यह पेज, Custom Search JSON API (एपीआई) के एक्सएमएल वर्शन के बारे में बताता है, जो सिर्फ़ Google साइट खोज ग्राहक.
- खास जानकारी
- Programmable Search Engine के अनुरोध का फ़ॉर्मैट
- एक्सएमएल के नतीजे
खास जानकारी
Google WebSearch सेवा की मदद से, Google Site Search को चालू किया जा सकता है ग्राहकों को अपनी वेब साइटों पर Google खोज परिणाम दिखाने के लिए करते हैं. कॉन्टेंट बनाने खोज सेवा दिखाने के लिए WebSearch सेवा, एक सामान्य एचटीटीपी-आधारित प्रोटोकॉल का इस्तेमाल करती है नतीजे. सर्च एडमिन के पास यह कंट्रोल होता है कि वे खोज परिणामों का अनुरोध करते हैं और यह अनुरोध करते हैं कि वे असली उपयोगकर्ता. इस दस्तावेज़ में Google के तकनीकी पहलुओं की जानकारी दी गई है खोज अनुरोध और परिणामों के प्रारूप में होता है.
Google WebSearch के नतीजे वापस पाने के लिए, आपका ऐप्लिकेशन Google एक सामान्य एचटीटीपी अनुरोध. इसके बाद Google, एक्सएमएल में खोज के नतीजे दिखाता है फ़ॉर्मैट. एक्सएमएल फ़ॉर्मैट वाले नतीजों से अपनी पसंद के मुताबिक खोज के नतीजे कैसे दिखाए जाते हैं.
WebSearch अनुरोध का फ़ॉर्मैट
- अनुरोध करें खास जानकारी
- क्वेरी की शर्तें
- अनुरोध के पैरामीटर
- WebSearch क्वेरी के सैंपल
- WebSearch क्वेरी पैरामीटर की परिभाषाएं
- इमेज क्वेरी के सैंपल
- इमेज सर्च क्वेरी पैरामीटर की परिभाषाएं
- बेहतर खोज
- ऐडवांस खोज क्वेरी पैरामीटर
- क्वेरी में इस्तेमाल होने वाले खास शब्द
- अनुरोध करने की सीमाएं
अनुरोध अवलोकन
Google Search का अनुरोध, एक स्टैंडर्ड एचटीटीपी GET कमांड है. यह
में पैरामीटर का कलेक्शन शामिल होता है जो आपके
क्वेरी. ये पैरामीटर, अनुरोध यूआरएल में name=value के तौर पर शामिल होते हैं
एंपरसैंड (&) वर्णों से अलग किए गए जोड़े. पैरामीटर में ये शामिल हैं
डेटा, जैसे कि खोज क्वेरी और यूनीक इंजन आईडी (cx), जो आपकी
इंजन जो एचटीटीपी अनुरोध कर रहा है. WebSearch या Image Search सेवा वापस मिलती है
एक्सएमएल के आपके अनुरोधों के जवाब में एक्सएमएल भेजा जाता है.
खोज में इस्तेमाल होने वाले शब्द और नाम
ज़्यादातर खोज अनुरोधों में एक या ज़्यादा क्वेरी शब्द शामिल होते हैं. क्वेरी के लिए इस्तेमाल किया गया शब्द खोज अनुरोध में एक पैरामीटर के मान के रूप में दिखाई देता है.
क्वेरी में इस्तेमाल हुए शब्द, फ़िल्टर करने के लिए कई तरह की जानकारी दे सकते हैं और उन खोज परिणामों को व्यवस्थित करें जिन्हें Google दिखाता है. क्वेरी में यह जानकारी हो सकती है:
- ऐसे शब्द या वाक्यांश जिन्हें शामिल करना है या
छोड़ें
- खोज क्वेरी में सभी शब्द (डिफ़ॉल्ट)
- खोज क्वेरी का एक सटीक वाक्यांश
- खोज क्वेरी में कोई शब्द या वाक्यांश
- दस्तावेज़ में कहां 'एक्सप्लोर करें' मॉड्यूल में,
खोज के लिए शब्द
- दस्तावेज़ में कहीं भी (डिफ़ॉल्ट)
- सिर्फ़ दस्तावेज़ के मुख्य हिस्से में
- सिर्फ़ दस्तावेज़ के टाइटल में
- सिर्फ़ दस्तावेज़ के यूआरएल में
- सिर्फ़ दस्तावेज़ में मौजूद लिंक में
- दस्तावेज़ों पर लागू पाबंदियां
- किसी खास तरह के फ़ाइल टाइप के दस्तावेज़ शामिल करना या शामिल न करना (जैसे कि PDF फ़ाइलें या Word दस्तावेज़)
- यूआरएल की खास क्वेरी जो वापस दिखती हैं
खोज करने के बजाय, दिए गए यूआरएल के बारे में जानकारी देखना
- ऐसी क्वेरी जिनमें किसी यूआरएल के बारे में सामान्य जानकारी दी जाती है, जैसे कि इसकी ओपन डायरेक्ट्री कैटगरी, स्निपेट या भाषा
- ऐसी क्वेरी जो यूआरएल से लिंक करने वाले वेब पेजों के सेट को दिखाती हैं
- ऐसी क्वेरी जो दिए गए यूआरएल से मिलते-जुलते वेब पेजों का सेट दिखाती हैं
डिफ़ॉल्ट खोज
खोज क्वेरी पैरामीटर की वैल्यू, यूआरएल एस्केप होनी चाहिए. ध्यान दें कि किसी भी खाली सफ़ेद जगह के क्रम में, प्लस का निशान ("+") जोड़ देगा खोज क्वेरी. इसके बारे में ज़्यादा जानकारी, इस दस्तावेज़ के यूआरएल एस्केप करना सेक्शन में दी गई है.
खोज क्वेरी पद का उपयोग करके WebSearch सेवा को सबमिट किया जाता है q पैरामीटर. ऐप्लिकेशन सैंपल खोज क्वेरी शब्द है:
q=horses+cows+pigs
डिफ़ॉल्ट रूप से, Google WebSearch सेवा सिर्फ़ वही दस्तावेज़ वापस भेजती है जो सभी शब्दों को खोज क्वेरी में शामिल करना चाहिए.
अनुरोध के पैरामीटर
इस सेक्शन में उन पैरामीटर की सूची दी गई है जिनका इस्तेमाल करके, खोज अनुरोध. पैरामीटर दो सूचियों में बंटे होते हैं. पहली सूची में ऐसे पैरामीटर होते हैं जो सभी खोज अनुरोधों के लिए काम के होते हैं. दूसरी सूची में ऐसे पैरामीटर हैं जो हैं यह सिर्फ़ ऐडवांस खोज के अनुरोधों के लिए सही है.
तीन अनुरोध पैरामीटर ज़रूरी हैं:
- client पैरामीटर को
google-csbeपर सेट किया जाना चाहिए - आउटपुट पैरामीटर
दिखाए गए एक्सएमएल नतीजों का फ़ॉर्मैट; (xml) के साथ नतीजे दिखाए जा सकते हैं
या इसके बिना (
xml_no_dtd) Google के DTD का कोई रेफ़रंस नहीं होना चाहिए. हमारा सुझाव है कि आप: इस वैल्यू कोxml_no_dtdपर सेट कर रहा है. ध्यान दें: अगर इस पैरामीटर की जानकारी नहीं दी जाती है, तो नतीजे एक्सएमएल के बजाय, एचटीएमएल में होना चाहिए.
- cx पैरामीटर, जो यूनीक वैल्यू को दिखाता है
इंजन का आईडी.
दूसरे पैरामीटर के अलावा, सबसे ज़्यादा इस्तेमाल किए जाने वाले अनुरोध पैरामीटर जिनका ज़िक्र ऊपर किया गया है:
- num—खोज नतीजों की अनुरोध की गई संख्या
- q—खोज के लिए इस्तेमाल हुए शब्द
- start—नतीजों के लिए शुरुआती इंडेक्स
WebSearch क्वेरी के सैंपल
नीचे दिए गए उदाहरण इससे पता चलता है कि अलग-अलग क्वेरी पैरामीटर का इस्तेमाल कैसे किया जाता है. परिभाषा WebSearch क्वेरी में अलग-अलग क्वेरी पैरामीटर उपलब्ध कराए जाते हैं पैरामीटर की परिभाषाएं और बेहतर खोज क्वेरी इस दस्तावेज़ के पैरामीटर सेक्शन.
इस अनुरोध में पहले 10 नतीजे दिखाने हैं (start=0&num=10)
क्वेरी शब्द "रेड सॉक्स" के लिए (q=red+sox). क्वेरी भी
यह बताता है कि नतीजे कनाडा की वेब साइटों (cr=countryCA) से आने चाहिए
और यह फ़्रेंच (lr=lang_fr) में होना चाहिए. आखिर में, क्वेरी
क्लाइंट, आउटपुट के लिए वैल्यू तय करता है,
और cx पैरामीटर, तीनों ज़रूरी हैं.
http://www.google.com/search?
start=0
&num=10
&q=red+sox
&cr=countryCA
&lr=lang_fr
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
इस उदाहरण में कुछ ऐडवांस खोज क्वेरी का इस्तेमाल किया गया है
पैरामीटर का इस्तेमाल करें. यह अनुरोध, as_q का इस्तेमाल करता है
q पैरामीटर के बजाय पैरामीटर (as_q=red+sox) है. यह टूल,
as_eq पैरामीटर की मदद से, ऐसे किसी भी दस्तावेज़ को शामिल नहीं किया जाता है जिसमें "Yankees" शब्द हो से
खोज के नतीजे (as_eq=yankees).
http://www.google.com/search?
start=0
&num=10
&as_q=red+sox
&as_eq=Yankees
&client=google-csbe
&output=xml_no_dtd
&cx=00255077836266642015:u-scht7a-8i
WebSearch क्वेरी पैरामीटर की परिभाषाएं
| c2coff | |||||||
|---|---|---|---|---|---|---|---|
| जानकारी | Optional. c2coff पैरामीटर, सरल और ट्रेडिशनल चाइनीज़ सर्च सुविधा. इस पैरामीटर के लिए डिफ़ॉल्ट वैल्यू
|
||||||
| उदाहरण | q=google&c2coff=1 |
||||||
| क्लाइंट | |
|---|---|
| जानकारी | ज़रूरी है. |
| उदाहरण | q=google&client=google-csbe |
| cr | |
|---|---|
| जानकारी | Optional. Google Web Search, दस्तावेज़ का देश तय करता है विश्लेषण कर रहा है:
देश (cr) पैरामीटर देखें इस पैरामीटर के लिए मान्य वैल्यू की सूची में, वैल्यू सेक्शन का इस्तेमाल करें. |
| उदाहरण | q=Frodo&cr=countryNZ |
| सीएक्स | |
|---|---|
| जानकारी | ज़रूरी है. |
| उदाहरण | q=Frodo&cx=00255077836266642015:u-scht7a-8i |
| फ़िल्टर करें | |||||||
|---|---|---|---|---|---|---|---|
| जानकारी | Optional. filter पैरामीटर चालू होता है या Google खोज नतीजों के अपने-आप फ़िल्टर होने की सुविधा को बंद करता है. इसका अपने-आप फ़िल्टर होना सेक्शन देखें दस्तावेज़ देखें.
ध्यान दें: डिफ़ॉल्ट रूप से, Google सभी फ़िल्टर के लिए फ़िल्टर लागू करता है खोज नतीजे सबमिट करें. |
||||||
| उदाहरण | q=google&filter=0 |
||||||
| gl | |
|---|---|
| जानकारी | Optional. WebSearch के अनुरोधों में |
| उदाहरण | यह अनुरोध यूनाइटेड किंगडम में लिखे गए उन दस्तावेज़ों को बूस्ट करता है जो
WebSearch के नतीजे: |
| hl | |
|---|---|
| जानकारी | Optional. अंतरराष्ट्रीय क् वेरी के लिए इंटरफ़ेस की भाषाएं सेक्शन देखें और परिणाम प्रस्तुतिकरण ज़्यादा जानकारी के लिए और इस्तेमाल किए जा सकने वाले इंटरफ़ेस की भाषाएं देखें. |
| उदाहरण | यह अनुरोध फ़्रेंच भाषा में वाइन के विज्ञापनों को लक्षित करता है. (विन यह है वाइन के लिए फ़्रेंच शब्द.) q=vin&ip=10.10.10.10&ad=w5&hl=fr |
| क्वालिटी | |
|---|---|
| जानकारी | Optional. |
| उदाहरण | यह अनुरोध 'पिज़्ज़ा' खोजता है और 'चीज़'. एक्सप्रेशन
|
| ie | |
|---|---|
| जानकारी | Optional. वर्णों को कोड में बदलने का तरीका सेक्शन देखें और जानें कि आपको इस पैरामीटर का इस्तेमाल कब करना होगा. वर्ण एन्कोडिंग देखें
संभावित |
| उदाहरण | q=google&ie=utf8&oe=utf8 |
| lr | |
|---|---|
| जानकारी | Optional. Google Web Search, दस्तावेज़ की भाषा इसके आधार पर तय करता है विश्लेषण कर रहा है:
भाषा ( |
| उदाहरण | q=Frodo&lr=lang_en |
| संख्या | |
|---|---|
| जानकारी | Optional.
ध्यान दें: अगर खोज के नतीजों की कुल संख्या कम है परिणामों की अनुरोधित संख्या से ज़्यादा, सभी उपलब्ध खोज परिणाम वापस नहीं किया जाएगा. |
| उदाहरण | q=google&num=10 |
| ओए | |
|---|---|
| जानकारी | Optional. वर्णों को कोड में बदलने का तरीका सेक्शन देखें और जानें कि आपको इस पैरामीटर का इस्तेमाल कब करना होगा. वर्ण एन्कोडिंग देखें
संभावित |
| उदाहरण | q=google&ie=utf8&oe=utf8 |
| आउटपुट | |||||||
|---|---|---|---|---|---|---|---|
| जानकारी | ज़रूरी है.
|
||||||
| उदाहरण | output=xml_no_dtd |
||||||
| q | |
|---|---|
| जानकारी | Optional. ऐसे कई ख़ास क्वेरी पद भी हैं जिन्हें
Google Search कंट्रोल पैनल में, सबसे ऊपर मौजूद
ध्यान दें: q पैरामीटर के लिए तय की गई वैल्यू यूआरएल-एस्केप्ड होने चाहिए. |
| उदाहरण | q=vacation&as_oq=london+paris |
| सुरक्षित | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| जानकारी | Optional.
वयस्कों के लिए बने कॉन्टेंट को फ़िल्टर करना देखें इस सुविधा के बारे में ज़्यादा जानकारी के लिए, सेफ़ सर्च सेक्शन के साथ इसे चालू करें. |
||||||||
| उदाहरण | q=adult&safe=high |
||||||||
| शुरू करें | |
|---|---|
| जानकारी | Optional.
|
| उदाहरण | start=10 |
| क्रम से लगाएं | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
| यूडी | |
|---|---|
| जानकारी | Optional. http://www.花井鮨.com इस पैरामीटर के लिए मान्य वैल्यू अगर http://www.xn--elq438j.com. ध्यान दें: यह सुविधा बीटा वर्शन में है. |
| उदाहरण | q=google&ud=1 |
बेहतर खोज
इमेज के नीचे दिए गए अन्य क्वेरी पैरामीटर, बेहतर खोज क्वेरी के लिए काम के होते हैं. बेहतर खोज सबमिट करने पर, कई पैरामीटर की वैल्यू (उदाहरण के लिए, as_eq, as_epq, as_oq वगैरह) को क्वेरी में शामिल किया जाता है उस खोज के लिए शब्द. इस इमेज में, Google का ऐडवांस खोज वाला पेज दिखाया गया है. इमेज पर, हर एक का नाम बेहतर खोज पैरामीटर, उसके अंदर या उसके बगल में लाल टेक्स्ट में लिखा होता है उस पेज पर फ़ील्ड, जिससे वह पैरामीटर संबंधित है.
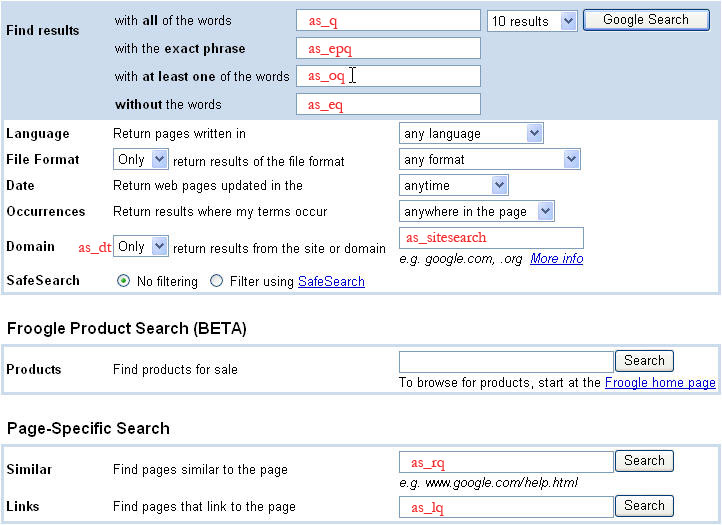
बेहतर खोज क्वेरी पैरामीटर
| as_dt | |
|---|---|
| जानकारी | Optional. |
| उदाहरण | as_dt=i,as_dt=e |
| as_epq | |
|---|---|
| जानकारी | Optional. |
| उदाहरण | as_epq=abraham+lincoln |
| as_eq | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
| as_lq | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
| as_nlo | |
|---|---|
| जानकारी | Optional. |
| उदाहरण | ये नतीजे, 5 से 10 की खोज की रेंज पर सेट करते हैं. इनमें ये भी शामिल हैं:
|
| as_nhi | |
|---|---|
| जानकारी | Optional. |
| उदाहरण | ये नतीजे, 5 से 10 की खोज की रेंज पर सेट करते हैं. इनमें ये भी शामिल हैं:
|
| as_oq | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
| as_q | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
| as_qdr | |
|---|---|
| जानकारी | Optional.
|
| उदाहरण |
यह उदाहरण पिछले साल के नतीजों के लिए अनुरोध करता है:
यह उदाहरण पिछले 10 दिनों के नतीजों के लिए अनुरोध करता है:
|
| as_sitesearch | |
|---|---|
| जानकारी | Optional. |
| उदाहरण |
|
क्वेरी में इस्तेमाल किए जाने वाले खास शब्द
Google Web Search, क्वेरी के लिए ऐसे कई खास शब्दों का इस्तेमाल करने की अनुमति देता है जो
Google खोज इंजन की अतिरिक्त क्षमताओं का एक्सेस करता है. ये
q अनुरोध पैरामीटर की वैल्यू में, खास क्वेरी के लिए शब्द शामिल होने चाहिए. अन्य क्वेरी शब्दों की तरह,
क्वेरी के लिए खास शब्द यूआरएल-एस्केप होने चाहिए. ऐप्लिकेशन
की संख्या में विशेष क्वेरी शब्दों में एक कोलन (:) होता है. यह किरदार
यह भी ज़रूरी है कि यूआरएल एस्केप होने चाहिए; इसकी यूआरएल-एस्केप्ड वैल्यू %3A है.
| बैक लिंक [link:] | |
|---|---|
| जानकारी |
आप as_lq अनुरोध का इस्तेमाल भी कर सकते हैं
ध्यान दें: आप तब कोई अन्य क्वेरी शब्द दर्ज नहीं कर सकते, जब
|
| उदाहरण |
|
| बूलियन OR खोज [ या ] | |
|---|---|
| जानकारी |
आप as_oq अनुरोध का इस्तेमाल भी कर सकते हैं पैरामीटर का इस्तेमाल करें. ध्यान दें: अगर खोज का अनुरोध किया जाता है, तो क्वेरी "लंदन+OR+Paris" का उल्लेख करता है, खोज परिणामों में ये शामिल होंगे दस्तावेज़ों में कम से कम इन दो शब्दों में से कम से कम एक शब्द हो. कुछ मामलों में, खोज परिणामों के दस्तावेज़ों में दोनों शब्द हो सकते हैं. |
| उदाहरण | लंदन या पेरिस खोजें: उपयोगकर्ता का इनपुट:
london OR
paris क्वेरी के लिए इस्तेमाल किया गया शब्द:q=london+OR+parisलंदन या पेरिस में छुट्टियों के लिए खोजें: क्वेरी शब्द:
q=vacation+london+OR+parisछुट्टियों और लंदन, पेरिस या चॉकलेट में से कोई एक खोजें: क्वेरी शब्द:
q=vacation+london+OR+paris+OR+chocolatesछुट्टियां बिताने और चॉकलेट के साथ ही लंदन या पेरिस में घूमने के लिए जब चॉकलेट को सबसे कम वज़न दिया जाता है, तो: क्वेरी शब्द:
q=vacation+london+OR+paris+chocolatesऐसे दस्तावेज़ में छुट्टियां, चॉकलेट और फूल खोजें यह भी हो सकता है कि लंदन या पेरिस: क्वेरी शब्द:
q=vacation+london+OR+paris+chocolates+flowersलंदन या पेरिस में छुट्टियों के लिए खोजें और यह भी खोजें चॉकलेट या फूलों में से किसी एक के लिए: क्वेरी शब्द: q=vacation+london+OR+paris+chocolates+OR+flowers |
| क्वेरी शब्द बाहर रखें [-] | |
|---|---|
| जानकारी | बाहर रखें (
क्वेरी को बाहर रखने वाला शब्द तब काम आता है, जब किसी खोज के लिए शब्द में ज़्यादा का मतलब है. उदाहरण के लिए, शब्द "बेस" नतीजे दिखा सके मछली या संगीत से जुड़े विषयों पर बात करते हैं. अगर आपको मछली, आप अपने खोज नतीजों से संगीत से जुड़े दस्तावेज़ों को बाहर रख सकते हैं 'बाहर रखने वाली क्वेरी' शब्द का इस्तेमाल करें. आप as_eq अनुरोध का इस्तेमाल भी कर सकते हैं किसी खास शब्द या वाक्यांश से मेल खाने वाले दस्तावेज़ों को शामिल न करने के लिए पैरामीटर खोज नतीजों से. |
| उदाहरण | उपयोगकर्ता का इनपुट: bass -musicक्वेरी शब्द: q=bass+%2Dmusic |
| फ़ाइल प्रकार बहिष्करण [ -फ़ाइल का प्रकार: ] | |
|---|---|
| जानकारी |
ध्यान दें: एक से ज़्यादा प्रॉडक्ट को बाहर रखा जा सकता है
ज़्यादा Google जिन फ़ाइल टाइप का इस्तेमाल करता है उनमें ये शामिल हैं:
आने वाले समय में और भी फ़ाइल टाइप जोड़ी जा सकती हैं. अप-टू-डेट सूची को हमेशा Google के फ़ाइल टाइप के बारे में अक्सर पूछे जाने वाले सवाल में देखा जा सकता है. |
| उदाहरण | इस उदाहरण में वे दस्तावेज़ दिखाए जाते हैं जिनमें "Google" लिखा हो CANNOT TRANSLATE
ये PDF दस्तावेज़ नहीं हैं: इस उदाहरण में वे दस्तावेज़ दिखाए जाते हैं जिनमें "Google" लिखा हो लेकिन
इसमें PDF और Word, दोनों तरह के दस्तावेज़ शामिल नहीं हैं: |
| फ़ाइल प्रकार फ़िल्टर करना [ filetype: ] | |
|---|---|
| जानकारी |
आपके पास, वीडियो खोजने पर पाबंदी लगाने का विकल्प है
कई फ़ाइल एक्सटेंशन में से किसी एक से मेल खाने वाले दस्तावेज़ों के लिए नतीजे
आपकी क्वेरी के लिए ज़्यादा डिफ़ॉल्ट रूप से, खोज के नतीजे किसी भी फ़ाइल एक्सटेंशन वाले दस्तावेज़ों को शामिल करें. Google जिन फ़ाइल टाइप का इस्तेमाल करता है उनमें ये शामिल हैं:
आने वाले समय में और भी फ़ाइल टाइप जोड़ी जा सकती हैं. अप-टू-डेट सूची को हमेशा Google के फ़ाइल टाइप के बारे में अक्सर पूछे जाने वाले सवाल में देखा जा सकता है. |
| उदाहरण | इस उदाहरण में ऐसे PDF दस्तावेज़ दिखाए गए हैं जिनमें "Google" लिखा है: इस उदाहरण में, बताए गए PDF और Word के दस्तावेज़ दिखाए जाते हैं
"Google": |
| क्वेरी शब्द [+] शामिल करें | |
|---|---|
| जानकारी | शामिल करें (+) क्वेरी शब्द से पता चलता है कि कोई शब्द या वाक्यांश खोज परिणामों में शामिल सभी दस्तावेज़ों में आना चाहिए. टूल का इस्तेमाल करने के लिए क्वेरी शब्द शामिल नहीं करते है, तो आप उस शब्द या वाक्यांश का प्रस्ताव देंगे जिसे "+" के साथ सभी खोज परिणामों में शामिल होता है (प्लस का निशान).
आपको उस सामान्य शब्द से पहले |
| उदाहरण | उपयोगकर्ता का इनपुट: Star Wars Episode +Iक्वेरी शब्द: q=Star+Wars+Episode+%2BI |
| सिर्फ़ Search के लिंक, सभी शब्द [ allinlinks: ] | |
|---|---|
| जानकारी |
अगर आपकी खोज क्वेरी में
|
| उदाहरण | उपयोगकर्ता का इनपुट:allinlinks: Google searchक्वेरी शब्द: q=allinlinks%3A+Google+search |
| फ़्रेज़ सर्च | |
|---|---|
| जानकारी | वाक्यांश खोज (") क्वेरी शब्द की सहायता से वाक्यांशों को उद्धरण चिह्नों के भीतर या उन्हें हाइफ़न से जोड़ा जा सकता है.
वाक्यांश खोज विशेष रूप से तब उपयोगी होती हैं जब आप के लिए इस्तेमाल किया जाता है. आप as_epq अनुरोध का इस्तेमाल भी कर सकते हैं पैरामीटर का उपयोग करें. |
| उदाहरण | उपयोगकर्ता का इनपुट:"Abraham Lincoln"क्वेरी शब्द: q=%22Abraham+Lincoln%22 |
| सिर्फ़ टेक्स्ट से सर्च, सभी शब्द [allintext:] | |
|---|---|
| जानकारी |
अगर आपकी खोज क्वेरी में
|
| उदाहरण | इस उदाहरण में बताया गया है कि
"Google" और "खोजें" सभी दस्तावेज़ों के मुख्य हिस्से में दिखना चाहिए
खोज के नतीजों में: उपयोगकर्ता का इनपुट: allintext:Google searchक्वेरी शब्द: q=allintext%3AGoogle+search |
| टाइटल खोज, एक शब्द [intitle:] | |
|---|---|
| जानकारी |
ध्यान दें: अगर
दस्तावेज़ के शीर्षक में एक शब्द के बजाय एक शब्द के नीचे
ऐसे हर शब्द के आगे
|
| उदाहरण | यह उदाहरण बताता है कि शब्द "Google" इसमें होना चाहिए
खोज परिणामों में मौजूद किसी भी दस्तावेज़ के शीर्षक, और शब्दों के लिए
"खोजें" शीर्षक, यूआरएल, लिंक या मुख्य हिस्से के टेक्स्ट में कहीं भी दिखना चाहिए
उनमें से ये दस्तावेज़: |
| टाइटल सर्च, सभी शब्द [allintitle:] | |
|---|---|
| जानकारी |
ध्यान दें: खोज क्वेरी की शुरुआत में
|
| उदाहरण | इस उदाहरण में बताया गया है कि शब्द "Google" और "खोजें"
खोज के नतीजों में मौजूद किसी भी दस्तावेज़ के टाइटल में दिखना चाहिए: |
| यूआरएल खोज, एक शब्द [inurl:] | |
|---|---|
| जानकारी |
|
| उदाहरण | यह उदाहरण बताता है कि शब्द "Google" इसमें होना चाहिए
खोज के नतीजों में मौजूद किसी भी दस्तावेज़ के यूआरएल और "खोजें" शब्द को
उन लेखों के टाइटल, यूआरएल, लिंक या मुख्य हिस्से में कहीं भी शामिल होने चाहिए
दस्तावेज़: |
| यूआरएल खोज, सभी शब्द [allinurl:] | |
|---|---|
| जानकारी |
|
| उदाहरण | इस उदाहरण में बताया गया है कि शब्द "Google" और "खोजें"
खोज के नतीजों में, किसी भी दस्तावेज़ के यूआरएल में यह ज़रूर दिखना चाहिए: |
| वेब दस्तावेज़ की जानकारी [info:] | |
|---|---|
| जानकारी |
ध्यान दें: आप तब कोई अन्य क्वेरी शब्द दर्ज नहीं कर सकते, जब
|
| उदाहरण | उपयोगकर्ता का इनपुट: info:www.google.comक्वेरी शब्द: q=info%3Awww.google.com |
इमेज क्वेरी के सैंपल
नीचे दिए गए उदाहरणों में, इमेज एचटीटीपी के कुछ अनुरोध दिखाए गए हैं. इनकी मदद से, अलग-अलग क्वेरी पैरामीटर का इस्तेमाल करने का तरीका बताया गया है. अलग-अलग क्वेरी पैरामीटर की परिभाषाएं, इस दस्तावेज़ के 'इमेज क्वेरी पैरामीटर की परिभाषाएं' सेक्शन में दी गई हैं.
यह अनुरोध, क्वेरी शब्द "बंदर" के लिए पहले पांच नतीजों (start=0&num=5) के लिए कहता है फ़ाइल टाइप .png में से (q=monkey). आखिर में, क्वेरी में client, output, और cx पैरामीटर की वैल्यू का पता चलता है. ये तीनों ज़रूरी हैं.
http://www.google.com/cse? searchtype=image start=0 &num=5 &q=monkey &as_filetype=png &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
इमेज सर्च क्वेरी पैरामीटर
| as_filetype | |
|---|---|
| जानकारी | Optional. किसी खास तरह की इमेज दिखाता है. इन वैल्यू का इस्तेमाल किया जा सकता है: |
| उदाहरण | q=google&as_filetype=png |
| imgsz | |
|---|---|
| जानकारी | Optional. तय साइज़ की इमेज दिखाता है, जहां साइज़ इनमें से कोई एक हो सकता है:
|
| उदाहरण | q=google&as_filetype=png&imgsz=icon |
| इमेज टाइप | |
|---|---|
| जानकारी | Optional. किसी ऐसे टाइप की इमेज दिखाता है जो इनमें से कोई एक हो सकती है:
|
| उदाहरण | q=google&as_filetype=png&imgtype=photo |
| imgc | |
|---|---|
| जानकारी | Optional. ब्लैक ऐंड व्हाइट, ग्रेस्केल या रंगीन इमेज दिखाता है:
|
| उदाहरण | q=google&as_filetype=png&imgc=gray |
| imgcolor | |
|---|---|
| जानकारी | Optional. किसी खास रंग की इमेज दिखाता है:
|
| उदाहरण | q=google&as_filetype=png&imgcolor=yellow |
| as_rights | |
|---|---|
| जानकारी | Optional. लाइसेंस के हिसाब से फ़िल्टर. इस्तेमाल की जा सकने वाली वैल्यू में ये शामिल हैं:
|
| उदाहरण | q=cats&as_filetype=png&as_rights=cc_attribute |
अनुरोध की सीमाएं
नीचे दिए गए चार्ट में उन खोज अनुरोधों की सीमाओं की जानकारी दी गई है जिन्हें आपने खोज के लिए इस्तेमाल किया है Google को भेजें:
| कॉम्पोनेंट | सीमा | टिप्पणी |
|---|---|---|
| खोज अनुरोध अवधि | 2048 बाइट | |
| क्वेरी में इस्तेमाल हुए शब्दों की संख्या | 10 | इसमें इन पैरामीटर में शब्द शामिल होते हैं: q, as_epq, as_eq, as_lq, as_oq, as_q |
| परिणामों की संख्या | 20 | अगर num पैरामीटर को 20 से बड़ी संख्या पर सेट किया जाता है, तो सिर्फ़ 20 नतीजे मिलते हैं. यहां की यात्रा पर हूं ज़्यादा नतीजे मिलते हैं, तो आपको कई अनुरोध भेजने होंगे और start पैरामीटर की वैल्यू को इससे बढ़ाएं हर अनुरोध के साथ किया जा सकता है. |
क्वेरी और नतीजों को दुनिया भर में दिखाना
Google WebSearch सेवा की मदद से, कई भाषाओं में उपलब्ध है. आप कैरेक्टर एन्कोडिंग तय कर सकते हैं इसका इस्तेमाल आपके एचटीटीपी अनुरोध को समझने और एक्सएमएल रिस्पॉन्स को कोड में बदलने के लिए किया जाएगा (ieऔर oe खोज का इस्तेमाल करके पैरामीटर). नतीजों को सिर्फ़ दस्तावेज़ों को शामिल करने के लिए भी फ़िल्टर किया जा सकता है कुछ भाषाओं में लिखे गए हों.
इन सेक्शन में, Google पर खोज करने से जुड़ी समस्याओं के बारे में बताया गया है एकाधिक भाषाएं:
वर्ण एन्कोडिंग
सर्वर, वेब पेजों जैसा डेटा उपयोगकर्ता एजेंट को भेजते हैं, जैसे कि एन्कोड किए गए बाइट के क्रम के रूप में. इसके बाद, उपयोगकर्ता एजेंट डिकोड करता है बाइट को वर्णों के क्रम में लगाना होगा. को अनुरोध भेजते समय वेबखोज सेवा, आप दोनों के लिए एन्कोडिंग स्कीम निर्दिष्ट कर सकते हैं और आपको मिलने वाले एक्सएमएल रिस्पॉन्स के लिए भी इस्तेमाल किया जा सकता है.
यह तय करने के लिए कि ie अनुरोध पैरामीटर का इस्तेमाल किया जा सकता है
आपके एचटीटीपी अनुरोध में मौजूद वर्णों को कोड में बदलने का तरीका. आप
कोड में बदलने के तरीके की जानकारी देने के लिए भी oe पैरामीटर का इस्तेमाल करें
एक्सएमएल के रिस्पॉन्स को कोड में बदलने के लिए, Google को इस स्कीम का इस्तेमाल करना चाहिए. अगर आप
ISO-8859-1 (या latin1) के अलावा किसी अन्य एन्कोडिंग स्कीम का इस्तेमाल करके, कृपया पक्का करें कि आप सही मान दर्ज करें.
ie और oe पैरामीटर के लिए.
ध्यान दें: अगर एक से ज़्यादा यूआरएल के लिए खोज करने की सुविधा दी जा रही है
, हमारा सुझाव है कि आप utf8 (UTF-8) एन्कोडिंग वैल्यू का इस्तेमाल करें
ie और oe पैरामीटर, दोनों के लिए लागू होता है.
कृपया वर्ण सीमा को देखें एन्कोडिंग स्कीम, जिसमें वैल्यू की पूरी सूची के लिए अपेंडिक्स शामिल है इसका इस्तेमाल ie और oe पैरामीटर के लिए किया जा सकता है.
कैरेक्टर एन्कोडिंग के बारे में ज़्यादा जानने के लिए, कृपया http://www.w3.org/TR/REC-html40/charset.html देखें.
इंटरफ़ेस की भाषाएं
hl अनुरोध पैरामीटर का इस्तेमाल करके, अपने ग्राफ़िकल इंटरफ़ेस की भाषा को पहचानें. hl पैरामीटर वैल्यू, एक्सएमएल के खोज नतीजों पर असर डाल सकती है. ऐसा खास तौर पर अंतरराष्ट्रीय क्वेरी, जब भाषा की पाबंदी (lr पैरामीटर का इस्तेमाल करके) साफ़ तौर पर न बताई गई हो. ऐसे में मामलों में, hl पैरामीटर खोज नतीजों को प्रमोट कर सकता है उसी भाषा में हो जो उपयोगकर्ता की इनपुट भाषा में है.
हमारा सुझाव है कि आप hl पैरामीटर को साफ़ तौर पर सेट करें ताकि यह पक्का किया जा सके कि Google हर क्वेरी के लिए खोज परिणाम.
कृपया काम करने वाला इंटरफ़ेस देखें भाषाएं सेक्शन में, hl पैरामीटर की मान्य वैल्यू की पूरी सूची देखी जा सकती है.
विशिष्ट भाषाओं में लिखे गए दस्तावेज़ों को खोजना
lr अनुरोध पैरामीटर का इस्तेमाल करके खोज परिणामों को उन दस्तावेज़ों तक सीमित करें जिन्हें किसी विशेष दस्तावेज़ में लिखा गया है भाषा या भाषाओं का सेट.
lr पैरामीटर बूलियन ऑपरेटर के साथ काम करता है, ताकि आपको यह जानकारी मिल सके एक से ज़्यादा ऐसी भाषाएं जिन्हें खोज में शामिल किया जाना चाहिए या शामिल नहीं किया जाना चाहिए नतीजे.
यहां दिए गए उदाहरणों में बताया गया है कि दस्तावेज़ों का अनुरोध करने के लिए, बूलियन ऑपरेटर का इस्तेमाल कैसे किया जा सकता है अलग-अलग भाषाओं में ब्राउज़ कर सकते हैं.
जैपनीज़ में लिखे गए दस्तावेज़ों के लिए:
lr=lang_jp
इटैलियन या जर्मन में लिखे दस्तावेज़ों के लिए:
lr=lang_it|lang_de
ऐसे दस्तावेज़ों के लिए जो हंगेरियन या चेक में नहीं लिखे गए हैं:
lr=(-lang_hu).(-lang_cs)
कृपया भाषा संग्रह देखें lr पैरामीटर और बूलियन' पैरामीटर की संभावित वैल्यू की पूरी सूची के लिए, वैल्यू सेक्शन ऑपरेटर सेक्शन में, इनके इस्तेमाल के बारे में पूरी जानकारी पाएं ऑपरेटर का इस्तेमाल करें.
सरल और पारंपरिक चीनी खोज
सिंप्लिफ़ाइड चाइनीज़ और ट्रेडिशनल चाइनीज़, लिखने के दो अलग-अलग वैरिएंट हैं के बारे में बात करते हैं. एक ही सिद्धांत को अलग तरह से लिखा जा सकता है हर वैरिएंट के लिए उपलब्ध हो. किसी एक वैरिएंट में क्वेरी की वजह से, Google WebSearch सेवा, ऐसे नतीजे दिखा सकती है जिनमें दोनों पेज शामिल हों अलग-अलग वर्शन का इस्तेमाल करें.
इस सुविधा का उपयोग करने के लिए:
- c2coff अनुरोध पैरामीटर को 0 पर सेट करें
और - इनमें से कोई एक काम करें:
इस उदाहरण में ऐसे क्वेरी पैरामीटर दिखाए गए हैं जिन्हें नतीजों के अनुरोध में शामिल किया जाएगा सिंप्लिफ़ाइड और ट्रेडिशनल चाइनीज़, दोनों में. (ध्यान दें कि अन्य ज़रूरी जानकारी, जैसे कि का इस्तेमाल क्लाइंट के तौर पर नहीं किया है, इसलिए इस उदाहरण में शामिल नहीं किया गया है.)
search?hl=zh-CN
&lr=lang_zh-TW|lang_zh-CN
&c2coff=0परिणाम फ़िल्टर करना
Google WebSearch आपको खोज को फ़िल्टर करने के कई तरीके उपलब्ध कराता है नतीजे:
- स्वचालित खोज के नतीजों को फ़िल्टर करना
- भाषा और देश के हिसाब से फ़िल्टर करना
- वयस्कों के लिए बने कॉन्टेंट को, इसके हिसाब से फ़िल्टर करना SafeSearch
खोज के नतीजों को अपने-आप फ़िल्टर करना
खोज के सबसे अच्छे नतीजे दिखाने के लिए, Google जो खोज परिणामों को अपने आप फ़िल्टर करने के लिए दो तकनीकों का उपयोग करता है, इन्हें आम तौर पर अनचाहे कामों के लिए माना जाता है:
-
डुप्लीकेट कॉन्टेंट—अगर एक से ज़्यादा दस्तावेज़ों में तो उस सेट का सबसे प्रासंगिक दस्तावेज़ ही आपके खोज परिणामों में शामिल किया गया.
-
होस्ट क्राउडिंग—अगर आपको एक ही साइट के रूप में है, तो हो सकता है कि Google उस साइट के सभी परिणाम न दिखाए या
में नीचे के नतीजे दिखाओ रैंकिंग पहले की तुलना में कम थी.
हमारा सुझाव है कि आप सामान्य खोज अनुरोधों के लिए ये फ़िल्टर चालू रखें क्योंकि फ़िल्टर ज़्यादातर खोज की क्वालिटी को काफ़ी बेहतर बनाते हैं नतीजे. हालांकि, अपने-आप काम करने वाले इन फ़िल्टर को बायपास करने के लिए, फ़िल्टर क्वेरी पैरामीटर को 0 पर सेट किया जा सकता है. खोज अनुरोध.
भाषा और देश फ़िल्टर करना
Google WebSearch सेवा, इसके मास्टर इंडेक्स से नतीजे दिखाती है सभी वेब दस्तावेज़ों में. मास्टर इंडेक्स में इसके उप-संग्रह शामिल हैं ऐसे दस्तावेज़ जिन्हें भाषा या अन्य खास एट्रिब्यूट के हिसाब से ग्रुप में बांटा जाता है और मूल देश का नाम है.
खोज के नतीजों को इसके सब-कलेक्शन तक सीमित करने के लिए, lr और cr अनुरोध पैरामीटर का इस्तेमाल किया जा सकता है ऐसे दस्तावेज़ जो खास भाषाओं में लिखे गए हैं या जिनके स्रोत किसी देश में लागू होता है.
Google Web Search, विश्लेषण करके किसी दस्तावेज़ की भाषा तय करता है:
- दस्तावेज़ के यूआरएल का टॉप लेवल डोमेन (टीएलडी)
- दस्तावेज़ में मौजूद भाषा वाले मेटा टैग
- दस्तावेज़ के मुख्य हिस्से में इस्तेमाल की गई मुख्य भाषा
अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
कृपया lr पैरामीटर की परिभाषा भी देखें, जो खोज की जा रही है
अलग-अलग भाषाओं में लिखे गए दस्तावेज़ों और भाषा कलेक्शन की वैल्यू को
ज़्यादा जानकारी के लिए lr पैरामीटर के लिए वैल्यू के रूप में इस्तेमाल किया जाता है
भाषा के आधार पर नतीजों को सीमित करने के बारे में जानकारी.
Google Web Search, विश्लेषण करके किसी दस्तावेज़ के देश का पता लगाता है:
- दस्तावेज़ के यूआरएल का टॉप लेवल डोमेन (टीएलडी)
- वेब सर्वर के आईपी पते का भौगोलिक स्थान
कृपया cr पैरामीटर और Country कलेक्शन की परिभाषा भी देखें वे वैल्यू जिनका इस्तेमाल cr पैरामीटर की वैल्यू के तौर पर किया जा सकता है. इससे देश के हिसाब से नतीजों पर पाबंदी लगाने के बारे में ज़्यादा जानकारी मिलेगी ऑरिजिन.
ध्यान दें: भाषा को एक साथ जोड़ा जा सकता है और देश के मान चुनें. इसके लिए उदाहरण के लिए, आप ऐसे दस्तावेज़ों का अनुरोध कर सकते हैं, जो फ़्रेंच में लिखे गए हैं और फ़्रांस या कनाडा से आए हैं या आप ऐसे दस्तावेज़ों का अनुरोध कर सकते हैं जो वे हॉलैंड के हैं और अंग्रेज़ी में नहीं लिखे गए हैं. lr और cr पैरामीटर, दोनों बूलियन ऑपरेटर के साथ काम करते हैं.
सेफ़ सर्च की मदद से, वयस्कों के लिए बना कॉन्टेंट फ़िल्टर करना
Google के कई ग्राहक, इनके लिए खोज के नतीजे नहीं दिखाना चाहते साइटें जिनमें वयस्कों के लिए कॉन्टेंट हो. सेफ़ सर्च फ़िल्टर का इस्तेमाल करके, यह पता लगाया जा सकता है कि जिनमें वयस्कों के लिए कॉन्टेंट होता है और उन्हें हटा दिया जाता है. Google के फ़िल्टर, कीवर्ड और वाक्यांशों की जांच करने के लिए मालिकाना हक वाली टेक्नोलॉजी का इस्तेमाल करते हैं जोड़ें. हालांकि कोई भी फ़िल्टर 100 प्रतिशत सटीक नहीं होता, लेकिन सेफ़ सर्च की सुविधा अपनी खोज से बहुत ज़्यादा वयस्क सामग्री हटाएं नतीजे.
Google, सेफ़ सर्च की सेटिंग को मौजूदा समय के अंदर बेहतर बनाने की कोशिश करता है. लगातार वेब को क्रॉल करके और अपडेट को शामिल करके उपयोगकर्ता के सुझावों से.
सेफ़ सर्च की सुविधा, इन भाषाओं में उपलब्ध है:
| डच अंग्रेज़ी फ़्रेंच जर्मन |
इटैलियन पुर्तगाली (ब्राज़ीलियन) स्पैनिश ट्रेडिशनल चाइनीज़ |
Google आपके खोज नतीजों को जिस हद तक फ़िल्टर करता है उसे अडजस्ट किया जा सकता है safe क्वेरी पैरामीटर का इस्तेमाल करके वयस्क सामग्री. नीचे दी गई टेबल में, Google की सेफ़ सर्च की सेटिंग के बारे में जानकारी दी गई है. साथ ही, यह भी बताया गया है कि वे सेटिंग से आपके खोज के नतीजों पर असर पड़ेगा:
| सेफ़ सर्च का लेवल | ब्यौरा |
|---|---|
| उच्च | इससे ज़्यादा सख्त वर्शन चालू किया जाता है सुरक्षित खोज के सुझाव दिए जाते हैं. |
| मध्यम | यह को शामिल करने वाले वेब पेजों को ब्लॉक करता है पोर्नोग्राफ़ी और अन्य साफ़ तौर पर सेक्शुअल ऐक्ट दिखाने वाला कॉन्टेंट. |
| बंद है | वयस्क को फ़िल्टर नहीं करता खोज के नतीजों में मौजूद कॉन्टेंट. |
अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है * सेफ़ सर्च की डिफ़ॉल्ट सेटिंग बंद है.
अगर आपने सेफ़ सर्च की सेटिंग चालू की है और आपको खोज के नतीजों में, अगर आपको लगता है कि आपके नतीजों में आपत्तिजनक कॉन्टेंट दिख रहा है, तो कृपया साइट के यूआरएल को safesearch@google.com पर ईमेल करें. साइट की जांच करेगा.
एक्सएमएल नतीजे
- Google एक्सएमएल डीटीडी के नतीजे
- एक्सएमएल रिस्पॉन्स के बारे में जानकारी
- XML सामान्य और ऐडवांस खोज क्वेरी के लिए नतीजे
- नियमित/बेहतर खोज: सैंपल क्वेरी और एक्सएमएल के नतीजे
- सामान्य/ऐडवांस खोज: एक्सएमएल टैग
Google XML परिणाम DTD
Google सभी तरह के एक्सएमएल फ़ॉर्मैट के बारे में बताने के लिए, एक ही DTD का इस्तेमाल करता है खोज के नतीजे. कई टैग और एट्रिब्यूट सभी के लिए लागू होते हैं खोज प्रकार. हालांकि, कुछ टैग केवल खास लोगों के लिए ही लागू होते हैं खोज प्रकार. इस वजह से, डीटीडी की परिभाषाएं कम हो सकती हैं इस दस्तावेज़ में बताई गई परिभाषाओं से ज़्यादा पाबंदी वाला है.
इस दस्तावेज़ में डीटीडी के उन पहलुओं के बारे में बताया गया है जो काम के हैं WebSearch के लिए. अगर डीटीडी को देखा जाता है, तो आप उन टैग और एट्रिब्यूट को सुरक्षित रूप से अनदेखा कर सकते हैं जो दस्तावेज़ यहां दिए गए हैं. अगर परिभाषा DTD और दस्तावेज़ में बताया गया है, तो यह तथ्य इस दस्तावेज़ में दिया गया है.
Google, इनके रेफ़रंस के साथ या इनके बिना, एक्सएमएल नतीजे दे सकता है DTD. DTD, खोज एडमिन की मदद करने के लिए एक गाइड है और एक्सएमएल पार्सर, Google के एक्सएमएल नतीजों को समझते हैं. क्योंकि Google के एक्सएमएल व्याकरण समय-समय पर बदल सकता है, इसलिए आपको अपने पार्सर का इस्तेमाल करें.
इसके अलावा, आपको हर बार खोज का अनुरोध सबमिट करने पर DTD. Google, डीटीडी को अपडेट करता है ऐसा बहुत कम होता है. इन अनुरोधों की वजह से बेवजह की देरी और बैंडविड्थ होती है ज़रूरतें.
Google का सुझाव है कि एक्सएमएल नतीजे पाने के लिए, आप xml_no_dtd आउटपुट फ़ॉर्मैट का इस्तेमाल करें. अगर खोज अनुरोध में xml आउटपुट फ़ॉर्मैट चुना जाता है, तो अंतर सिर्फ़ यह है कि एक्सएमएल नतीजों में नीचे दी गई लाइन शामिल की जाती है:
<!DOCTYPE GSP SYSTEM "google.dtd">नए डीटीडी को यहां ऐक्सेस किया जा सकता है: http://www.google.com/google.dtd.
कृपया ध्यान दें कि हो सकता है कि इस समय DTD की सभी सुविधाएं उपलब्ध न हों या समर्थित न हों.
एक्सएमएल रिस्पॉन्स के बारे में जानकारी
- सभी एलिमेंट वैल्यू मान्य एचटीएमएल के तौर पर तब तक नहीं हैं, जब तक इन्हें डिसप्ले नहीं किया जा सकता जो एक्सएमएल टैग की परिभाषाओं में दी गई है.
- कुछ एलिमेंट वैल्यू ऐसे यूआरएल होते हैं जिन्हें यूआरएल से पहले, एचटीएमएल-एन्कोडेड में डालना ज़रूरी होता है वे दिखाए जाते हैं.
- आपके एक्सएमएल पार्सर को ऐसे एट्रिब्यूट और टैग को अनदेखा करना चाहिए जो दस्तावेज़ में नहीं हैं. इससे आपके ऐप्लिकेशन को बिना किसी बदलाव के काम करना जारी रखने की अनुमति मिलती है अगर Google, इस एक्सएमएल आउटपुट में ज़्यादा सुविधाएं जोड़ता है.
- मान के रूप में शामिल करने पर कुछ वर्णों का एस्केप होना ज़रूरी है
एक्सएमएल टैग. आपके एक्सएमएल प्रोसेसर को ये इकाइयां
सही वर्णों का इस्तेमाल करें. यदि आप इकाइयों को सही ढंग से रूपांतरित नहीं करते हैं,
उदाहरण के लिए, ब्राउज़र & "& के रूप में वर्ण.
एक्सएमएल
स्टैंडर्ड दस्तावेज़ों में ये वर्ण शामिल होते हैं; ये वर्ण हैं
नीचे दी गई टेबल में दिया गया है:
वर्ण एस्केप्ड फ़ॉर्म्स इकाई वर्ण कोड एंपरसैंड & & & सिंगल कोट ' ' ' डबल कोट " " " इससे ज़्यादा > > > इससे कम < < <
सामान्य और बेहतर खोज क्वेरी के लिए एक्सएमएल नतीजे
सामान्य/बेहतर खोज: सैंपल क्वेरी और एक्सएमएल नतीजे
WebSearch के इस अनुरोध में 10 नतीजे चाहिए (num=10)
खोज शब्द "socer" के बारे में (q=socer), यह शब्द
"सॉकर" इस उदाहरण में जान-बूझकर गलत स्पेलिंग लिखी गई है.)
http://www.google.com/search?
q=socer
&hl=en
&start=10
&num=10
&output=xml
&client=google-csbe
&cx=00255077836266642015:u-scht7a-8i
इस अनुरोध से नीचे दिया गया एक्सएमएल नतीजा मिलता है. ध्यान दें कि यह बताने के लिए एक्सएमएल के नतीजे में कई टिप्पणियां कि कुछ टैग कहां नहीं परिणाम में शामिल दिखाई देगा.
<?xml version="1.0" encoding="ISO-8859-1" standalone="no" ?>
<GSP VER="3.2">
<TM>0.452923</TM>
<Q>socer</Q>
<PARAM name="cx" value="00255077836266642015:u-scht7a-8i" original_value="00255077836266642015%3Au-scht7a-8i"/>
<PARAM name="hl" value="en" original_value="en"/>
<PARAM name="q" value="socer" original_value="socer"/>
<PARAM name="output" value="xml" original_value="xml"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe"/>
<PARAM name="num" value="10" original_value="10"/>
<Spelling>
<Suggestion q="soccer"><b><i>soccer</i></b></Suggestion>
</Spelling>
<Context>
<title>Sample Vacation CSE</title>
<Facet>
<FacetItem>
<label>restaurants</label>
<anchor_text>restaurants</anchor_text>
</FacetItem>
<FacetItem>
<label>wineries</label>
<anchor_text>wineries</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>golf_courses</label>
<anchor_text>golf courses</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>hotels</label>
<anchor_text>hotels</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>nightlife</label>
<anchor_text>nightlife</anchor_text>
</FacetItem>
</Facet>
<Facet>
<FacetItem>
<label>soccer_sites</label>
<anchor_text>soccer sites</anchor_text>
</FacetItem>
</Facet>
</Context>
<RES SN="1" EN="10">
<M>6080</M>
/*
* The FI tag after the comment indicates that the result
* set has been filtered. If the number of results were exact, the
* FI tag would be replaced by an XT tag in the same format.
*/
<FI />
<NB>
/*
* Since the request is for the first page of results, the PU tag,
* which contains a link to the previous page of search results,
* is not included in this XML result. If the sample result did include
* a previous page of results, it would be listed here, in the same format
* as the NU tag on the following line
*/
<NU>/search?q=socer&hl=en&lr=&ie=UTF-8&output=xml&client=test&start=10&sa=N</NU>
</NB>
<R N="1">
<U>http://www.soccerconnection.net/</U>
<UE>http://www.soccerconnection.net/</UE>
<T>SoccerConnection.net</T>
<CRAWLDATE>May 21, 2007</CRAWLDATE>
<S><b>soccer</b>; players; coaches; ball; world cup;<b>...</b></S>
<Label>transcodable_pages</Label>
<Label>accessible</Label>
<Label>soccer_sites</Label>
<LANG>en</LANG>
<HAS>
<DI>
<DT>SoccerConnection.net</DT>
<DS>Post your <b>soccer</b> resume directly on the Internet.</DS>
</DI>
<L/>
<C SZ="8k" CID="kWAPoYw1xIUJ"/>
<RT/>
</HAS>
</R>
/*
* The result includes nine more results, each enclosed by an R tag.
*/
</RES>
</GSP>
नियमित/बेहतर खोज: एक्सएमएल टैग
नियमित खोज के अनुरोधों और बेहतर खोज के लिए एक्सएमएल रिस्पॉन्स दोनों अनुरोध, एक्सएमएल टैग के एक जैसे सेट का इस्तेमाल करते हैं. ये एक्सएमएल टैग यहां दिखाए गए हैं जैसा कि ऊपर बताया गया है. साथ ही, इसकी जानकारी नीचे टेबल में दी गई है.
यहां दिए गए एक्सएमएल टैग को अंग्रेज़ी वर्णमाला के क्रम में टैग के नाम के हिसाब से सूची में रखा गया है और हर टैग की परिभाषा में टैग का ब्यौरा होता है. उदाहरण के लिए, एक्सएमएल नतीजे में टैग किस तरह से दिखेगा और टैग का फ़ॉर्मैट कॉन्टेंट. अगर टैग किसी दूसरे एक्सएमएल टैग का सब-टैग है या टैग में अपने खुद के सब-टैग या एट्रिब्यूट हैं, तो वह जानकारी इसमें भी दी गई है टैग की परिभाषा टेबल.
कुछ सब-टैग के आगे कुछ सिंबल दिखाए जा सकते हैं नीचे दी गई परिभाषाएं देखें. ये निशान और उनके मतलब इस तरह से हैं:
* = सब-टैग
के शून्य या इससे ज़्यादा इंस्टेंस + = सब-टैग
के एक या इससे ज़्यादा इंस्टेंस
| A | B | C | D | जी | घं | मैं | लो | क॰ | उत्तर | सवाल | दक्षिण | दक्षिण | स | U | X |
| anchor_text | |
|---|---|
| परिभाषा | <anchor_text> टैग, उस टेक्स्ट के बारे में बताता है जो आपको उपयोगकर्ताओं को रिफ़ाइन करने की सुविधा की पहचान करने के लिए, लेबल. रिफ़ाइन करने के लेबल के बाद से बिना अक्षरों और अंकों वाले वर्णों को अंडरस्कोर से बदलें, तो आपको ऐसा नहीं करना चाहिए आपके यूज़र इंटरफ़ेस में <label> टैग की वैल्यू दिखाता है. इसके बजाय, आपको <anchor_text> टैग. |
| उदाहरण | <anchor_text>गॉल्फ़ कोर्स</anchor_text> |
| इसका सब-टैग | FacetItem |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| ब्लॉक करें | |
|---|---|
| परिभाषा | यह टैग, प्रमोशन के नतीजे की बॉडी लाइन में ब्लॉक के कॉन्टेंट को शामिल करता है. हर ब्लॉक में T, U, और L सब-टैग होते हैं. खाली T टैग से पता चलता है कि ब्लॉक में टेक्स्ट मौजूद है; खाली U और L टैग से पता चलता है कि ब्लॉक में एक लिंक है (जिसमें U सब-टैग में दिया गया यूआरएल और L सब-टैग में ऐंकर टेक्स्ट दिया गया है). |
| सब-टैग | T, U, L |
| इसका सब-टैग | BODY_LINE |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| BODY_LINE | |
|---|---|
| परिभाषा | यह टैग, प्रमोट किए गए नतीजे के मुख्य हिस्से में किसी लाइन का कॉन्टेंट शामिल करता है. हर बॉडी लाइन में कई ब्लॉक टैग होते हैं, जिनमें कुछ टेक्स्ट या यूआरएल और ऐंकर टेक्स्ट वाला लिंक होता है. |
| सब-टैग | ब्लॉक* |
| इसका सब-टैग | SL_MAIN |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| परिभाषा | <C> टैग बताता है कि WebSearch सेवा
को इस खोज परिणाम यूआरएल का कैश मेमोरी में सेव किया गया वर्शन वापस मिल सकता है. आपके पास ये विकल्प नहीं हैं
एक्सएमएल एपीआई की मदद से, कैश मेमोरी में सेव किए गए पेजों को वापस पाया जा सकता है. हालांकि, आपके पास उपयोगकर्ताओं को रीडायरेक्ट करने का विकल्प भी होता है
www.google.com पर
कॉन्टेंट. |
|||||||||
| एट्रिब्यूट |
|
|||||||||
| उदाहरण | <सी एसज़ेड="6 हज़ार" CID="kvOXK_cYSSgJ" /> | |||||||||
| इसका सब-टैग | इसमें शामिल हैं | |||||||||
| कॉन्टेंट का फ़ॉर्मैट | खाली | |||||||||
| सी2सी | |
|---|---|
| परिभाषा | <C2C> टैग बताता है कि परिणाम पारंपरिक चीनी भाषा के एक पेज को दर्शाता है. यह टैग केवल तभी दिखाई देता है जब सिंप्लिफ़ाइड और ट्रेडिशनल चीनी खोज सक्षम है. चालू करने के बारे में ज़्यादा जानने के लिए, c2coff क्वेरी पैरामीटर की परिभाषा देखें इस सुविधा को बंद कर रहा है. |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| संदर्भ | |
|---|---|
| परिभाषा | <Context> टैग में खोज परिणामों के किसी सेट के साथ संबद्ध शोधन लेबल. |
| उदाहरण | <Context> |
| सब-टैग | टाइटल, फ़ेसेट+ |
| कॉन्टेंट का फ़ॉर्मैट | कंटेनर |
| क्रॉल तारीख | |
|---|---|
| परिभाषा | <CRAWLDATE> टैग वह तारीख पहचानता है जब
पेज को पिछली बार क्रॉल किया गया था. |
| उदाहरण | <CRAWLDATE>21 मई, 2005</CRAWLDATE> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| डीआई | |
|---|---|
| परिभाषा | <DI> टैग में ओपन डायरेक्ट्री प्रोजेक्ट शामिल होता है (ओडीपी) कैटगरी की जानकारी. |
| उदाहरण | <DI> |
| सब-टैग | DT?, DS? |
| इसका सब-टैग | इसमें शामिल हैं |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| DS | |
|---|---|
| परिभाषा | <DS> टैग एक कैटगरी है. |
| उदाहरण | <DS>अपनी पोस्ट <b>soccer</b> सीधे यहाँ से फिर से शुरू करो इंटरनेट.</DS> |
| इसका सब-टैग | डीआई |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (इसमें एचटीएमएल हो सकता है) |
| डीटी | |
|---|---|
| परिभाषा | <DT> टैग किसी सिंगल विंडो का टाइटल देता है ODP डायरेक्ट्री में मौजूद कैटगरी की सूची है. |
| उदाहरण | <DT>SoccerConnection.net</DT> |
| इसका सब-टैग | डीआई |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (इसमें एचटीएमएल हो सकता है) |
| मुखिका | |
|---|---|
| परिभाषा | <Facet> टैग में, <FacetItem> टैग का लॉजिकल ग्रुपिंग शामिल होता है. आप बनाएं ये ग्रुप, Programmable Search Engine का इस्तेमाल करते हैं इंजन एक्सएमएल स्पेसिफ़िकेशन फ़ॉर्मैट. अगर आप इन्हें नहीं बनाते ग्रुपिंग, results_xml_tag_Context><Context> टैग कंटेन अप चार <Facet> टैग तक. हर <Facet> टैग में मौजूद आइटम, डिसप्ले के लिए ग्रुप किए जाएंगे. हालांकि, यह ज़रूरी नहीं है कि इनमें कोई लॉजिकल लॉजिकल न हो संबंध. |
| उदाहरण | <मुखिका> |
| सब-टैग | FacetItem+, title+ |
| इसका सब-टैग | Context |
| कॉन्टेंट का फ़ॉर्मैट | कंटेनर |
| FacetItem | |
|---|---|
| परिभाषा | <FacetItem> टैग में जानकारी शामिल होती है खोज परिणामों के किसी सेट के साथ संबद्ध शोधन लेबल के बारे में. |
| उदाहरण | <FacetItem> |
| सब-टैग | लेबल, anchor_text+ |
| इसका सब-टैग | फ़ेसेट |
| कॉन्टेंट का फ़ॉर्मैट | FacetItem |
| FI | |
|---|---|
| परिभाषा | <FI> टैग, फ़्लैग के तौर पर काम करता है जो बताता है कि खोज के लिए दस्तावेज़ को फ़िल्टर किया गया या नहीं. अपने-आप फ़िल्टर करना सेक्शन देखें Google के खोज परिणामों के बारे में ज़्यादा जानकारी के लिए इस दस्तावेज़ का फ़िल्टर. |
| उदाहरण | <FI /> |
| इसका सब-टैग | रिज़ॉल्यूशन |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| GSP | |||||||
|---|---|---|---|---|---|---|---|
| परिभाषा | <GSP> टैग Google एक्सएमएल के खोज नतीजों में दिए गए सारे डेटा को इनकैप्सुलेट करता है. "जीएसपी" इससे मेल खाता है "Google सर्च प्रोटोकॉल" का संक्षिप्त नाम. |
||||||
| एट्रिब्यूट |
|
||||||
| उदाहरण | <GSP VER="3.2"> | ||||||
| सब-टैग | PARAM+, Q, RES?, TM | ||||||
| कॉन्टेंट का फ़ॉर्मैट | खाली | ||||||
| है | |
|---|---|
| परिभाषा | <HAS> टैग इनकैप्सुलेट करता है
किसी भी खास खोज के बारे में जानकारी
अनुरोध पैरामीटर का इस्तेमाल करें.
ध्यान दें: इसके लिए <HAS> की परिभाषा DTD की तुलना में, WebSearch ज़्यादा पाबंदी लगा. |
| सब-टैग | डीआई?, L?, C?, आरटी? |
| इसका सब-टैग | दक्षिण |
| ISURL | |
|---|---|
| परिभाषा | Google, <ISURL> टैग दिखाता है अगर संबंधित खोज क्वेरी कोई यूआरएल है. |
| इसका सब-टैग | GSP |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| L | |
|---|---|
| परिभाषा | <L> टैग का मौजूद होना इससे पता चलता है कि WebSearch सेवा, अन्य साइटों को इस खोज नतीजे का यूआरएल. ऐसी साइटें ढूंढने के लिए, लिंक: क्वेरी के लिए खास शब्द का इस्तेमाल करें. |
| इसका सब-टैग | इसमें शामिल हैं |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| लेबल | |
|---|---|
| परिभाषा | <label> टैग, रिफ़ाइनमेंट लेबल के बारे में बताता है जिसकी मदद से आपको मिलने वाले खोज नतीजों को फ़िल्टर किया जा सकता है. इस्तेमाल करने के लिए रिफ़ाइन करने का लेबल जोड़ने के लिए, स्ट्रिंग में ज़्यादा:[[label tag value]] जोड़ें Google से किए गए आपके एचटीटीपी अनुरोध में q पैरामीटर की वैल्यू इस तौर पर होगी: नीचे दिए गए उदाहरण में दिखाया गया है. कृपया ध्यान दें कि यह मान Google को क्वेरी भेजने से पहले यूआरएल एस्केप किया गया. This example uses the refinement label golf_courses to ध्यान दें: <label> टैग और यूआरएल अलग-अलग होते हैं <Label> टैग, जो रिफ़ाइनमेंट लेबल की पहचान करता है आपके खोज नतीजों में किसी खास यूआरएल से जुड़ा हो. |
| उदाहरण | <label>golf_courses</label> |
| इसका सब-टैग | FacetItem |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| LANG | |
|---|---|
| परिभाषा | <LANG> टैग में इसके बारे में Google का सबसे अच्छा अनुमान होता है खोज के नतीजे की भाषा. |
| उदाहरण | <lang>hi</lang> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| M | |
|---|---|
| परिभाषा | <M> टैग अनुमानित योग की पहचान करता है खोज के लिए परिणामों की संख्या. ध्यान दें: हो सकता है कि यह अनुमान सही न हो. |
| उदाहरण | <M>1,62,00,000</M> |
| इसका सब-टैग | रिज़ॉल्यूशन |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| NB | |
|---|---|
| परिभाषा | <NB> टैग में नेविगेशन की जानकारी शामिल होती है—यह जानकारी, खोज के नतीजों के अगले पेज या इसके पिछले पेज पर ले जाती है खोज परिणाम—खोज परिणाम सेट के लिए. ध्यान दें: यह टैग सिर्फ़ मौजूद है अगर और नतीजे उपलब्ध हैं. |
| उदाहरण | <NB> |
| सब-टैग | NU?, PU? |
| इसका सब-टैग | रिज़ॉल्यूशन |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| NU | |
|---|---|
| परिभाषा | <NU> टैग में खोज परिणामों का अगला पेज. |
| उदाहरण | <NU>/search?q=flowers&num=10&hl=hi&ie=UTF-8 &Output=xml&client=test&start=10</NU> |
| इसका सब-टैग | एनबी |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (सापेक्ष URL) |
| पैरामीटर | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| परिभाषा | <PARAM> टैग इससे जुड़े एचटीटीपी अनुरोध में सबमिट किए गए इनपुट पैरामीटर की पहचान करता है को भी बदल सकते हैं. पैरामीटर की जानकारी इसमें होती है टैग विशेषताएं—नाम, मान, मूल_मान—और एचटीटीपी अनुरोध में सबमिट किए गए हर पैरामीटर के लिए एक PARAM टैग होना चाहिए. |
||||||||||||
| एट्रिब्यूट |
|
||||||||||||
| उदाहरण | <PARAM name="cr" value="countryNZ" मूल_value="countryNZ" /> | ||||||||||||
| इसका सब-टैग | GSP | ||||||||||||
| कॉन्टेंट का फ़ॉर्मैट | पेचीदा लेवल | ||||||||||||
| PU | |
|---|---|
| परिभाषा | <PU> टैग खोज परिणामों का पिछला पेज. |
| उदाहरण | <PU>/search?q=flowers&num=10&hl=hi&Output=xml &client=test&start=10</PU> |
| इसका सब-टैग | एनबी |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (सापेक्ष URL) |
| Q | |
|---|---|
| परिभाषा | <Q> टैग खोज क्वेरी की पहचान करता है एक्सएमएल नतीजे से जुड़े एचटीटीपी अनुरोध में सबमिट किया गया. |
| उदाहरण | <Q>पिज़्ज़ा</Q> |
| इसका सब-टैग | GSP |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| R | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| परिभाषा | <R> टैग में अलग-अलग खोज परिणाम. ध्यान दें: इसके लिए <R> टैग की परिभाषा DTD की तुलना में, WebSearch ज़्यादा पाबंदी लगा. |
|||||||||
| एट्रिब्यूट |
|
|||||||||
| सब-टैग | U, UE, T?, CRAWLDATE, S?, LANG?, इसमें शामिल हैं | |||||||||
| इसका सब-टैग | रिज़ॉल्यूशन | |||||||||
| आरईएस | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| परिभाषा | <RES> टैग व्यक्तिगत समूह का सेट शामिल करता है जानकारी और खोज के नतीजे देखें. |
|||||||||
| एट्रिब्यूट |
|
|||||||||
| उदाहरण | <RES SN="1" अंग्रेज़ी="10"> | |||||||||
| सब-टैग | M, FI?, XT?, ध्यान दें?, आर* | |||||||||
| इसका सब-टैग | GSP | |||||||||
| कॉन्टेंट का फ़ॉर्मैट | खाली | |||||||||
| S | |
|---|---|
| परिभाषा | <S> टैग में खोज का एक उद्धरण होता है नतीजा, जिसमें क्वेरी के शब्द बोल्ड में हाइलाइट किए गए हों. लाइन ब्रेक सही टेक्स्ट रैपिंग के लिए उद्धरण में शामिल किया जाता है. |
| उदाहरण | <S>वॉशिंगटन (CNN) -- राष्ट्रपति को लेकर सीनेट में स्टैंडऑफ़ <b>बुश's</b> न्यायिक चुनाव होगा नॉमिनेट किए गए पांच लोगों को आखिरी वोट देने के लिए रोका गया और <b>...<b>...</b><S> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (HTML) |
| SL_MAIN | |
|---|---|
| परिभाषा | यह टैग, प्रमोशन के नतीजे का कॉन्टेंट शामिल करता है. प्रमोशन पार्स करने के लिए इस्तेमाल करें. टाइटल लिंक का ऐंकर टेक्स्ट और यूआरएल, T और U सब-टैग में शामिल होते हैं. मुख्य हिस्से और लिंक की लाइनें BODY_LINE सब-टैग में शामिल होती हैं. |
| सब-टैग | BODY_LINE*, T, U |
| इसका सब-टैग | SL_RESULTS |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| SL_RESULTS | |
|---|---|
| परिभाषा | प्रमोट किए गए नतीजों के लिए कंटेनर टैग. जब भी आपके खोज परिणामों में कोई प्रचार होगा, तब इनमें से एक दिखाई देगा. SL_MAIN सब-टैग में मुख्य नतीजे का डेटा शामिल होता है. |
| सब-टैग | SL_MAIN* |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| वर्तनी (स्पेलिंग) | |
|---|---|
| परिभाषा | <वर्तनी> टैग किसी वैकल्पिक टेक्स्ट को शामिल करता है सबमिट की गई क्वेरी के लिए स्पेलिंग का सुझाव. यह टैग केवल यहां दिखाई देता है खोज परिणामों का पहला पेज. स्पेलिंग के सुझाव यहां उपलब्ध हैं अंग्रेज़ी, चाइनीज़, जैपनीज़, और कोरियन. ध्यान दें: Google सिर्फ़ इन चीज़ों के लिए स्पेलिंग के सुझाव दिखाएगा ऐसी क्वेरी जिनमें gl पैरामीटर की वैल्यू मौजूद है अंग्रेज़ी के छोटे अक्षरों का इस्तेमाल करें. |
| उदाहरण | <स्पेलिंग> |
| सब-टैग | सुझाव |
| इसका सब-टैग | GSP |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
| सुझाव | |||||||
|---|---|---|---|---|---|---|---|
| परिभाषा | <Suggestion> टैग में सबमिट की गई क्वेरी के लिए वैकल्पिक स्पेलिंग का सुझाव. Google आपके यूआरएल पैरामीटर को कैसे इस्तेमाल करेगा, यह तय करने के लिए टैग के कॉन्टेंट का इस्तेमाल करें. q एट्रिब्यूट की वैल्यू यूआरएल-एस्केप्ड स्पेलिंग का सुझाव, जिसे क्वेरी के लिए इस्तेमाल किया जा सकता है. | ||||||
| एट्रिब्यूट |
|
||||||
| उदाहरण | <सुझाव q="soccer">&lt;b&gt;&lt;i&gt;soccer&lt;/i&gt;&lt;/b&gt;</Suggestion> | ||||||
| इसका सब-टैग | स्पेलिंग | ||||||
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (HTML) | ||||||
| T | |
|---|---|
| परिभाषा | <T> टैग में टाइटल शामिल है दिखाई देती है. |
| उदाहरण | <T>अमीसी ईस्ट कोस्ट पिज़्ज़ेरिया</T> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (HTML) |
| title | |
|---|---|
| परिभाषा | <Context> का चाइल्ड होने के नाते, <Context> टैग में आपके Programmable Search Engine का नाम शामिल होता है. <Facet> के चाइल्ड टैग के तौर पर, <title> टैग, पहलुओं के सेट के लिए टाइटल उपलब्ध कराता है. |
| उदाहरण | <कॉन्टेक्स्ट> के बच्चे के तौर पर: <title>मेरी खोज Engine</title> <Facet> के बच्चे के तौर पर: <title>facet टाइटल</title> |
| इसका सब-टैग | कॉन्टेक्स्ट, फ़ेसेट |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट |
| TM | |
|---|---|
| परिभाषा | <TM> टैग, सर्वर के कुल समय की पहचान करता है की ज़रूरत नहीं होती, जिसे कुछ सेकंड में मापा जाता है. |
| उदाहरण | <TM>0.100445</TM> |
| इसका सब-टैग | GSP |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (फ़्लोटिंग-पॉइंट नंबर) |
| टीटी | |
|---|---|
| परिभाषा | <TT> टैग से खोज नतीजे मिलते हैं सलाह. |
| उदाहरण | <TT><i>Tip: ज़्यादातर लोगों के लिए ब्राउज़र में, रिटर्न कुंजी दबाने से वही परिणाम प्राप्त होते हैं, जो क्लिक करने पर खोज बटन.</i></TT> |
| इसका सब-टैग | GSP |
| U | |
|---|---|
| परिभाषा | <U> टैग आपको यूआरएल दिखाता है. |
| उदाहरण | <U>http://www.dominos.com/</U> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (निरपेक्ष URL) |
| UD | |
|---|---|
| परिभाषा | <UD> टैग, IDN-एन्कोडेड उपलब्ध कराता है खोज के नतीजे के लिए (इंटरनैशनल डोमेन नेम) यूआरएल. इस वैल्यू की मदद से, स्थानीय भाषाओं का इस्तेमाल करके दिखाए जाएंगे. उदाहरण के लिए, आईडीएन कोड में बदले गए यूआरएल http://www.%E8%8A%B1%E4%BA%95.com को डिकोड किया जा सकता है और http://www.花鮨.com के तौर पर दिखाया जा सकता है. इस <UD> टैग को सिर्फ़ इनके लिए खोज नतीजों में शामिल किया जाएगा ऐसे अनुरोध जिनमें ud पैरामीटर शामिल था. ध्यान दें: यह सुविधा बीटा वर्शन में है. |
| उदाहरण | <UD>http://www.%E8%8A%B1%E4%BA%95.com/</UD> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (आईडीएन से कोड में बदला गया यूआरएल) |
| UE | |
|---|---|
| परिभाषा | <UE> टैग से यूआरएल मिलता है दिखाता है. वैल्यू को यूआरएल एस्केप किया गया है, ताकि वह सही हो का इस्तेमाल करें. |
| उदाहरण | <UE>http://www.dominos.com/</UE> |
| इसका सब-टैग | दक्षिण |
| कॉन्टेंट का फ़ॉर्मैट | टेक्स्ट (यूआरएल-एस्केप्ड यूआरएल) |
| XT | |
|---|---|
| परिभाषा | <XT> टैग बताता है कि जैसा कि M टैग में बताया गया है, नतीजों की कुल अनुमानित संख्या से असल में परिणामों की कुल संख्या. अपने-आप अपडेट होने की सुविधा के बारे में जानें ज़्यादा जानकारी के लिए, इस दस्तावेज़ के सेक्शन को फ़िल्टर किया जा रहा है. |
| उदाहरण | <XT /> |
| इसका सब-टैग | रिज़ॉल्यूशन |
| कॉन्टेंट का फ़ॉर्मैट | खाली |
इमेज सर्च क्वेरी के लिए एक्सएमएल के नतीजे
इमेज के इस सैंपल में, खोज के लिए इस्तेमाल हुए शब्द "बंदर" के बारे में पांच नतीजे (num=5) मांगे गए हैं (q=बंदर).
http://www.google.com/cse? searchtype=image &num=2 &q=monkey &client=google-csbe &output=xml_no_dtd &cx=00255077836266642015:u-scht7a-8i
इस अनुरोध से नीचे दिया गया एक्सएमएल नतीजा मिलता है.
<GSP VER="3.2">
<TM>0.395037</TM>
<Q>monkeys</Q>
<PARAM name="cx" value="011737558837375720776:mbfrjmyam1g" original_value="011737558837375720776:mbfrjmyam1g" url_<escaped_value="011737558837375720776%3Ambfrjmyam1g" js_escaped_value="011737558837375720776:mbfrjmyam1g"/>
<PARAM name="client" value="google-csbe" original_value="google-csbe" url_escaped_value="google-csbe" js_escaped_value="google-csbe"/>
<PARAM name="q" value="monkeys" original_value="monkeys" url_escaped_value="monkeys" js_escaped_value="monkeys"/>
<PARAM name="num" value="2" original_value="2" url_escaped_value="2" js_escaped_value="2"/>
<PARAM name="output" value="xml_no_dtd" original_value="xml_no_dtd" url_escaped_value="xml_no_dtd" js_escaped_value="xml_no_dtd"/>
<PARAM name="adkw" value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" original_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" url_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A" js_escaped_value="AELymgUP4VYSok20wy9SeYczEZ5UXxpBmRsJH4oC4aXhVuZgwGKuponcNXjrYkkw2bRv1BylIm89ndJ-Q4vxvyW0tcbiqipcQC9op_cBG84T12WMvX8660A"/>
<PARAM name="hl" value="en" original_value="en" url_escaped_value="en" js_escaped_value="en"/>
<PARAM name="oe" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="ie" value="UTF-8" original_value="UTF-8" url_escaped_value="UTF-8" js_escaped_value="UTF-8"/>
<PARAM name="boostcse" value="0" original_value="0" url_escaped_value="0" js_escaped_value="0"/>
<Context>
<title>domestigeek</title>
</Context>
<ARES/>
<RES SN="1" EN="2">
<M>2500000</M>
<NB>
<NU>/images?q=monkeys&num=2&hl=en&client=google-csbe&cx=011737558837375720776:mbfrjmyam1g&boostcse=0&output=xml_no_dtd
&ie=UTF-8&oe=UTF-8&tbm=isch&ei=786oTsLiJaaFiALKrPChBg&start=2&sa=N
</NU>
</NB>
<RG START="1" SIZE="2"/>
<R N="1" MIME="image/jpeg">
<RU>http://www.flickr.com/photos/fncll/135465558/</RU>
<U>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</U>
<UE>
http://farm1.static.flickr.com/46/135465558_123402af8c.jpg
</UE>
<T>Computer <b>Monkeys</b> | Flickr - Photo Sharing!</T>
<RK>0</RK>
<BYLINEDATE>1146034800</BYLINEDATE>
<S>Computer <b>Monkeys</b> | Flickr</S>
<LANG>en</LANG>
<IMG WH="500" HT="305" IID="ANd9GcQARKLwzi-t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs">
<SZ>88386</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="130" HT="79" URL="http://t0.gstatic.com/images?q=tbn:ANd9GcQARKLwzi-
t4lpWi2AERV3kJb4ansaQzTn3MNDZR9fD_JDiktPKByKUBLs"/>
</R>
<R N="2" MIME="image/jpeg">
<RU>
http://www.flickr.com/photos/flickerbulb/187044366/
</RU>
<U>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</U>
<UE>
http://farm1.static.flickr.com/73/187044366_506a1933f4.jpg
</UE>
<T>
one. ugly. <b>monkey</b>. | Flickr - Photo Sharing!
</T>
<RK>0</RK>
<BYLINEDATE>1152514800</BYLINEDATE>
<S>one. ugly. <b>monkey</b>.</S>
<LANG>en</LANG>
<IMG WH="400" HT="481" IID="ANd9GcQ3Qom0bYbee4fThCQVi96jMEwMU6IvVf2b8K5vERKVw-
EF4tQQnDDKOq0"><SZ>58339</SZ>
<IN/>
</IMG>
<TBN TYPE="0" WH="107" HT="129" URL="http://t1.gstatic.com/images?q=tbn:ANd9GcQ3Qom0bYbee4fThCQ
Vi96jMEwMU6IvVf2b8K5vERKVw-EF4tQQnDDKOq0"/>
</R>
</RES>
</GSP>इमेज सर्च: एक्सएमएल टैग
नीचे दी गई टेबल में अतिरिक्त एक्सएमएल टैग दिए गए हैं, जिनका इस्तेमाल इमेज सर्च क्वेरी के लिए एक्सएमएल जवाबों में किया जाता है.
कुछ सब-टैग के आगे कुछ सिंबल दिखाए जा सकते हैं नीचे दी गई परिभाषाएं देखें. ये निशान और उनके मतलब इस तरह से हैं:
* = सब-टैग
के शून्य या इससे ज़्यादा इंस्टेंस + = सब-टैग
के एक या इससे ज़्यादा इंस्टेंस
| RG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| परिभाषा | <RG> टैग में किसी इमेज के खोज नतीजों की जानकारी दिखती है. |
|||||||||
| एट्रिब्यूट |
| |||||||||
| इसका सब-टैग | रिज़ॉल्यूशन | |||||||||
| रूस | |
|---|---|
| परिभाषा | <RU Tag> टैग में, इमेज के हर खोज नतीजे की जानकारी शामिल होती है. |
| इसका सब-टैग | दक्षिण |