
Распределённая трассировка важна для получения аналитической информации и контроля за многоуровневой архитектурой микросервисов. При объединении вызовов между сервисами в цепочку, от сервиса A к сервису B и к сервису C, важно понимать, были ли вызовы успешными, а также задержку на каждом этапе.
В Spring Boot вы можете использовать Spring Cloud Sleuth для беспрепятственного добавления инструментария распределённой трассировки в ваше приложение. По умолчанию он может пересылать данные трассировки в Zipkin.
В Google Cloud Platform есть Stackdriver Trace — управляемый сервис, позволяющий хранить данные трассировки без необходимости управления собственным экземпляром Zipkin и хранилищем. Stackdriver Trace также может создавать отчёты о распределении задержек и автоматически выявлять снижение производительности.
У вас есть два варианта использования Stackdriver Trace из приложения Spring Boot:
- Используйте Stackdriver Trace Zipkin Proxy и просто настройте Spring Cloud Sleuth для использования этого прокси в качестве конечной точки Zipkin.
- Или используйте Spring Cloud GCP Trace, который легко интегрируется с Spring Cloud Sleuth и пересылает данные трассировки непосредственно в Stackdriver Trace.
В этой лабораторной работе вы узнаете, как создать новое приложение Spring Boot и использовать Spring Cloud GCP Trace для распределенной трассировки.
Чему вы научитесь
- Как создать приложение Spring Boot Java и настроить Stackdriver Trace.
Что вам понадобится
- Проект облачной платформы Google
- Браузер, например Chrome или Firefox
- Знакомство со стандартными текстовыми редакторами Linux, такими как Vim, EMAC или Nano
Как вы будете использовать это руководство?
Как бы вы оценили свой опыт создания веб-приложений HTML/CSS?
Как бы вы оценили свой опыт использования сервисов Google Cloud Platform?
Настройка среды для самостоятельного обучения
Если у вас ещё нет учётной записи Google (Gmail или Google Apps), необходимо её создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект:



Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud (имя, указанное выше, уже занято и не будет вам работать, извините!). Далее в этой практической работе он будет обозначаться как PROJECT_ID .
Далее вам необходимо включить биллинг в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этой лабораторной работы не должно обойтись вам дороже нескольких долларов, но может обойтись дороже, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «Очистка» в конце этого документа).
Новые пользователи Google Cloud Platform имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Google Cloud Shell
Хотя Google Cloud и Kubernetes можно использовать удаленно с вашего ноутбука, в этой лабораторной работе мы будем использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Активировать Google Cloud Shell
В консоли GCP щелкните значок Cloud Shell на верхней правой панели инструментов:

Затем нажмите «Запустить Cloud Shell»:

Подготовка и подключение к среде займет всего несколько минут:

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предлагает постоянный домашний каталог объёмом 5 ГБ и работает в облаке Google Cloud, что значительно повышает производительность сети и аутентификацию. Значительную часть работы в этой лаборатории, если не всю, можно выполнить, просто используя браузер или Chromebook от Google.
После подключения к Cloud Shell вы должны увидеть, что вы уже аутентифицированы и что проекту уже присвоен ваш PROJECT_ID .
Выполните следующую команду в Cloud Shell, чтобы подтвердить, что вы прошли аутентификацию:
gcloud auth list
Вывод команды
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить его с помощью этой команды:
gcloud config set project <PROJECT_ID>
Вывод команды
Updated property [core/project].
После запуска Cloud Shell вы можете использовать командную строку для создания нового приложения Spring Boot с помощью Spring Initializr:
$ curl https://start.spring.io/starter.tgz -d packaging=jar \
-d dependencies=web,lombok,cloud-gcp,cloud-starter-sleuth \
-d baseDir=trace-service-one | tar -xzvf - \
&& cd trace-service-oneСоздайте новый REST-контроллер, добавив новый класс:
src/main/java/com/example/demo/WorkController.java
package com.example.demo;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Random;
@RestController
@Slf4j
public class WorkController {
Random r = new Random();
public void meeting() {
try {
log.info("meeting...");
// Delay for random number of milliseconds.
Thread.sleep(r.nextInt(500));
} catch (InterruptedException e) {
}
}
@GetMapping("/")
public String work() {
// What is work? Meetings!
// When you hit this URL, it'll call meetings() 5 times.
// Each time will have a random delay.
log.info("starting to work");
for (int i = 0; i < 5; i++) {
this.meeting();
}
log.info("finished!");
return "finished work!";
}
}Вы можете запустить приложение Spring Boot обычным способом с помощью плагина Spring Boot. Давайте пропустим тесты для этой лабораторной работы:
$ ./mvnw -DskipTests spring-boot:run После запуска приложения нажмите на значок «Веб-просмотр».  на панели инструментов Cloud Shell выберите предварительный просмотр на порту 8080 .
на панели инструментов Cloud Shell выберите предварительный просмотр на порту 8080 .
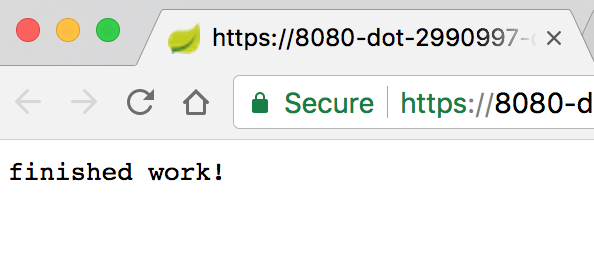
После непродолжительного ожидания вы должны увидеть результат:
В Cloud Shell вы также должны увидеть сообщения журнала с идентификатором трассировки и идентификатором диапазона:

Включить API трассировки Stackdriver
Чтобы использовать Stackdriver Trace для хранения данных трассировки, сначала необходимо включить API Stackdriver Trace. Чтобы включить API, перейдите в раздел «Службы API» → «Библиотека».

Поиск Stackdriver Trace
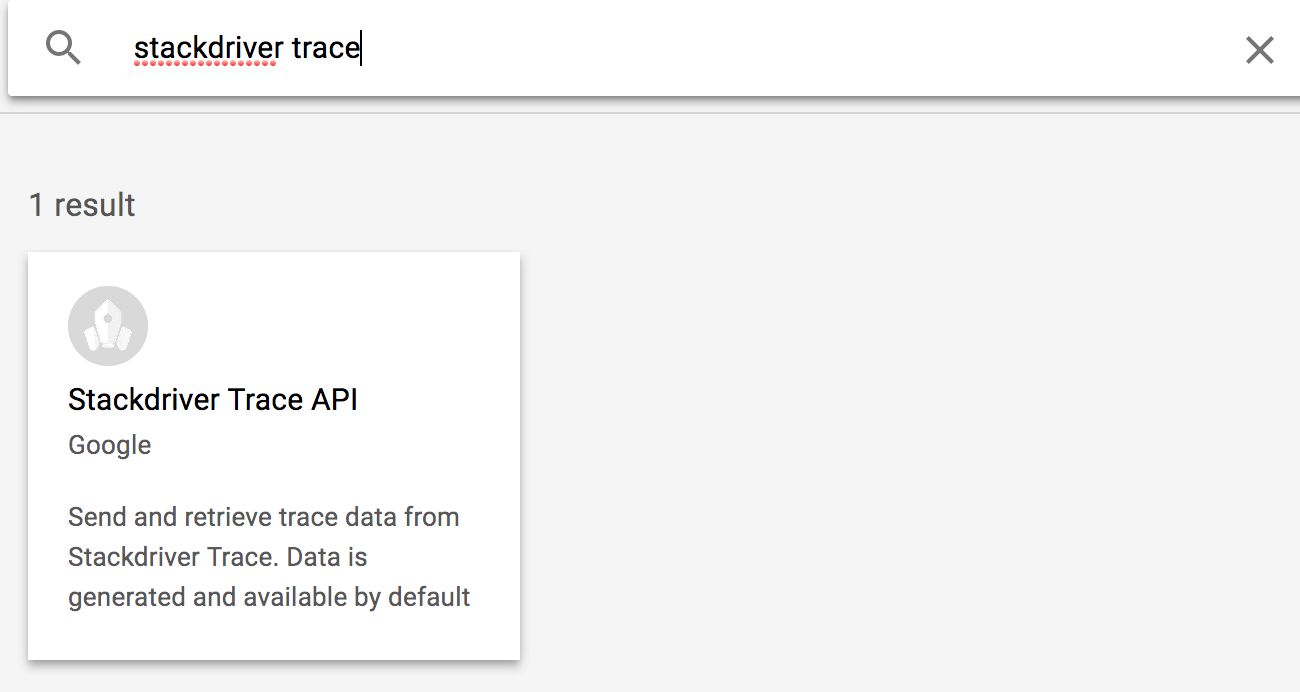
Нажмите Stackdriver Trace API , затем нажмите Включить, если он еще не включен.
Настройка учетных данных приложения по умолчанию
Для этой лабораторной работы вам потребуется настроить учётные данные приложения по умолчанию. Эти данные будут автоматически выбраны стартером Spring Cloud GCP Trace.
Сначала войдите в систему:
$ gcloud auth application-default login
You are running on a Google Compute Engine virtual machine.
The service credentials associated with this virtual machine
will automatically be used by Application Default
Credentials, so it is not necessary to use this command.
If you decide to proceed anyway, your user credentials may be visible
to others with access to this virtual machine. Are you sure you want
to authenticate with your personal account?
Do you want to continue (Y/n)? Y
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth...
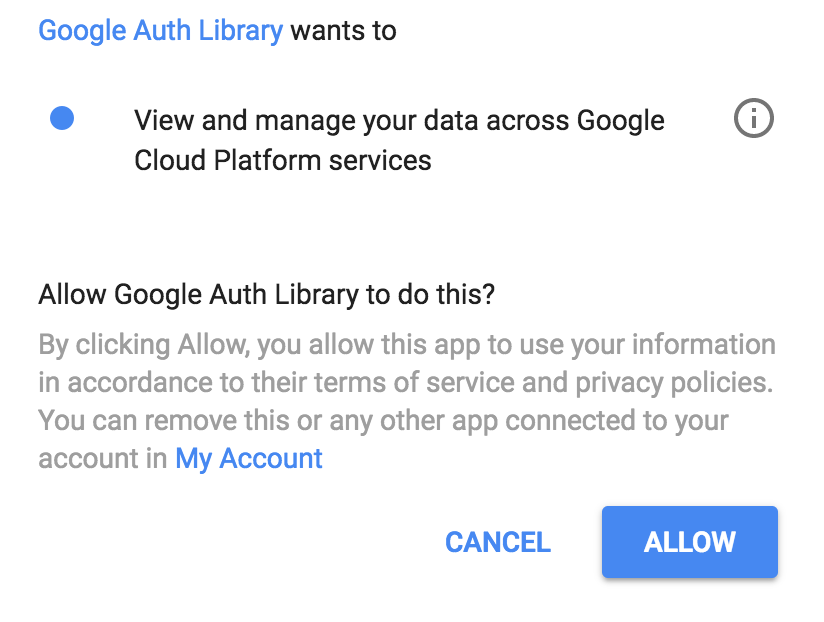
Enter verification code: ...Нажмите на ссылку, чтобы открыть новую вкладку браузера, а затем нажмите « Разрешить».
Затем скопируйте и вставьте проверочный код обратно в Cloud Shell и нажмите Enter. Вы должны увидеть:
Credentials saved to file: [/tmp/tmp.jm9bnQ4R9Q/application_default_credentials.json]
These credentials will be used by any library that requests
Application Default Credentials.Добавить трассировку Spring Cloud GCP
В этом сервисе мы уже использовали Spring Cloud Sleuth для трассировки. Добавим стартовый компонент Spring Cloud GCP Trace для пересылки данных в Stackdriver Trace.
Добавьте зависимость Spring Cloud GCP Trace:
pom.xml
<project>
...
<dependencies>
...
<!-- Add Stackdriver Trace Starter -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-gcp-starter-trace</artifactId>
</dependency>
</dependencies>
...
</project>По умолчанию Spring Cloud Sleuth не производит выборку каждого запроса. Чтобы немного упростить тестирование, увеличьте частоту выборки до 100% в application.properties , чтобы убедиться в наличии данных трассировки, а также проигнорируйте некоторые URL-адреса, которые нам не нужны:
$ echo "
spring.sleuth.sampler.probability=1.0
spring.sleuth.web.skipPattern=(^cleanup.*|.+favicon.*)
" > src/main/resources/application.propertiesЗапустите приложение еще раз и используйте Cloud Shell Web Preview для просмотра приложения:
$ export GOOGLE_CLOUD_PROJECT=`gcloud config list --format 'value(core.project)'`
$ ./mvnw -DskipTests spring-boot:runПо умолчанию Spring Cloud GCP Trace собирает данные трассировки в пакеты и отправляет их каждые 10 секунд или при получении минимального количества данных трассировки. Это можно настроить. Дополнительную информацию можно найти в справочной документации Spring Cloud GCP Trace .
Подать заявку на услугу:
$ curl localhost:8080В Cloud Console перейдите в Stackdriver → Trace → Trace list.
Вверху сузьте временной диапазон до 1 часа. По умолчанию автоматическая перезагрузка включена. Таким образом, по мере поступления данных трассировки они должны отображаться в консоли!

Данные трассировки должны появиться примерно через 30 секунд.
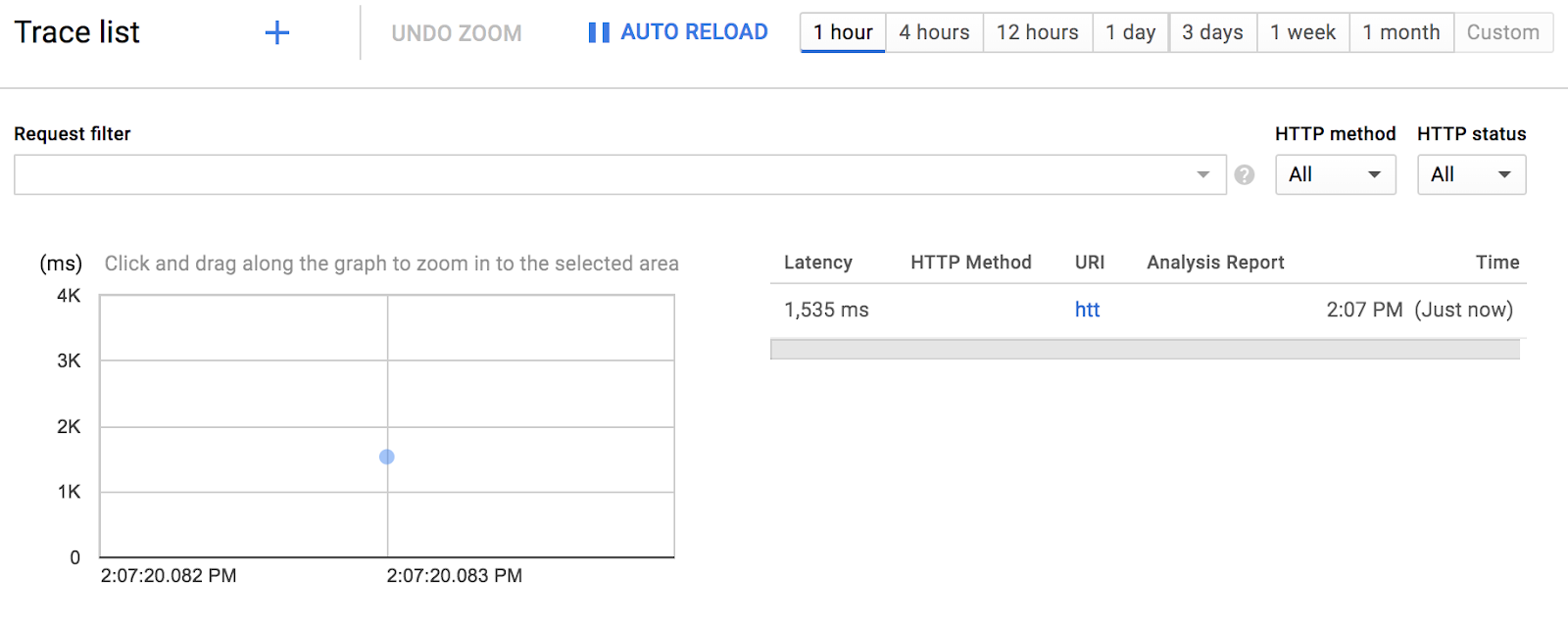
Нажмите на синюю точку, чтобы увидеть детали трассировки:
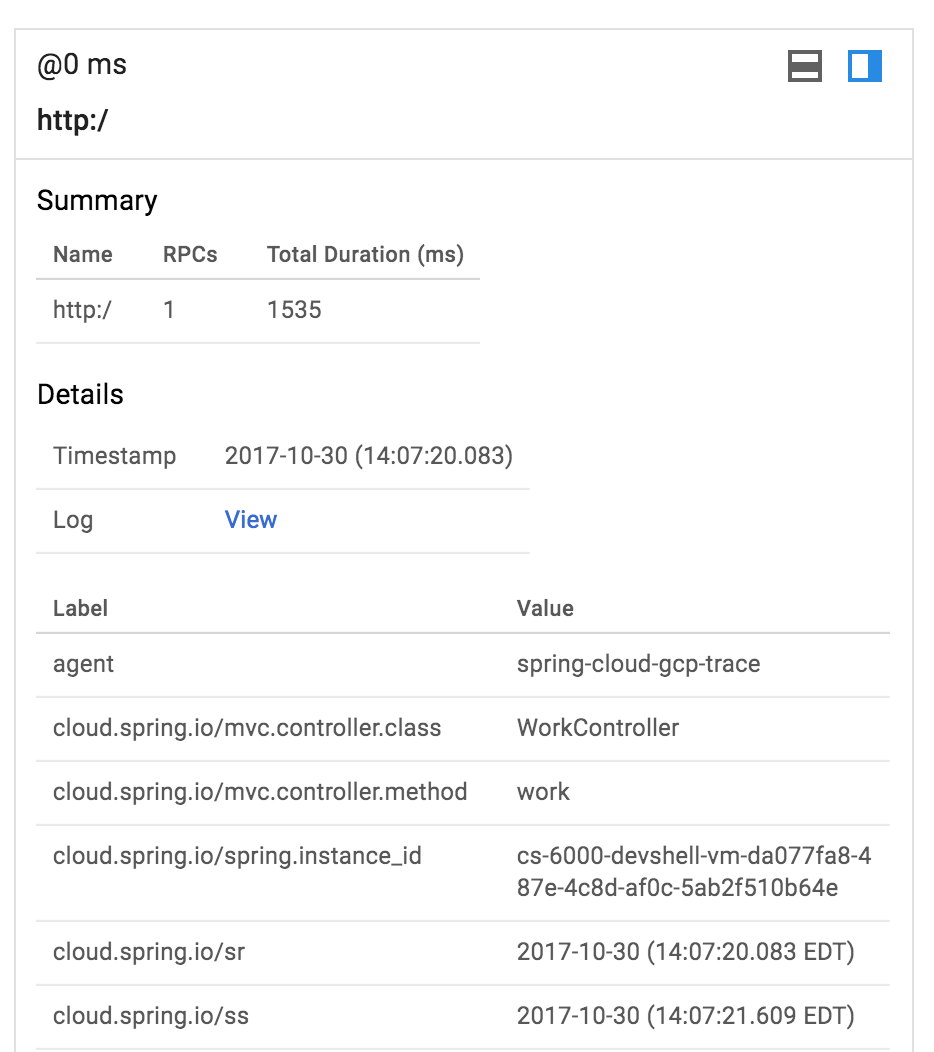
Это было довольно просто!
Откройте новый сеанс Cloud Shell, нажав на значок + :
В новом сеансе создайте второе приложение Spring Boot:
$ curl https://start.spring.io/starter.tgz -d packaging=jar \
-d dependencies=web,lombok,cloud-gcp,cloud-starter-sleuth \
-d baseDir=trace-service-two | tar -xzvf - \
&& cd trace-service-twoСоздайте новый REST-контроллер, добавив новый класс:
src/main/java/com/example/demo/MeetingController.java
package com.example.demo;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Random;
@RestController
@Slf4j
public class MeetingController {
Random r = new Random();
@GetMapping("/meet")
public String meeting() {
try {
log.info("meeting...");
Thread.sleep(r.nextInt(500 - 20 + 1) + 20);
} catch (InterruptedException e) {
}
return "finished meeting";
}
}Добавить трассировку Spring Cloud GCP в pom.xml
pom.xml
<project>
...
<dependencies>
...
<!-- Add Stackdriver Trace starter -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-gcp-starter-trace</artifactId>
</dependency>
</dependencies>
...
</project>Настройте Sleuth для выборки 100% запросов:
src/main/resources/application.properties
$ echo "
spring.sleuth.sampler.probability=1.0
spring.sleuth.web.skipPattern=(^cleanup.*|.+favicon.*)
" > src/main/resources/application.propertiesНаконец, вы можете запустить приложение Spring Boot на порту 8081 с помощью плагина Spring Boot:
$ export GOOGLE_CLOUD_PROJECT=`gcloud config list --format 'value(core.project)'`
$ ./mvnw -DskipTests spring-boot:run -Dserver.port=8081 При запущенном trace-service-two вернитесь в первое окно сеанса Cloud Shell и внесите изменения в trace-service-one .
Сначала инициализируем новый компонент RestTemplate :
src/main/java/com/example/demo/DemoApplication.java
package com.example.demo;
...
import org.springframework.web.client.RestTemplate;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class DemoApplication {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}В WorkController.meeting() выполните вызов службы Meeting.
src/main/java/com/example/demo/WorkController.java
package com.example.demo;
...
import org.springframework.web.client.RestTemplate;
import org.springframework.beans.factory.annotation.Autowired;
@RestController
@Slf4j
public class WorkController {
@Autowired
RestTemplate restTemplate;
public void meeting() {
String result = restTemplate.getForObject("http://localhost:8081/meet", String.class);
log.info(result);
}
...
}Запустите службу еще раз и активируйте конечную точку из веб-предварительного просмотра:
$ export GOOGLE_CLOUD_PROJECT=`gcloud config list --format 'value(core.project)'`
$ ./mvnw -DskipTests spring-boot:runВ обоих окнах сеанса вы должны увидеть сообщения журнала с идентификатором трассировки, переданным от одной службы к другой.
В списке трассировок Stackdriver Trace вы должны увидеть вторую трассировку:
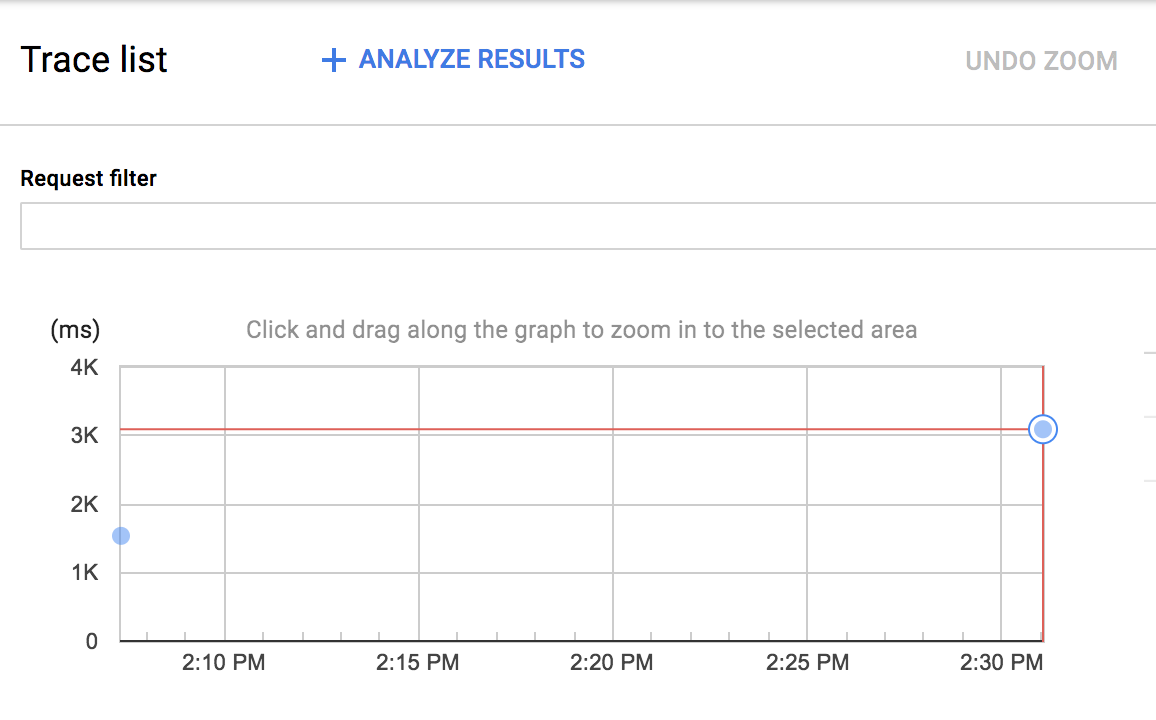
Вы можете нажать на новую синюю точку и увидеть детали трассировки:
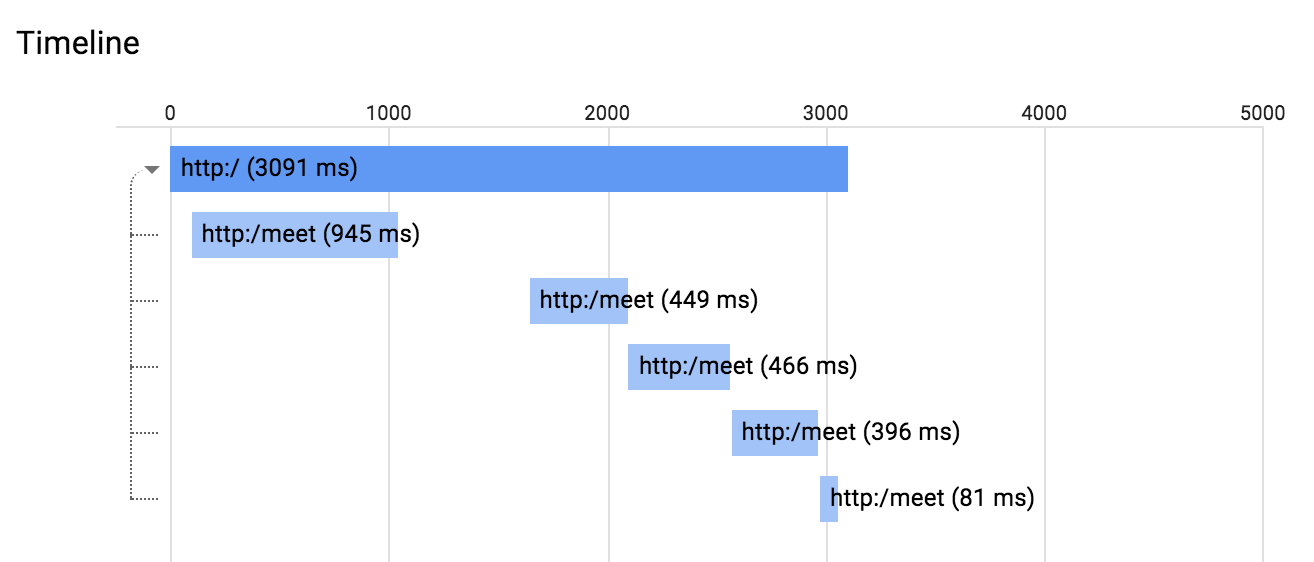
Вы также можете нажать на любой промежуток на этой диаграмме, чтобы увидеть подробную информацию о нем.
При использовании Stackdriver Trace в качестве хранилища данных трассировки, Stackdriver Trace может использовать эти данные для построения отчёта о распределении задержки. Для построения такого отчёта потребуется более 100 трассировок:

Кроме того, Stackdriver Trace может автоматически обнаруживать снижение производительности одной и той же службы за два разных периода времени в отчете об анализе .
В этой лабораторной работе вы создали 2 простых сервиса и добавили распределенную трассировку с помощью Spring Cloud Sleuth, а также использовали Spring Cloud GCP для пересылки информации трассировки в Stackdriver Trace.
Вы узнали, как написать свое первое веб-приложение App Engine!
Узнать больше
- Трассировка Stackdriver: https://cloud.google.com/trace/
- Проект Spring на GCP: http://cloud.spring.io/spring-cloud-gcp/
- Репозиторий Spring на GCP GitHub: https://github.com/spring-cloud/spring-cloud-gcp
- Java на облачной платформе Google: https://cloud.google.com/java/
Лицензия
Данная работа распространяется по лицензии Creative Commons Attribution 2.0 Generic License.