Introducción a la programación y C++
Este tutorial en línea continúa con conceptos más avanzados. Lee la Parte III. En este módulo, nos enfocaremos en el uso de punteros y comenzar a usar objetos.
Aprendizaje del ejemplo 2
En este módulo, nos enfocaremos en adquirir más práctica con la descomposición, comprender los punteros y comenzar a usar objetos y clases. Revisa los siguientes ejemplos. Escribe los programas por tu cuenta cuando se te solicite o realiza los experimentos. No podemos enfatizar lo suficiente que la clave para convertirse en un buen programador es la práctica, la práctica y la práctica.
Ejemplo 1: Más práctica de descomposición
Considera el siguiente resultado de un juego simple:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
La primera observación es el texto introductorio que se muestra una vez por programa. ejecución. Necesitamos un generador de números al azar para definir la distancia del enemigo para cada ronda. Necesitamos un mecanismo para obtener la entrada de ángulo del jugador está en una estructura en bucle, ya que se repite hasta que alcanzamos al enemigo. También necesitas una función para calcular la distancia y el ángulo. Por último, debemos llevar un registro de cuántos disparos se necesitaron para golpear al enemigo, y cuántos enemigos tenemos golpear durante la ejecución del programa. Aquí hay un posible esquema para el programa principal.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
El procedimiento de Disparo controla la ejecución del juego. En esa función, llamamos un generador de números aleatorios para conocer la distancia del enemigo, obtener la información del jugador y calcular si golpeó o no al enemigo. El la condición de guardia en el bucle es qué tan cerca estamos de golpear al enemigo.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Debido a las llamadas a cos() y sin(), necesitarás incluir matemáticas. Probar escribir este programa, es una buena práctica para la descomposición de problemas del código C++ básico. Recuerda hacer solo una tarea en cada función. Este es el más sofisticado que hemos escrito hasta ahora, así que puede llevarte para hacerlo.Esta es nuestra solución.
Ejemplo 2: Practica con punteros
Hay cuatro puntos que debes recordar cuando trabajes con punteros:- Los punteros son variables que contienen direcciones de memoria. Mientras se ejecuta un programa,
Todas las variables se almacenan en la memoria, cada una en su dirección o ubicación únicas.
Un puntero es un tipo especial de variable que contiene una dirección de memoria en lugar
que un valor de datos. Así como los datos se modifican cuando se usa una variable normal,
el valor de la dirección almacenada en un puntero se modifica como una variable del puntero
de que se manipule. Por ejemplo:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Solemos decir que un puntero "puntos" a la ubicación en la que se almacena
(la “puntero”). En el ejemplo anterior, intptr apunta al punto
5)
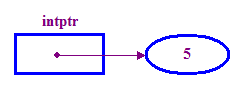
Observa el uso de la función "new" para asignar memoria a nuestro punto. Esto es algo que debemos hacer antes de intentar acceder al punto.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.El operador * se usa para la desreferencia en C. Uno de los errores más comunes Cuando trabajan con punteros, los programadores de C/C++ olvidan inicializar la punta. A veces, esto puede causar fallas en el tiempo de ejecución es una ubicación en la memoria que contiene datos desconocidos. Si intentamos modificar este datos, podemos causar daños sutiles en la memoria, por lo que es un error difícil rastrearlo.
- La asignación de un puntero entre dos punteros hace que apunten al mismo puntero.
Así que la asignación y = x; hace y apunta a la misma punta que x. Asignación del puntero
no toca el punto. Solo cambia un puntero para que tenga la misma ubicación
como otro puntero. Después de la asignación del puntero, los dos punteros “share” el
punto.
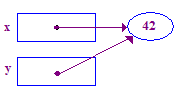
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
A continuación, se muestra un seguimiento de este código:
| 1. Asigna dos punteros x e y. La asignación de los punteros no asignan puntos. | 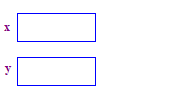 |
| 2. Asigna un punto y establece la x para que apunte a ella. | 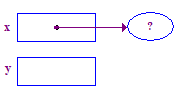 |
| 3. Anula la referencia x para almacenar 42 en su punta. Este es un ejemplo básico de la operación de desreferencia. Comienza en x, sigue la flecha hacia arriba para acceder su punta. | 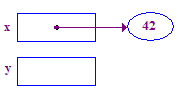 |
| 4. Intenta anular la referencia y almacenar 13 en su punto. Esta falla porque y tiene no tiene una punta, nunca se le asignó una. | 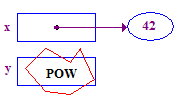 |
| 5. Asignar y = x; para que la Y apunte al punto de x. Ahora x e y apuntan a la misma persona, que está "compartiendo". | 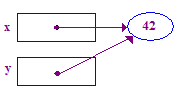 |
| 6. Intenta anular la referencia y almacenar 13 en su punto. Esta vez funciona, porque la tarea anterior te dio un puntero. | 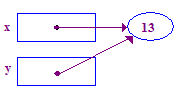 |
Como puedes ver, las imágenes son muy útiles para comprender el uso del puntero. Aquí tienes otro ejemplo.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Observa que, en este ejemplo, nunca asignamos memoria con el bloque como "autor" y "título" usando un operador lógico. Declaramos una variable de número entero normal y la manipulamos con punteros.
En este ejemplo, ilustramos el uso del operador de eliminación, que desasigna del montón de memoria y cómo podemos realizar la asignación a estructuras más complejas. Abordaremos organización de la memoria (pila y del entorno de ejecución) en otra lección. Por ahora, solo Se considera que el montón es un almacén gratuito de memoria disponible para programas en ejecución.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
En este ejemplo final, mostramos cómo se usan los punteros para pasar valores por referencia. a una función. Así es como modificamos los valores de las variables dentro de una función.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Si quitáramos el “&” de los argumentos en la definición de la función Duplicar, pasamos las variables "por valor", es decir, se hace una copia del valor de la variable. Cualquier cambio realizado en la variable en la función modifica la copia. No modifican la variable original.
Cuando se pasa una variable por referencia, no pasamos una copia de su valor, pasamos la dirección de la variable a la función. Cualquier modificación que que hagamos a la variable local modifica en realidad la variable original que se pasó.
Si eres programador de C, esto es un nuevo giro. Podríamos hacer lo mismo en C Declara Duplicate() como Duplicate(int *x), En ese caso, x es un puntero a un int, luego llama a Duplicate() con el argumento &x (dirección de x) y usa desreferencias de x en Duplicate() (consulta a continuación). Pero C++ proporciona una manera más sencilla de pasar valores a funciones de referencia, a pesar de que la antigua “C” manera de hacerlo aún funciona.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Ten en cuenta que, con las referencias de C++, no necesitamos pasar la dirección de una variable, ni necesitamos hacer referencia a la variable dentro de la función llamada.
¿Qué genera el siguiente programa? Haz una imagen de la memoria para averiguarlo.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Ejecuta el programa para ver si respondiste correctamente.
Ejemplo 3: Pasa valores por referencia
Escribe una función llamada speed(), que tome como entrada la velocidad de un vehículo y una cantidad. La función suma la cantidad a la velocidad para acelerar el vehículo. El parámetro de velocidad se debe pasar por referencia y, por último, importe por valor. Esta es nuestra solución.
Ejemplo n.o 4: Clases y objetos
Considera la siguiente clase:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Observa que las variables de miembro de clase tienen un guion bajo final. Esto se hace para diferenciar entre variables locales y variables de clase.
Agrega un método de disminución a esta clase. Esta es nuestra solución.
Las maravillas de la ciencia: Informática
Ejercicios
Al igual que en el primer módulo de este curso, no proporcionamos soluciones a ejercicios ni proyectos.
Recuerda que un buen programa...
... se descompone lógicamente en funciones en las que cualquier función realiza una sola tarea.
... tiene un programa principal que se asemeja a un esquema de lo que hará el programa.
... tiene nombres descriptivos de funciones, constantes y variables.
... usa constantes para evitar cualquier “magia” números en el programa.
Tiene una interfaz de usuario fácil de usar.
Ejercicios de calentamiento
- Ejercicio 1
El número entero 36 tiene una propiedad peculiar: es un cuadrado perfecto y también es la suma de los números enteros del 1 al 8. El siguiente número es 1225, es 352, y la suma de los números enteros del 1 al 49. Encontrar el siguiente número un cuadrado perfecto y también la suma de una serie 1...n. Este próximo número puede ser mayor que 32,767. Puedes usar funciones de biblioteca que conozcas, (o fórmulas matemáticas) para que tu programa se ejecute más rápido. También es posible escribir este programa usando bucles for para determinar si un número es perfecto cuadrado o la suma de una serie. (Nota: Según la máquina y el programa, puede llevar bastante tiempo encontrar ese número).
- Ejercicio 2
Tu librería universitaria necesita tu ayuda para estimar su negocio para la próxima año. La experiencia ha demostrado que las ventas dependen en gran medida de la necesidad de un libro. para un curso o solo opcional, y si se usó o no en la clase antes. Un libro de texto nuevo y obligatorio se venderá al 90% de los posibles inscripciones, pero si ya se utilizó en la clase anteriormente, solo el 65% lo comprará. De forma similar, el 40% de los potenciales inscripciones comprará un libro de texto nuevo y opcional, pero si se usó en la clase antes de que solo el 20% lo compre. (Ten en cuenta que “usado” aquí no significa que los libros son de segunda mano).
Escribir un programa que acepte como entrada una serie de libros (hasta que el usuario ingrese un centinela). Por cada libro solicitado: un código para el libro, el costo de la copia única para el libro, el número actual de libros disponibles, la posible inscripción de la clase, y datos que indiquen si el libro es obligatorio, opcional, si es nuevo o se usó en el pasado. Como salida muestra toda la información de entrada en una pantalla bien formateada junto con la cantidad de libros que se deben pedir (si los hay, ten en cuenta que solo se piden libros nuevos) el costo total de cada pedido.
Luego, después de completar toda la entrada, muestra el costo total de todos los pedidos de libros y la ganancia esperada si la tienda paga el 80% del precio de lista. Como aún no hemos analizamos cualquier manera de tratar con un gran conjunto de datos que ingresan a un programa (permanece ajustado!), procesa un libro a la vez y muestra la pantalla de salida de ese libro. Luego, cuando el usuario termine de ingresar todos los datos, tu programa debería generar los valores totales y de ganancias.
Antes de comenzar a escribir código, tómate un tiempo para pensar en el diseño de este programa. Desglosar en un conjunto de funciones y crear una función main() que se lea de la siguiente manera: esboza tu solución al problema. Asegúrate de que cada función realice una tarea.
Este es un resultado de muestra:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Proyecto de base de datos
En este proyecto, crearemos un programa C++ completamente funcional que implementa una interfaz de la aplicación de base de datos.
Nuestro programa nos permitirá administrar una base de datos de compositores y la información relevante. sobre ellas. Las funciones del programa incluyen las siguientes:
- La capacidad de agregar un nuevo compositor
- La capacidad de clasificar a un compositor (es decir, indicar cuánto nos gusta o no nos gusta la música del compositor)
- La capacidad de ver todos los compositores en la base de datos
- La capacidad de ver todos los compositores según su clasificación
"Hay dos formas de construir un Una forma es hacer que sea tan simple ninguna deficiencia, y la otra es hacerlo tan complicado que no haya no presentan deficiencias evidentes. El primer método es mucho más difícil". - C.A.R. Hoare
Muchos de nosotros aprendimos a diseñar y programar mediante un método enfoque. La pregunta central con la que comenzamos es “¿Qué debe hacer el programa?”. Mié descomponer la solución a un problema en tareas, cada una de las cuales resuelve una parte el problema. Estas tareas se asignan a funciones en nuestro programa que se llaman secuencialmente de main() o de otras funciones. Este enfoque paso a paso es ideal para algunas problemas que necesitamos resolver. Pero la mayoría de las veces, nuestros programas no son solo lineales secuencias de tareas o eventos.
Con un enfoque orientado a objetos (OO), comenzamos con la pregunta “¿Qué es lo los objetos que modelo?". En lugar de dividir un programa en tareas, como se describe arriba, la dividimos en modelos de objetos físicos. Estos objetos físicos tienen un estado definido por un conjunto de atributos y un conjunto de comportamientos o acciones que que pueden realizar. Las acciones pueden cambiar el estado del objeto o podrían invocar acciones de otros objetos. La premisa básica es que un objeto "sabe" cómo de hacer las cosas por sí solo.
En el diseño fuera de la oficina, definimos los objetos físicos en términos de clases y objetos. atributos y comportamientos. Generalmente, hay una gran cantidad de objetos en un programa de OO. Sin embargo, muchos de estos objetos son básicamente los mismos. Ten en cuenta lo siguiente.
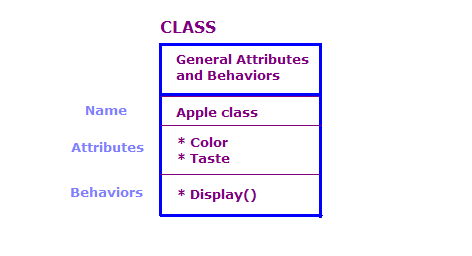
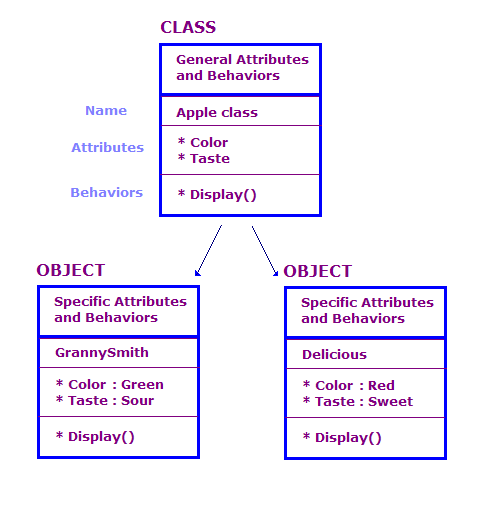
En este diagrama, definimos dos objetos que son de la clase Apple. Cada objeto tiene los mismos atributos y acciones que la clase, pero el objeto define los atributos para un tipo específico de manzana. Además, el panel muestra los atributos de ese objeto en particular, p.ej., “Verde” y "Sour".
Un diseño OO consta de un conjunto de clases, los datos asociados con estas clases, y el conjunto de acciones que pueden realizar las clases. También necesitamos identificar formas en que interactúan las diferentes clases. Esta interacción la pueden realizar objetos de una clase que invoca las acciones de objetos de otras clases. Por ejemplo, podría tener una clase AppleOutputer que genera el color y el sabor de un array de los objetos Apple, llamando al método Display() de cada objeto Apple.
Estos son los pasos que realizamos para hacer un diseño fuera de la oficina:
- Identificar las clases y definir en general lo que es un objeto de cada clase que almacena como datos y qué puede hacer un objeto.
- Cómo definir los elementos de datos de cada clase
- Definir las acciones de cada clase y cómo se pueden realizar algunas acciones de una clase
implementadas mediante acciones de otras clases relacionadas.
En un sistema grande, estos pasos ocurren de forma iterativa en diferentes niveles de detalle.
Para el sistema de base de datos de Composer, necesitamos una clase Composer que encapsule todos los elementos los datos que queremos almacenar en un compositor individual. Un objeto de esta clase puede se asciende o descenderá a sí misma (cambiar su clasificación) y mostrar sus atributos.
También necesitamos una colección de objetos Composer. Para esto, definimos una clase Database que administra los registros individuales. Un objeto de esta clase puede agregar o recuperar Composer y mostrar los individuales mediante la invocación de la acción de visualización de un objeto de Composer.
Por último, necesitamos algún tipo de interfaz de usuario para proporcionar operaciones interactivas en la base de datos. Esta es una clase de marcador de posición; es decir, realmente no sabemos de la interfaz de usuario, pero sabemos que la necesitaremos. Tal vez será gráfico, tal vez basado en texto. Por ahora, definimos un marcador de posición que podemos rellenar más tarde.
Ahora que identificamos las clases para la aplicación de la base de datos del compositor, el siguiente paso es definir los atributos y las acciones para las clases. De una forma más compleja, nos sentaríamos con lápiz y papel o UML o tarjetas CRC o OOD para asignar la jerarquía de clases y cómo interactúan los objetos.
Para nuestra base de datos de Composer, definimos una clase de Composer que contiene los objetos datos que queremos almacenar en cada compositor. También contiene métodos para manipular clasificaciones y la visualización de los datos.
La clase Database necesita algún tipo de estructura para contener objetos Composer. Debemos poder agregar un nuevo objeto de Composer a la estructura, así como recuperar un objeto de Composer específico. También nos gustaría mostrar todos los objetos ya sea por orden de entrada o por clasificación.
La clase de interfaz de usuario implementa una interfaz accionada por menús, con controladores que acciones de llamada en la clase Database.
Si las clases se comprenden fácilmente y sus atributos y acciones son claros, igual que en la aplicación del compositor, el diseño de las clases es relativamente sencillo. Sin embargo, si tienes alguna pregunta sobre cómo se relacionan e interactúan las clases, es mejor hacer un dibujo primero y trabajar en los detalles antes de empezar al código.
Una vez que tenemos una imagen clara del diseño y lo hayamos evaluado (más información sobre este pronto), definimos la interfaz para cada clase. No nos preocupamos por la implementación. en este punto? ¿Qué son los atributos y las acciones, y qué partes de una clase estados y acciones están disponibles para otras clases.
En C++, normalmente hacemos esto definiendo un archivo de encabezado para cada clase. El compositor tiene miembros de datos privados para todos los datos que queremos almacenar en un compositor. Necesitamos descriptores de acceso (métodos get) y mutadores (métodos "set"), así como los acciones principales para la clase.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
La clase Database también es sencilla.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Observa cómo encapsulamos cuidadosamente los datos específicos del compositor en un . Podríamos haber colocado una struct o clase en la clase Database para representar el Composer, y accediste a él directamente desde allí. Pero eso sería “subobjetivación”, es decir, no estamos modelando tanto con objetos como pudiéramos.
Lo verás cuando comiences a trabajar en la implementación de Composer y Database. , es mucho más claro tener una clase Composer independiente. En particular, tener operaciones atómicas separadas en un objeto de Composer simplifica enormemente la implementación de los métodos Display() en la clase Database.
Por supuesto, también existe la "objetividad excesiva" dónde intentamos que todo sea una clase, o tenemos más clases de las que necesitamos. Lleva practicar para encontrar el equilibrio adecuado y descubrirás que los programadores individuales tendrán opiniones diferentes.
Determinar si estás objetivando demasiado o poco a menudo se puede clasificar cuidadosamente diagramando tus clases. Como mencioné antes, es importante preparar una clase antes de comenzar a programar y esto puede ayudarte a analizar tu enfoque. Un problema común la notación usada para este propósito es UML (Lenguaje de modelado unificado) Ahora que tenemos las clases definidas para los objetos Composer y Database, debemos una interfaz que permite al usuario interactuar con la base de datos. Un menú sencillo hazlo:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Podríamos implementar la interfaz de usuario como una clase o como un programa de procedimiento. No todo en un programa de C++ tiene que ser una clase. De hecho, si el procesamiento es secuencial o orientado a las tareas, como en este programa de menú, está bien implementarlo de manera procedimental. Es importante implementarlo de manera que siga siendo un "marcador de posición", Es decir, si queremos crear una interfaz gráfica de usuario en algún momento, deberíamos y no es necesario cambiar nada en el sistema que en la interfaz de usuario.
Lo último que necesitamos para completar la solicitud es un programa para probar las clases. Para la clase Composer, queremos un programa main() que tome entradas, propague una composer y, luego, lo muestra para asegurarte de que la clase funcione correctamente. También queremos llamar a todos los métodos de la clase Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Necesitamos un programa de prueba similar para la clase Database.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Ten en cuenta que estos programas de prueba sencillos son un buen primer paso, pero requieren para inspeccionar manualmente los resultados y asegurarse de que el programa funcione correctamente. Como un sistema se hace más grande, la inspección manual de los resultados rápidamente se vuelve poco práctica. En una lección posterior, presentaremos los programas de prueba con verificación automática en el formulario de las pruebas de unidades.
El diseño de nuestra aplicación ya está completo. El siguiente paso es implementar los archivos .cpp para las clases y la interfaz de usuario.Para empezar, continúa y Copia y pega el .h y el código del controlador de prueba anterior en archivos y compílalos.Usa los conductores de prueba para probar las clases. Luego, implementa la siguiente interfaz:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Usa los métodos que definiste en la clase Database para implementar la interfaz de usuario. Haz que tus métodos sean a prueba de errores. Por ejemplo, una clasificación siempre debe estar en el rango De 1 a 10. Tampoco permitas que nadie agregue 101 compositores, a menos que planees cambiar de datos en la clase Database.
Recuerda: Todo tu código debe seguir nuestras convenciones de programación, que se repiten aquí para su comodidad:
- Cada programa que escribimos comienza con un comentario de encabezado que proporciona el nombre del el autor, su información de contacto, una breve descripción y el uso (si corresponde). Cada función o método comienza con un comentario sobre la operación y el uso.
- Agregamos comentarios explicativos con oraciones completas, siempre que el código no se documenta a sí mismo, por ejemplo, si el procesamiento es complicado, no evidente interesantes o importantes.
- Usa siempre nombres descriptivos: las variables son palabras en minúscula separadas por _, como en my_variable. Los nombres de funciones/métodos usan letras mayúsculas para los palabras, como en MyExcitingFunction(). Las constantes comienzan con una "k". y usar letras mayúsculas para marcar palabras, como en kDaysInWeek.
- La sangría es un múltiplo de dos. El primer nivel tiene dos espacios; si más la sangría, usamos cuatro espacios, seis espacios, etc.
¡Bienvenido al mundo real!
En este módulo, presentaremos dos herramientas muy importantes que se usan en la mayoría de los casos de ingeniería de software organizaciones. El primero es una herramienta de compilación y el segundo es una herramienta de administración en un sistema de archivos. Ambas herramientas son esenciales en la ingeniería de software industrial, muchos ingenieros suelen trabajar en un sistema grande. Estas herramientas ayudan a coordinar y controlar los cambios en la base de código y proporcionar un medio eficiente de compilación y la vinculación de un sistema de muchos archivos de programas y encabezados.
Archivos makefile
El proceso de compilación de un programa generalmente se gestiona con una herramienta de compilación, que compila y vincula los archivos requeridos en el orden correcto. Muy a menudo, los archivos C++ tienen dependencias, por ejemplo, una función llamada en un programa reside en otro . O tal vez se necesite un archivo de encabezado para varios archivos .cpp diferentes. R La herramienta de compilación descifra el orden de compilación correcto a partir de estas dependencias. Si y, además, compilar solo los archivos que hayan cambiado desde la última compilación. Esto puede ahorrarte un mucho tiempo en sistemas con cientos o miles de archivos.
Una herramienta de compilación de código abierto llamada Make se suele usar. Para obtener más información, lee a través de esta artículo. Ve si puedes crear un gráfico de dependencias para la aplicación Composer Database. y, luego, traducirlo a un archivo makefile.Aquí está nuestra solución.
Sistemas de administración de configuración
La segunda herramienta que se usa en la ingeniería de software industrial es la administración de configuración. (CM). Se usa para administrar el cambio. Supongamos que Bob y Susan son escritores de tecnología y ambas trabajan para actualizar un manual técnico. Durante una reunión, sus el gerente les asigna a cada una una sección del mismo documento para que la actualice.
El manual técnico está almacenado en una computadora a la que pueden acceder Bob y Susan. Sin ninguna herramienta o proceso de CM implementado, podrían surgir varios problemas. Uno posible es que la computadora que almacena el documento esté configurada para que Bob y Susan no pueden trabajar en el manual al mismo tiempo. Esto demoraría reducirlos considerablemente.
Surge una situación más peligrosa cuando la computadora de almacenamiento permite el documento para que Bob y Susan lo abran al mismo tiempo. Esto es lo que podría suceder:
- Roberto abre el documento en su computadora y trabaja en su sección.
- Susan abre el documento en su computadora y trabaja en su sección.
- Roberto completa sus cambios y guarda el documento en la computadora de almacenamiento.
- Susana completa los cambios y guarda el documento en la computadora de almacenamiento.
En esta ilustración, se muestra el problema que puede ocurrir si no hay controles en la copia única del manual técnico. Cuando Susan guarda los cambios, sobrescribirá las que haya creado Robert.
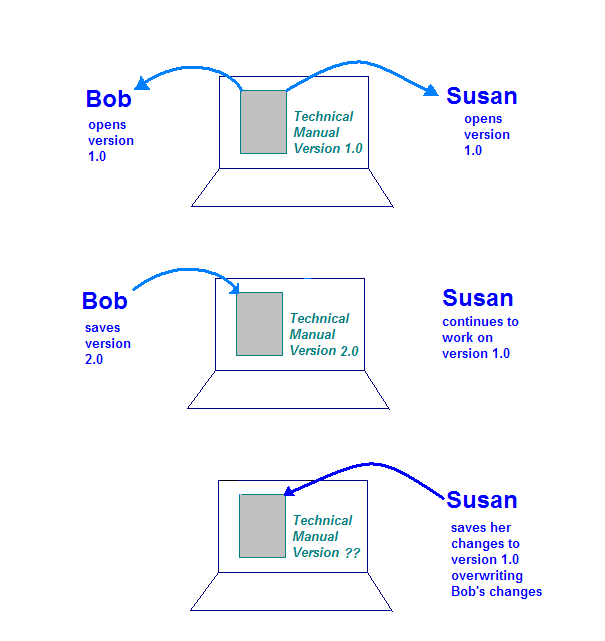
Este es exactamente el tipo de situación que un sistema de CM puede controlar. Con un CM tanto Bob como Susan "revisan" su propia copia de la documentación manual y trabajar en ellos. Cuando Roberto vuelve a revisar sus cambios, el sistema sabe que Susan quiere revisar su propia copia. Cuando Susan revisa su copia, el sistema analiza los cambios que hicieron Bob y Susan y crea una nueva versión que combina los dos conjuntos de cambios.
Los sistemas de CM tienen varias funciones además de la administración de cambios simultáneos, como se describe arriba. Muchos sistemas almacenan archivos de todas las versiones de un documento, desde la primera fecha y hora de su creación. En el caso de un manual técnico, esto puede ser muy útil cuando un usuario tiene una versión antigua del manual y le hace preguntas a un técnico. Un sistema de CM permitiría al escritor técnico acceder a la versión anterior y poder para ver lo que ve el usuario.
Los sistemas de CM son especialmente útiles para controlar los cambios realizados en el software. Tales se denominan sistemas de administración de configuración de software (SCM). Si consideras la gran cantidad de archivos de código fuente individuales en una gran empresa y la gran cantidad de ingenieros que deben hacerles cambios, está claro que el sistema SCM es fundamental.
Administración de configuración de software
Los sistemas SCM se basan en una idea simple: las copias definitivas de tus archivos se mantienen en un repositorio central. Las personas extraen copias de los archivos del repositorio, trabajar en esas copias y volver a revisarlas cuando hayan terminado. SCM administran y realizan un seguimiento de las revisiones de varias personas en relación con un único registro principal. automático.
Todos los sistemas de SCM proporcionan las siguientes funciones esenciales:
- Administración de simultaneidad
- Control de versiones
- Sincronización
Veamos cada una de estas funciones en más detalle.
Administración de simultaneidad
La simultaneidad se refiere a la edición simultánea de un archivo por parte de más de una persona. Con un repositorio grande, queremos que las personas puedan hacer esto, pero también a algunos problemas.
Veamos un ejemplo simple en el dominio de la ingeniería: supongamos que permitimos que los ingenieros para modificar el mismo archivo de forma simultánea en un repositorio central de código fuente. Client1 y Client2 deben realizar cambios en un archivo al mismo tiempo:
- El cliente1 abre bar.cpp.
- El cliente2 abre bar.cpp.
- Client1 cambia el archivo y lo guarda.
- Client2 cambia el archivo y lo guarda, y reemplaza los cambios de Client1.
Desde luego, no queremos que esto suceda. Incluso si controlábamos la situación hacer que los dos ingenieros trabajen en copias separadas en lugar de hacerlo directamente en un diseño maestro (como en la siguiente ilustración), las copias se deben conciliar de alguna manera. Más probable Los sistemas SCM resuelven este problema al permitir que varios ingenieros verifiquen un archivo ("sincronizar" o "actualizar") y realizar los cambios necesarios. La SCM Luego, el sistema ejecuta algoritmos para combinar los cambios a medida que se vuelven a verificar los archivos. (“enviar” o “confirmar”) al repositorio.
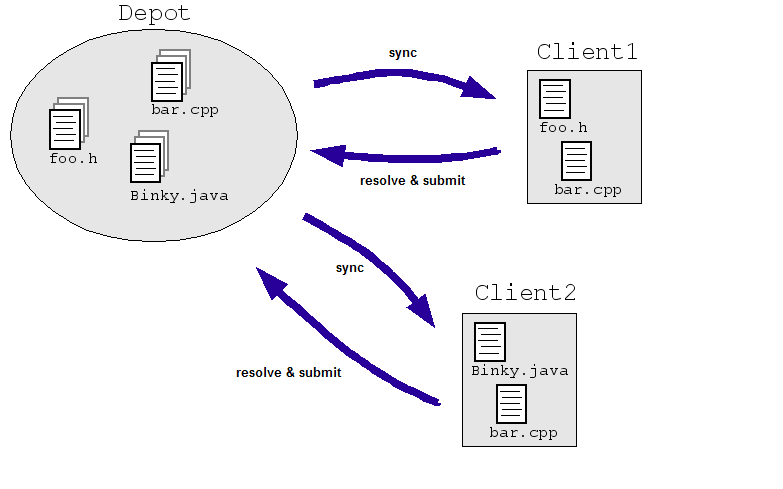
Estos algoritmos pueden ser simples (solicitar a los ingenieros que resuelvan cambios conflictivos) simples (determinan cómo fusionar los cambios conflictivos de forma inteligente y solo preguntarle a un ingeniero si el sistema realmente se bloquea).
Control de versiones
El control de versiones se refiere al seguimiento de las revisiones de archivos que posibilita volver a crear (o revertir) a una versión anterior del archivo Esto se realiza a través de una copia de archivo de cada archivo cuando se registran en el repositorio. o guardando todos los cambios realizados en un archivo. En cualquier momento, podemos usar los archivos o cambiar información para crear una versión anterior. Los sistemas de control de versiones también pueden crear informes de registro de quién registró cambios, cuándo se registró y qué de los cambios.
Sincronización
Con algunos sistemas SCM, los archivos individuales entran y salen del repositorio. Los sistemas más potentes te permiten consultar más de un archivo a la vez. Ingenieros revisar su propia copia completa y completa del repositorio (o parte de él) y el trabajo en archivos según sea necesario. Luego, confirman sus cambios en el repositorio principal. periódicamente y actualizar sus propias copias personales para estar al tanto de los cambios han hecho otras personas. Este proceso se llama sincronización o actualización.
Subversión
Subversion (SVN) es un sistema de control de versión de código abierto. Tiene todos los características descritas anteriormente.
SVN adopta una metodología simple cuando se producen conflictos. Un conflicto ocurre cuando dos o más ingenieros realizan cambios diferentes en la misma área de la base de código y y, luego, ambas envían sus cambios. SVN solo alerta a los ingenieros que hay conflicto, depende de los ingenieros resolverlos.
Usaremos SVN a lo largo de este curso para ayudarte a familiarizarte con administración de configuraciones. Esos sistemas son muy comunes en la industria.
El primer paso es instalar SVN en tu sistema. Haz clic en aquí para instrucciones. Busca tu sistema operativo y descarga el objeto binario correspondiente.
Terminología de SVN
- Revisión: Es un cambio en un archivo o conjunto de archivos. Una revisión es una "instantánea" en un proyecto en constante cambio.
- Repositorio: Es la copia principal en la que SVN almacena el historial de revisión completo de un proyecto. Cada proyecto tiene un repositorio.
- Copia de trabajo: La copia en la que un ingeniero realiza cambios en un proyecto. Hay puede haber muchas copias de trabajo de un determinado proyecto, cada una propiedad de un ingeniero individual.
- Confirmación de la compra: Para solicitar una copia de trabajo desde el repositorio. Una copia funcional equivale al estado del proyecto cuando se confirmó.
- Confirmación: Te permite enviar los cambios de tu copia de trabajo al repositorio central. También se conoce como registro o envío.
- Actualización: Para traer los de otros cambios del repositorio a tu copia de trabajo, o para indicar si tu copia de trabajo tiene cambios no confirmados. Este es el que la sincronización, como se describió anteriormente. La actualización/sincronización proporciona tu copia de trabajo estén actualizados con la copia del repositorio.
- Conflicto: la situación en la que dos ingenieros intentan confirmar cambios en el mismo de un archivo. SVN indica conflictos, pero los ingenieros deben resolverlos.
- Mensaje de registro: Es un comentario que adjuntas a una revisión cuando la confirmas, lo que describe tus cambios. El registro brinda un resumen de lo que sucedió en un proyecto.
Ahora que ya instalaste SVN, ejecutaremos algunos comandos básicos. El primero debes configurar un repositorio en un directorio específico. Estos son los comandos:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
El comando import copia el contenido del directorio mytree en la proyecto de directorio en el repositorio. Podemos observar el directorio de la repositorio con el comando list
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
La importación no crea una copia funcional. Para hacerlo, debes usar la svn confirmación de la compra. Esto crea una copia de trabajo del árbol de directorios. Vamos a hazlo ahora:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Ahora que tienes una copia en funcionamiento, puedes realizar cambios en los archivos y directorios ahí. Tu copia de trabajo es como cualquier otra colección de archivos y directorios puede agregar o editar elementos nuevos, moverlos e incluso eliminar de toda la copia de trabajo. Ten en cuenta que si copias y mueves archivos en tu copia de trabajo, es importante usar copia svn y movimiento svn en lugar de del sistema operativo. Para agregar un archivo nuevo, usa svn add y para borrar para un archivo, usa svn delete. Si lo único que quieres hacer es editar, abre con el editor y ya puedes editarlo.
Existen algunos nombres de directorios estándar que se usan a menudo con Subversion. El "baúl" directorio contiene la línea principal de desarrollo de tu proyecto. Una “rama” directorio contiene cualquier versión de la rama en la que estés trabajando.
$ svn list file:///usr/local/svn/repos /trunk /branches
Supongamos que realizaste todos los cambios necesarios en tu copia de trabajo y quieres sincronizarla con el repositorio. Si muchos otros ingenieros están trabajando en esta área del repositorio, es importante mantener actualizada tu copia de trabajo. Puedes usar el comando svn status para ver los cambios que realizaste en la nube.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Ten en cuenta que hay muchas marcas en el comando de estado para controlar este resultado. Si deseas ver los cambios específicos en un archivo modificado, usa svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Por último, para actualizar tu copia de trabajo desde el repositorio, usa el comando svn update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
Este es un lugar donde podría ocurrir un conflicto. En el resultado anterior, la “U” indica no se hicieron cambios en las versiones del repositorio de estos archivos y se actualizará de que los datos se hayan completado. La “G” significa que se produjo una fusión. La versión del repositorio tenía se modificaron, pero estos no entraron en conflicto con los tuyos. La “C” indica un conflicto. Esto significa que los cambios del repositorio se superpusieron con los tuyos y ahora debes elegir entre ellas.
Por cada archivo que tenga un conflicto, Subversion colocará tres archivos en el archivo texto:
- file.mine: Este es el archivo tal como existía en su copia de trabajo antes de que actualizó tu copia de trabajo.
- file.rOLDREV: Este es el archivo que extrajo del repositorio antes de antes de hacer los cambios.
- file.rNEWREV: Este archivo es la versión actual del repositorio.
Puedes realizar una de las siguientes tres acciones para resolver el conflicto:
- Revisa los archivos y realiza la combinación manualmente.
- Copia uno de los archivos temporales creados por SVN sobre tu versión de copia de trabajo.
- Ejecuta svn Revert para descartar todos los cambios.
Una vez que resuelvas el conflicto, ejecuta el comando svn resolve para informar a SVN. Esto elimina los tres archivos temporales y SVN ya no ve el archivo en un el estado de conflicto.
Lo último que debes hacer es confirmar tu versión final en el repositorio. Esta se completa con el comando svn commit. Cuando confirmas un cambio, necesitas para proporcionar un mensaje de registro en el que se describan los cambios. Se adjuntó este mensaje de registro a la revisión que creaste.
svn commit -m "Update files to include new headers."
Hay mucho más que aprender sobre SVN y cómo puede admitir software de gran tamaño proyectos de ingeniería de atributos. Hay muchos recursos disponibles en la Web, realiza una búsqueda en Google en "Subversion".
A modo de práctica, crea un repositorio para el sistema de Composer Database y, luego, importa todos tus archivos. A continuación, confirma una copia y sigue los comandos que se describieron arriba.
Referencias
Artículo de Wikipedia sobre SVN
Aplicación: un estudio de anatomía
Visita eSkeletons de The University de Texas en Austin