C++ Dil Eğiticisi
Bu serinin ilk bölümleri eğitim daha önce sunulan ve ileri düzey kavramlar hakkında daha fazla bilgi sağlayacağız. Bizim dinamik bellek ve nesneler ile sınıflar hakkında daha fazla ayrıntıya odaklanacağız. Kalıtım, polimorfizm, şablonlar, hariç tutmanızı öneririz. Bunları daha sonra İleri Düzey C++ kursunda inceleyeceğiz.
Nesneye Dayalı Tasarım
Bu mükemmel eğitim vermelidir. Belgede metodolojisini inceleyeceğiz.
3. Örnekle Öğrenin
Bu modüldeki odak noktamız, işaretçiler, nesne odaklı çok boyutlu diziler ve sınıflar/nesneler. Şu konuları gözden geçirin: örnekler. İyi bir programcı olmanın anahtarının önemini ne kadar vurgulasak azdır: pratik yapmak, pratik yapmak, pratik yapmaktır.1. Alıştırma: İşaretçilerle Daha Fazla Alıştırma
İşaretçilerle ilgili daha fazla alıştırma yapmak isterseniz bu kaynak bölümünü inceleyin.
Aşağıdaki programın sonucu ne olur? Lütfen programı çalıştırmayın çıkışı belirlemek için bellek resmini çizin.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Sonucu elle belirledikten sonra, programınızı çalıştırarak doğru.
2. Alıştırma: Sınıflar ve Nesnelerle İlgili Daha Fazla Alıştırma
Sınıflar ve nesneler üzerinde daha fazla alıştırma yapmak isterseniz burada iki küçük sınıfın uygulanmasının incelendiği bir kaynaktır. Al alıştırmalar yapın.
3. Alıştırma: Çok Boyutlu Diziler
Şu programı kullanabilirsiniz:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Bu programda "Bu hat nasıl çalışır?" şeklinde bir çizgi var. - anlayabilir misin? Açıklamamızı burada bulabilirsiniz.
3 boyutlu bir diziyi başlatan ve 3. boyutu dolduran bir program yazma değerini alır. Çözümümüzü burada bulabilirsiniz.
4. Alıştırma: Kapsamlı bir OO Tasarım Örneği
Burada ayrıntılı nesne odaklı tasarım örneği. baştan sona kadar takip edebilirsiniz. Son kod Java'da yazılmıştır ancak bu dili ne kadar uzaklaştırdığınıza göre tüm ayrıntıları gelmiş.
Lütfen bu örneğin tamamını incelemek için zaman ayırın. Harika bir sürecin ve onu destekleyen tasarım araçlarının bir resmini gösteriyoruz.
Birim Testi
Giriş
Testler, yazılım mühendisliği sürecinin kritik bir parçasıdır. Birim testi küçük bir test aracının işlevselliğini kontrol eden özel bir test türüdür. modülünü kullanabilirsiniz.Birim testi her zaman mühendis tarafından yapılır ve genellikle modülü kodladıkları sırada yapılır. Test sürücüleri Composer ve Database sınıflarını test etmek için kullanılanlar, birim testlerine örnektir.
Birim Testleri aşağıdaki özelliklere sahiptir. Bence...
- bir bileşeni yalıtılmış olarak test etme
- deterministik
- genellikle tek bir sınıfa karşılık gelir
- dış kaynaklara bağımlılıklardan kaçının, örneğin, veritabanları, dosyalar, ağ
- hızla uygulamak
- herhangi bir sırada çalıştırılabilir
Çevik projelerde ekibinize destek sağlayan ve büyük yazılım mühendisliği kuruluşlarında birim testlerinde tutarlılık sağlar. Bazı gelişmiş açık kaynak birim test çerçeveleri vardır: daha fazla bilgi edineceksiniz.
Birim testi kapsamında yapılan testler aşağıda açıklanmıştır.
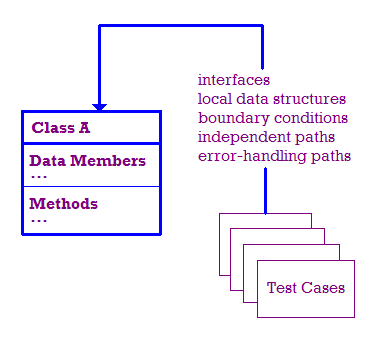
İdeal bir dünyada aşağıdaki testler yapılır:
- Modül arayüzü, bilginin girip çıktığını kontrol etmek için test edilir sağlayabilir.
- Yerel veri yapıları, verileri düzgün şekilde depoladıklarından emin olmak için incelenir.
- Modülün doğru çalıştığından emin olmak için sınır koşulları test edilir sınırlayan veya sınırlayan sınırlardır.
- Modül boyunca bağımsız yolları test ederek her yolun
Dolayısıyla modüldeki her ifade en az bir kez yürütülür.
- Son olarak, hataların düzgün şekilde ele alınıp alınmadığını kontrol etmemiz gerekir.
Kod Kapsamı
Gerçekte, "kod kapsamının" tam bir "kod kapsamını" elde edemeyiz test edildi. Kod kapsamı, bir yazılımın hangi parçalarının ve sistemin test senaryosu paketi tarafından yürütüldüğü (kapstığı) ve hangi kısımların yürütülmedi. %100 kapsama ulaşmaya çalışırsak gerçek kodu yazmaktansa birim testleri yazmaktan kaçının! Konu başlıklarıyla ilgili test edilir. Bu da kısa sürede genel bir üstel problemi analiz eder.

Bu diyagramda kırmızı çizgiler test edilmezken renksiz çizgiler test edilir.
%100 kapsam girişimi yerine, güvenimizi artıran testlere odaklanıyoruz modülün düzgün çalıştığından emin olun. Aşağıdaki gibi durumları test ederiz:
- Boş vakalar
- Aralık testleri (ör. pozitif/negatif değer testleri)
- Sıra dışı durumlar
- Hata durumları
- Çoğu zaman yürütülme olasılığı en yüksek olan yolları test etme
Birim Testi Çerçeveleri
Çoğu birim test çerçevesi, yürütülürken değerleri test etmek için onaylar kullanır bir yol sunar. Onaylamalar, bir koşulun doğru olup olmadığını kontrol eden ifadelerdir. İlgili içeriği oluşturmak için kullanılan sonucu başarılı, önemli olmayan başarısızlık veya ölümcül başarısızlık olabilir. Şu tarihten sonra: bir onay işlemi gerçekleştirilirse, sonuç kritik olmayan başarısızlığa dayanıyor. Önemli bir hata oluşursa mevcut işlev iptal edildi.
Testler, durumu ayarlayan veya modülünüzü manipüle eden bir koddan oluşur. bir dizi tahminle doğrulanabilir. Tüm onaylar testler başarılı olur, yani "doğru" dönerse test başarılı olur. aksi takdirde başarısız olur.
Bir test durumu bir veya daha fazla test içerir. Testleri, daha sonra mümkün olduğunca iyi bir şekilde test edilen kodun yapısını yansıtır. Bu kursta, bir proje yöneticisinin CPPUnit'i kullanmanızı öneririz. Bu çerçeveyle birim testleri yazabilir ve C++'ta oluşturup bunları otomatik olarak çalıştırarak, başarı veya başarısız olma durumu hakkında bir rapor olabilir.
PBM Birimi Montajı
CPPUnit kodunu şuradan indirin: SourceForge olarak yapılandırabilirsiniz. Uygun bir dizin bulun ve tar.gz dosyasını oraya yerleştirin. Ardından, aşağıdaki komutları (Linux, Unix'de) girin ve uygun cppunit dosyasını ad:
gunzip filename.tar.gz tar -xvf filename.tar
Windows kullanıyorsanız, tar.gz dosyasını ayıklayacak bir yardımcı program bulmanız gerekebilir. dosyası olarak da kaydedebilir. Sonraki adım, kitaplıkları derlemektir. CPU dizinine geçin. Burada, özel talimatlar içeren bir YÜKLEME dosyası vardır. Genellikle şunu çalıştırmanız gerekir:
./configure make install
Sorunlarla karşılaşırsanız YÜKLEME dosyasına bakın. Kitaplıklar genellikle cppunit/src/cppunit dizininde bulunur. Derlemenin çalışıp çalışmadığını kontrol etmek için cppunit/examples/simple dizinine gidip "make" yazın. Eğer her şey düzgün derlenir ve hazırsınız demektir.
Google Ads ile sorunsuz bir şekilde burada bulabilirsiniz. Lütfen bu eğiticiyi inceleyerek karmaşık sayı sınıfını ve ilişkili sayı sınıfını oluşturun olanak sağlar. cppunit/examples dizininde birkaç ek örnek vardır.
Bunu Neden Yapmam Gerekiyor???
Birim testi, sektörde çeşitli nedenlerle kritik bir öneme sahiptir. Artık bir neden vardır: Yaptığımız işi kontrol ederken bir şekilde yardımcı oluyorum. Çok küçük bir program geliştiriyor olsak bile içgüdüsel olarak programımızın bekleneni yaptığından emin olmak için bir tür denetleyici veya sürücü yazması gerekir.
Mühendisler uzun tecrübelerinden sonra bir programın başarılı olma olasılığının ilk denemede çok küçüktür. Ünite testleri bu fikir üzerine inşa edilir ve kendilerini kontrol eden ve tekrarlanabilir olan uygulamalardır. Onaylar, manuel olarak çıktı denetleniyor. Sonuçları yorumlamak kolay olduğu için (testin, başarısız olursa testler tekrar tekrar çalıştırılabilir. Böylece, testlerin bu da, kodunuzu değişime karşı daha dirençli hale getiren bir güvenlik ağıdır.
Bunu somut bir şekilde ifade edelim: Tamamlanmış kodunuzu CVS ile mükemmel çalışır. Bir süre daha mükemmel şekilde çalışmaya devam ediyor. Sonra bir gün kodunuzu başka biri değiştirdiğinde. Birisi er ya da geç bozulacak kodunuz. Sence kendiliğinden mi fark ederler? Olası değil. Ancak birim testlerini yazmaktansa, bunları her gün otomatik olarak çalıştırabilen sistemler vardır. Bunlara sürekli entegrasyon sistemleri denir. O mühendis, X kodu kırarsa sistem sorunu düzeltene kadar onlara sakıncalı e-postalar gönderir. somut olarak ortaya koyar. Mühendis X SİZ olsanız bile!
Yazılım geliştirmenize ve bu yazılımı güvende tutmanıza yardımcı olmanın yanı sıra durumunda, birim testi:
- Yürütülebilir bir spesifikasyon ve senkronize edilebilen dokümanlar oluşturur kodla birlikte girin. Diğer bir deyişle, davranış biçimi vardır.
- Gereksinimleri uygulamadan ayırmanıza yardımcı olur. Çünkü şu iddiada bulunuyorsunuz: bunu açıkça görme fırsatınız olur. fikir edinmek yerine davranışını daha iyi hale getirebilirsiniz.
- Denemeleri destekler. Güvenlik ağınız varsa sizi ne zaman modülün davranışını bozarsanız yeni bir şey deneme ve tasarımlarınızı yeniden yapılandırabilirsiniz.
- Tasarımlarınızı iyileştirir. Kapsamlı birim testleri yazmak genellikle kodunuzu daha test edilebilir hale getirin. Test edilebilir kod, test edilemez olandan genellikle daha modülerdir girin.
- Kaliteyi yüksek tutar. Kritik bir sistemdeki küçük bir hata, şirketlerin kullanıcının mutluluğunu veya güvenini kaybetmesine neden olabilir. İlgili içeriği oluşturmak için kullanılan güvenli bir netlik sağlar ve birim testlerinin bu olasılığı azaltır. Hataları yakalayarak aynı zamanda kalite güvencesi ekiplerinin daha gelişmiş ve zorlu bariz hataları bildirmek yerine hata senaryoları
Composer veritabanı uygulaması için CPPUnit kullanarak birim testleri yazmak için zaman ayırın. Yardım için cppunit/examples/ dizinine bakın.
Google Nasıl Yönetiliyor?
GirişOrta Çağ'da bir keşişin binlerce el yazmasına baktığını arşivleri de bulunuyor.“Aristote’in sözü nerede...”

Neyse ki el yazmaları içeriğe göre düzenlenmiş ve kağıda yazılmış içindeki bilgilerin alınmasını kolaylaştırmak için özel simgeler içeren her biri. Bu tür bir organizasyon olmasaydı, işe yarar el yazması.
Büyük koleksiyonlardan yazılı bilgileri depolama ve alma etkinliği Bilgi Alma (IR) olarak adlandırılır. Bu etkinlik, sektördeki yüzyıllardır, özellikle de kağıt ve matbaa gibi buluşlarla basın. Eskiden yalnızca birkaç insanla doluydu. Şimdi, ancak her gün yüz milyonlarca insan bilgi ediniyor. masaüstünde arama yaptıklarında veya arama motoru kullandıklarında.
Bilgi Almaya Başlarken

Dr. Seuss, 30 yılda 46 çocuk kitabı yazdı. Kitapları sırıtıyor, sırıtan fillerle gerçekleşiyordu. Hatırlıyor musun hangi yaratıkların yer aldığı hikaye? Ebeveyn değilseniz yalnızca çocuklar bunu yapabilir yaratıkların yer aldığı Dr. Seuss hikayeleri setini söyle:
(COW ve BEE) veya CROWS
Bu sorunu çözmemize yardımcı olmak için bazı klasik bilgi edinme modellerini uygulayacağız sorun.
Bariz bir yaklaşım, kaba kuvvettir: 46 Dr. Seuss hikayesinin tümünü edinin ve okumayı öğreteceğim. Her kitap için hangilerinde COW ve BEE kelimelerinin olduğuna dikkat edin ve aynı zamanda CROWS kelimesini içeren kitapları arayın. Bilgisayarlar çok büyük bizim için çok daha hızlı olacak. Dr. Seuss kitaplarındaki tüm metin dosyaları gözden geçirebiliyoruz. Örneğin, gibi küçük bir koleksiyona sahipsiniz. Bu teknik işe yarıyor.
Ancak daha fazlasına ihtiyaç duyduğumuz birçok durum var. Örneğin, grep'in işleyemeyeceği kadar büyük olduğundan, şu anda çevrimiçi olan tüm verilerin oranı. Ayrıca, yalnızca koşullarımıza uygun belgeleri istiyoruz. alaka düzeyine göre sıralanmasını sağlayabilirsiniz.
grep dışındaki bir yaklaşım, koleksiyondaki dokümanların dizinini oluşturmaktır. bir ön plana çıkarmaya çalışın. IR'deki dizin, arkasını bulalım. Her bir kelimedeki tüm kelimelerin (veya terimlerin) bir listesini "the", "ve" ve diğer bağlantı gibi ifadeleri çıkararak Dr. Seuss'un hikayesine edatlar vb. (bunlara durduracak kelimeler denir). Bu durumda, Bu bilgiler, terimleri bulmayı ve tanımlamayı kolaylaştıracak şekilde, hikaye anlatacağım.
Olası bir temsil, hikayenin üstte yer aldığı bir matristir. her satırda listelenen terimleri girin. Bir sütundaki "1", terimin göründüğünü belirtir yazabilirsiniz.
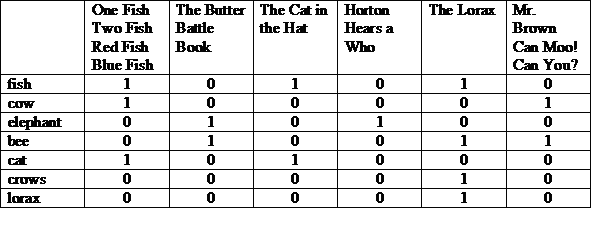
Her bir satır veya sütunu bir bit vektör olarak görüntüleyebiliriz. Bir satırın bit vektörü, haberde geçiyor. Bir sütunun bit vektörü hangi terimlerin görebilirsiniz.
İlk sorunumuza dönelim:
(COW ve BEE) veya CROWS
Bu terimlerin bit vektörlerini alıp önce bit vektörü uygularız ve ardından bir şekilde ilişkilendirmenizi sağlar.
(100001 ve 010011) veya 000010 = 000011
Cevap: “Bay Kahverengi Can Moo! Yapabilir misin?" ve "The Lorax". Bu bir resimdir "tam eşleme" modeli olan Boole Alma modelinin temelini oluşturur.
Matrisi tüm Dr. Seuss hikayelerini ve diğer tüm alakalı terimler aranır. Matris önemli ölçüde büyüyecek ve bu da gözlem, girişlerin çoğunun 0 olacaktır. Matrisler muhtemelen en iyi seçenek değildir. temsil eder. Yalnızca bu ilkeleri depolamanın bir yolunu bulmamız gerekiyor.
Bazı Geliştirmeler
Bu sorunu çözmek için IR'de kullanılan yapıya ters çevrilmiş dizin denir. Bir terim sözlüğü tutarız ve her terim için birer listemiz olur terimin geçtiği belgelerin kaydedildiği belgeler. Bu listeye yayınlar adı verilir liste. Tek başına bağlı bir liste, bu yapıyı gösterildiği gibi en iyi şekilde temsil eder. bölümüne göz atın.
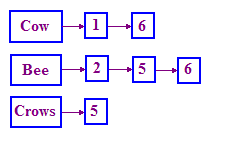
Bağlı listeleri bilmiyorsanız "bağlantılı
listesini inceleyebilirsiniz. Bir tane, nasıl oluşturulacağını ve nasıl
nasıl kullanıldığına bakalım. Bu konuyu sonraki modülde daha ayrıntılı olarak ele alacağız.
Belge kimliklerinde (DocIDs) kullanılan iş hayatına dokunun. Ayrıca, sorguların işlenmesini kolaylaştırdıkları için bu DocID'leri de sıralarız.
Sorguları nasıl işleriz? Orijinal sorun için öncelikle COW yayınlarını buluruz. listesi, ardından BEE yayınlar listesi. Daha sonra bunları "birleştiriyoruz":
- Her iki liste için işaretçileri kullanın ve iki ilan listesini inceleyin olanak tanır.
- Her iki adımda, her iki işaretçinin işaret ettiği DocID'yi karşılaştırın.
- Bunlar aynıysa DocID'yi bir sonuç listesine yerleştirin, aksi takdirde işaretçiyi ilerletin daha küçük docID'ye işaret eder.
Ters çevrilmiş bir dizini şu şekilde oluşturabiliriz:
- İstediğiniz her dokümana bir DocID atayın.
- Her doküman için, belgenin ilgili terimlerini belirleyin (tokenize).
- Her bir terim için, ilişkili olduğunu ve söz konusu sıklığın ne olduğunu belirtir. Birden fazla belirli bir terim birden fazla dokümanda yer alıyorsa kayıtları.
- Kayıtları terime göre sıralayın.
- için tek kayıtları işleyerek sözlük ve gönderiler listesini oluşturun ve ayrıca, daha fazla arama teriminde geçen terimlere ait birden çok kaydı birleştirerek birden fazla dokümandır. DocID'lerin bağlı listesini oluşturun (sıralı olarak). Her biri teriminin, tüm kayıtlardaki sıklıkların toplamı olan bir sıklığı da vardır. bir terim olabilir.
Proje
Deneme yapabileceğiniz birkaç uzun düz metin dokümanı bulun. İlgili içeriği oluşturmak için kullanılan dokümanlardan, algoritma yardımıyla ters çevrilmiş bir dizin oluşturmaktır. 'ne başvurun. Ayrıca, sorguların girişi için bir arayüz oluşturmanız gerekir. ve bunları işlemek için bir motor. Forumda proje iş ortağı bulabilirsiniz.
Bu projenin tamamlanması için gereken süreç şu şekildedir:
- İlk olarak, belgelerdeki terimleri tanımlamak için bir strateji belirlemeniz gerekir. Aklınıza gelen tüm yok sayılabilecek kelimelerin bir listesini yapın ve dosyalardaki kelimeleri okur, şartları kaydeder ve yok sayılan kelimeleri eler. Bu listeyi incelerken, listenize daha fazla engellenecek kelime eklemeniz gerekebilir. terimleri alır.
- İşlevinizi test etmek için PBMUnit test senaryoları ve her şeyi getirmek için bir Makefile yazın bir araya getirir. Dosyalarınızı CVS'de kontrol edin, özellikle de iş ortaklarıyla birlikte çalışma. CVS örneğinizi nasıl açacağınızı araştırmak isteyebilirsiniz. geri dönelim.
- Konum verilerini, yani hangi dosya ve nerede konum verilerini dahil etmek için işleme ekleyin arama terimi bulunur mu? Belirlenen bu terimlerin hedeflerini belirlemek için sayfa numarası veya paragraf numarası.
- Bu ek işlevi test etmek için PBMUnit test senaryoları yazın.
- Ters bir dizin oluşturun ve konum verilerini her terimin kaydında saklayın.
- Daha fazla test durumu yazın.
- Kullanıcının sorgu girmesine izin verecek bir arayüz tasarlayın.
- Yukarıda açıklanan arama algoritmasını kullanarak, ters çevrilmiş dizini işleyin ve kullanıcıya konum verilerini döndürür.
- Bu son kısım için test senaryolarına da yer verdiğinizden emin olun.
Tüm projelerde yaptığımız gibi, proje iş ortakları bulmak için forumu ve sohbeti kullanın ve fikirlerinizi paylaşmak istiyoruz.
Ekstra Özellik
Birçok IR sisteminde yaygın olarak kullanılan bir işleme adımı, karmaşıklık olarak adlandırılır. İlgili içeriği oluşturmak için kullanılan türetmenin arkasındaki ana fikir, kullanıcıların "edinme" ile ilgili bilgi arayan "al", "alın" ve "alın" ifadelerini içeren bilgiler içeren belgelerle de "alındı", "alma" vb. Sistemler, korelasyon nedeniyle bu yüzden bu biraz zor. Örneğin, bir ürünle ilgilenen "bilgi edinme" bölümünde "Gol ile İlgili Bilgi" başlıklı bir doküman örtüşme nedeniyle "Retriever". Türetme için yararlı bir algoritma Porter algoritması.