Учебник по языку C++
Первые разделы этого руководства охватывают базовый материал, уже представленный в двух последних модулях, и предоставляют дополнительную информацию о более сложных концепциях. В этом модуле основное внимание уделяется динамической памяти и более подробной информации об объектах и классах. Также представлены некоторые сложные темы, такие как наследование, полиморфизм, шаблоны, исключения и пространства имен. Мы изучим их позже в курсе Advanced C++.
Объектно-ориентированный дизайн
Это отличный учебник по объектно-ориентированному проектированию. Мы будем применять методологию, представленную здесь, в проекте этого модуля.
Учитесь на примере №3
В этом модуле основное внимание уделяется получению большей практики в работе с указателями, объектно-ориентированным проектированием, многомерными массивами и классами/объектами. Проработайте следующие примеры. Мы не можем не подчеркнуть, что ключом к тому, чтобы стать хорошим программистом, является практика, практика, практика!Упражнение № 1. Больше практики с указателями
Если вам нужна дополнительная практика с указателями, прочитайте этот ресурс , который охватывает все аспекты указателей и содержит множество примеров программ.
Каков результат выполнения следующей программы? Пожалуйста, не запускайте программу, а нарисуйте изображение памяти, чтобы определить результат.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Определив результат вручную, запустите программу и проверьте, правы ли вы.
Упражнение № 2. Больше практики с классами и объектами
Если вам нужна дополнительная практика с классами и объектами, вот ресурс, в котором реализованы два небольших класса. Уделите некоторое время выполнению упражнений .
Упражнение №3: Многомерные массивы
Рассмотрим следующую программу:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}В этой программе есть строка с пометкой «Как работает эта строка?» - ты можешь это понять? Вот наше объяснение.
Напишите программу, которая инициализирует трехмерный массив и заполняет значение третьего измерения суммой всех трех индексов. Вот наше решение.
Упражнение № 4. Расширенный пример объектно-ориентированного проектирования
Вот подробный пример объектно-ориентированного проектирования , который проходит весь процесс от начала до конца. Окончательный код написан на языке программирования Java, но вы сможете прочитать его, учитывая, как далеко вы продвинулись.
Пожалуйста, найдите время, чтобы проработать весь этот пример. Это отличная иллюстрация процесса и инструментов проектирования, которые его поддерживают.
Модульное тестирование
Введение
Тестирование является важной частью процесса разработки программного обеспечения. Модульный тест — это особый вид теста, который проверяет функциональность одного небольшого модуля исходного кода. Модульное тестирование всегда выполняется инженером и обычно выполняется одновременно с кодированием модуля. Тестовые драйверы, которые вы использовали для тестирования классов Composer и Database, являются примерами модульных тестов.
Модульные тесты имеют следующие характеристики. Они...
- протестировать компонент изолированно
- детерминированы
- обычно сопоставляется с одним классом
- избегать зависимостей от внешних ресурсов, например баз данных, файлов, сети
- выполнить быстро
- можно запускать в любом порядке
Существуют автоматизированные платформы и методологии, которые обеспечивают поддержку и согласованность модульного тестирования в крупных организациях, занимающихся разработкой программного обеспечения. Существует несколько сложных сред модульного тестирования с открытым исходным кодом, о которых мы узнаем позже в этом уроке.
Тесты, которые выполняются как часть модульного тестирования, показаны ниже.

В идеальном мире мы проверяем следующее:
- Интерфейс модуля тестируется, чтобы убедиться, что информация поступает и выходит правильно.
- Локальные структуры данных проверяются, чтобы убедиться, что они хранят данные правильно.
- Граничные условия проверяются, чтобы убедиться, что модуль работает правильно на границах, которые ограничивают или ограничивают обработку.
- Мы тестируем независимые пути через модуль, чтобы убедиться, что каждый путь и, следовательно, каждый оператор в модуле выполняется хотя бы один раз.
- Наконец, нам нужно проверить, правильно ли обрабатываются ошибки.
Покрытие кода
На самом деле мы не можем добиться полного «покрытия кода» с помощью нашего тестирования. Покрытие кода — это метод анализа, который определяет, какие части программной системы были выполнены (покрыты) набором тестовых примеров, а какие части не были выполнены. Если мы попытаемся достичь 100% покрытия, мы потратим больше времени на написание модульных тестов, чем на написание реального кода! Рассмотрите возможность создания модульных тестов для всех независимых путей следующего. Это может быстро стать экспоненциальной проблемой.

На этой диаграмме красные линии не проверяются, а бесцветные линии проверяются.
Вместо того, чтобы стремиться к 100% покрытию, мы концентрируемся на тестах, которые повышают нашу уверенность в том, что модуль работает правильно. Мы тестируем такие вещи, как:
- Нулевые случаи
- Тесты диапазона, например, тесты на положительные/отрицательные значения
- Краевые случаи
- Случаи сбоя
- Тестирование путей, которые с наибольшей вероятностью будут выполняться большую часть времени
Платформы модульного тестирования
Большинство платформ модульного тестирования используют утверждения для проверки значений во время выполнения пути. Утверждения — это утверждения, которые проверяют, истинно ли условие. Результатом утверждения может быть успех, нефатальный сбой или фатальный сбой. После выполнения утверждения программа продолжает работу в обычном режиме, если результатом является либо успех, либо нефатальный сбой. В случае фатального сбоя текущая функция прерывается.
Тесты состоят из кода, который устанавливает состояние или манипулирует вашим модулем, в сочетании с рядом утверждений, проверяющих ожидаемые результаты. Если все утверждения в тесте успешны, т. е. возвращают true, то тест завершается успешно; в противном случае это терпит неудачу.
Тестовый пример содержит один или несколько тестов. Мы группируем тесты в тест-кейсы, которые отражают структуру тестируемого кода. В этом курсе мы собираемся использовать CPUUnit в качестве нашей среды модульного тестирования. С помощью этого фреймворка мы можем писать модульные тесты на C++ и запускать их автоматически, предоставляя отчет об успехе или провале тестов.
Установка ЦППУнита
Загрузите код CPUUnit с SourceForge . Найдите подходящий каталог и поместите туда файл tar.gz. Затем введите следующие команды (в Linux, Unix), подставив соответствующее имя файла cppunit:
gunzip filename.tar.gz tar -xvf filename.tar
Если вы работаете в Windows, вам может потребоваться найти утилиту для извлечения файлов tar.gz. Следующим шагом будет компиляция библиотек. Перейдите в каталог cppunit. Там есть файл INSTALL, содержащий конкретные инструкции. Обычно вам нужно запустить:
./configure make install
Если у вас возникнут проблемы, обратитесь к файлу INSTALL. Библиотеки обычно находятся в каталоге cppunit/src/cppunit. Чтобы проверить, что компиляция сработала, перейдите в каталог cppunit/examples/simple и введите «make». Если все компилируется нормально, значит, все готово.
Здесь есть отличный учебник. Пожалуйста, просмотрите это руководство и создайте класс комплексных чисел и связанные с ним модульные тесты. В каталоге cppunit/examples есть несколько дополнительных примеров.
Почему я должен это делать???
Модульное тестирование критически важно в промышленности по нескольким причинам. Одна из причин вам уже известна: нам нужен какой-то способ проверки нашей работы при разработке кода. Даже когда мы разрабатываем очень маленькую программу, мы инстинктивно пишем какую-то программу проверки или драйвер, чтобы убедиться, что наша программа делает то, что от нее ожидается.
Из многолетнего опыта инженеры знают, что вероятность того, что программа заработает с первой попытки, очень мала. Модульные тесты развивают эту идею, делая программы тестирования самопроверяемыми и повторяемыми. Утверждения заменяют ручную проверку вывода. А поскольку результаты легко интерпретировать (тест либо проходит, либо не проходит), тесты можно запускать снова и снова, обеспечивая защитную сетку, которая делает ваш код более устойчивым к изменениям.
Давайте сформулируем это более конкретно: когда вы впервые отправляете готовый код в CVS, он работает отлично. И какое-то время он продолжает работать идеально. Затем однажды кто-то другой меняет ваш код. Рано или поздно кто-то взломает ваш код. Думаете, они сами заметят? Вряд ли. Но когда вы пишете модульные тесты, существуют системы, которые могут запускать их автоматически каждый день. Это так называемые системы непрерывной интеграции . Поэтому, когда этот инженер X взломает ваш код, система будет отправлять ему неприятные электронные письма, пока он это не исправит. Даже если инженер Х — это ВЫ!
Модульное тестирование не только помогает вам разрабатывать программное обеспечение, а затем обеспечивать его безопасность перед лицом изменений, но и:
- Создает исполняемую спецификацию и документацию, которая синхронизируется с кодом. Другими словами, вы можете прочитать модульный тест, чтобы узнать, какое поведение поддерживает модуль.
- Помогает отделить требования от реализации. Поскольку вы утверждаете внешне видимое поведение, вы получаете возможность подумать о нем явно, а не смешивать идеи о том, как реализовать это поведение.
- Поддерживает эксперименты. Если у вас есть система безопасности, которая предупреждает вас, когда вы нарушаете поведение модуля, вы с большей вероятностью попробуете что-то и переконфигурируете свои проекты.
- Улучшает ваши проекты. Написание тщательных модульных тестов часто требует от вас сделать ваш код более тестируемым. Тестируемый код часто более модульный, чем нетестируемый.
- Сохраняет качество на высоком уровне. Небольшая ошибка в критической системе может привести к потере компанией миллионов долларов или, что еще хуже, счастья или доверия пользователей. Сеть безопасности, которую обеспечивают модульные тесты, уменьшает эту возможность. Выявляя ошибки на ранней стадии, они также позволяют командам контроля качества тратить время на более сложные и трудные сценарии сбоев, а не сообщать об очевидных сбоях.
Уделите некоторое время написанию модульных тестов с использованием CPPUnit для приложения базы данных Composer. За помощью обратитесь к каталогу cppunit/examples/.
Как работает Google
ВведениеПредставьте себе средневекового монаха, просматривающего тысячи рукописей в архивах своего монастыря. «Где тот Аристотель…»

К счастью для него, рукописи упорядочены по содержанию и отмечены специальными символами, облегчающими поиск информации, содержащейся в каждой из них. Без такой организации было бы очень сложно найти соответствующую рукопись.
Деятельность по хранению и извлечению письменной информации из больших коллекций называется поиском информации (IR) . Эта деятельность становилась все более важной на протяжении веков, особенно с появлением таких изобретений, как бумага и печатный станок. Раньше здесь было занято всего несколько человек. Однако сейчас сотни миллионов людей ежедневно занимаются поиском информации, когда используют поисковую систему или выполняют поиск на рабочем столе.
Начало работы с поиском информации

Доктор Сьюз за 30 лет написал 46 детских книг. В его книгах рассказывалось о кошках, коровах и слонах, о гринчах и лораксе. Помните ли вы, какие существа были в какой истории? Если вы не родитель, только дети могут сказать вам, в какой серии историй Доктора Сьюза есть эти существа:
(КОРОВА и ПЧЕЛА) или ВОРОНЫ
Мы применим некоторые классические модели поиска информации, чтобы помочь нам решить эту проблему.
Очевидный подход — грубая сила: возьмите все 46 рассказов доктора Сьюза и начните читать. Для каждой книги отметьте, какая из них содержит слова КОРОВА и ПЧЕЛА, и в то же время найдите книги, содержащие слово ВОРОНЫ. Компьютеры справляются с этим гораздо быстрее, чем мы. Если у нас есть весь текст из книг доктора Сьюза в цифровой форме, скажем, в виде текстовых файлов, мы можем просто просмотреть файлы. Для небольшой коллекции, такой как книги доктора Сьюза, этот метод работает отлично.
Однако во многих ситуациях нам нужно больше. Например, совокупность всех данных, находящихся в данный момент в сети, слишком велика, чтобы с ней мог справиться grep. Нам также не просто нужны документы, соответствующие нашему состоянию, мы привыкли ранжировать их в соответствии с их релевантностью.
Другой подход, помимо grep, заключается в создании индекса документов в коллекции перед выполнением поиска. Указатель в IR похож на указатель в конце учебника. Мы составляем список всех слов (или терминов ) в каждом рассказе доктора Сьюза, исключая такие слова, как «the», «and», а также другие связки, предлоги и т. д. (они называются стоп-словами ). Затем мы представляем эту информацию таким образом, чтобы облегчить поиск терминов и идентификацию статей, в которых они содержатся.
Одним из возможных представлений является матрица с историями вверху и терминами, перечисленными в каждой строке. «1» в столбце означает, что термин появляется в истории этого столбца.
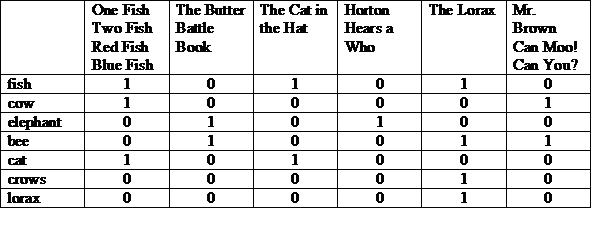
Мы можем рассматривать каждую строку или столбец как битовый вектор. Битовый вектор строки указывает, в каких статьях появляется термин. Битовый вектор столбца указывает, какие термины появляются в статье.
Возвращаясь к нашей исходной задаче:
(КОРОВА и ПЧЕЛА) или ВОРОНЫ
Мы берем битовые векторы для этих терминов и сначала выполняем побитовое И, затем выполняем побитовое ИЛИ к результату.
(100001 и 010011) или 000010 = 000011
Ответ: «Господин. Браун Кан Му! Не могли бы вы?" и «Лоракс». Это иллюстрация модели логического поиска , которая представляет собой модель «точного соответствия».
Предположим, нам нужно расширить матрицу, включив в нее все истории доктора Сьюза и все соответствующие термины в этих историях. Матрица значительно увеличится, и важно отметить, что большинство записей будут равны 0. Матрица, вероятно, не является лучшим представлением индекса. Нам нужно найти способ хранить только единицы.
Некоторые улучшения
Структура, используемая в IR для решения этой проблемы, называется инвертированным индексом . Мы ведем словарь терминов, а затем для каждого термина у нас есть список, в котором записаны документы, в которых этот термин встречается. Этот список называется списком сообщений . Односвязный список хорошо подходит для представления этой структуры, как показано ниже.
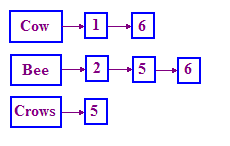
Если вы не знакомы со связанными списками, просто выполните поиск в Google по запросу «связанный список в C++», и вы найдете множество ресурсов, описывающих, как его создать и как его использовать. Мы рассмотрим это более подробно в следующем модуле.
Обратите внимание, что мы используем идентификаторы документов ( DocID ) вместо названия истории. Мы также сортируем эти DocID, поскольку это облегчает обработку запросов.
Как мы обрабатываем запрос? Для исходной задачи мы сначала находим список сообщений COW, затем список сообщений BEE. Затем мы «объединяем» их вместе:
- Сохраняйте маркеры в обоих списках и просматривайте два списка сообщений одновременно.
- На каждом этапе сравнивайте DocID, на который указывают оба указателя.
- Если они одинаковы, поместите этот DocID в список результатов, в противном случае переместите указатель на меньший docID.
Вот как мы можем построить инвертированный индекс:
- Присвойте DocID каждому интересующему документу.
- Для каждого документа определите соответствующие термины (токенизация).
- Для каждого термина создайте запись, состоящую из термина, DocID, в котором он встречается, и частоты в этом документе. Обратите внимание, что для определенного термина может быть несколько записей, если он встречается более чем в одном документе.
- Отсортируйте записи по терминам.
- Создайте словарь и список публикаций, обрабатывая отдельные записи для термина, а также объединяя несколько записей для терминов, которые встречаются более чем в одном документе. Создайте связанный список идентификаторов DocID (в отсортированном порядке). Каждый термин также имеет частоту, которая представляет собой сумму частот во всех записях термина.
Проект
Найдите несколько длинных текстовых документов, с которыми можно поэкспериментировать. Проект заключается в создании инвертированного индекса из документов с использованием описанных выше алгоритмов. Также вам потребуется создать интерфейс для ввода запросов и механизм их обработки. Найти партнера проекта можно на форуме.
Вот возможный процесс завершения этого проекта:
- Первое, что нужно сделать, — это определить стратегию идентификации терминов в документах. Составьте список всех стоп-слов, которые только можете придумать, и напишите функцию, которая считывает слова в файлах, сохраняет термины и удаляет стоп-слова. Возможно, вам придется добавить в список дополнительные стоп-слова при просмотре списка терминов из итерации.
- Напишите тестовые примеры CPPUnit для проверки вашей функции и make-файл, чтобы собрать все воедино для вашей сборки. Проверьте свои файлы в CVS, особенно если вы работаете с партнерами. Возможно, вы захотите узнать, как открыть свой экземпляр CVS для удаленных инженеров.
- Добавить обработку для включения данных о местоположении, то есть о том, в каком файле и где находится термин? Возможно, вам захочется провести расчет, чтобы определить номер страницы или номер абзаца.
- Напишите тестовые примеры CPPUnit, чтобы протестировать эту дополнительную функциональность.
- Создайте инвертированный индекс и сохраните данные о местоположении в записи каждого термина.
- Напишите больше тестовых случаев.
- Разработайте интерфейс, позволяющий пользователю вводить запрос.
- Используя описанный выше алгоритм поиска, обработайте инвертированный индекс и верните пользователю данные о местоположении.
- Обязательно включите тестовые примеры и для этой заключительной части.
Как и во всех проектах, используйте форум и чат, чтобы найти партнеров по проекту и поделиться идеями.
Дополнительная функция
Общий этап обработки во многих IR-системах называется стеммингом . Основная идея стемминга заключается в том, что пользователи, ищущие информацию о «извлечении», также будут заинтересованы в документах, содержащих информацию, содержащую слова «извлечь», «получено», «извлечение» и так далее. Системы могут быть подвержены ошибкам из-за плохого стемминга, поэтому это немного сложно. Например, пользователь, заинтересованный в «поиске информации», может получить документ под названием «Информация о золотистых ретриверах» из-за стемминга. Полезным алгоритмом стемминга является алгоритм Портера .