
Google Docs API を使用すると、ドキュメントの任意のタブからコンテンツにアクセスできます。
タブとは
Google ドキュメントには、タブと呼ばれる組織レイヤがあります。ドキュメントでは、現在のスプレッドシートのタブと同様に、1 つのドキュメント内に複数のタブを作成できます。各タブには、独自のタイトルと ID があります(URL に追加されます)。タブには子タブを設定することもできます。子タブは、別のタブの下にネストされたタブです。
ドキュメント コンテンツがドキュメント リソースでどのように表現されるかの構造的な変更
以前のドキュメントにはタブの概念がなかったため、Document リソースには、次のフィールドを介してすべてのテキスト コンテンツが直接含まれていました。
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
タブの構造階層が追加されたため、これらのフィールドはドキュメント内のすべてのタブのテキスト コンテンツを意味的に表さなくなりました。テキストベースのコンテンツは別のレイヤで表現されるようになりました。Google ドキュメントのタブのプロパティとコンテンツには、document.tabs を使用してアクセスできます。これは Tab オブジェクトのリストで、各オブジェクトには前述のテキスト コンテンツ フィールドがすべて含まれています。以降のセクションでは概要を説明します。タブの JSON 表現でも詳細な情報を提供しています。
[Access] タブのプロパティ
tab.tabProperties を使用してタブのプロパティにアクセスします。これには、タブの ID、タイトル、位置などの情報が含まれます。
タブ内のテキスト コンテンツにアクセスする
タブ内の実際のドキュメント コンテンツは tab.documentTab として公開されます。上記のテキスト コンテンツ フィールドはすべて、tab.documentTab を使用してアクセスできます。たとえば、document.body ではなく document.tabs[indexOfTab].documentTab.body を使用します。
タブの階層
子タブは、API では Tab の tab.childTabs フィールドとして表されます。ドキュメント内のすべてのタブにアクセスするには、子タブの「ツリー」をたどる必要があります。たとえば、次のようなタブ階層を含むドキュメントについて考えてみましょう。
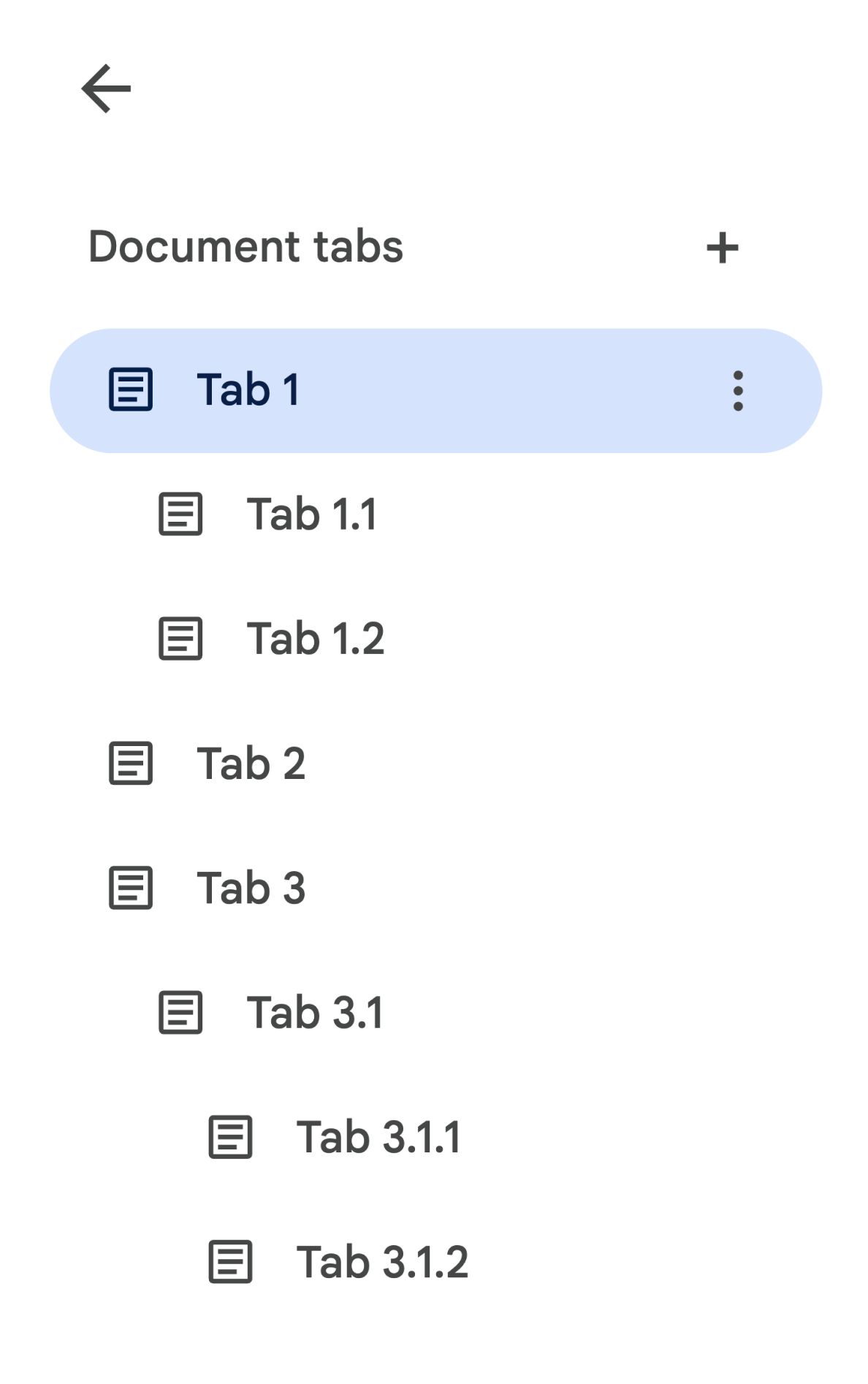
Tab 3.1.2 から Body を取得するには、document.tabs[2].childTabs[0].childTabs[1].documentTab.body にアクセスします。後述のサンプルコード ブロックを参照してください。このブロックには、ドキュメント内のすべてのタブを反復処理するサンプルコードが用意されています。
メソッドの変更
タブの導入に伴い、ドキュメント メソッドのそれぞれにいくつかの変更が加えられました。コードの更新が必要になる場合があります。
documents.get
デフォルトでは、すべてのタブの内容が返されるわけではありません。すべてのタブにアクセスするには、コードを更新する必要があります。documents.get メソッドは、すべてのタブのコンテンツをレスポンスで提供するかどうかを構成できる includeTabsContent パラメータを公開します。
includeTabsContentがtrueに設定されている場合、documents.getメソッドはdocument.tabsフィールドが入力されたDocumentリソースを返します。documentに直接あるテキスト フィールド(document.bodyなど)はすべて空のままになります。includeTabsContentが指定されていない場合、Documentリソース(document.bodyなど)のテキスト フィールドには、最初のタブのコンテンツのみが入力されます。document.tabsフィールドは空になり、他のタブのコンテンツは返されません。
documents.create
documents.create メソッドは、作成された空のドキュメントを表す Document リソースを返します。返された Document リソースは、ドキュメントのテキスト コンテンツ フィールドと document.tabs の両方で、空のドキュメント コンテンツを設定します。
document.batchUpdate
各 Request には、更新を適用するタブを指定する方法が含まれています。デフォルトでは、タブが指定されていない場合、ほとんどの場合、Request はドキュメントの最初のタブに適用されます。ReplaceAllTextRequest、DeleteNamedRangeRequest、ReplaceNamedRangeContentRequest は 3 つの特別なリクエストで、代わりにすべてのタブに適用されるようデフォルト設定されます。
詳しくは、Request のドキュメントをご覧ください。
内部リンクの変更
ドキュメント内のタブ、ブックマーク、見出しへの内部リンクを作成できます。タブ機能の導入により、Link リソースの link.bookmarkId フィールドと link.headingId フィールドは、ドキュメント内の特定のタブのブックマークや見出しを表すことができなくなりました。
デベロッパーは、読み取りオペレーションと書き込みオペレーションで link.bookmark と link.heading を使用するようにコードを更新する必要があります。内部リンクは BookmarkLink オブジェクトと HeadingLink オブジェクトを使用して公開されます。各オブジェクトには、ブックマークまたは見出しの ID と、それが配置されているタブの ID が含まれています。また、link.tabId はタブへの内部リンクを公開します。
documents.get レスポンスのリンクの内容は、includeTabsContent パラメータによっても異なります。
includeTabsContentがtrueに設定されている場合、すべての内部リンクがlink.bookmarkとlink.headingとして公開されます。以前のフィールドは使用されなくなります。includeTabsContentが指定されていない場合、単一のタブを含むドキュメントでは、その単一のタブ内のブックマークまたは見出しへの内部リンクは引き続きlink.bookmarkIdおよびlink.headingIdとして公開されます。複数のタブを含むドキュメントでは、内部リンクはlink.bookmarkとlink.headingとして公開されます。
document.batchUpdate で、以前のフィールドのいずれかを使用して内部リンクが作成された場合、ブックマークまたは見出しは Request で指定されたタブ ID からのものとみなされます。タブが指定されていない場合は、ドキュメントの最初のタブからとみなされます。
リンクの JSON 表現には、より詳細な情報が記載されています。
タブの一般的な使用パターン
次のコードサンプルは、タブを操作するさまざまな方法を示しています。
ドキュメント内のすべてのタブからタブの内容を読み取る
タブ機能の前にこれを行っていた既存のコードは、includeTabsContent パラメータを true に設定し、タブツリー階層をトラバースし、Document の代わりに Tab と DocumentTab からゲッター メソッドを呼び出すことで、タブをサポートするように移行できます。次のコードサンプルの一部は、ドキュメントからテキストを抽出するのスニペットに基づいています。ドキュメントのすべてのタブのテキスト コンテンツを印刷する方法を示します。このタブ トラバーサル コードは、タブの実際の構造を気にしない他の多くのユースケースに適用できます。
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
ドキュメントの最初のタブからタブの内容を読み取る
これは、すべてのタブを読み取るのと同様です。
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
最初のタブを更新するリクエストを作成する
次のコードサンプルの一部は、Request で特定のタブをターゲットにする方法を示しています。このコードは、テキストの挿入、削除、移動ガイドのサンプルに基づいています。
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }