DSPL là viết tắt của Dataset Publishing Language (Ngôn ngữ xuất bản dữ liệu). Tập dữ liệu được mô tả trong DSPL có thể được nhập vào Dữ liệu công khai của Google Explorer, một công cụ cho phép khám phá trực quan .
Lưu ý: Để tải dữ liệu lên Google Public Data bằng cách sử dụng công cụ tải dữ liệu công khai lên, bạn phải có Tài khoản Google.
Hướng dẫn này cung cấp một ví dụ từng bước về cách chuẩn bị Tập dữ liệu DSPL.
Tập dữ liệu DSPL là một gói chứa tệp XML và một tập hợp Tệp CSV. Tệp CSV là các bảng đơn giản chứa dữ liệu của tập dữ liệu. Tệp XML mô tả siêu dữ liệu của tập dữ liệu, bao gồm siêu dữ liệu thông tin như nội dung mô tả về các biện pháp cũng như siêu dữ liệu có cấu trúc như thông tin tham chiếu giữa các bảng. Siêu dữ liệu cho phép người dùng không phải chuyên gia khám phá và trực quan hoá dữ liệu của bạn.
Điều kiện tiên quyết duy nhất để hiểu hướng dẫn này là có về XML. Một số hiểu biết về các khái niệm đơn giản về cơ sở dữ liệu (ví dụ: bảng, khoá chính) có thể giúp ích, nhưng không bắt buộc. Để tham khảo, tệp XML hoàn chỉnh và tập dữ liệu hoàn chỉnh gói liên kết với hướng dẫn này cũng có sẵn để bạn xem xét.
Tổng quan
Trước khi bắt đầu tạo tập dữ liệu, sau đây là thông tin tổng quan về nội dung của tập dữ liệu DSPL:
- Thông tin chung: Giới thiệu về tập dữ liệu
- Khái niệm: Định nghĩa về "sự vật" để xuất hiện trong tập dữ liệu (ví dụ: quốc gia, tỷ lệ thất nghiệp, giới tính, etc.)
- Lát cắt: Tổ hợp các khái niệm có dữ liệu
- Bảng: Dữ liệu cho các khái niệm và lát cắt. Bảng khái niệm giữ bản liệt kê và bảng lát cắt chứa dữ liệu thống kê
- Chủ đề: Dùng để sắp xếp các khái niệm về tập dữ liệu trong một hệ thống phân cấp có ý nghĩa thông qua việc gắn nhãn
Để minh hoạ các khái niệm khá trừu tượng này, hãy xem xét tập dữ liệu (với dữ liệu giả) được sử dụng trong suốt hướng dẫn này: chuỗi thời gian thống kê cho dân số và thất nghiệp, được tổng hợp theo nhiều nhóm quốc gia, Tiểu bang và giới tính của Hoa Kỳ.
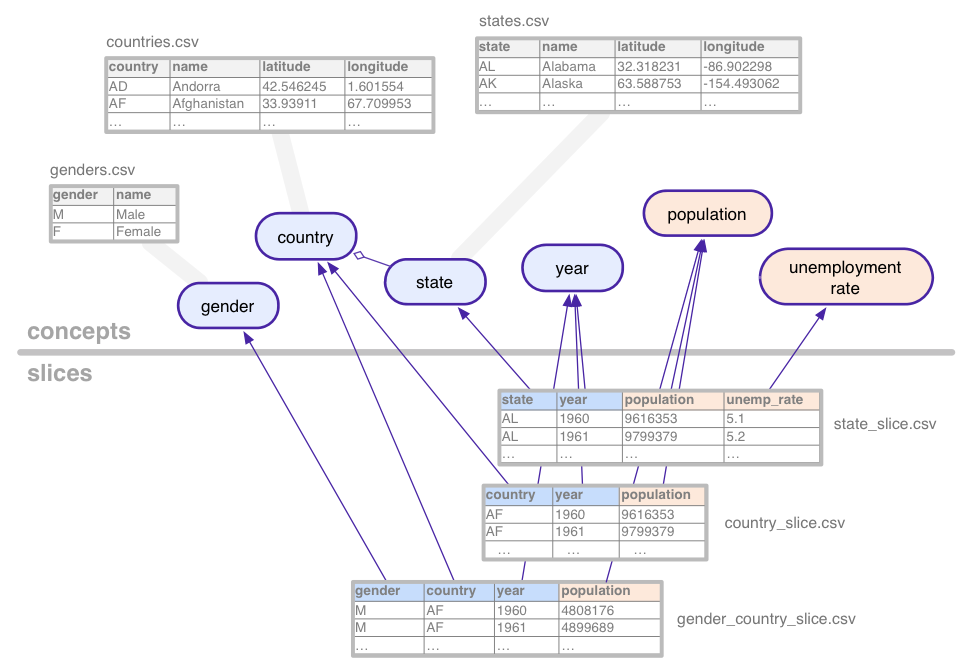
Tập dữ liệu mẫu này xác định các khái niệm sau:
- country
- gender
- dân số
- tiểu bang
- tỷ lệ thất nghiệp
- năm
Các khái niệm theo phân loại (chẳng hạn như trạng thái) có liên quan đến khái niệm tables (bảng liệt kê tất cả giá trị có thể có của chúng) (California, Arizona, v.v.). Các khái niệm có thể có cột bổ sung cho các thuộc tính như tên hoặc quốc gia của một tiểu bang.
Lát cắt xác định từng tổ hợp khái niệm có
trong tập dữ liệu. Một lát cắt chứa kích thước và
chỉ số. Trong hình trên, các tham số có màu xanh dương và
chỉ số có màu cam. Trong ví dụ này, lát cắt
gender_country_slice có dữ liệu cho chỉ số này
population và phương diện country,
year và gender. Một lát cắt khác, được gọi là
country_slice, cung cấp tổng số người dùng hằng năm (chỉ số) cho
quốc gia.
Ngoài phương diện và chỉ số, các phần cũng tham chiếu đến bảng chứa dữ liệu thực tế.
Bây giờ, chúng ta hãy từng bước tạo một tập dữ liệu như vậy trong DSPL (Bộ xử lý tín hiệu kỹ thuật số).
Thông tin về tập dữ liệu
Để bắt đầu, chúng ta cần tạo một tệp XML cho tập dữ liệu. Sau đây là phần mở đầu phần mô tả DSPL cho tập dữ liệu mẫu:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
Nội dung mô tả về tập dữ liệu bắt đầu bằng <dspl> cấp cao nhất
. Thuộc tính targetNamespace chứa một URI
xác định duy nhất tập dữ liệu này. Không gian tên của tập dữ liệu đặc biệt
quan trọng khi xuất bản tập dữ liệu, vì đây sẽ là giá trị nhận dạng toàn cầu của
tập dữ liệu của bạn và cách để người khác tham chiếu đến tập dữ liệu đó.
Lưu ý rằng bạn có thể bỏ qua thuộc tính targetNamespace. Trong
Trong trường hợp này, một không gian tên duy nhất sẽ tự động được tạo khi tập dữ liệu được
đã nhập.
Sử dụng thông tin từ các tập dữ liệu khác
Tập dữ liệu có thể sử dụng lại định nghĩa và dữ liệu từ các tập dữ liệu khác bằng cách nhập
các tập dữ liệu đó. Mỗi phần tử <import> chỉ định
không gian tên của một tập dữ liệu khác mà tập dữ liệu này sẽ tham chiếu.
Trong tập dữ liệu mẫu của mình, chúng tôi sẽ cần một số định nghĩa từ http://www.google.com/publicdata/dataset/google/quantity (một tập dữ liệu do Google tạo ra chứa các khái niệm hữu ích để xác định đại lượng bằng số), và từ các tập dữ liệu thời gian, thực thể và địa lý. Các tập dữ liệu này cung cấp định nghĩa liên quan đến thời gian, đối tượng và địa lý tương ứng.
Phần tử <dspl> trên cùng cung cấp tiền tố không gian tên
khai báo (ví dụ: xmlns:time="http://...") cho mỗi
của các tập dữ liệu đã nhập. Cần khai báo tiền tố để tham chiếu
từ các tập dữ liệu khác một cách ngắn gọn. Ví dụ:
time:year tham chiếu đến định nghĩa của year trong
tập dữ liệu được nhập có không gian tên được liên kết với tiền tố
time.
Thông tin về tập dữ liệu và nhà cung cấp
Phần tử <info> chứa thông tin chung về
tập dữ liệu: tên, nội dung mô tả và URL nơi có thể cung cấp thêm thông tin
đã tìm thấy.
Phần tử <provider> chứa thông tin về
nhà cung cấp tập dữ liệu: tên và URL của tập dữ liệu mà bạn có thể cung cấp thêm thông tin
(thường là trang chủ của nhà cung cấp dữ liệu).
Định nghĩa khái niệm
Chúng tôi hiện đã cung cấp một số thông tin chung về tập dữ liệu, chúng ta đã sẵn sàng để bắt đầu xác định nội dung của chiến dịch. Mục tiêu tiếp theo của chúng tôi là thêm số liệu thống kê về dân số của các quốc gia trong 50 năm qua.
Điều đầu tiên chúng ta cần làm là đưa ra một số định nghĩa cho các khái niệm dân số, quốc gia và năm. Trong DSPL, những định nghĩa này được gọi là khái niệm.
Khái niệm là định nghĩa về một loại dữ liệu xuất hiện trong một tập dữ liệu. Các giá trị dữ liệu tương ứng với một khái niệm nhất định được gọi các phiên bản của khái niệm đó.
Dân số
Hãy bắt đầu bằng việc định nghĩa khái niệm tập hợp. Trong một
Tài liệu DSPL, các khái niệm được định nghĩa trong <concepts>
nằm ngay sau tập dữ liệu và thông tin về nhà cung cấp.
Sau đây là một khái niệm về tập hợp chỉ cần một lượng thông tin tối thiểu
cho mọi khái niệm: id (giá trị nhận dạng duy nhất), name và
type.
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Dưới đây là cách thức hoạt động của mẫu:
- Mỗi khái niệm phải cung cấp một
idgiúp nhận dạng duy nhất khái niệm trong tập dữ liệu. Điều này có nghĩa là không có hai khái niệm nào được xác định trong cùng một tập dữ liệu có thể có cùng mã nhận dạng. - Cũng giống như tập dữ liệu và nhà cung cấp tập dữ liệu đó,
Các phần tử
<info>cung cấp thông tin dạng văn bản về khái niệm, chẳng hạn như tên và nội dung mô tả. - Phần tử
<type>chỉ định kiểu dữ liệu cho thực thể của khái niệm (nói cách khác là "giá trị" của khái niệm). Trong ví dụ này, loạipopulationlàintegerDSPL hỗ trợ các kiểu dữ liệu sau:stringintegerfloatbooleandate
Quốc gia
Bây giờ, hãy viết định nghĩa về khái niệm quốc gia:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
Định nghĩa về khái niệm quốc gia bắt đầu giống như định nghĩa trước đó,
với id, info và type.
Giá trị khái niệm
Các khái niệm phân loại như quốc gia có bản liệt kê tất cả
thực thể. Nói cách khác, bạn có thể liệt kê tất cả các quốc gia có thể
tham chiếu. Tuy nhiên, để làm được điều này, mỗi quốc gia cần có một giá trị nhận dạng riêng biệt.
Ví dụ này sử dụng
mã quốc gia theo ISO để xác định các quốc gia; những mã này
thuộc loại string.
Trong ví dụ này, bạn không cần sử dụng mã ISO; bạn cũng có thể sử dụng tên quốc gia. Tuy nhiên, tên gọi khác nhau tuỳ theo ngôn ngữ, có thể thay đổi theo thời gian và không phải lúc nào cũng được sử dụng nhất quán trên các tập dữ liệu. Đối với các quốc gia và đối với các khái niệm phân loại nói chung, đây là thực hành chọn nội dung, ngắn gọn, ổn định, thường dùng và không phụ thuộc vào ngôn ngữ giá trị nhận dạng (nếu có).
Thuộc tính khái niệm
Ngoài id, khái niệm quốc gia còn có
Phần tử <property> chỉ định tên của quốc gia.
Nói cách khác, tên quốc gia ("ở Ireland") là một thuộc tính
của quốc gia có id IE. Tài sản là cách DSPL cung cấp
thông tin có cấu trúc bổ sung về các đối tượng của một khái niệm.
Tương tự như khái niệm, thuộc tính cũng có id,
info và type.
Dữ liệu khái niệm
Cuối cùng, khái niệm quốc gia có phần tử <table>.
Phần tử này tham chiếu đến một bảng liệt kê danh sách tất cả
quốc gia.
Việc sử dụng bảng có ý nghĩa đối với một số khái niệm, nhưng không có ý nghĩa đối với các khái niệm khác. Cho thực thể không hợp lý khi liệt kê tất cả các giá trị có thể có cho tập hợp khái niệm. Tuy nhiên, nếu bạn tham khảo một bảng cho một khái niệm thì bảng đó phải chứa tất cả các trường hợp của khái niệm đó, ví dụ: danh sách này phải liệt kê mọi quốc gia chứ không chỉ một vài quốc gia mẫu.
Tập dữ liệu xác định bảng countries_table như sau:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Bảng quốc gia chỉ định các cột của bảng và loại dữ liệu,
và tham chiếu đến tệp CSV chứa dữ liệu đó. Tệp CSV này có thể là
được đóng gói và tải lên cùng với tập dữ liệu XML hoặc truy cập từ xa thông qua giao thức HTTP, HTTPS,
hoặc FTP. Trong các trường hợp sau, bạn sẽ thay thế countries.csv bằng
một URL, ví dụ: http://www.myserver.com/mydata/countries.csv.
Bất kể tệp được lưu trữ ở đâu, tệp CSV sẽ có dạng như sau:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
Hàng đầu tiên của bảng liệt kê các mã cột, như được chỉ định trong DSPL
Định nghĩa table. Mỗi hàng sau đây tương ứng với một hàng
ví dụ về khái niệm quốc gia. Nếu khái niệm có bảng, thì
bảng phải chứa tất cả các trường hợp của khái niệm- trong
trường hợp, trường này phải liệt kê tất cả các quốc gia.
Các cột được liên kết với khái niệm quốc gia và thuộc tính của quốc gia đó dựa trên
mã nhận dạng của họ. Mã nhận dạng của cột đầu tiên (country) khớp với khái niệm
mã nhận dạng. Điều này có nghĩa là cột này chứa mã nhận dạng quốc gia duy nhất
được xác định theo khái niệm quốc gia. Cột tiếp theo tương ứng với
thuộc tính name của khái niệm quốc gia. Các giá trị
trong cột này khớp với các giá trị của thuộc tính name.
Có một vài yêu cầu đối với dữ liệu CSV cho bảng khái niệm:
- Tiêu đề cột trong dòng đầu tiên của tệp dữ liệu phải
khớp chính xác với khái niệm
idvà thuộc tínhidkhái niệm liên quan đến dữ liệu (mặc dù đơn đặt hàng có thể thay đổi). - Mỗi hàng phải có chính xác số phần tử như số phần tử các thuộc tính trên khái niệm (ngay cả khi giá trị trống).
- Mỗi giá trị cho trường
idcủa khái niệm (ở đây, mã quốc gia) phải là duy nhất và không được để trống (trường trống là trường không hoặc chỉ có khoảng trắng). - Giá trị của những thuộc tính tham chiếu đến các khái niệm khác phải là trống hoặc là giá trị hợp lệ của khái niệm được tham chiếu.
- Các giá trị chứa dấu phẩy, dấu ngoặc kép hoặc ký tự dòng mới phải là được đặt hoàn toàn trong dấu ngoặc kép.
- Mọi ký tự dấu ngoặc kép cố định bên trong một giá trị phải nằm ngay lập tức đứng sau một dấu ngoặc kép khác.
Năm
Khái niệm cuối cùng mà chúng tôi cần cho dữ liệu dân số của quốc gia mình là một khái niệm
đại diện cho năm. Thay vì định nghĩa một khái niệm mới, chúng ta sẽ sử dụng
ý tưởng từ một trong những tập dữ liệu mà chúng tôi đã nhập:
"http://www.google.com/publicdata/dataset/google/time". Để thực hiện việc này,
chúng ta cần tham chiếu dưới dạng time:year, trong đó time
biểu thị tập dữ liệu được tham chiếu, và year xác định
khái niệm.
Các khái niệm chuẩn
time:year là một phần trong một tập hợp nhỏ các khái niệm chuẩn
do Google xác định. Khái niệm chuẩn cung cấp các định nghĩa cơ bản về thời gian,
địa lý, số lượng, đơn vị, v.v.
Trên thực tế, khái niệm quốc gia được định nghĩa ở trên tồn tại như một
khái niệm chuẩn. Chúng tôi chỉ tạo bài viết này chỉ nhằm mục đích minh hoạ.
Bất cứ khi nào có thể, bạn nên sử dụng các khái niệm chuẩn trong tập dữ liệu của mình,
trực tiếp hoặc bằng cách mở rộng các tiện ích đó (tìm hiểu thêm về tiện ích bên dưới). Các khái niệm chuẩn
làm cho dữ liệu của bạn có thể so sánh với các tập dữ liệu khác, đồng thời bật các tính năng cho
trong Public Data Explorer. Ví dụ: tạo ảnh động dữ liệu theo thời gian
hoặc hiển thị dữ liệu địa lý trên bản đồ dựa vào việc sử dụng time và
geo khái niệm chuẩn tương ứng.
Lát đầu tiên
Bây giờ, khi chúng ta đã có các khái niệm về dân số, quốc gia và năm, đã đến lúc để kết hợp chúng lại với nhau!
Do đó, chúng ta cần tạo một lát cắt kết hợp các trình duyệt này. Trong DSPL, lát cắt là tổ hợp các khái niệm về dữ liệu tồn tại.
Tại sao không chỉ tạo bảng với các cột phù hợp? Vì các lát cắt (slice) thông tin của tập dữ liệu về khái niệm của tập dữ liệu đó. Điều này sẽ trở thành rõ ràng hơn khi chúng tôi tạo thêm nhiều phần khác trong tập dữ liệu.
Lát cắt xuất hiện trong tệp DSPL trong <slices>
phải xuất hiện ngay sau phần concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Cũng giống như các khái niệm, mỗi lát cắt có một id
(countries_slice) xác định duy nhất lát cắt trong phần
tập dữ liệu.
Lát cắt chứa hai loại nội dung tham chiếu khái niệm: Phương diện và
chỉ số. Giá trị của các chỉ số thay đổi theo giá trị của
thứ nguyên. Ở đây, giá trị của population (chỉ số) thay đổi theo
các phương diện country và year.
Tương tự như các khái niệm, Lát cắt bao gồm tệp tham chiếu đến bảng chứa dữ liệu của lát cắt. Bảng được tham chiếu phải có một cột cho từng phương diện và chỉ số của phần này. Cũng như đối với các khái niệm, lát cắt các phương diện và chỉ số được liên kết với các cột của bảng có cùng mã nhận dạng.
Bảng lát cắt
Bảng dành cho lát cắt dân số của chúng ta xuất hiện trong tables
của tệp DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Xin lưu ý rằng cột year đi kèm với format
chỉ định cách định dạng năm. Sau đây là các định dạng ngày được hỗ trợ:
các mã được xác định bằng định dạng ngày giờ Joda.
Bảng countries_slice chỉ định các cột của bảng và
loại của chúng và trỏ đến tệp CSV chứa dữ liệu. Tệp CSV
sẽ có dạng như sau:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Mỗi hàng của bảng dữ liệu chứa một tổ hợp phương diện duy nhất
country và year, cùng với giá trị tương ứng
của chỉ số population (ví dụ: dân số –
metric – của Afghanistan vào năm 1960 – thứ nguyên).
Xin lưu ý rằng các giá trị trong cột country khớp với
giá trị/mã nhận dạng của khái niệm country, là tiêu chuẩn ISO 3166
Mã gồm 2 chữ cái của quốc gia đó.
Dữ liệu CSV cho một lát cắt phải đáp ứng các điều kiện ràng buộc sau:
- Mỗi giá trị của một trường phương diện (chẳng hạn như
countryvàyear) không được để trống. Giá trị cho các trường chỉ số (chẳng hạn nhưpopulation) có thể trống. Giá trị trống được biểu thị bằng không ký tự. - Mỗi giá trị của trường phương diện tham chiếu đến một khái niệm phải
hiện diện trong dữ liệu của khái niệm đó. Ví dụ: giá trị
AFphải có trong bảng dữ liệu khái niệmcountry. - Từng tổ hợp riêng biệt của các giá trị phương diện (ví dụ:
AF, 2000, có thể chỉ xảy ra một lần. - Dữ liệu phải được sắp xếp theo các cột phương diện không theo thời gian (theo bất kỳ thứ tự nào),
và sau đó tuỳ ý thực hiện bởi bất kỳ cột nào khác. Ví dụ:
trong bảng có các cột
[date, dimension1, dimension2, metric1, metric2], bạn có thể sắp xếp theodimension1, sau đó làdimension2, sau đó làdate, nhưng không phải bởidaterồi đến phương diện.
Tóm tắt
Đến thời điểm này, chúng tôi đã có đủ thông tin trong DSPL để mô tả quốc gia dữ liệu dân số. Tóm lại, những việc chúng tôi phải làm là:
- Tạo tiêu đề DSPL và nội dung mô tả về tập dữ liệu và tập dữ liệu đó đám mây
- Tạo một khái niệm về dân số và một khái niệm khác cho quốc gia, với một csv liệt kê tất cả các quốc gia và tên của các quốc gia đó.
- Tạo một lát cắt về số liệu dân số của chúng tôi cho các quốc gia theo thời gian, tham chiếu đến khái niệm năm đã được xác định trong tập dữ liệu thời gian đã nhập từ Google.
Trong phần còn lại của hướng dẫn này, chúng tôi sẽ làm cho tập dữ liệu trở nên phong phú hơn bằng cách thêm nhiều phương diện hơn trong nhiều phần hơn, cũng như nhiều chỉ số hơn được nhóm theo chủ đề.
Thêm phương diện: Các tiểu bang của Hoa Kỳ
Bây giờ, hãy làm phong phú tập dữ liệu của chúng ta bằng cách thêm dữ liệu dân số cho các tiểu bang ở Hoa Kỳ. Trước tiên, chúng ta cần định nghĩa khái niệm về trạng thái. Kiểu này trông rất giống giống như khái niệm quốc gia mà chúng ta đã xác định trước đó.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Phần mở rộng về khái niệm và thuộc tính tham khảo
Khái niệm trạng thái giới thiệu một số tính năng mới của DSPL.
Đầu tiên, trạng thái mở rộng một khái niệm khác,
geo:location (được xác định trong tập dữ liệu địa lý bên ngoài, chúng tôi
được nhập vào đầu tập dữ liệu). Về mặt ngữ nghĩa, điều này có nghĩa là
state là một loại geo:location. Hệ quả là
nó kế thừa tất cả các thuộc tính và thuộc tính của
geo:location. Cụ thể, vị trí xác định các thuộc tính cho
latitude và longitude; bằng cách mở rộng
các thuộc tính này cũng được áp dụng cho trạng thái. Hơn nữa, vì
vị trí kế thừa từ entity:entity, trạng thái cũng nhận được
tất cả sản phẩm sau, bao gồm name,
description và info_url.
Lưu ý: Khái niệm quốc gia được xác định trước đây
về mặt kỹ thuật cũng phải được mở rộng từ geo:location.
Điểm này đã được bỏ qua trước đây để đơn giản hoá; chúng tôi đã đưa vào
Tuy nhiên, trong
tệp XML cuối cùng.
Lưu ý: Bạn có thể sử dụng extends
xây dựng trong tập dữ liệu của riêng bạn để sử dụng lại thông tin được xác định bởi các tập dữ liệu khác.
Để sử dụng extends, tất cả các thực thể của khái niệm phải
các trường hợp hợp lệ của khái niệm mà bạn đang mở rộng. Tiện ích cho phép bạn thêm
các thuộc tính và thuộc tính bổ sung, đồng thời hạn chế tập hợp các thực thể ở
là tập hợp con của các thực thể của khái niệm mở rộng.
Ngoài tính kế thừa, thuộc tính trạng thái cũng đưa ra
ý tưởng về tài liệu tham khảo của khái niệm.
Cụ thể, khái niệm trạng thái có một thuộc tính tên là country,
đề cập đến khái niệm quốc gia mà chúng tôi đã tạo ở trên. Việc này được thực hiện bằng
bằng thuộc tính concept. Xin lưu ý rằng tài sản này không
cung cấp mã nhận dạng, chỉ một thông tin tham chiếu khái niệm. Điều này tương đương với việc tạo id
có cùng giá trị với mã nhận dạng của khái niệm được tham chiếu (ví dụ:
country trong ví dụ này). Mối quan hệ phân cấp giữa
tiểu bang và hạt được thu thập bằng cách dùng thuộc tính
isParent="true" về tham chiếu. Nhìn chung,
các thứ nguyên có mối quan hệ phân cấp (chẳng hạn như vị trí địa lý)
được thể hiện theo cách này, với khái niệm con có một thuộc tính
tham chiếu đến khái niệm gốc bằng thuộc tính isParent.
Định nghĩa trong bảng cho các trạng thái có dạng như sau:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
Cột quốc gia có giá trị không đổi đối với tất cả các tiểu bang. Chỉ định thuộc tính này trong
DSPL tránh lặp lại giá trị đó cho mọi trạng thái trong dữ liệu. Ngoài ra, hãy lưu ý
mà chúng tôi đã bao gồm các cột cho name, latitude và
longitude vì trạng thái đã kế thừa các thuộc tính này từ
geo:location. Mặt khác, một số thuộc tính kế thừa
(ví dụ: description) không có cột; không sao-
nếu một thuộc tính bị loại khỏi bảng định nghĩa khái niệm, thì giá trị của thuộc tính đó là
được giả định là không xác định cho mọi thực thể của khái niệm.
Tệp CSV có dạng như sau:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Do đã có các khái niệm về dân số và năm, nên chúng ta có thể sử dụng lại các khái niệm đó để xác định một lát cắt mới cho tập hợp trạng thái.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>Định nghĩa bảng dữ liệu sẽ có dạng như sau:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Và tệp CSV có dạng như sau:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Chờ đã, tại sao chúng ta lại tạo một lát cắt mới, thay vì thêm một lát cắt khác so với kích thước trước đó không?
Một lát cắt có kích thước cho cả tiểu bang và quốc gia sẽ không chính xác, vì một số hàng sẽ dành cho dữ liệu quốc gia và một số hàng sẽ dành cho tiểu bang . Bảng sẽ có "lỗ" cho một số phương diện, tức là không được phép (lưu ý rằng chỉ cho phép thiếu giá trị đối với các chỉ số và không phải phương diện).
Phương diện đóng vai trò là "khoá chính" cho lát cắt. Điều này có nghĩa là mỗi hàng dữ liệu phải có giá trị cho tất cả các phương diện và không được có hai hàng dữ liệu có thể có cùng giá trị cho tất cả các phương diện.
Thêm chỉ số: Thất nghiệp Mức phí
Bây giờ, hãy thêm một chỉ số khác vào tập dữ liệu:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
Mục info của chỉ số này có tên, nội dung mô tả và
URL (liên kết đến Cục Thống kê Lao động Hoa Kỳ).
Khái niệm này cũng mở rộng khái niệm chính tắc quantity:rate.
Số lượng
tập dữ liệu xác định các khái niệm chính để biểu thị số lượng. Trong
tập dữ liệu của mình, bạn nên tạo các khái niệm dạng số bằng cách mở rộng
khái niệm số lượng thích hợp. Do đó, khái niệm population
được xác định ở trên, về mặt kỹ thuật, phải được mở rộng từ
quantity:amount
Thuộc tính khái niệm
Khái niệm này cũng giới thiệu về cấu trúc của thuộc tính. Trong
ví dụ này, một thuộc tính được dùng để cho biết rằng unemployment_rate
là tỷ lệ phần trăm. Thuộc tính is_percentage được kế thừa từ
khái niệm quantity:rate mà khái niệm này mở rộng. Chiến dịch này
được Public Data Explorer sử dụng để hiển thị ký hiệu phần trăm khi
trực quan hoá dữ liệu.
Các thuộc tính cung cấp một cơ chế chung để đính kèm các cặp khoá/giá trị vào
khái niệm (trái ngược với thuộc tính liên kết các giá trị bổ sung với
thực thể của một khái niệm). Cũng giống như khái niệm và thuộc tính,
có id, info và
type. Giống như thuộc tính, lớp này có thể tham chiếu đến các khái niệm khác.
Thuộc tính không chỉ dành cho những nội dung chung được xác định trước, chẳng hạn như số các thuộc tính. Bạn có thể xác định các thuộc tính cho các khái niệm của riêng mình.
Thêm dữ liệu tỷ lệ thất nghiệp cho Hoa Kỳ Các trạng thái
Hiện tại, chúng tôi đã sẵn sàng thêm dữ liệu về tỷ lệ thất nghiệp cho các tiểu bang tại Hoa Kỳ. Bởi vì tỷ lệ thất nghiệp là một chỉ số và chúng tôi đã có dữ liệu dân số cho các tiểu bang, chúng ta có thể thêm thông tin đó vào phần chúng ta đã tạo cho tiểu bang và năm phương diện:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... và thêm một cột khác vào định nghĩa bảng:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... và về tệp CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Trước đó, chúng tôi đã đề cập rằng đối với mỗi lát cắt, các thứ nguyên tạo thành một khoá chính cho lát cắt. Ngoài ra, mỗi tập dữ liệu chỉ có thể chứa một lát cho tổ hợp phương diện đã cho. Tất cả chỉ số có sẵn cho những quảng cáo này thứ nguyên phải thuộc cùng phần đó.
Các phương diện khác: Bảng chi tiết về dân số theo giới tính
Hãy làm phong phú tập dữ liệu của chúng tôi bằng bảng phân tích dân số theo giới tính cho quốc gia. Đến nay, bạn đã bắt đầu biết được diễn biến... Trước tiên, chúng ta cần thêm khái niệm về giới tính:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
Phần khái niệm giới tính info có một
pluralName, cung cấp văn bản được dùng để tham chiếu đến
nhiều trường hợp của khái niệm giới. Phần info cũng
bao gồm totalName, cung cấp văn bản sẽ được dùng để
đề cập đến tất cả các trường hợp của khái niệm giới nói chung. Cả hai đều là
được sử dụng bởi Public Data Explorer để hiển thị thông tin có liên quan đến giới tính
khái niệm. Nói chung, bạn nên cung cấp chúng cho các khái niệm có thể được sử dụng dưới dạng
thứ nguyên.
Lưu ý rằng khái niệm giới tính cũng được mở rộng từ
entity:entity. Đây là một phương pháp hay cho khái niệm
được dùng làm phương diện, vì nó cho phép bạn thêm tên tuỳ chỉnh,
URL và màu sắc cho các trường hợp khái niệm khác nhau.
Khái niệm giới tính đề cập đến bảng genders_table,
chứa các giá trị có thể có cho giới tính và tên hiển thị của chúng
(bị bỏ qua tại đây).
Để thêm dân số theo giới tính vào tập dữ liệu, chúng ta cần tạo một lát cắt mới (nhớ: mỗi tổ hợp kích thước có sẵn tương ứng với một phần tập dữ liệu).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
Định nghĩa trong bảng cho lát cắt sẽ có dạng như sau:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
Tệp CSV cho bảng có dạng như sau:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
So với các quốc gia, diện tích dân số và tỷ lệ thất nghiệp trước đây, tệp này có phương diện bổ sung; từng giá trị của chỉ số tổng thể không chỉ tương ứng với một quốc gia và năm cụ thể, mà còn tương ứng với một giới tính cụ thể.
Lưu ý rằng chúng ta đã tạo một quy tắc "thưa thớt" tập dữ liệu. Không phải tất cả Chỉ số có sẵn cho tất cả các phương diện: tổng số là có sẵn cho các quốc gia và tiểu bang của Hoa Kỳ, hằng năm, trong khi tỷ lệ thất nghiệp chỉ áp dụng cho quốc gia. Có bảng chi tiết theo giới tính chỉ áp dụng cho dân số theo quốc gia; không có thông tin về tỷ lệ thất nghiệp chứ không phải cho thứ nguyên trạng thái. Độ trễ cũng có thể tồn tại trong dữ liệu với một số chỉ số nhất định không có giá trị cho các giá trị thứ nguyên nhất định, nhưng không được thể hiện trong DSPL.
Chủ đề
Tính năng cuối cùng của DSPL mà chúng ta sẽ sử dụng trong tập dữ liệu là chủ đề. Chủ đề được dùng để phân loại các khái niệm theo thứ bậc và được dùng bởi để giúp người dùng điều hướng đến dữ liệu của bạn.
Trong tệp DSPL, chủ đề xuất hiện ngay trước khái niệm. Sau đây là ví dụ hệ thống phân cấp chủ đề:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Bạn có thể lồng các chủ đề vào từng chủ đề một cách sâu sắc nếu cần.
Để sử dụng chủ đề, bạn chỉ cần tham chiếu chúng từ khái niệm định nghĩa, như sau:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Một khái niệm có thể đề cập đến nhiều chủ đề.
Gửi tập dữ liệu của bạn
Bây giờ bạn đã tạo tập dữ liệu của mình, bước tiếp theo là nén tập dữ liệu đó và tải tệp zip lên để công cụ Google Public Data Explorer. Nếu bạn gặp bất kỳ vấn đề nào, hãy kiểm tra Câu hỏi thường gặp, trong đó có nội dung thảo luận vấn đề tải lên thường gặp nhất.
Để tham khảo, bạn cũng có thể tải tệp XML hoàn chỉnh và gói tập dữ liệu hoàn chỉnh xuống được liên kết với hướng dẫn này.
Điểm nên tham quan từ đây
Chúc mừng bạn đã tạo tập dữ liệu DSPL đầu tiên! Giờ đây khi bạn hiểu kiến thức cơ bản, chúng tôi khuyên bạn nên đọc qua Hướng dẫn cho nhà phát triển. cùng nhiều yếu tố khác, tài liệu "nâng cao" Các tính năng DSPL như hỗ trợ đa ngôn ngữ và các khái niệm có thể ánh xạ.
Bạn cũng có thể xem thêm một số tập dữ liệu mẫu khác.