编程和 C++ 简介
此在线教程还介绍了更多高级概念,请阅读第 III 部分。本单元的重点是如何使用指针以及如何开始使用对象。
通过示例 2 进行学习
本单元重点介绍如何进行分解、理解指针以及如何开始使用对象和类。请查看以下示例。在需要时自行编写程序,或者自己做实验。成为一名优秀程序员的关键在于练习、练习、练习!
示例 1:更多分解练习
我们来考虑一个简单游戏的以下输出:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
第一个观察结果是介绍性文字,每个节目会显示一次 执行。我们需要一个随机数生成器来定义敌方 一轮。我们需要一种从玩家获取角度输入的机制, 很明显,它处于循环结构中,因为它会一直重复,直到我们击中敌人为止。我们还 需要一个函数来计算距离和角度。最后,我们必须 可以看出我们打出了多少射击,以及我们拥有多少敌人 触发。以下是可能的主程序概要。
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
“Fire”程序负责处理游戏过程。在该函数中,我们调用 然后使用随机数生成器获取敌方距离 然后设置循环 获取玩家的输入并计算他们是否击中了敌人。通过 循环中的守卫条件就是我们与敌人的距离有多近
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
由于会调用 cos() 和 sin(),因此您需要添加 math.h。试试看 编写这个程序,这是进行问题分解的好办法, 基本 C++ 回顾。请记住,在每个函数中只执行一项任务。这是 因此,使用我们编写的最复杂的程序, 做到这一点。点击此处即可了解我们的解决方案。
示例 2:使用指针练习
使用指针时,请注意以下四点: <ph type="x-smartling-placeholder">- </ph>
- 指针是用于存储内存地址的变量。在程序执行过程中
所有变量都存储在内存中,每个变量都有自己唯一的地址或位置。
指针是一种特殊类型的变量,它包含内存地址,
比数据值更高。就像使用普通变量时数据会修改一样,
存储在指针中的地址值被修改为指针变量
被操纵示例如下:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - 我们通常将指针“指向”它存储的位置
(“指控对象”)。因此,在上面的示例中,intptr 指向指针
5.
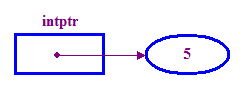
请注意使用“new”运算符来为整数分配内存 指尖的。我们必须先完成这项操作,才能尝试接触目标对象。
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.C 语言中的 * 运算符用于解引用。最常见的错误之一 C/C++ 程序员在使用指针时会忘记初始化 目标对象。这有时会导致运行时崩溃,因为我们正在访问 内存中包含未知数据的位置。如果我们尝试修改 数据,我们可能会导致轻微的内存损坏,使之成为难以跟踪的错误。
- 两个指针之间的指针赋值会使它们指向同一个指针。
因此,赋值 y = x;使 y 指向与 x 相同的目标对象。指针分配
没有碰到指针。它只是将一个指针更改为具有相同位置
作为另一点指针指针分配后,两个指针会“共享”该
指尖的。
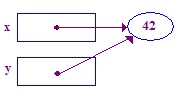
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
此代码的轨迹如下:
| 1. 分配两个指针 x 和 y。指针的分配 不会分配任何指针。 | 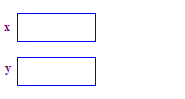 |
| 2. 分配一个指针,并将 x 设为指向它。 | 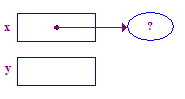 |
| 3. 解引用 x 以将 42 存储在其指针中。这是一个基本示例 解引用操作的过程从 x 开始,跟随箭头访问 目标对象。 | 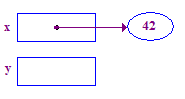 |
| 4. 尝试解除对 y 的引用,以便将 13 存储在其指针中。此崩溃的原因是: 没有指引者 -- 从未被分配。 | 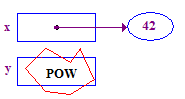 |
| 5. 指定 y = x;使 y 指向 x 的点。现在,x 和 y 指向 也就是同一个目标 - 它们在“共享”中。 | 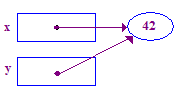 |
| 6. 尝试解除对 y 的引用,以便将 13 存储在其指针中。这次成功了 因为上一项作业给了你指点。 | 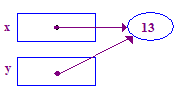 |
如您所见,图片对于理解指针的用法非常有用。以下是 另一个示例。
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
请注意,在此示例中,我们从未将“new”运算符。 我们声明了一个常规整数变量,并通过指针操纵它。
在本示例中,我们说明了如何使用删除运算符 堆内存,以及如何为更复杂的结构分配内存。我们将介绍以下内容: 内存组织(堆和运行时堆栈)。目前,仅 您可以将堆视为可供运行程序使用的可用内存空间
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
在最后一个示例中,我们将展示如何使用指针通过引用传递值 一个函数。这就是我们修改函数中变量值的方式。
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
如果我们要去掉“Duplicate 函数”定义中的参数“&”后面的部分, 我们将“按值”传递变量,也就是说, 变量。对函数中的变量所做的任何更改都会修改副本。 它们不会修改原始变量。
当变量通过引用传递时,我们不会传递其值的副本, 而是将变量的地址传递给函数。任何 对局部变量所做的修改实际上会修改传入的原始变量。
如果您是 C 语言程序员,这会是一个新的转折点。我们可以在 C 代码中执行相同的操作, 声明 Duplicate() 为 Duplicate(int *x), 在此例中是 x 是指向一个 int 的指针,然后使用参数 &x (x 的地址)调用 Duplicate(),并使用 x 不超过 Duplicate() (见下文)。但是,C++ 提供了一种更简单的方式来向函数传递值,即 虽然之前的“C”但仍然适用。
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
请注意,对于 C++ 引用,我们不需要传递变量的地址, 我们需要对调用的函数中的变量进行解引用操作吗?
以下程序会输出什么内容?画一张回忆图即可找出答案。
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} 运行程序,看看答案是否正确。
示例 3:通过引用传递值
编写一个名为 speed() 的函数,该函数将车辆的速度和速度作为输入。函数将相应的速度值与速度相加,以加快车辆的加速速度。speed 参数应通过引用传递,金额通过值传递。点击此处即可了解我们的解决方案。
示例 4:类和对象
请参考以下类:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
请注意,类成员变量的尾部带有下划线。这样做是为了区分局部变量和类变量。
向此类添加一个递减方法。点击此处即可了解我们的解决方案。
科学的奇迹:计算机科学
练习
与本课程的第一单元一样,我们不为练习和项目提供解决方案,
谨记一个好的计划...
... 逻辑上分解为函数,其中任何一个函数 执行且仅执行一项任务。
有一个主程序,看起来像是程序将做什么的概述。
...具有描述性的函数、常量和变量名称。
... 使用常量来避免产生“魔法”编码。
...它具有友好的用户界面。
热身锻炼
- 练习 1
整数 36 有一个奇特的属性:完全平方数, 从 1 到 8 的整数的总和。下一个数字是 1225 是 352,以及从 1 到 49 的整数的总和。查找下一个号码 是完全平方数,也是数列 1...n 的总和。下一个号码 可能会大于 32767。您可以使用自己熟悉的库函数 (或数学公式)来提升程序的运行速度。还有一种可能 使用 for 循环编写此程序,以确定数字是否完美无误 数的平方或之和。(注意:根据您的机器和程序, 可能要过很长时间才能找到这个数字)。
- 练习 2
你的大学书店需要你帮助估算未来业务 。经验表明,销售额在很大程度上取决于是否需要图书 课程还是可选课程,以及课程中是否使用过 。一本必学的新教科书会面向 90% 的潜在入学者销售, 但如果之前在课堂中使用过,只有 65% 的人会购买。同样, 40% 的潜在入学者会购买一本新的可选教科书,但 在类别中使用过,只有 20% 会购买。(请注意,此处的“二手” 并不是指二手书。)
编写一个程序,使其接受一系列图书(直到用户进入 一个哨兵)。对于要求提供的每本图书:图书代码,单本费用 图书、现有图书数量、潜在课程注册人数、 以及表明图书是必填项/选填项、是新书还是过去使用过的数据。如 输出,在格式美观的屏幕中显示所有输入信息, 必须订购多少本图书(如果有,请注意只订购新书)、 每笔订单的总费用
然后,在所有输入完成后,显示所有图书订单的总费用, 如果商店支付定价的 80%,则代表预期利润。由于我们还没有 讨论了处理加入程序的大量数据的各种方法(留下 调整!),一次仅处理一本图书,并显示该图书的输出屏幕。 然后,当用户输入完所有数据后,您的程序应会输出 总价值和利润价值
在开始编写代码之前,请花些时间考虑一下此程序的设计。 分解为一组函数,并创建一个类似于以下内容的 main() 函数: 概述你解决问题的方法。确保每个函数执行一项任务。
输出示例如下:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
数据库项目
在此项目中,我们创建一个功能齐全的 C++ 程序,实现一个简单的 数据库应用
通过该计划,我们可以管理作曲家和相关信息的数据库 。该计划的特色包括:
- 能够添加新作曲者
- 对作曲家进行排名(即表明我们有多喜欢或多不喜欢)的功能 作曲家的音乐)
- 能够查看数据库中的所有作曲家
- 能够按等级查看所有作曲家
“构建 软件设计:一种方法是把软件设计得简单一点, 而另一方面则是使其变得非常复杂 都没有明显的不足之处第一种方法要难得多。”- C.A.R. Hoare
我们中的很多人都学习了如何使用“程序设计”方法。 首先,我们的核心问题是“程序必须做什么?”。周三 将问题的解决方案分解为多个任务,每项任务可以解决一部分 问题。这些任务映射到程序中的函数,这些函数被依序调用 或其他函数。这种分步方法非常适合 需要解决的问题。但通常情况下,我们的程序不仅是线性的, 任务或事件序列。
采用面向对象的 (OO) 方法时,我们首先要问一个问题, “对象是建模对象?”它不应该像描述那样将程序划分为多个任务 我们将它划分为多个实物模型。这些实物具有 由一组属性定义的状态,以及一组 性能这些操作可能会更改对象的状态 调用其他对象的操作。基本前提是,对象“知道”方式 能够独立完成任务
在 OO 设计中,我们根据类和对象定义物理对象;属性 和行为。OO 程序中通常包含大量对象。 不过,其中许多对象本质上是相同的。请考虑以下要点。
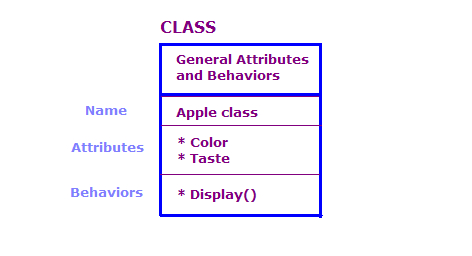
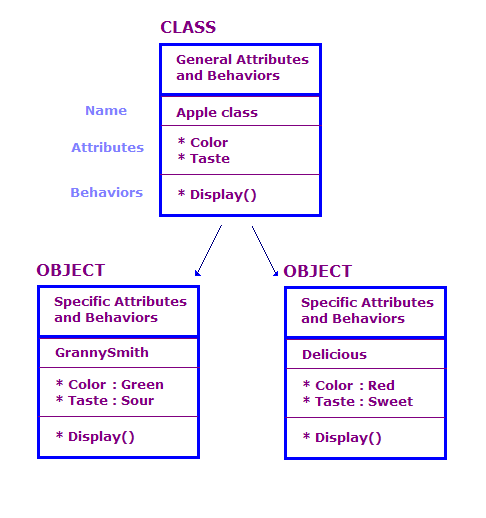
在此图中,我们定义了两个属于 Apple 类的对象。 每个对象都与类具有相同的属性和操作,但对象 定义了特定类型苹果的属性。此外,展示广告系列 操作会显示该特定对象的属性,例如 “绿色”和“Sour”
OO 设计由一组类、与这些类相关联的数据、 以及类可以执行的操作集。我们还需要确定 不同类别的互动方式。这种交互可以通过 某个类的调用。例如,我们 可以有一个 AppleOutputer 类输出数组的颜色和品味 方法是调用每个 Apple 对象的 Display() 方法。
以下是我们在进行 OO 设计时执行的步骤:
- 确定类,并大致定义每个类的对象 存储为数据以及对象的功能
- 定义每个类的数据元素
- 定义每个类的操作,以及一个类的某些操作的定义
其他相关类的操作实现的。
对于大型系统,这些步骤以不同的详细级别以迭代方式执行。
对于混合渲染器数据库系统,我们需要一个 Composer 类,用于封装所有 我们希望存储在单个 Composer 中的数据。此类的对象可以 提升或降位(更改其排名)和展示其属性。
我们还需要一个 Composer 对象的集合。为此,我们定义了一个 Database 类 用于管理各条记录此类的对象可以添加或检索 Composer 对象,并通过调用 一个 Compose 对象
最后,我们需要通过某种界面来提供交互式操作, 数据库这是一个占位符类,也就是说,我们真的不知道 看上去像现在一样,但我们确实需要这样一个。不确定 将会是图形内容的,也可能是基于文本的现在,我们定义一个占位符 供稍后填写
现在,我们已经确定了编辑器数据库应用的类, 下一步是定义类的属性和操作。在 就要坐下来,我们会使用铅笔和纸 UML 或 CRC 卡 或 OOD 绘制出类层次结构以及对象的交互方式。
对于编辑器数据库,我们定义一个 Composer 类,其中包含 每个 Composer 中要存储的数据。它还包含 排名和显示数据
Database 类需要某种结构来保存 Composer 对象。 我们需要能够向结构添加新的 Composer 对象 检索特定的 Composer 对象。我们还想显示所有对象 按参与顺序或排名
User Interface 类会实现菜单驱动的界面,其中包含 Database 类中的调用操作。
如果这些类易于理解且其属性和操作清晰明确, 与在 Composer 应用中一样,设计类相对比较简单。但是 如果您对课程之间的关系和互动方式有任何疑问, 最好先写出来,然后在开始之前仔细研究所有细节 编码。
对设计有清晰的认识并进行评估后, ),我们要为每个类定义接口。我们不负责实现 例如,属性和操作是什么,哪些部分 课程的状态和操作也可供其他类使用
在 C++ 中,我们通常通过为每个类定义头文件来实现此目的。作曲家 类包含我们要在 Composer 中存储的所有数据的私有数据成员。 我们需要访问器(“get”方法)和赋值器(“set”方法),以及 类主要操作
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Database 类也很简单。
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
请注意,我们如何将特定于 Composer 的数据仔细封装在单独的 类。我们可以在 Database 类中放置一个结构体或类,用来表示 Composer 记录,然后直接在该位置访问该记录。但这将是 “目标化不足”,即我们没有像使用对象那样 尽可能地找到它
在开始实现 Composer 和 Database 的过程中,您会看到 使用单独的 Composer 类会更清晰。具体来说, 对 Composer 对象使用单独的原子操作可以极大地简化实现 Display() 方法列表。
当然,还有一种“过度客观化”的情况其中 我们尝试让一切都成为一个类,或者拥有的类超出了所需数量。需要 找到合适的平衡点, 会各有不同。
通过谨慎行事,您可以确定自己是过度目标化还是目标性不足,通常可以通过 绘制类的示意图如前所述,要构建一个类, 这可以帮助您分析自己的方法。常见 用于该用途的记数法为 UML(统一建模语言) 现在我们已经为 Composer 和 Database 对象定义了类,接下来需要 供用户与数据库进行交互的界面。一个简单的菜单 具体做法:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
我们可以将界面实现为类或过程程序。非 C++ 程序中的所有内容都必须是类。事实上,如果处理是依序处理的 或任务导向型的,如本菜单程序中那样,可以按程序实现。 实现代码时务必要让它始终是“占位符” 也就是说,如果我们想要在某个时间点创建图形界面 您不必对系统进行任何更改,只需更改界面即可。
为完成应用,我们最后需要一个用于测试类的程序。 对于 Composer 类,我们需要一个 main() 程序,该程序可接受输入、填充 Composer 对象,然后显示该对象以确保该类正常运行。 我们还希望调用 Composer 类的所有方法。
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
我们需要为 Database 类提供一个类似的测试程序。
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
请注意,这些简单的测试程序是很好的第一步, 手动检查输出,确保程序正常运行。如 系统越大,人工检查输出就变得不切实际了。 在后续课程中,我们将以 单元测试。
我们的应用设计现已完成。下一步是 类和界面的 .cpp 文件。首先 将上述 .h 和测试驱动程序代码复制/粘贴到文件中,并对其进行编译。使用 测试驱动程序,以测试您的类。然后,实现以下接口:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
使用您在 Database 类中定义的方法实现界面。 确保您的方法不会出错。例如,排名应始终在 1-10。也不要让任何人添加 101 位作曲家,除非您打算更改 Database 类中的数据结构。
请记住,所有代码都需要遵循我们的编码规范, 此处:
- 我们编写的每个程序都以标头注释开头,并提供 作者、他们的联系信息、简短说明和用法(如果相关)。 每个函数/方法都以操作和用法注释开头。
- 只要代码与代码相同,我们都会使用完整的句子添加说明性注释。 而非文档本身。例如,如果处理过程较为复杂且不明显, 有趣或重要。
- 始终使用描述性名称:变量是小写字词,以 _(例如 my_variable)。函数/方法名称使用大写字母来标记 如 MyExcitingFunction() 所示。常量以“k”开头和 使用大写字母标记字词,如 kDaysInWeek。
- 缩进量为 2 的倍数。第一层为两个空格;如果进一步 因此需要缩进,我们使用 4 个空格、6 个空格等。
欢迎来到“现实世界”!
在本单元中,我们将介绍大多数软件工程中使用的两个非常重要的工具 组织。第一个是构建工具,第二个是配置管理 系统。这两种工具在工业软件工程中都至关重要, 许多工程师往往只从事一个大型系统的工作。这些工具有助于协调和 可控制对代码库的更改,并提供一种高效的编译方式, 以及从多个程序文件和头文件链接到一个系统。
Makefile
构建程序的过程通常通过构建工具进行管理, 并按照正确的顺序关联所需文件。C++文件常常包含 依赖项,例如,在一个程序中调用的函数位于另一个程序中 计划。或者,几个不同的 .cpp 文件可能需要头文件。答 构建工具会根据这些依赖项确定正确的编译顺序。它会 也只会编译自上次构建以来发生更改的文件。这样可以节省 在包含数百或数千个文件的系统中花费大量时间
常用的开源构建工具是 Make。如需了解相关信息,请参阅 文章。 看看您能否为 Composer 数据库应用创建依赖关系图, 然后将其转换为 makefile。点击此处 解决方案
配置管理系统
工业软件工程中使用的第二种工具是配置管理 (CM)。用于管理变更。假设 Bob 和 Susan 都是技术文档工程师 他们都在努力更新技术手册在会议期间,他们的 经理会为每个他们分配同一个文档的部分要更新的内容。
技术手册存储在 Bob 和 Susan 都能访问的计算机上。 如果没有实施任何 CM 工具或流程,可能会出现许多问题。一个 存储文档的计算机可能设置成这样 Bob 和 Susan 不能同时编写手册。这会减慢 大幅降低
如果存储计算机确实允许存储相关文档,就会出现更危险的情况。 可以同时由 Bob 和 Susan 打开。可能出现的情况如下:
- 李明在计算机上打开文档,开始编辑部分。
- 苏珊在计算机上打开了文档,开始编辑部分。
- 李明完成了所有更改,并将文档保存在存储计算机上。
- 苏珊完成了修改,并将文档保存在存储计算机上。
此图显示了没有控件时可能出现的问题 单独复制一份技术手册。她在保存更改后 将覆盖 Bob 创建的文件。
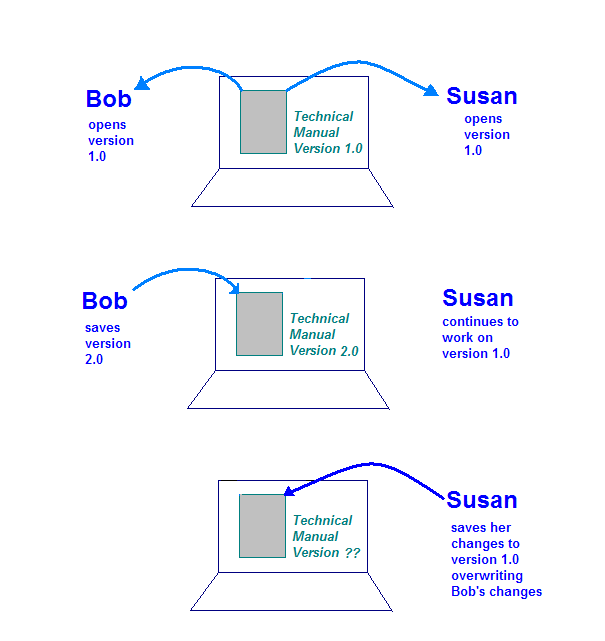
这正是 CM 系统能够控制的情况。有社区管理者 Bob 和 Susan自己的技术资源 手动处理这些代码当小鲍检查他的更改时,系统会知道 Susan 已经签出自己的副本了当小苏签入副本时,系统会 同时分析了小鲍和小苏所做的更改,并创建了一个新版本, 将两组更改合并在一起。
除了管理并发更改,CM 系统还具有许多其他功能,如上文所述 。许多系统会存储文档所有版本的归档,从第一个 创建时间。如果是技术手册 当用户有旧版手册并且向技术文档工程师提问时触发。 CM 系统将允许技术文档工程师访问旧版本,并能够 了解用户看到的内容
CM 系统特别适用于控制对软件所做的更改。此类 称为软件配置管理 (SCM) 系统。如果您考虑 大型软件工程中大量单独的源代码文件 还有大量工程师必须对这些代码进行更改, 很明显,SCM 系统至关重要。
软件配置管理
SCM 系统基于一个简单的理念:您文件的最终副本 都保存在中央代码库中人们可以从代码库中签出文件副本, 处理这些副本,然后在完成后重新签入。SCM 系统可针对单个主服务器管理和跟踪多人进行的修订 。
所有 SCM 系统都提供以下基本功能:
- 并发管理
- 版本控制
- 同步
我们来详细了解一下每个功能。
并发管理
并发是指多个人同时编辑一个文件。 有了大型仓库,我们希望员工能够做到这一点,但这可能会引领 一些问题。
我们来考虑一下工程领域的简单示例:假设我们允许工程师 在源代码的中央代码库中同时修改同一文件的权限。 Client1 和 Client2 都需要同时对文件进行更改:
- Client1 打开 bar.cpp。
- Client2 打开 bar.cpp。
- Client1 更改该文件并保存。
- Client2 将更改该文件并保存,覆盖 Client1 的更改。
显然,我们不希望发生这种情况。即使我们控制了 让两位工程师分别处理各自的副本,而不是直接处理母版 (如下图所示),副本必须进行协调。大多数人 为了解决此问题,SCM 系统允许多个工程师检查一个文件, 输出(“同步”或“更新”),并根据需要进行更改。SCM 然后,在文件重新签入时运行算法来合并更改 (“提交”或“提交”)提交到代码库。

这些算法可能很简单(要求工程师解决有冲突的更改) 或不太简单(确定如何以智能方式合并有冲突的更改) 仅在系统确实卡住时询问工程师)。
版本控制
版本控制是指跟踪文件修订版本 重新创建(或回滚到)文件的先前版本。为此,您可以 在签入代码库时,为每个文件创建归档副本, 或保存对文件所做的每项更改我们可以随时 或更改信息以创建先前的版本。版本控制系统还可以 创建日志报告,记录哪些人签入了更改、签入时间以及发生了什么 更改的内容
同步
在某些 SCM 系统中,各个文件会签入和签出存储区。 功能更强大的系统可让您一次签出多个文件。工程师 签出他们自己的完整代码库(或其中一部分) 管理文件。然后,他们将自己的更改提交回主代码库 并更新自己的个人副本以及时了解更改 他人创造的佳绩此过程称为同步或更新。
Subversion 版本
Subversion (SVN) 是一个开源版本控制系统。它包含 功能。
当发生冲突时,SVN 会采用简单的方法。冲突是指 或更多工程师对代码库的同一区域进行不同的更改, 然后两个人都提交自己的更改SVN 只会提醒工程师 冲突 - 需要工程师来解决。
在本课程中,我们将使用 SVN 来帮助您熟悉 配置管理此类系统在行业中非常常见。
第一步是在系统上安装 SVN。点击 此处 操作说明。找到您使用的操作系统并下载合适的二进制文件。
SVN 部分术语
- 修订版本:一个文件或一组文件发生更改。修订版本是 “快照”在不断变化的项目中
- 代码库:主副本,SVN 在其中存储项目的完整修订历史记录。 每个项目都有一个代码库。
- 工作副本:工程师对项目进行更改的副本。那里 可以是给定项目的多个工作副本,每个副本归单个工程师所有。
- 签出:从代码库中请求工作副本。有效副本 等于项目签出时的状态。
- 提交:将工作副本中的更改发送到中央仓库。 也称为“签入或提交”。
- 更新:如要将他人的复制到您的工作副本 或指明您的工作副本是否包含任何未提交的更改。这是 这与同步操作相同(如上所述)。因此,更新/同步会将您的工作副本 并更新代码库副本
- 冲突:两位工程师尝试对同一个作业进行更改的情况 文件区域。SVN 表示存在冲突,但工程师必须解决它们。
- 日志消息:您在提交修订版本时附加到修订版本的注释, 来描述您的更改日志会总结发生的情况 资源。
现在您已经安装了 SVN,下面我们将运行一些基本命令。通过 首先要在指定目录中设置仓库。这里展示了 命令:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
import 命令会将 mytree 目录的内容复制到 目录项目我们可以在 使用 list 命令
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
导入操作不会创建工作副本。为此,您需要使用 svn checkout 命令。这将创建目录树的工作副本。让我们 立即执行该操作:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
现在您拥有了工作副本,可以更改文件和目录 您的工作副本与任何其他文件和目录集合一样 - 您可以添加新过滤器、编辑过滤器、移动文件,甚至删除 整个工作副本。请注意,如果您复制并移动工作副本中的文件, 请务必使用 svn copy 和 svn move,而不是 操作系统命令要添加新文件,请使用 svn add 并删除 文件请使用 svn delete。如果您只想进行编辑,只需打开 文件即可进行修改!
有一些标准目录名称通常与 Subversion 一起使用。“后备箱”目录 是项目开发的主线。“分支”目录 包含您可能正在处理的任何分支版本。
$ svn list file:///usr/local/svn/repos /trunk /branches
所以,假设您已经对工作副本进行了所有必要的更改, 将其与代码库同步如果有很多其他工程师也在工作 请务必保持您的工作副本处于最新状态。 您可以使用 svn status 命令查看自己所做的更改 。
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
请注意,status 命令中有许多用于控制此输出的标志。 如果您想查看修改后的文件中的具体更改,请使用 svn diff。
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...最后,要从代码库中更新工作副本,请使用 svn update 命令。
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
这个地方可能会出现冲突。在上面的输出中,“U”表示 未对这些文件的代码库版本进行任何更改,我们更新了 已完成。“G”表示发生了合并。代码库版本包含 已更改,但您所做的更改与您的更改并不冲突。“C”表示 冲突。这意味着代码库中的更改与您的更改重叠, 现在,您必须在两者之间进行选择
对于每个存在冲突的文件,Subversion 会将三个文件放在 副本:
- file.mine:这是您的文件,因为它在您提交请求之前存在于您的工作副本中。 已更新您的工作副本。
- file.rOLDREV:这是您在开始之前从代码库中签出的文件 进行更改
- file.rNEWREV:此文件是代码库中的当前版本。
您可以执行以下三项操作之一来解决冲突:
- 浏览文件并手动进行合并。
- 复制 SVN 创建的其中一个临时文件,以覆盖您的工作副本版本。
- 运行 svn restore 以舍弃您的所有更改。
解决冲突后,您需要运行 svn resolve 来通知 SVN。 这会移除这三个临时文件,且 SVN 不会再在 冲突状态。
最后一项操作是将最终版本提交到代码库。本次 请通过 svn commit 命令完成。在提交更改时 以提供一条日志消息来描述您的更改。此日志消息已附加 修订版本
svn commit -m "Update files to include new headers."
关于 SVN,以及它如何支持大型软件,还有很多内容需要了解 工程项目。网络上提供了大量资源 - 在 Google 上搜索“Subversion”
作为练习,请为您的 Composer 数据库系统创建一个仓库,然后导入 所有文件然后签出有效副本并执行所述命令 。
参考
应用:解剖学研究
了解大学的 eSkeletons 德克萨斯州奥斯汀办事处