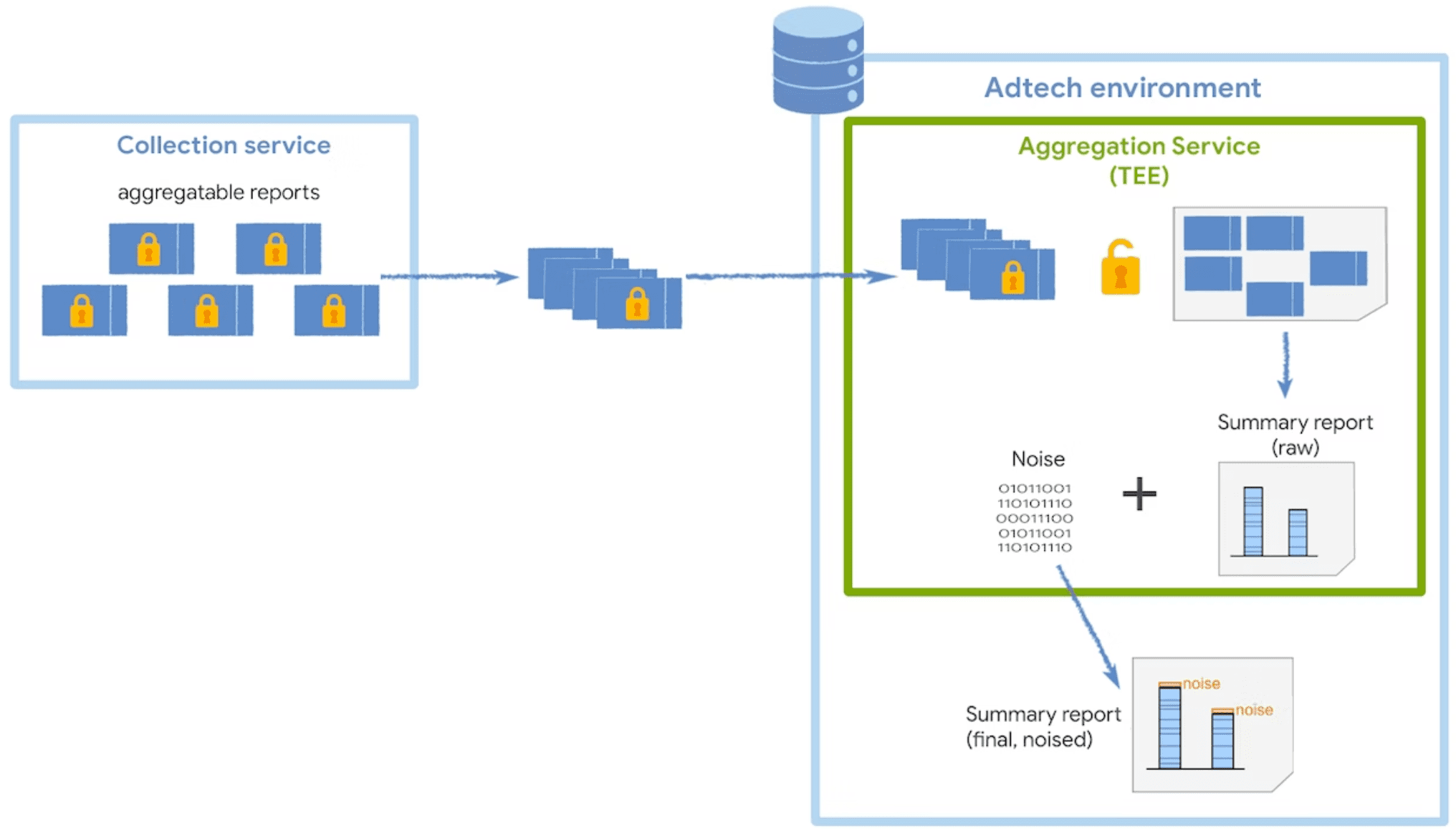
集計サービスは、コレクタから暗号化された集計可能レポートを受け取り、概要レポートを生成します。コレクタで集計可能なレポートをバッチ処理する方法の詳細については、バッチ処理ガイドをご覧ください。
このサービスは、データの整合性、データの機密性、コードの整合性について一定の保証を提供する高信頼実行環境(TEE)で実行されます。コーディネーターが TEE とともにどのように使用されるかについて詳しくは、役割と目的をご覧ください。
概要レポート
概要レポートでは、収集したデータにノイズが追加されたものを確認できます。特定のキーセットの概要レポートをリクエストできます。
概要レポートには、JSON 辞書形式の Key-Value ペアのセットが含まれています。各ペアには次のものが含まれます。
bucket: バイナリ数値文字列としての集計キー。使用される集計キーが「123」の場合、バケットは「1111011」になります。value: 特定の測定目標の概要値。利用可能なすべての集計可能レポートから合計され、ノイズが追加されます。
次に例を示します。
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
ノイズとスケーリング
ユーザーのプライバシーを保護するため、集計サービスは、概要レポートがリクエストされるたびに、各概要値にノイズを 1 回追加します。ノイズ値は ラプラス確率分布からランダムに抽出されます。ノイズの追加方法を直接制御することはできませんが、測定データへのノイズの影響を軽減することはできます。
ノイズ分布は、集計可能なすべての値の合計に関係なく同じです。したがって、集計可能な値が大きいほど、ノイズの影響は小さくなります。
たとえば、ノイズ分布の標準偏差が 100 で、中心がゼロであるとします。収集された集計可能なレポート値(「集計可能な値」)が 200 に過ぎない場合、ノイズの標準偏差は集計値の 50% になります。ただし、集計可能な値が 20,000 の場合、ノイズの標準偏差は集計値の 0.5% にすぎません。したがって、集計可能な値が 20,000 の場合、信号対雑音比は大幅に高くなります。
したがって、集計可能な値にスケーリング ファクタを掛けると、ノイズを低減できます。スケール係数は、特定の集計可能な値をスケーリングする量を表します。

より大きなスケーリング係数を選択して値をスケールアップすると、相対的なノイズが低減されます。ただし、これにより、すべてのバケットのすべての拠出の合計が拠出予算の上限に達する速度も速くなります。小さいスケーリング係数定数を選択して値をスケールダウンすると、相対ノイズが増加しますが、予算の上限に達するリスクは軽減されます。
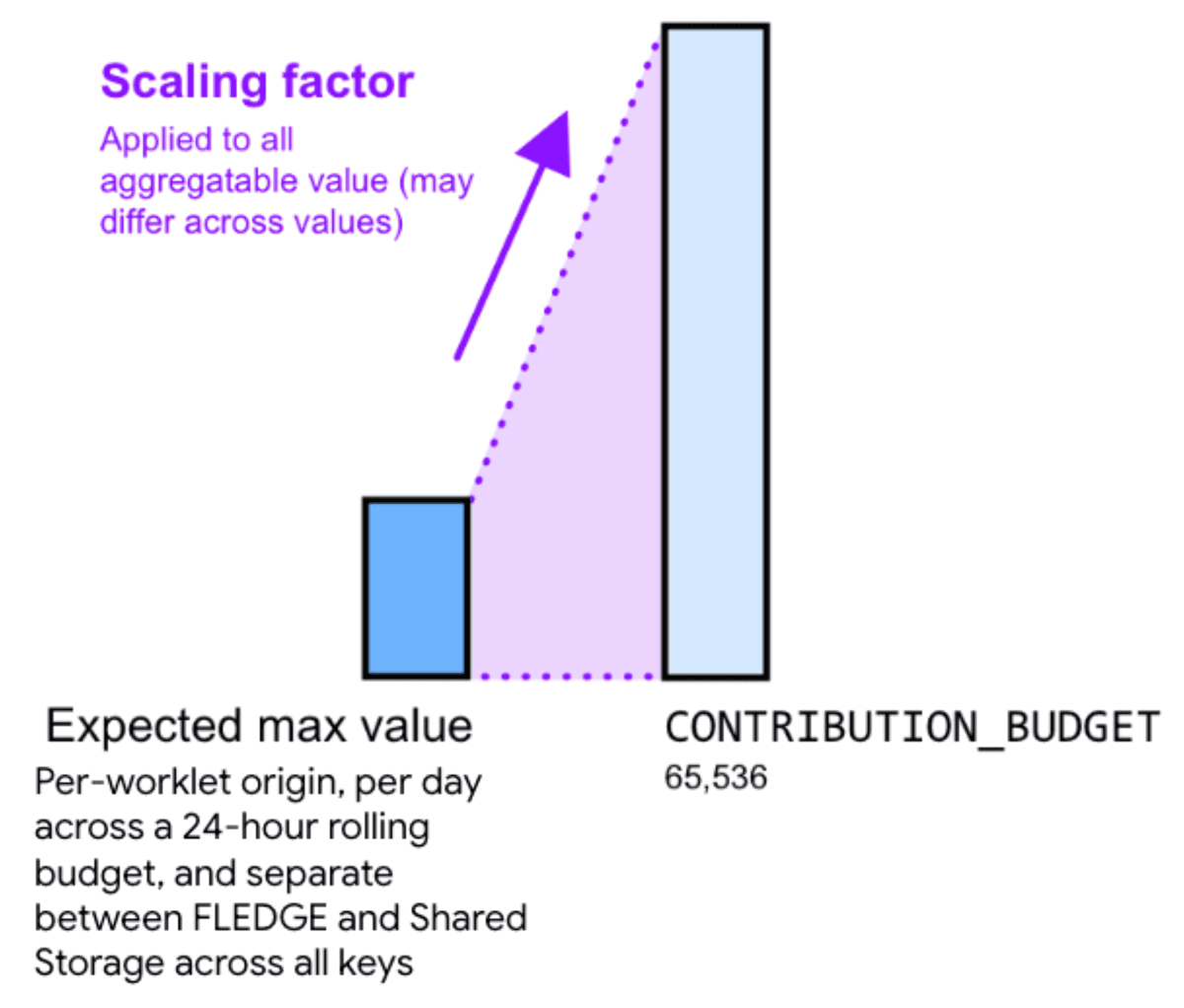
適切なスケーリング ファクタを計算するには、コントリビューション バジェットを、すべてのキーの集計可能な値の最大合計で割ります。
詳しくは、拠出金予算のドキュメントをご覧ください。
意見交換とフィードバックの提供
Private Aggregation API は現在検討中であり、今後変更される可能性があります。この API をお試しになった際のフィードバックをお寄せください。
- GitHub: 説明を読み、質問を投稿し、ディスカッションに参加します。
- デベロッパー サポート: プライバシー サンドボックス デベロッパー サポート リポジトリで質問や意見交換を行えます。
- Private Aggregation に関する最新のお知らせについては、Shared Storage API グループと Protected Audience API グループに参加してください。