Tutoriel sur le langage C++
Les premières sections de ce tutoriel les documents de base déjà présentés dans les deux derniers modules et vous donnerez plus d'informations sur les concepts avancés. Notre ce module porte sur la mémoire dynamique et plus de détails sur les objets et les classes. Certains sujets avancés sont également présentés, comme l'héritage, le polymorphisme, les modèles, les exceptions et les espaces de noms. Nous les étudierons plus tard dans le cours Advanced C++.
Conception orientée objet
C'est une excellente tutoriel sur la conception orientée objet. Nous appliquerons les la méthodologie présentée ici dans le projet de ce module.
Apprendre par l'exemple n° 3
L'objectif de ce module est d'apprendre à utiliser les pointeurs, la conception, les tableaux multidimensionnels et les classes/objets. Effectuez les opérations suivantes exemples. Nous ne soulignerons jamais assez que la clé pour devenir un bon programmeur c'est de s'entraîner, de s'entraîner !Exercice n° 1: S'entraîner davantage avec les pointeurs
Si vous avez besoin de vous entraîner davantage avec les pointeurs, lisez les ce ressource qui couvre tous les aspects des pointeurs et fournit de nombreux exemples de programmes.
Quel est le résultat du programme suivant ? N'exécutez pas le programme, mais dessiner l'image de la mémoire pour déterminer la sortie.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Une fois que vous avez déterminé manuellement la sortie, exécutez le programme pour voir si vous êtes Correct.
Exercice n° 2: S'entraîner davantage avec les classes et les objets
Si vous avez besoin de vous exercer supplémentaire avec les classes et les objets, cliquez ici est une ressource qui passe par l'implémentation de deux petites classes. Prenez des du temps pour faire les exercices.
Exercice n° 3: Tableaux multidimensionnels
Prenons l'exemple du programme suivant:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Ce programme comporte une ligne intitulée "Comment fonctionne cette ligne ?" - Tu peux le savoir ? Pour en savoir plus, consultez cette page.
Écrire un programme qui initialise un tableau à trois dimensions et remplit la 3e dimension par la somme des trois index. Pour en savoir plus, consultez cette page.
Exercice n° 4: Exemple de conception d'un plan d'exploitation complet
Voici un récapitulatif exemple de conception orientée objet, qui couvre l'intégralité du début à la fin. Le code final est écrit en langage Java de programmation, mais vous serez en mesure de le lire étant donné la distance sont arrivés.
Veuillez prendre le temps de parcourir cet exemple entier. C'est une Illustration du processus et des outils de conception qui le sous-tendent.
Tests unitaires
Introduction
Les tests constituent une partie essentielle du processus d'ingénierie logicielle. Un test unitaire est un type de test particulier qui vérifie le fonctionnement d'un petit du code source.Les tests unitaires sont toujours réalisés par l'ingénieur et généralement effectuées en même temps qu'ils codent le module. Les pilotes de test que vous utilisées pour tester les classes Composer et Database sont des exemples de tests unitaires.
Les tests unitaires présentent les caractéristiques suivantes. Ils...
- tester un composant de manière isolée
- sont déterministes
- correspondent généralement à une seule classe
- éviter toute dépendance à des ressources externes, comme bases de données, fichiers, réseau
- exécuter rapidement
- peuvent s'exécuter dans n'importe quel ordre
Il existe des frameworks et des méthodologies automatisés qui fournissent une assistance et la cohérence pour les tests unitaires dans les grandes organisations d’ingénierie logicielle. Il existe des frameworks de tests unitaires Open Source sophistiqués, que nous plus en détail dans la suite de cette leçon.
Les tests effectués dans le cadre de tests unitaires sont illustrés ci-dessous.

Dans un monde idéal, nous testons les éléments suivants:
- L'interface du module est testée pour vérifier que les informations entrent et sortent. correctement.
- Les structures de données locales sont examinées pour s’assurer qu’elles stockent correctement les données.
- Les conditions de limite sont testées pour s'assurer que le module fonctionne correctement aux limites qui limitent ou limitent le traitement.
- Nous testons des chemins d'accès indépendants dans le module pour vérifier que chaque chemin d'accès, et
Ainsi, chaque instruction du module est exécutée au moins une fois.
- Enfin, nous devons vérifier que les erreurs sont traitées correctement.
Couverture de code
En réalité, nous ne pouvons pas atteindre une "couverture du code" complète avec nos tests. La couverture de code est une méthode d'analyse qui détermine les parties d'un logiciel ont été exécutés (couverts) par la suite de scénarios de test et quelles parties ont n'a pas été exécutée. Si nous essayons d'atteindre une couverture de 100 %, nous passerons plus de temps les tests unitaires que l'écriture du code. Pensez à choisir l'unité teste tous les chemins indépendants des éléments suivants. Cela peut rapidement devenir dans un problème exponentiel.

Dans ce diagramme, les lignes rouges ne sont pas testées, tandis que les lignes non colorées sont sont testées.
Au lieu d'essayer une couverture à 100 %, nous nous concentrons sur des tests qui renforcent notre confiance pour vérifier que le module fonctionne correctement. Nous testons par exemple les éléments suivants:
- Cas de valeur nulle
- Tests de plage, par exemple des tests de valeurs positives/négatives
- Cas extrêmes
- Cas d'échec
- Tester les chemins les plus susceptibles de s'exécuter la plupart du temps
Frameworks de tests unitaires
La plupart des frameworks de tests unitaires utilisent des assertions pour tester les valeurs lors de l'exécution de un chemin d'accès. Les assertions sont des instructions qui vérifient si une condition est vraie. La le résultat d'une assertion peut être une réussite, un échec non fatal ou un échec fatal. Après une assertion est effectuée, le programme continue normalement si le résultat est soit une réussite ou un échec non fatal. En cas d'échec fatal, la fonction actuelle est annulée.
Les tests sont constitués de code qui configure l'état ou manipule votre module, avec un certain nombre d'assertions qui vérifient les résultats attendus. Si toutes les assertions d'un test réussissent, c'est-à-dire renvoient "true" (vrai), le test réussit ; sinon elle échoue.
Un scénario de test contient un ou plusieurs tests. Nous regroupons les tests dans des scénarios de test qui reflètent la structure du code testé. Dans ce cours, nous allons utiliser CPPUnit comme framework de tests unitaires. Ce framework permet d'écrire des tests unitaires en C++ et les exécuter automatiquement, en générant un rapport sur la réussite ou l'échec de tests.
Installation du module CPPUnit
Téléchargez le code CPPUnit à l'adresse SourceForge : Recherchez le répertoire approprié et placez-y le fichier tar.gz. Saisissez ensuite le les commandes suivantes (sous Linux, Unix) en remplaçant le fichier cppunit approprié nom:
gunzip filename.tar.gz tar -xvf filename.tar
Si vous travaillez sous Windows, vous aurez peut-être besoin d'un utilitaire pour extraire le fichier tar.gz . L'étape suivante consiste à compiler les bibliothèques. Accédez au répertoire cppunit. Vous y trouverez un fichier INSTALL qui fournit des instructions spécifiques. Habituellement, vous devez exécuter:
./configure make install
Si vous rencontrez des problèmes, reportez-vous au fichier INSTALL. Les bibliothèques sont généralement qui se trouve dans le répertoire cppunit/src/cppunit. Pour vérifier que la compilation a fonctionné, allez dans le répertoire cppunit/examples/simple et tapez "make". Si tout se compile correctement, alors vous êtes prêt.
Il existe un excellent didacticiel cliquez ici. Veuillez suivre ce tutoriel pour créer la classe des nombres complexes et la classe associée les tests unitaires. Vous trouverez plusieurs exemples supplémentaires dans le répertoire cppunit/examples.
Pourquoi dois-je procéder ainsi ??
Les tests unitaires sont essentiels dans le secteur pour plusieurs raisons. Vous êtes déjà familiarisé avec une raison: nous avons besoin d'un moyen de vérifier notre travail tout en développer du code. Même lorsque nous développons un tout petit programme, écrire une sorte de vérificateur ou de pilote pour s'assurer que notre programme fait ce qui est attendu.
Forts de leur longue expérience, les ingénieurs savent que les chances qu'un programme fonctionne au premier essai sont très faibles. Les tests unitaires s'appuient sur cette idée en rendant des tests et reproductibles. Les assertions remplacent en inspectant les résultats. Et comme les résultats sont faciles à interpréter (le test qu'elles réussissent ou échouent), les tests peuvent être exécutés encore et encore, un filet de sécurité qui rend votre code plus résistant aux modifications.
Concrètement, lorsque vous envoyez pour la première fois votre code finalisé à CVS fonctionne parfaitement. Et il continue de fonctionner parfaitement pendant un certain temps. Ensuite, un jour, quelqu'un d'autre modifie votre code. Tôt ou tard, que quelqu'un cassera votre code. Pensez-vous qu'ils le remarqueront d'eux-mêmes ? Peu probable. Mais lorsque vous écrire des tests unitaires, il existe des systèmes qui peuvent les exécuter automatiquement, tous les jours. C'est ce que l'on appelle les systèmes d'intégration continue. Quand cet ingénieur X interrompt votre code, le système lui enverra des e-mails désagréables jusqu'à ce qu'il soit résolu Même si vous êtes l'ingénieur X !
En plus de vous aider à développer des logiciels, et à assurer leur sécurité face au changement, les tests unitaires:
- Crée une spécification exécutable et une documentation qui restent synchronisées avec le code. En d'autres termes, vous pouvez lire un test unitaire pour savoir le comportement pris en charge par le module.
- Il vous aide à distinguer les exigences de l'implémentation. Parce que vous affirmez ce comportement visible de l'extérieur, vous avez la possibilité d'y penser explicitement au lieu de se mélanger les idées sur la façon de mettre en œuvre le comportement.
- Compatible avec l'expérimentation. Si vous avez un filet de sécurité pour vous alerter lorsque si vous avez décomposé le comportement d'un module, vous êtes plus susceptible et reconfigurer vos conceptions.
- Améliore vos conceptions. Écrire des tests unitaires approfondis nécessite souvent rendre votre code plus facile à tester. Le code testable est souvent plus modulaire que non testable. du code source.
- Garantit une qualité élevée. Un petit bogue dans un système critique peut amener une entreprise de perdre des millions de dollars, ou pire, la satisfaction ou la confiance d'un utilisateur. La de sécurité que les tests unitaires offrent des réductions de cette possibilité. En attraper des insectes elles permettent également aux équipes de contrôle qualité de consacrer du temps à des tâches plus complexes des scénarios de défaillance, plutôt que de signaler des défaillances évidentes.
Prenez le temps d'écrire des tests unitaires à l'aide de CPPUnit pour l'application de base de données Composer. Pour obtenir de l'aide, consultez le répertoire cppunit/examples/.
Fonctionnement de Google
IntroductionImaginez un moine au Moyen Âge regardant les milliers de manuscrits les archives de son monastère."Où est celle-là d'Aristote..."

Heureusement pour lui, les manuscrits sont organisés par contenu et inscrits avec des symboles spéciaux pour faciliter la récupération des informations contenues dans chaque élément. Sans une telle organisation, il serait très difficile de trouver manuscrit.
Activité de stockage et de récupération d'informations écrites dans de grandes collections est appelée Récupération d'informations (IR). Cette activité est de plus en plus au fil des siècles, en particulier avec des inventions telles que le papier et l'imprimerie appuyez. Auparavant, seules quelques personnes y étaient occupées. Maintenant, Toutefois, des centaines de millions de personnes recourent à la récupération d'informations lorsqu'ils utilisent un moteur de recherche ou effectuent des recherches sur leur ordinateur.
Premiers pas avec la récupération d'informations

Le Dr Seuss a écrit 46 livres pour enfants sur une période de 30 ans. Ses livres racontaient des chats, des vaches et des éléphants, des grincements et le lorax. Te rappelles-tu Quelles créatures se trouvaient dans quelle histoire ? Sauf si vous êtes un parent, seuls les enfants peuvent vous saurez quelle série d'histoires contient ces créatures:
(COW et BEE) ou CROWS
Pour résoudre ce problème, nous allons appliquer des modèles classiques de récupération d'informations. problème.
Une approche évidente est la force brute: obtenez les 46 histoires de Dr. Seuss et commencez en lecture seule. Pour chaque livre, notez lequel(s) contiennent les mots COW et BEE, et en même temps, recherchez les livres qui contiennent le mot CROWS. Les ordinateurs sont beaucoup plus rapidement que nous. Si nous avons tout le texte des livres du Dr Seuss sous forme numérique, par exemple sous forme de fichiers texte, nous pouvons simplement parcourir les fichiers. Pour une comme les livres du Dr. Seuss, cette technique fonctionne très bien.
Cependant, il existe de nombreuses situations dans lesquelles nous avons besoin d'un plus grand nombre. Par exemple, la collection de toutes les données actuellement en ligne sont beaucoup trop volumineuses pour grep. Nous ne faisons pas non plus nous voulons seulement les documents qui remplissent notre condition, nous sommes habitués à en les classant en fonction de leur pertinence.
Une autre approche que la commande grep, consiste à créer un index des documents dans une collection avant d'effectuer la recherche. Un indice dans la réponse infrarouge est similaire à un indice au niveau verso d'un manuel. Nous établissons une liste de tous les mots (ou termes) de chaque l'histoire du docteur Seuss, sans les mots comme "le", "et" et autres, des prépositions, etc. (appelées mots vides). Nous représentons ensuite de façon à faciliter la recherche des termes et l'identification les histoires dans lesquelles ils se trouvent.
Une représentation possible est une matrice avec les histoires en haut et les termes listés sur chaque ligne. Le chiffre "1" dans une colonne indique que le terme apparaît dans l’histoire pour cette colonne.
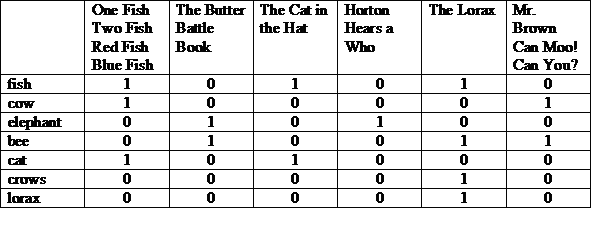
Nous pouvons afficher chaque ligne ou colonne en tant que vecteur de bits. Le vecteur de bits d'une ligne indique dans lesquels le terme apparaît. Le vecteur de bits d'une colonne indique quels termes apparaissent dans l'histoire.
Revenons à notre problème initial:
(COW et BEE) ou CROWS
Nous prenons les vecteurs de bits pour ces termes, nous exécutons d'abord l'opérateur AND (ET) bit à bit, puis nous exécutons un opérateur OU au niveau du bit sur le résultat.
(100001 et 010011) ou 000010 = 000011
La réponse : "M. Brown Can Moo! Tu le crois ?" et "Le Lorax". Il s'agit d'une illustration du modèle de récupération booléenne, qui est un modèle de type "mot clé exact".
Supposons que nous devions étendre la matrice pour inclure tous les témoignages du Dr Seuss et toutes les termes pertinents dans les histoires. La matrice prendrait de plus en plus d'ampleur, et une étape importante l'observation est que la plupart des entrées sont égales à 0. Une matrice n'est probablement pas la meilleure la représentation de l'index. Nous devons trouver un moyen de stocker uniquement les "1".
Quelques améliorations
La structure utilisée dans les infrarouges pour résoudre ce problème est appelée indice inversé. Nous tenons un dictionnaire de termes, puis nous dressons une liste pour chacun de ces termes. qui enregistre les documents dans lesquels le terme apparaît. Cette liste est appelée une liste de publications liste. Une liste de liens simples permet de représenter cette structure telle qu'illustrée ci-dessous.
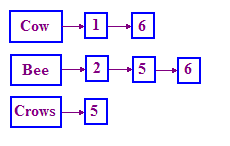
Si vous ne connaissez pas les listes associées, il vous suffit d'effectuer une recherche Google sur "
en C++", et vous trouverez de nombreuses
ressources décrivant comment en créer un,
et leur utilisation. Nous aborderons ce point plus en détail dans un module ultérieur.
Notez que nous utilisons les ID de document (DocIDs) au lieu du nom du histoire. Nous trions également ces ID de document, car cela facilite le traitement des requêtes.
Comment traiter une requête ? Pour le problème d'origine, nous trouvons d'abord les offres de COW puis à la liste des publications du BEE. Nous les fusionnons ensuite:
- Maintenez les repères dans les deux listes et parcourez les deux listes de publications simultanément.
- À chaque étape, comparez le DocID indiqué par les deux pointeurs.
- S'ils sont identiques, placez cet ID de document dans une liste de résultats, sinon faites avancer le pointeur pointant vers le plus petit docID.
Voici comment créer un index inversé:
- Attribuez un ID de document à chaque document qui vous intéresse.
- Identifiez les termes pertinents pour chaque document (tokenisation).
- Pour chaque terme, créez un enregistrement comprenant le terme, le DocID dans lequel et une fréquence dans ce document. Notez qu'il peut y avoir plusieurs d'enregistrements pour un terme particulier s'il apparaît dans plusieurs documents.
- Triez les enregistrements par terme.
- Créez le dictionnaire et la liste des publications en traitant les enregistrements uniques pour et combine les enregistrements multiples pour les termes qui apparaissent dans plusieurs documents. Créez une liste associée des ID de document (par ordre de tri). Chaque Le terme a aussi une fréquence, qui correspond à la somme des fréquences de tous les enregistrements pour un terme.
Le projet
Trouvez plusieurs longs documents en texte brut que vous pouvez tester. La consiste à créer un index inversé à partir des documents, à l'aide d'algorithmes décrites ci-dessus. Vous devrez aussi créer une interface pour la saisie des requêtes et un moteur pour les traiter. Vous trouverez un partenaire du projet sur le forum.
Voici un processus possible pour mener à bien ce projet:
- La première chose à faire est de définir une stratégie d'identification des termes dans les documents. Faites une liste de tous les mots vides auxquels vous pouvez penser et écrivez une fonction qui lit les mots dans les fichiers, enregistre les termes et élimine les mots vides. Vous devrez peut-être ajouter d'autres mots vides à votre liste lorsque vous examinerez la liste à partir d'une itération.
- Écrivez des scénarios de test CPPUnit pour tester votre fonction et un fichier makefile pour tout regrouper pour votre build. Enregistrez vos fichiers dans CVS, surtout si vous avec des partenaires. Pour savoir comment ouvrir votre instance CVS, aux ingénieurs à distance.
- Ajouter un traitement pour inclure les données de localisation, c'est-à-dire le fichier et l'emplacement le fichier est-il un terme ? Vous voudrez peut-être trouver un calcul pour définir numéro de page ou de paragraphe.
- Rédigez des scénarios de test CPPUnit pour tester cette fonctionnalité supplémentaire.
- Créez un index inversé et stockez les données de localisation dans l'enregistrement de chaque terme.
- Écrivez d'autres scénarios de test.
- Concevez une interface pour permettre à un utilisateur de saisir une requête.
- À l'aide de l'algorithme de recherche décrit ci-dessus, traitez l'index inversé et renvoyer les données de localisation à l'utilisateur.
- Veillez également à inclure des scénarios de test pour cette dernière partie.
Comme pour tous les projets, utilisez le forum et le chat pour trouver des partenaires. et de partager des idées.
Une fonctionnalité supplémentaire
Une étape de traitement courante dans de nombreux systèmes infrarouges est appelée recherche de radicaux. La l'idée principale à l'origine de la recherche de radical est que les utilisateurs recherchant des informations sur le thème de la "récupération" seront également intéressés par les documents dont les informations contiennent le terme "récupérer", « récupéré », « retrieving », etc. Les systèmes peuvent être sensibles à des erreurs en raison ou de mauvaises variétés, ce qui est un peu délicat. Par exemple, un utilisateur intéressé dans la "récupération d'informations", peut obtenir un document intitulé Retrievers" à cause de la racinisation des radis. Un algorithme utile pour trouver le radical est le Algorithme de Porter :