C++ 语言教程
本课程的早期部分是 教程 涵盖已经介绍的基本资料 并进一步介绍高级概念。我们的 本单元的重点是动态内存,以及有关对象和类的更多详情。 我们还介绍了一些高级主题,如继承、多态、模板 异常和命名空间我们稍后会在高级 C++ 课程中研究这些内容。
面向对象的设计
这是一个非常好 教程。我们会将 介绍的方法。
通过示例 3 进行学习
本单元重点介绍如何使用指针进行面向对象的更多练习 设计、多维数组和类/对象。请完成以下操作 示例。我们要特别强调,要成为一名优秀程序员,关键是 就是练习、练习、再练习!练习 1:使用指针进行更多练习
如果您需要更多练习使用指针,请通读 这个 资源,该文档涵盖了指针的所有方面,并提供了许多程序示例。
以下程序的输出是什么?请勿运行该程序,但 绘制内存图片以确定输出。
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}手动确定输出后,运行程序以查看 正确。
练习 2:更多地使用类和对象进行练习
如果你需要进一步练习使用类和对象, 此处 是实现两个小类的资源。采纳一些 并完成练习。
练习 3:多维数组
请参考以下计划:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}此程序中有一行标记为“How does this line work?”(此行的工作原理是什么?) - 你能明白吗? 您可以在此处查看相关说明。
编写一个程序,用于初始化三维数组并填充第三维 值的总和。 点击此处即可了解我们的解决方案。
练习 4:详细的 OO 设计示例
这里是 面向对象的设计示例,其中介绍了 完整流程。最终代码是使用 Java 编写的 但您可以参考它学得有多远 来了。
请花点时间了解整个示例。非常棒 以及支持该过程的设计工具。
单元测试
简介
测试是软件工程流程中的关键一环。单元测试 是一种特定的测试,用于检查单个小型 是源代码模块单元测试始终由工程师完成, 通常在对模块进行编码时完成。您测试的 用于测试 Composer 和 Database 类都属于单元测试。
单元测试具有以下特征。他们...
- 单独测试组件
- 是确定性的
- 通常会映射到单个类
- 避免依赖于外部资源,例如数据库、文件、网络
- 快速执行
- 可按任意顺序运行
有一些自动化框架和方法可以 以便确保大型软件工程组织中的单元测试保持一致。 有一些复杂的开源单元测试框架, 我们会在本课程稍后的部分中
作为单元测试的一部分进行的测试如下所示。

在理想情况下,我们会对以下内容进行测试:
- 测试模块接口,以确保信息流入和流出 正确。
- 检查本地数据结构,确保正确存储数据。
- 测试边界条件,以确保模块正常运行 以限制处理
- 我们会测试模块的独立路径,以确保每条路径均可用;
因此模块中的每条语句至少会执行一次。
- 最后,我们需要检查错误是否已得到正确处理。
代码覆盖率
实际上,我们无法实现完全的“代码覆盖率”。 代码覆盖率是一种分析方法,用于确定软件的哪些部分 已由测试用例套件执行(覆盖)了,哪些部分 尚未执行。如果我们尝试实现 100% 覆盖率,则会花费更多的时间 比编写实际代码更复杂!考虑提供单元 测试以下所有独立路径。这可能会很快成为 指数题。
在此图中,未测试红线,而未测试无色线 测试。
我们并非尝试 100% 覆盖率,而是专注于可以提高置信度的测试 该模块可正常运行。我们会针对以下方面进行测试:
- null 情况
- 范围测试,例如正/负值测试
- 边缘用例
- 故障案例
- 测试最可能执行的路径
单元测试框架
在代码执行期间,大多数单元测试框架都使用断言来测试值 路径。断言是检查条件是否成立的语句。通过 结果可以是成功、非严重失败或严重失败。更新后 则执行断言,如果结果为 成功或非严重失败如果发生严重故障,当前函数 已中止。
测试由用于设置状态或操纵模块的代码组成, 以及许多用于验证预期结果的断言。如果所有断言 如果返回 true,则测试成功;否则 就会失败
一个测试用例包含一个或多个测试。我们将测试划分为不同的测试用例 反映所测试代码的结构。在本课程中,我们将使用 CPPUnit 作为我们的单元测试框架。借助此框架,我们可以编写单元测试 并自动生成,并提供关于成功或失败的报告 测试。
CPPUnit 安装
从以下位置下载 CPPUnit 代码: SourceForge。 找到相应的目录并将 tar.gz 文件放在该目录中。然后,输入 以下命令(在 Linux、Unix 中),替换成相应的 cppunit 文件 名称:
gunzip filename.tar.gz tar -xvf filename.tar
如果您使用的是 Windows,则可能需要寻找一个实用程序来解压 tar.gz 文件。下一步是编译库。切换到 cppunit 目录。 其中提供了 INSTALL 文件,该文件提供了具体说明。通常 您需要运行以下命令:
./configure make install
如果您遇到问题,请参阅 INSTALL 文件。这些库通常是 (位于 cppunit/src/cppunit 目录中)。要检查编译是否有效, 进入 cppunit/examples/simple 目录并输入“make”如果 一切正常,就说明大功告成了。
我们提供了一个非常实用的教程 此处。 请浏览本教程,创建复数类及其关联的 单元测试。cppunit/examples 目录中还有其他几个示例。
为什么一定要这样做??
出于多种原因,单元测试在行业中至关重要。您 一个原因是在访问网站时, 开发代码。即使我们开发了一个非常小的程序,我们也会本能地 编写某种检查工具或驱动程序,确保程序按预期运行。
工程师根据长期经验,深知程序行之有效 都非常小。单元测试是基于上述想法构建的, 程序自检和可重复。断言会取代 检查输出。而且,由于可以轻松解读结果(测试 通过或失败),可以反复运行测试,从而提供 使您的代码更适应更改情况的安全网。
我们具体来说一下:当您首次将完成的代码提交到 CVS 格式,完美无瑕而且在一段时间内,它仍会正常运行。然后 有一天,其他人更改了您的代码。迟早会有人遇到 您的代码。他们会自己注意到吗?不太可能。但当您 编写单元测试时,有些系统可以每天自动运行它们。 这些系统称为持续集成系统。所以当这个工程师 X 破坏了您的代码,在问题得以解决之前,系统会向他们发送令人厌烦的电子邮件 。就算工程师 X 就是你!
除了帮助您开发软件,以及确保软件安全 因此,单元测试
- 创建可执行规范和保持同步的文档 以及代码。换言之,您可以通过查看单元测试来了解 该模块支持的行为。
- 可帮助您将要求与实现分离开来。因为您要声明 因此,您有机会明确地审视 而不是混杂有关如何实现该行为的想法。
- 支持实验。如有安全网提醒 您破坏了模块的行为,就更有可能 并重新配置您的设计。
- 改进您的设计。编写全面的单元测试通常需要 提高代码的可测试性可测试代码的模块化通常比不可测试的代码更模块化 代码。
- 保持高品质。关键系统中的一个小错误就可能导致企业 损失数百万美元,更糟糕的是,还会导致用户满意度或信任度降低。通过 可以降低这种可能性。通过捕捉虫子 它们还可让 QA 团队将时间花在更复杂、更难的 而不是报告明显的故障
请花些时间使用 CPPUnit 为 Composer 数据库应用编写单元测试。 如需帮助,请参阅 cppunit/examples/ 目录。
Google 的运作方式
简介想象一下中世纪的一位僧侣在看 他修道院的档案“那是亚里士多德的那首歌在哪儿...”

幸运的是,这些手稿按内容分类和刻字, 并带有特殊符号,以方便对 。如果没有这种组织方式,就很难找到相关的 手稿。
存储和检索大型集合中的书面信息的活动 称为信息检索 (IR)。如今,这一活动越来越多 这在几个世纪以来都有着举足轻重的地位,尤其是纸质和印刷品等发明 按。以前只有少数人上场。现在, 然而,却每天都有数以亿计的人 使用搜索引擎或在桌面上搜索。
信息检索入门

苏斯博士在 30 年的时间里撰写了 46 本儿童图书。他讲的书 包括猫、牛和大象,还有各种笑容和笑容的洛拉克斯星。你记得吗 哪个故事中涉及哪些生物?除非您是家长,否则只有孩子可以 告诉你哪组苏斯博士的故事中到处都是怪物:
(COW 和 BEE)或 CROWS
我们将应用一些经典的信息检索模型来帮助解决此问题 问题。
一种显而易见的方法就是使用暴力破解:获取苏斯博士的 46 个故事,然后开始 阅读。对于每本图书,记下哪本书包含 COW 和 BEE 一词,以及 同时查找包含字词“CROWS”的图书。计算机就像是 在这方面要比现在快如果我们能找到苏斯博士的著作中的所有文字 例如文本文件,我们只需通过 grep 命令浏览文件。对于 苏斯博士的书籍等小藏品,这种技术就很有效。
然而,在很多情况下,我们需要更多模型。例如, 目前在线的所有数据中,有 50% 过大,无法用 grep 处理。我们也不会 只希望与条件匹配的文档,我们已经习惯了 根据相关性对它们进行排名
除了 grep 之外,还有一种方法是为集合中的文档创建索引。 。IR 中的索引类似于 我们会列出每个字词中的所有字词(也称“字词”) 苏斯博士的故事,省去了“的”“和”等关联词, 介词等(这些称为停止词)。然后,我们使用 以便于您查找相关条款和识别 以及他们讲述的故事
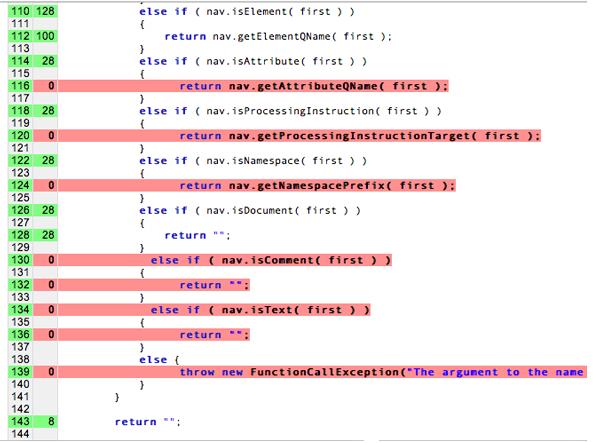
一种可能的表示形式是顶部显示故事的矩阵, 每行列出的一些字词列中的“1”表示该字词出现 。
我们可以将每行或每列视为一个位矢量。行的位矢量表示 字词出现在哪些故事中。列的位矢量表示 出现在故事中。
回到我们的原始问题:
(COW 和 BEE)或 CROWS
我们针对这些项取位矢量,先执行按位 AND,然后执行 对结果进行按位或运算。
(100001 和 010011)或 000010 = 000011
答案是:“棕色 Can Moo!你能吗?”和《The Lorax》这是一张插图 布尔值检索模型模型属于“完全匹配”模型。
假设我们要扩展矩阵,将苏斯博士的所有故事和 在故事中加入相关的字词。矩阵将会大幅增长,而一个重要的 大多数条目为 0。矩阵可能不是最好的 索引的表示法。我们需要找到一种方法来存储 1。
一些增强功能
IR 中用于解决此问题的结构称为“反转索引”。 我们维护着一个字词字典,然后针对每个字词生成一个列表 ,其中记录了出现该字词的文档。此列表称为帖子 列表。单链接列表可以很好地代表此结构,如下所示 。
如果您不熟悉链接列表,只需在 Google 搜索结果中的“linked”(链接)
列表,您可以找到许多关于如何创建此类代码的资源,
及其使用方式我们将在后面的单元中对此进行更详细的介绍。
请注意,我们使用文档 ID (DocIDs),而不是 故事。我们还会对这些 DocID 进行排序,因为它有助于处理查询。
我们如何处理查询?对于原始问题,我们首先找到 COW 帖子 列出,然后是 BEE 发帖列表。然后,我们将它们“合并”在一起:
- 在两个列表中保留标记,并浏览两个帖子列表 。
- 在每个步骤中,比较两个指针所指向的 DocID。
- 如果它们相同,则将该 DocID 放入结果列表中,否则将指针移到 指向较小的 docID。
构建倒排索引的方法如下:
- 为每个相关文档分配一个 DocID。
- 对于每个文档,确定其相关字词(词元化)。
- 对于每个术语,创建一个记录,该记录包含术语及其所在的 DocID 以及该文档中的频率。请注意 特定字词的记录。
- 按字词对记录进行排序。
- 通过处理 的单个记录来创建字典和帖子列表 同时将出现在更多字词中的字词的多个记录合并在一起 多个文档。创建 DocID 的链接列表(按排序顺序)。每个 字词还具有一个频率,也就是所有记录的频率之和 指定字词。
项目
查找几个可以试验的冗长明文文档。通过 使用上述算法根据文档创建倒排索引, 。您还需要创建一个查询输入界面 以及处理它们的引擎。您可以在论坛上找到项目合作伙伴。
以下是完成此项目的可能流程:
- 首先要定义一个策略来识别文档中术语。 列出你能想到的所有停用词,并编写一个函数, 通读文件中的词语、保存词语并消除无效词。 在查看列表时,您可能需要向列表中添加更多无效搜索字词。 从迭代中生成字词。
- 编写 CPPUnit 测试用例来测试您的函数,并编写 makefile 来将所有 帮助您构建应用将文件签入 CVS 格式,尤其是在 合作伙伴。您可能需要研究如何打开 CVS 实例 远程工程师使用
- 添加处理以包含位置数据,即哪个文件及其位置 文件名。您可能想通过一个计算来定义 页码或段落编号。
- 编写 CPPUnit 测试用例来测试此附加功能。
- 创建一个倒置索引,并将位置数据存储在每个术语的记录中。
- 编写更多测试用例。
- 设计一个允许用户输入查询的界面。
- 使用上述搜索算法,处理反向索引和 将位置数据返回给用户。
- 请务必也为最后这一部分添加测试用例。
正如我们对所有项目所做的那样,请在论坛和聊天功能中寻找项目合作伙伴 并分享想法
额外功能
在许多 IR 系统中,一个常见的处理步骤称为“词干提取”。通过 词干提取的主要理念是,用户在搜索有关“检索”的信息时 还会对包含“检索”、 “retrieved”“retrieve”等。系统很容易由于以下原因 词干提取不当,所以这有点棘手。例如,某个用户对 在“信息检索”中,可能就会得到一个标题为“黄金信息” 研究结果。用于词干提取的实用算法是 波特算法。