Wprowadzenie do programowania i C++
Ten samouczek online jest kontynuacją bardziej zaawansowanych zagadnień – zapoznaj się z częścią III. W tym module skoncentrujemy się na używaniu wskaźników i rozpoczynaniu pracy z obiektami.
Ucz się na przykładzie nr 2
W tym module skupimy się na przyswajaniu wiedzy w zakresie rozkładania elementów, zrozumieniu wskaźników oraz rozpoczynaniu pracy z obiektami i klasami. Przeanalizuj podane niżej przykłady. Napisz programy samodzielnie lub przeprowadź eksperymenty. Podkreślamy, że kluczem do bycia dobrym programistą jest praktyka, praktyka i ćwiczenie.
Przykład 1. Więcej ćwiczeń rozkładu
Przeanalizujmy następujący wynik z prostej gry:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
Pierwsza obserwacja to tekst wprowadzający wyświetlany raz na program. Potrzebujemy generatora liczb losowych, aby określić odległość wroga dla każdego runda. Potrzebujemy mechanizmu do pobierania danych kątowych z odtwarzacza, przypomina pętlę, która powtarza się, dopóki nie trafimy na wroga. Dodatkowo potrzebujesz funkcji do obliczania odległości i kąta. Na koniec musimy monitorować ile strzałów potrzebowaliśmy, żeby trafić wroga, i ilu mamy wrogów. podczas wykonywania programu. Oto możliwy zarys głównego programu.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
Procedura „Ognia” służy do przebiegu rozgrywki. W tej funkcji wywołujemy funkcję z generatora liczb losowych, aby zmierzyć odległość wroga, a następnie skonfigurować pętlę, uzyskać dane wejściowe gracza i obliczyć, czy uderzył wróg, czy nie. Warunek warowny oznacza, jak blisko zbliżyliśmy się do wroga.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Ze względu na wywołania funkcji cos() i sin() musisz dodać funkcję math.h. Wypróbuj na pisaniu tego programu. To wspaniała praktyka w rozkładaniu problemów. poczytaj o podstawowej wersji C++. Pamiętaj, aby dla każdej funkcji wykonać tylko jedno zadanie. To jest jak najbardziej zaawansowany program, więc może zajść czas.Oto nasze rozwiązanie.
Przykład 2. Ćwiczenie za pomocą wskaźników
Podczas pracy ze wskaźnikami należy pamiętać o 4 rzeczach:- Wskaźniki to zmienne przechowujące adresy pamięci. Podczas realizacji programu
Wszystkie zmienne są przechowywane w pamięci, każda z osobnym, unikalnym adresem lub lokalizacją.
Wskaźnik to specjalny typ zmiennej, która zawiera adres pamięci zamiast
niż wartość danych. Tak jak dane są modyfikowane po użyciu zwykłej zmiennej,
wartość adresu zapisanego we wskaźniku jest modyfikowana jako zmienna wskaźnika
jest manipulacją. Oto przykład:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Zwykle mówimy, że wskaźnik „wskazuje” do lokalizacji, w której jest przechowywana.
(„pointee”). W powyższym przykładzie intptr wskazuje na punkt
5.
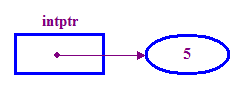
Zwróć uwagę na użycie atrybutu „nowy” operator przydzielający pamięć dla liczby całkowitej Pointee. To musisz zrobić, zanim spróbujesz uzyskać dostęp do punktu.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.Operator * służy do usuwania odniesienia w C. Jeden z najczęstszych błędów Programiści C/C++ podczas pracy ze wskaźnikami zapominają o zainicjowaniu czyli punktu orientacyjnego. Może to czasem spowodować awarię środowiska wykonawczego, ponieważ uzyskujemy dostęp lokalizacji w pamięci, która zawiera nieznane dane. Jeśli spróbujemy to zmienić może powodować niewielkie uszkodzenie pamięci, co utrudnia wykrycie błędów.
- Przypisanie wskaźnika między 2 wskaźnikami sprawia, że wskazują one ten sam punkt.
Zatem przypisanie y = x; wskazuje ten sam punkt co x. Przypisanie wskaźnika
nie dotyka punktu. Zmienia się tylko 1 wskaźnik na tę samą lokalizację
jako kolejny wskazówkę. Po przypisaniu wskaźnika dwa wskaźniki „udostępnij”
Pointee.
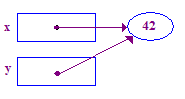
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Oto fragment tego kodu:
| 1. Przydziel 2 wskaźniki x i y. Przydzielenie wskaźników nie przydzielać żadnych punktów. | 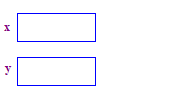 |
| 2. Przydziel punkt i ustaw x, aby wskazać ten punkt. | 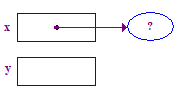 |
| 3. Odwołaj się do wartości x, aby zapisać w punkcie 42 wartość 42. To jest podstawowy przykład. podczas operacji usuwania danych. Zacznij od x. Aby przejść, podążaj za strzałką. swojego punktu widzenia. | 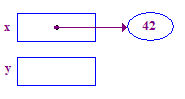 |
| 4. Spróbuj przywrócić parametr 13 do zapisu w jego punkcie. Dzieje się tak, ponieważ nie ma wskaźnika – nigdy nie został mu przypisany. | 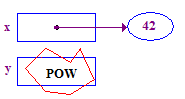 |
| 5. Przypisz y = x; w taki sposób, aby y wskazywał punkt x. Teraz x i y wskazują na ten sam punktor – oni „udostępniają”. | 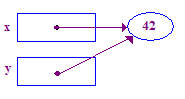 |
| 6. Spróbuj przywrócić parametr 13 do zapisu w jego punkcie. Tym razem się uda. bo w ramach poprzedniego projektu przyznano Ci punkt obsługi. | 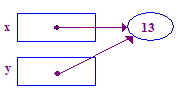 |
Jak widać, obrazy bardzo pomagają w zrozumieniu użycia wskaźnika. Oto inny przykład.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Zwróć uwagę, że w tym przykładzie nigdy nie przydzielaliśmy pamięci z parametrem „new” . Zadeklarowaliśmy normalną zmienną całkowitą i zmieniliśmy ją za pomocą wskaźników.
W tym przykładzie pokazujemy użycie operatora usuwania, który zwalnia przydział. pamięci sterty i jak można je przydzielić do bardziej złożonych struktur. Zagadnienia organizacji pamięci (stos ze stertą i środowiskiem wykonawczym) w ramach innej lekcji. Na razie postrzegamy ten dysk jako wolną pamięć dostępną dla uruchomionych programów.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
W ostatnim przykładzie pokazujemy, jak wskaźniki służą do przekazywania wartości przez odwołanie. do funkcji. W ten sposób zmieniamy wartości zmiennych w funkcji.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Jeśli pozostawimy znak & w argumentach w definicji funkcji zduplikowanej, przekazujemy zmienne „według wartości”, tj. kopia zawiera wartość tę zmienną. Wszelkie zmiany wprowadzone w zmiennej w funkcji powodują modyfikację kopii. Nie modyfikują oryginalnej zmiennej.
Jeśli zmienna jest przekazywana przez odwołanie, nie przekazujemy kopii jej wartości, przekazujemy do funkcji adres zmiennej. Wszelkie modyfikacje zmieniamy też zmienną lokalną, która powoduje modyfikację oryginalnej przekazywanej przez nią zmiennej.
Jeśli jesteś programistą C, to zupełnie nowa odsłona. To samo możemy zrobić w C, deklarowanie funkcji Duplikat() jako Duplikat(int *x), W tym przypadku x. jest wskaźnikiem do liczby całkowitej, a następnie wywołuje funkcję Duplikat() z argumentem &x (adres x) i korzysta z deskrypcji x wewnątrz Duplikat() (patrz poniżej). C++ zapewnia jednak prostszy sposób przekazywania wartości do funkcji przez mimo że poprzednie „C” nadal działa.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Zwróć uwagę na odwołania do C++: nie musimy przekazywać adresu zmiennej ani należy usunąć odwołanie do zmiennej wewnątrz wywołanej funkcji.
Co generuje następujący program? Narysuj obrazek pamięci, aby ją odnaleźć.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Uruchom program, aby sprawdzić, czy udało Ci się udzielić poprawnej odpowiedzi.
Przykład 3: Przekazywanie wartości za pomocą odwołania
Napisz funkcję o nazwie przyspieszenie(), która pobiera jako dane wejściowe prędkość pojazdu oraz ilość. Funkcja dodaje wartość do prędkości pojazdu. Parametr prędkości powinien być przekazywany przez odwołanie oraz ilość przez wartość. Oto nasze rozwiązanie.
Przykład 4. Klasy i obiekty
Weźmy pod uwagę te zajęcia:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Zwróć uwagę, że na końcu zmiennych członków klasy znajduje się podkreślenie. W ten sposób można odróżnić zmienne lokalne i zmienne klasy.
Dodaj do tej klasy metodę zmniejszania. Oto nasze rozwiązanie.
Cuda nauki: informatyka
Ćwiczenia
Tak jak w pierwszym module tego szkolenia, nie udostępniamy rozwiązań dotyczących ćwiczeń i projektów.
Pamiętaj, że dobry program...
... jest logicznie podzielony na funkcje, w których dowolna wykonuje tylko jedno zadanie.
... ma główny program, który określa jego przeznaczenie.
... ma opisowe nazwy funkcji, stałych i zmiennych.
... używa stałych, by uniknąć wszelkiej „magii” w programie.
... ma przyjazny interfejs.
Ćwiczenia rozgrzewające
- Ćwiczenie 1
Liczba całkowita 36 ma dziwną właściwość: jest to kwadrat idealny, a także sumę liczb całkowitych z zakresu od 1 do 8. Następna taka liczba to 1225, która to 352 i sumę liczb całkowitych z zakresu od 1 do 49. Znajdź następny numer który stanowi idealny kwadrat, a także sumę szeregu 1...n. Ten następny numer może być większy niż 32 767. Możesz korzystać z funkcji biblioteki, o których znasz, (lub wzorów matematycznych), aby przyspieszyć działanie programu. Jest również możliwe aby napisać ten program przy użyciu pętli for, by ustalić, czy liczba jest idealna kwadrat lub suma szeregu. (Uwaga: w zależności od komputera i programu znalezienie tego numeru może trochę potrwać).
- Ćwiczenie 2
Twoja księgarnia uniwersytecka potrzebuje Twojej pomocy w oszacowaniu możliwości roku. Doświadczenie pokazuje, że sprzedaż zależy w dużym stopniu od tego, czy potrzebna jest książka dla danego kursu lub tylko opcjonalnego, i określ, czy został on użyty podczas zajęć wcześniej. Nowy, wymagany podręcznik zostanie sprzedany 90% studentów, ale jeśli był on wcześniej używany podczas zajęć, nabywa go tylko 65% użytkowników. Podobnie 40% studentów kupi nowy, opcjonalny podręcznik, jeśli zostało użyte podczas zajęć, zanim tylko 20% z nich dokona zakupu. (zwróć uwagę na słowo „używane” nie oznacza książek z drugiej ręki).
Napisz program, który akceptuje jako dane wejściowe serię książek (dopóki użytkownik nie wpisze hasła) strażnik). W przypadku każdej książki podaj: kod książki, koszt pojedynczego egzemplarza książki, aktualną liczbę książek pod ręką, prawdopodobną liczbę uczniów, i dane wskazujące, czy książka jest wymagana/opcjonalna czy nowa/używana w przeszłości. Jako wszystkie dane wejściowe na odpowiednio sformatowanym ekranie liczbę książek, które należy zamówić (jeśli występują, pamiętaj, że zamawiane są tylko nowe książki), łączny koszt każdego zamówienia.
Następnie, po uzupełnieniu wszystkich danych, wyświetlić łączny koszt wszystkich zamówień książek. oczekiwany zysk, jeśli sklep zapłaci 80% rynkowej ceny detalicznej. Ponieważ jeszcze nie omówiliśmy sposoby radzenia sobie z dużym zbiorem danych napływających do programu (nie dostrojone!), przetwarzaj tylko jedną książkę naraz i wyświetlaj jej ekran wyjściowy. Następnie, gdy użytkownik zakończy wpisywanie wszystkich danych, program powinien wyświetlić sumy i zysku.
Zanim zaczniesz pisać kod, zastanów się nad stworzeniem tego programu. Rozłożenie na zbiór funkcji i utworzenie funkcji main(), która odczytuje polecenie opis rozwiązania problemu. Upewnij się, że każda z funkcji wykonuje jedno zadanie.
Oto przykładowe dane wyjściowe:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Projekt bazy danych
W ramach tego projektu tworzymy w pełni funkcjonalny program w języku C++, który implementuje prosty aplikacji bazy danych.
Nasz program pozwoli nam zarządzać bazą danych kompozytorów i istotnymi informacjami na jej temat o nich. Funkcje programu:
- Możliwość dodawania nowego kompozytora
- Możliwość określenia pozycji kompozytora w rankingu (tzn. wskazanie, co nam się podoba, a co nie) muzyki kompozytora)
- Możliwość wyświetlania wszystkich kompozytorów w bazie danych
- możliwość wyświetlania wszystkich kompozytorów według rangi;
„Są 2 sposoby tworzenia projektowania oprogramowania: Jednym ze sposobów jest uproszczenie procesu, by można było bez wad. Drugim jest jego złożoność, nie ma oczywistych nieprawidłowości. Pierwsza metoda jest o wiele trudniejsza”. – C.A.R. Hoare
Wielu z nas nauczyło się projektować i programować za pomocą „procedury” jak ważna jest pokora. Podstawowe pytanie, od którego zaczynamy, brzmi: „Co musi robić program?”. Śr podzielić rozwiązanie problemu na zadania, z których każde rozwiązuje część i rozpoznają problem. Te zadania są mapowane na funkcje w naszym programie, które są wywoływane kolejno z main() lub z innych funkcji. Ta szczegółowa procedura jest idealna dla niektórych, które musimy rozwiązać. Jednak najczęściej nasze programy nie mają charakteru liniowego, przez sekwencje zadań lub zdarzeń.
Przy podejściu zorientowanym na obiekt zaczynamy od pytania „Jaki jest modelowanych obiektów?” Zamiast dzielić program na zadania w sposób opisany dzielimy je na modele obiektów fizycznych. Te fizyczne obiekty stan zdefiniowany przez zestaw atrybutów oraz zestaw zachowań lub działań, które mogą osiągnąć. Te działania mogą zmienić stan obiektu lub mogą wywoływania działań innych obiektów. Podstawowe założenie jest takie, że obiekt „wie” jak do samodzielnego działania.
W projekcie ogólnym definiujemy obiekty fizyczne za pomocą klas i obiektów. atrybuty i zachowaniach. W programie operacyjnym jest zwykle bardzo dużo obiektów. Wiele z tych obiektów jest jednak zasadniczo takich samych. Weź pod uwagę poniższe kwestie.
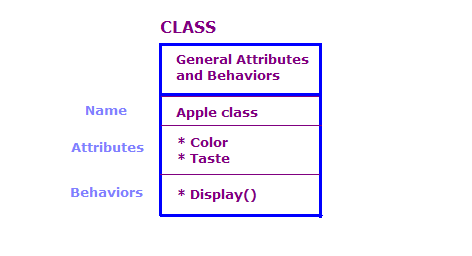
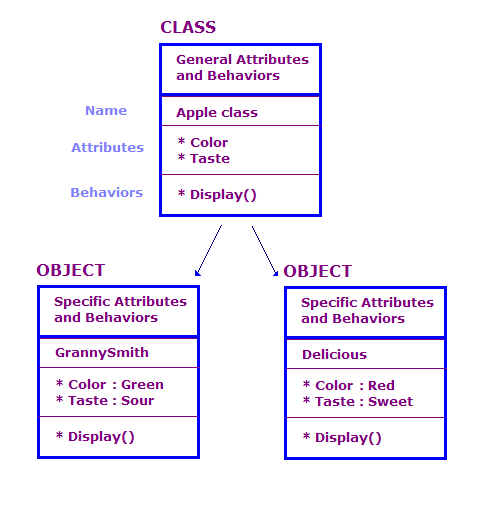
Na tym diagramie zdefiniowaliśmy 2 obiekty klasy Apple. Każdy obiekt ma te same atrybuty i działania co klasa, ale obiekt definiuje atrybuty konkretnego typu jabłka. Dodatkowo, akcja wyświetla atrybuty danego obiektu, np. „Zielony” i „Skwaśne”.
Projekt OO składa się z zestawu klas, danych powiązanych z nimi oraz zestaw działań, które można wykonać na zajęciach. Musimy też określić na sposób interakcji między poszczególnymi klasami. Obiekty mogą wykonywać tę interakcję klasy wywołującej działania obiektów innych klas. Na przykład możemy może mieć klasę AppleOutputer, która zwraca kolor i smak tablicy przez wywołanie metody Display() każdego obiektu Apple.
Oto czynności, które wykonujemy podczas projektowania OO:
- Zidentyfikuj klasy i zdefiniuj ogólnie obiekt każdej z nich i funkcji obiektu.
- Zdefiniuj elementy danych każdej klasy
- Zdefiniuj działania każdej z zajęć i sposoby realizacji niektórych z nich
zaimplementowane za pomocą działań innych powiązanych klas.
W dużym systemie te kroki następują iteracyjnie na różnych poziomach szczegółowości.
W systemie bazy danych kompozytora potrzebna jest klasa Composer, która zawiera wszystkie dane, które chcemy przechowywać w odniesieniu do konkretnego kompozytora. Obiekt tej klasy może promować lub degradować swoją pozycję (zmienić pozycję w rankingu) i wyświetlać jego atrybuty.
Potrzebny jest też zbiór obiektów Composer. Definiujemy to na potrzeby klasy bazy danych. który zarządza poszczególnymi rekordami. Obiekt tej klasy może dodawać i pobierać Composer, a potem wyświetlać poszczególne, wywołując działanie wyświetlania obiektem Composer.
Potrzebujemy też jakiegoś interfejsu, aby zapewnić interaktywne operacje w bazie danych. To jest klasa zastępcza, czyli nie wiemy, co interfejsu użytkownika, ale wiemy, że będzie nam potrzebny. Może jeśli chodzi o elementy graficzne, może w postaci tekstowej. Na razie definiujemy obiekt zastępczy, które możemy podać później.
Teraz, gdy znamy już klasy aplikacji bazy danych kompozytora, Następnym krokiem jest zdefiniowanie atrybutów i działań związanych z klasami. W ze złożonymi procesami, wymagalibyśmy od Ciebie ołówka i papieru UML lub karty CRC lub OOD aby ułożyć hierarchię klas i sposób interakcji obiektów.
W bazie danych kompozytora definiujemy klasę Composer zawierającą które mają być przechowywane na poszczególnych kompozytorach. Zawiera też metody manipulowania rankingi i wyświetlanie danych.
Klasa bazy danych musi mieć jakąś strukturę do przechowywania obiektów Composer. Musimy mieć możliwość dodania do struktury nowego obiektu Composer oraz aby pobrać określony obiekt Composer. Chcemy też wyświetlić wszystkie obiekty w kolejności zgłoszeń lub według pozycji w rankingu.
Klasa interfejsu użytkownika implementuje interfejs oparty na menu, z modułami obsługi, które dla działań wywołania w klasie Database.
Jeśli klasy są łatwe do zrozumienia, a ich atrybuty i działania są jasne, tak jak w aplikacji kompozytora, opracowanie klas jest stosunkowo łatwe. Ale jeśli masz pytania dotyczące wzajemnych relacji i zależności między klasą, ale najpierw dobrze ją narysować i dopracować szczegóły, kodowaniu.
Po uzyskaniu jasnego obrazu projektu i jego sprawdzeniu (więcej na ten temat ), definiujemy interfejs każdej z klas. Nie przejmujemy się implementacją - jakie są atrybuty, działania i elementy, klasy” stan i działania są dostępne dla innych klas.
W C++ zwykle robimy to, definiując plik nagłówkowy dla każdej klasy. Kompozytor klasa zawiera prywatne dane użytkowników obejmujące wszystkie dane, które chcemy przechowywać w narzędziu kompozycyjnym. Potrzebujemy akcesorów („get”) i mutatorów („set”) oraz metod głównych działań dla danej klasy.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Klasa bazy danych też jest prosta.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Zwróć uwagę, że dane dotyczące kompozytora ujęliśmy w oddzielnym miejscu zajęcia. Mogliśmy umieścić w klasie Database obiekt typu struct lub class, który reprezentuje Composer i uzyskać do niego dostęp bezpośrednio z tego miejsca. Byłoby to jednak „under-objectification” (do obiektywności), czyli nie modelujemy z obiektami tak często, jak to tylko możliwe.
Za chwilę zaczniesz pracę nad implementacją narzędzi Composer i Database. , że znacznie wygodniejsze jest posiadanie osobnej klasy Composer. W szczególności oddzielne operacje niepodzielne na obiekcie Composer znacznie upraszczają implementację metod Display() w klasie Database.
Oczywiście istnieje też coś takiego, jak „nadmierne zastrzeżenie” gdzie ale staramy się, żeby ze wszystkich zajęć stały się zajęcia, albo mamy więcej zajęć, niż jest nam potrzebne. Potrzeba aby znaleźć odpowiednią równowagę, mamy różne opinie.
Określenie, czy użytkownik nie zgadza się z nimi, czy nie jest zbyt obszerne, można często tworzenie diagramów w klasach. Jak już wspominaliśmy, ważne jest opracowanie zajęć. projektu, przed rozpoczęciem programowania. Pomoże to w analizie podejścia. Częstym w tym celu UML (Unified Modeling Language) Mamy już zdefiniowane klasy dla obiektów Composer i Database, interfejsu, który pozwala użytkownikowi na interakcję z bazą danych. Proste menu Zrób sztuczkę:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Możemy zastosować interfejs jako klasę lub program proceduralny. Nie wszystko w programie w C++ musi być klasą. Jeśli przetwarzanie odbywa się sekwencyjnie, lub zadaniowa, tak jak w tym programie menu, można go stosować proceduralnie. Ważne jest, aby wdrożyć ją w taki sposób, by zawsze była obiektem zastępczym, Na przykład, jeśli chcemy w przyszłości utworzyć graficzny interfejs użytkownika, nie muszą wprowadzać żadnych zmian w systemie poza interfejsem użytkownika.
Ostatnim elementem, który musimy wypełnić, jest program do przetestowania zajęć. W klasie Composer potrzebny jest program main(), który pobiera dane wejściowe, wypełnia composer, a potem wyświetla go, by upewnić się, że klasa działa prawidłowo. Chcemy też wywoływać wszystkie metody klasy Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Potrzebujemy podobnego programu testowego dla klasy bazy danych.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Te proste programy testowe to dobry pierwszy krok, ale wymagają one aby ręcznie sprawdzić wynik, by upewnić się, że program działa prawidłowo. Jako gdy system staje się większy, ręczna kontrola danych wyjściowych gwałtownie staje się niepraktyczna. Na następnej lekcji omówimy programy do samodzielnej oceny filmów, testów jednostkowych.
Projekt naszego zgłoszenia jest już gotowy. Następnym krokiem jest wdrożenie pliki .cpp zajęć i interfejs.Na początek: Skopiuj, wklej w plikach plik .h i testuj kod sterownika, a następnie je skompiluj.Używaj jak sprawdzić swoje zajęcia. Następnie zaimplementuj ten interfejs:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Użyj metod zdefiniowanych w klasie bazy danych, aby zaimplementować interfejs użytkownika. Dopilnuj, aby Twoje metody były odporne na błędy. Na przykład ranking powinien zawsze mieścić się w zakresie 1–10. Nie zezwalaj też nikomu na dodawanie 101 kompozytorów, chyba że planujesz zmienić strukturę danych w klasie Database.
Pamiętaj, że cały kod musi być zgodny z naszymi konwencjami kodowania, które tutaj dla wygody użytkownika:
- Każdy tworzony przez nas program zaczyna się od komentarza w nagłówku, który zawiera nazwę autora, jego dane kontaktowe, krótki opis i sposób użycia (w stosownych przypadkach). Każda funkcja lub metoda zaczyna się od komentarza na temat operacji i użycia.
- Komentarze objaśniające, używając pełnych zdań, za każdym razem, gdy kod nie dokumentować ani udokumentować, np. jeśli przetwarzanie jest trudne, nieoczywiste, interesujące lub ważne.
- Zawsze używaj nazw opisowych: zmienne zawierają małe litery rozdzielone znakiem _ jak w zmiennej moja_zmienna. W nazwach funkcji i metod używane są wielkie litery na przykład w funkcji MyExcitingFunction(). Stałe zaczynają się od „k” oraz należy używać wielkich liter do oznaczania słów, na przykład kDaysInWeek.
- Wcięcie składa się z wielokrotności dwóch wartości. Pierwszy poziom to 2 spacje. jeśli dalej wymagane jest wcięcie. Stosujemy cztery spacje, sześć spacji itp.
Witaj w prawdziwym świecie!
W tym module przedstawiamy 2 bardzo ważne narzędzia wykorzystywane w większości inżynierii oprogramowania organizacji non-profit. Pierwszy to narzędzie do tworzenia, a drugi to zarządzanie konfiguracją. systemu. Oba te narzędzia są niezbędne w inżynierii oprogramowania przemysłowego, Wielu inżynierów pracuje często na jednym dużym systemie. Narzędzia te pomagają koordynować kontrolowanie zmian w bazie kodu i zapewnia wydajny sposób kompilacji oraz łączenie systemu z wielu plików programów i plików nagłówka.
Tworzenie plików
Proces budowania programu odbywa się zwykle za pomocą narzędzia do kompilacji, które kompiluje i linki do wymaganych plików we właściwej kolejności. Pliki w języku C++ często zawierają zależności, np. funkcja wywołana w jednym programie znajduje się w innym programu. Być może plik nagłówka jest potrzebny przez kilka różnych plików .cpp. O narzędzie do tworzenia kompilacji określa właściwą kolejność kompilacji na podstawie tych zależności. Będzie kompilować tylko te pliki, które zmieniły się od ostatniej kompilacji. Może to zaoszczędzić w systemach złożonych z setek, a nawet tysięcy plików.
Powszechnie stosowane jest narzędzie open source do kompilacji (make). Więcej informacji znajdziesz na stronie przez to, artykuł. Zobacz, czy możesz utworzyć graf zależności dla aplikacji Composer Database, a potem przełożyć ten plik na plik Makefile.Tutaj znajdziesz .
Systemy zarządzania konfiguracją
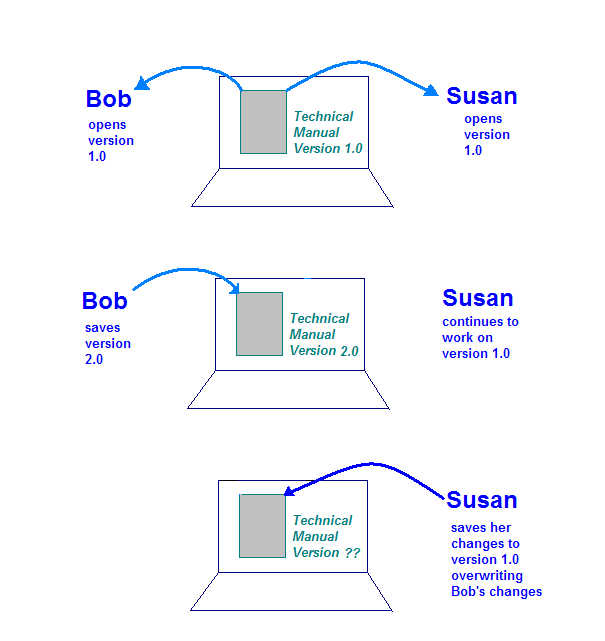
Drugim narzędziem stosowanym w inżynierii oprogramowania przemysłowego jest zarządzanie konfiguracją. (Menedżer Społeczności). Służy do zarządzania zmianą. Załóżmy, że Bob i Zuzanna są pisarzami na temat technologii Obaj pracują nad aktualizacją podręcznika technicznego. Podczas spotkania przypisuje każdej z nich sekcję tego samego dokumentu do aktualizacji.
Instrukcja obsługi jest przechowywana na komputerze, do którego mają dostęp zarówno Robert, jak i Zuzanna. Bez tego narzędzia i procesu mogłyby się pojawić różne problemy. Jeden Możliwe, że komputer, na którym jest przechowywany dokument, może zostać tak skonfigurowany, Robert i Zuzanna nie mogą jednocześnie pracować nad tym podręcznikiem. To spowolniłoby działanie znacznie je zmniejszyć.
Sytuacja jest bardziej niebezpieczna, gdy komputer zezwala na przesłanie dokumentu którą mogą otworzyć jednocześnie Robert i Zuzanna. Oto, co może się wydarzyć:
- Robert otwiera dokument na komputerze i pracuje nad swoją sekcją.
- Zuzanna otwiera dokument na komputerze i pracuje nad swoją sekcją.
- Robert kończy wprowadzanie zmian i zapisuje dokument na komputerze pamięci masowej.
- Zuzanna kończy wprowadzanie zmian i zapisuje dokument na komputerze pamięci masowej.
Ta ilustracja pokazuje problem, który może wystąpić, jeśli nie ma żadnych elementów sterujących na pojedynczej kopii podręcznika technicznego. Gdy Susan zapisuje zmiany, zastępuje te utworzone przez Roberta.
Właśnie takie sytuacje są kontrolowane przez system Menedżera Społeczności. Z Menedżerem Społeczności Robert i Susan „Zapłać” na własną kopię dokumentacji technicznej ręcznie i pracować nad nimi. Kiedy Robert sprawdza zmiany, system wie, że Susan ma własną kopię, Kiedy Susan sprawdza w swojej kopii, system analizuje zmiany wprowadzone przez Boba i Zuzannę, po czym tworzy nową wersję, łączy oba zestawy zmian.
Systemy CM mają wiele funkcji poza zarządzaniem równoczesnymi zmianami, co opisano powyżej. Wiele systemów przechowuje archiwa wszystkich wersji dokumentu, od pierwszej od chwili jego utworzenia. W przypadku instrukcji technicznych może być ona bardzo przydatna, gdy użytkownik ma starszą wersję podręcznika i zadaje pytania autorowi związanemu z technologią. System CM pozwoliłby autorowi technicznemu uzyskać dostęp do starej wersji aby sprawdzić, co widzi użytkownik.
Systemy CM są szczególnie przydatne do kontrolowania zmian wprowadzanych w oprogramowaniu. Taka są nazywane systemami zarządzania konfiguracją oprogramowania (SCM). Jeśli rozważasz ogromnej liczby plików z kodem źródłowym w dużej inżynierii oprogramowania organizacji i ogromnej liczby inżynierów, którzy muszą wprowadzić w nich zmiany, system SCM ma kluczowe znaczenie.
Zarządzanie konfiguracją oprogramowania
Systemy SCM działają w oparciu o prostą koncepcję – ostateczne kopie plików są przechowywane w centralnym repozytorium. Ludzie przeglądają kopie plików z repozytorium, na tych kopiach, a kiedy będą gotowe. SCM systemy zarządzania i śledzenia wersji przez wiele osób w pojedynczym wzorcu ustawiony.
Wszystkie systemy SCM oferują te podstawowe funkcje:
- Zarządzanie równoczesnością
- Obsługa wersji
- Synchronizacja
Przyjrzyjmy się dokładniej każdej z tych funkcji.
Zarządzanie równoczesnością
Równoczesność oznacza jednoczesne edytowanie pliku przez więcej niż 1 osobę. Przy dużym repozytorium chcemy, aby użytkownicy mogli to robić. do pewnych problemów.
Rozważmy prosty przykład z dziedziny inżynierii: załóżmy, że umożliwiamy inżynierom do jednoczesnego modyfikowania tego samego pliku w centralnym repozytorium kodu źródłowego. Klient1 i Klient2 muszą wprowadzić zmiany w pliku jednocześnie:
- Klient1 otwiera plik bar.cpp.
- Klient2 otwiera plik bar.cpp.
- Klient1 zmienia i zapisuje plik.
- Klient2 zmieni plik i zapisze go, zastępując zmiany wprowadzone przez Client1.
Oczywiście tego nie chcemy. Nawet gdybyśmy kontrolowali sytuację zatrudnienie dwóch inżynierów do pracy na osobnych kopiach zamiast bezpośrednio nad masterem. (jak widać na ilustracji poniżej), kopie trzeba w jakiś sposób uzgodnić. Większość Systemy SCM radzą sobie z tym problemem, umożliwiając wielu inżynierom sprawdzenie pliku. („synchronizacja” lub „aktualizacja”) i w razie potrzeby wprowadź zmiany. Menedżer ds. Menedżera treści system uruchamia algorytmy, które scalają zmiany w miarę sprawdzania plików. („submit” lub „commit”) do repozytorium.
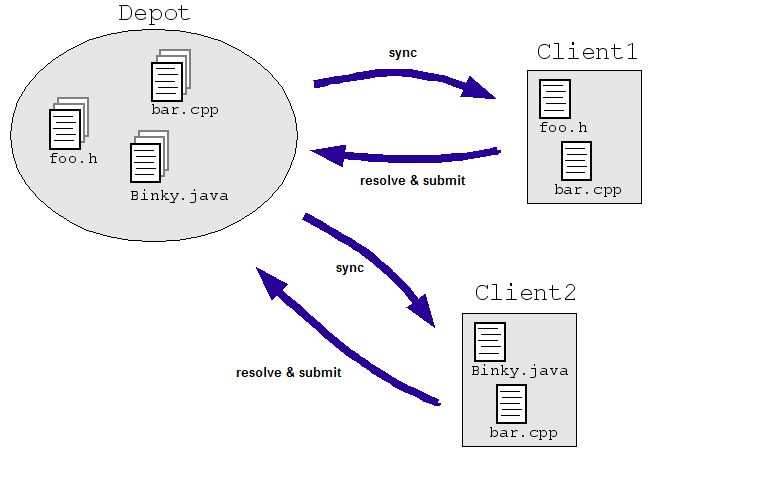
Te algorytmy mogą być proste (poproś programistów o rozwiązanie sprzecznych zmian) albo niezbyt proste (ustal, jak w inteligentny sposób połączyć sprzeczne zmiany i zapytaj inżyniera tylko wtedy, gdy system naprawdę się zawiesił.
Obsługa wersji
Obsługa wersji oznacza śledzenie wersji pliku, co umożliwia odtworzyć (lub przywrócić) poprzednią wersję pliku. Odbywa się to albo Tworząc kopię każdego pliku podczas sprawdzania w repozytorium, lub zapisując każdą zmianę wprowadzoną w pliku. W każdej chwili możemy użyć archiwum lub zmień informacje, by utworzyć poprzednią wersję. Systemy obsługi wersji mogą też tworzyć raporty w dziennikach z informacjami o tym, kto i kiedy sprawdza zmiany oraz co ze zmianami.
Synchronizacja
W niektórych systemach SCM poszczególne pliki są sprawdzane i wychodzące z repozytorium. Bardziej wydajne systemy umożliwiają sprawdzanie kilku plików naraz. Inżynierowie zapoznaj się z własną, pełną, kopią repozytorium (lub jego częścią) oraz pracą, w razie potrzeby. Następnie mogą zatwierdzić zmiany z powrotem w repozytorium głównym. okresowe, a także aktualizowanie własnych kopii, aby być na bieżąco ze zmianami. jakie zrobiły inne osoby. Ten proces nazywamy synchronizacją lub aktualizacją.
Zmiana kierunku
Subversion (SVN) to system kontroli wersji typu open source. Ma wszystkie funkcje funkcji opisanych powyżej.
W przypadku wystąpienia konfliktów SVN stosuje prostą metodologię. Konflikt ma miejsce, gdy 2 z nich lub większą liczbę inżynierów wprowadza różne zmiany w tym samym obszarze bazy kodu, a następnie oboje przesyłają swoje zmiany. SVN informuje tylko inżynierów o tym, że , ale rozwiązanie go należy do inżynierów.
W trakcie tego kursu będziemy używać SVN, aby pomóc Ci zapoznać się do zarządzania konfiguracją. Takie systemy są bardzo powszechne w branży.
Najpierw zainstaluj w systemie SVN. Kliknij tutaj, aby za instrukcje. Znajdź swój system operacyjny i pobierz odpowiedni plik binarny.
Określona terminologia SVN
- Wersja: zmiana w pliku lub zestawie plików. Wersja to jedna „zrzut” w stale zmieniającym się projekcie.
- Repozytorium: kopia główna, w której SVN przechowuje pełną historię wersji projektu. Każdy projekt ma 1 repozytorium.
- Kopia robocza: kopia, w której inżynier wprowadza zmiany w projekcie. OK mogą stanowić wiele kopii roboczych danego projektu, z których każda jest własnością indywidualnego inżyniera.
- Wymeldowanie: aby poprosić o roboczą kopię z repozytorium. Robocza kopia oznacza stan projektu w momencie płatności.
- Zatwierdź: służy do wysyłania zmian z kopii roboczej do centralnego repozytorium. Inna nazwa to meldowanie się lub przesyłanie.
- Aktualizacja: Aby przenieść zdjęcia innych osób zmiany z repozytorium na kopię roboczą lub aby wskazać, czy w kopii roboczej są jakieś niezatwierdzone zmiany. To jest tak samo jak w przypadku synchronizacji, co opisaliśmy powyżej. Aktualizacja/synchronizacja zapewnia kopię roboczą zawierać aktualną kopię repozytorium.
- Konflikt: sytuacja, w której 2 inżynierów próbuje wprowadzić zmiany w tym samym w obszarze pliku. SVN wskazuje konflikty, ale inżynierowie muszą je rozwiązać.
- Komunikat logu: komentarz dołączany do wersji przy jej zatwierdzeniu. opisuje wprowadzone przez Ciebie zmiany. Dziennik zawiera podsumowanie tego, co się dzieje w projekcie.
Po zainstalowaniu SVN przejdziemy teraz do kilku podstawowych poleceń. pierwszą rzeczą, jaką musisz zrobić, jest skonfigurowanie repozytorium w określonym katalogu. Oto polecenia:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
Polecenie import kopiuje zawartość katalogu mytree do z katalogu w repozytorium. Katalogowi można przyjrzeć się z poleceniem list.
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
Import nie spowoduje utworzenia kopii roboczej. Aby to zrobić, musisz skorzystać z pliku svn Checkout. Spowoduje to utworzenie roboczej kopii drzewa katalogów. Zacznijmy zrób to teraz:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Po utworzeniu kopii roboczej możesz wprowadzić zmiany w plikach i katalogach tam. Twoja kopia robocza nie różni się niczym od innych zbiorów plików i katalogów. – dodawać nowe, edytować, przenosić, a nawet usuwać całą roboczą kopię roboczą. Pamiętaj, że jeśli skopiujesz i przeniesiesz pliki w kopii roboczej, Ważne jest, by użyć kopii svn i przenoszenia svn zamiast poleceń systemu operacyjnego. Aby dodać nowy plik, użyj polecenia svn add, a potem usuń. i użyć polecenia svn delete. Jeśli chcesz edytować za pomocą edytora i zacznij edytować!
Istnieje kilka standardowych nazw katalogów często używanych z funkcją Subversion. „Pień” katalog to główna linia rozwoju Twojego projektu. „gałęzie”, katalog to dowolna wersja gałęzi, nad którą pracujesz.
$ svn list file:///usr/local/svn/repos /trunk /branches
Załóżmy, że wszystkie wymagane zmiany zostały wprowadzone w kopii roboczej które chcesz zsynchronizować z repozytorium. Jeśli pracuje wielu inżynierów, w tym obszarze repozytorium, pamiętaj o aktualizowaniu kopii roboczej. Możesz użyć polecenia svn status, aby wyświetlić wprowadzone zmiany. podjętych działań.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Pamiętaj, że w poleceniu stanu jest wiele flag do sterowania tymi danymi wyjściowymi. Jeśli chcesz wyświetlić konkretne zmiany w zmodyfikowanym pliku, użyj svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Na koniec, aby zaktualizować kopię roboczą z repozytorium, użyj polecenia svn update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
tylko w jednym miejscu, w którym może wystąpić konflikt. W powyższych danych wyjściowych „U” wskazuje nie wprowadzono żadnych zmian w wersjach repozytorium tych plików i została zaktualizowana nie mieliśmy do czynienia. Litera „G” oznacza, że doszło do scalenia. Wersja repozytorium miała została zmieniona, ale zmiany nie były sprzeczne z Twoimi. Litera „C” wskazuje w konflikcie. Oznacza to, że zmiany z repozytorium nakładały się na Twoje, i musisz wybrać jeden z nich.
Subversion umieszcza 3 pliki w każdym pliku, w którym występuje konflikt kopiuj:
- file.mine: to jest plik w postaci, w jakiej istniał w kopii roboczej przed zaktualizował(a) kopię roboczą.
- file.rOLDREV: To jest plik pobrany z repozytorium przed wprowadzić zmiany.
- file.rNEWREV: to bieżąca wersja w repozytorium.
Aby rozwiązać konflikt, możesz wykonać jedną z 3 czynności:
- Przejrzyj pliki i scal je ręcznie.
- Skopiuj jeden z plików tymczasowych utworzonych przez SVN, aby zastąpić wersję roboczą.
- Uruchom polecenie svn restore, aby odrzucić wszystkie zmiany.
O rozwiązaniu konfliktu powiadamiasz o tym SVN, uruchamiając polecenie svn rozwiązaniem. Spowoduje to usunięcie 3 plików tymczasowych, a SVN przestanie wyświetlać plik w .
Ostatnią rzeczą, jaką musisz zrobić, jest zatwierdzenie ostatecznej wersji w repozytorium. Ten można wykonać za pomocą polecenia svn Commit. Po wprowadzeniu zmiany niezbędne są aby dostarczyć komunikat logu z opisem zmian. Ten komunikat logu został załączony do utworzonej wersji.
svn commit -m "Update files to include new headers."
Znajdziesz tam o wiele więcej informacji o SVN i o tym, jak obsługuje on duże oprogramowanie w projektach technicznych. W internecie dostępne są liczne zasoby – wystarczy, że wyszukaj w Google hasło „Subversion”.
Aby przećwiczyć, utwórz repozytorium dla systemu bazy danych Composer i zaimportuj wszystkie pliki. Następnie wyświetl działającą kopię i wykonaj opisane polecenia. powyżej.
Pliki referencyjne
Artykuł w Wikipedii na temat SVN
Zastosowanie: Badanie z anatomii
Zobacz eSkeletons na uniwersytecie Teksasu w Austin