Introdução à programação e ao C++
Este tutorial on-line continua com conceitos mais avançados. Leia a Parte III. Neste módulo, vamos nos concentrar no uso de ponteiros e no uso de objetos.
Aprenda pelo exemplo 2
Nosso foco neste módulo é praticar mais a decomposição, entender ponteiros e começar a usar objetos e classes. Confira os exemplos a seguir. Escreva os programas por conta própria quando solicitado ou faça os experimentos. Não podemos enfatizar o suficiente que a chave para se tornar um bom programador é praticar, praticar e praticar!
Exemplo 1: mais prática de decomposição
Considere a seguinte saída de um jogo simples:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
A primeira observação é o texto introdutório, que é exibido uma vez por programa. execução. Precisamos de um gerador de números aleatórios para definir a distância do inimigo para cada todo o Precisamos de um mecanismo para receber a entrada do ângulo do jogador, e isso está obviamente em uma estrutura de loop, já que se repete até atingirmos o inimigo. Nós também precisa de uma função para calcular a distância e o ângulo. Finalmente, devemos acompanhar de quantos tiros foram necessários para acertar o inimigo e também quantos predadores temos durante a execução do programa. Aqui está um possível esboço do programa principal.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
O procedimento de disparo lida com o jogo. Nessa função, chamamos um gerador de número aleatório para descobrir a distância do inimigo e configurar a repetição para recebe as informações do jogador e calcula se ele acertou ou não o inimigo. A a condição de guarda no laço é o quão perto chegamos de atingir o inimigo.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Devido às chamadas para cos() e sin(), será necessário incluir math.h. Testar escrever este programa. Essa é uma ótima prática para decompor problemas e uma boa revisão do C++ básico. Lembre-se de realizar apenas uma tarefa em cada função. Esta é a programa mais sofisticado que escrevemos até agora, então pode demorar um pouco para fazer isso.Confira nossa solução.
Exemplo 2: praticar com os ponteiros
Há quatro coisas que você deve ter em mente ao trabalhar com ponteiros:- Os ponteiros são variáveis que contêm endereços de memória. Enquanto um programa é executado,
todas as variáveis são armazenadas na memória, cada uma em um endereço ou local exclusivo.
Um ponteiro é um tipo especial de variável que contém um endereço de memória em vez
do que um valor de dados. Assim como os dados são modificados quando uma variável normal é usada,
o valor do endereço armazenado em um ponteiro é modificado como uma variável de ponteiro
é manipulada. Veja um exemplo:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Geralmente dizemos que um ponteiro "aponta" no local em que armazenamos
(a "ponta"). No exemplo acima, o intptr aponta para o ponto.
5)
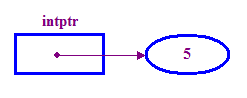
Observe o uso da palavra-chave para alocar memória para o número inteiro pontiaguda. Isso é algo que precisamos fazer antes de tentar acessar o ponteiro.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.O operador * é usado para desreferenciar em C. Um dos erros mais comuns Os programadores C/C++ fazem ao trabalhar com ponteiros é esquecer de inicializar a ponta. Isso às vezes pode causar uma falha no ambiente de execução porque estamos acessando um local na memória que contém dados desconhecidos. Se tentarmos modificar podemos causar uma corrupção sutil da memória, tornando-o um bug difícil de rastrear.
- A atribuição entre dois ponteiros faz com que eles apontem para o mesmo ponteiro.
Assim, a atribuição y = x; faz com que y aponte para o mesmo ponto que x. Atribuição do ponteiro
não toca o ponteiro. Ela apenas muda um ponteiro para ter a mesma localização
como outro ponteiro. Após a atribuição do ponteiro, os dois "compartilham" as
pontiaguda.
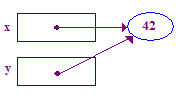
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Confira um trace desse código:
| 1. Aloque dois ponteiros x e y. Alocar os ponteiros não não aloque nenhum ponto. | 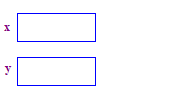 |
| 2. Aloque um ponteiro e defina x para apontar para ele. | 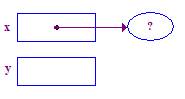 |
| 3. Desfaça a referência de x para armazenar 42 no ponteiro. Este é um exemplo básico da operação de remoção de referência. Comece em x, siga a seta para acessar a ponta. | 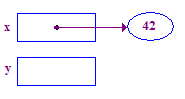 |
| 4. Tente remover a referência y para armazenar 13 na ponta. Isso falha porque y não tem um ponteiro, nunca foi atribuído a ele. | 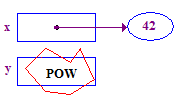 |
| 5. Atribuir y = x; de modo que y aponte para o ponto x. Agora x e y apontam para mesmo ponto, ou seja, estão "compartilhando". | 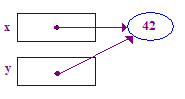 |
| 6. Tente remover a referência y para armazenar 13 na ponta. Desta vez, funcionou, porque a tarefa anterior deu um ponto de interesse. | 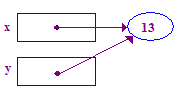 |
Como você pode notar, as imagens são muito úteis para entender o uso do ponteiro. Aqui está outro exemplo.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Observe neste exemplo que nunca alocamos memória com o valor usando um operador lógico. Declaramos uma variável de número inteiro normal e a manipulamos com ponteiros.
Neste exemplo, ilustramos o uso do operador delete que desaloca memória de heap e como podemos alocar para estruturas mais complexas. Vamos abordar organização da memória (heap e pilha de ambiente de execução) em outra aula. Por enquanto, apenas pense na heap como um armazenamento livre de memória disponível para programas em execução.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
Neste exemplo final, mostramos como ponteiros são usados para transmitir valores por referência a uma função. É assim que modificamos os valores das variáveis em uma função.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Se deixarmos os &'s fora dos argumentos na definição da função Duplicar, passamos as variáveis "por valor", ou seja, uma cópia é feita do valor de a variável. Quaisquer alterações feitas na variável na função modificam a cópia. Elas não modificam a variável original.
Quando uma variável é passada por referência, não estamos passando uma cópia de seu valor, estamos passando o endereço da variável para a função. Qualquer modificação que que fazemos à variável local modifica a variável original transmitida.
Se você é um programador C, esta é uma nova reviravolta. Podemos fazer o mesmo em C declarar Duplicate() como Duplicate(int *x), Nesse caso, x é um ponteiro para um int, chamando Duplicate() com o argumento &x (endereço de x) e desreferenciando de x dentro Duplicate() (link em inglês) Confira abaixo. Mas o C++ oferece uma maneira mais simples de passar valores para funções de referência, embora o antigo "C" maneira de fazer isso ainda funciona.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Observe que, com referências a C++, não precisamos passar o endereço de uma variável, nem precisamos desreferenciar a variável dentro da função chamada.
O que o programa abaixo gera? Desenhe a memória para descobrir.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Execute o programa para ver se você acertou a resposta.
Exemplo 3: transmissão de valores por referência
Escreva uma função chamada speed() que recebe como entrada a velocidade de um veículo e um valor. A função adiciona o valor à velocidade para acelerar o veículo. O parâmetro de velocidade deve ser transmitido por referência e o valor por valor. Confira nossa solução.
Exemplo 4: classes e objetos
Considere a seguinte classe:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Observe que as variáveis de membro de classe têm um sublinhado à direita. Isso é feito para diferenciar variáveis locais de variáveis de classe.
Adicione um método de decremento a essa classe. Confira nossa solução.
As maravilhas da ciência: ciência da computação
Exercícios
Como no primeiro módulo deste curso, não fornecemos soluções para exercícios e projetos.
Lembre-se de que um bom programa...
... é decomposta logicamente em funções em que qualquer função realiza apenas uma tarefa.
... tem um programa principal que parece um esboço do que o programa vai fazer.
... tem nomes descritivos de funções, constantes e variáveis.
usa constantes para evitar qualquer "mágica" no programa.
... tem uma interface do usuário fácil de usar.
Exercícios de aquecimento
- Exercício 1
O número inteiro 36 tem uma propriedade peculiar: é um quadrado perfeito e também é a soma dos números inteiros de 1 a 8. O próximo número é 1225, é 352, e a soma dos números inteiros de 1 a 49. Encontrar o próximo número que é um quadrado perfeito e também a soma de uma série 1...n. O próximo número pode ser maior que 32.767. Você pode usar funções de biblioteca que conhece, (ou fórmulas matemáticas) para acelerar o seu programa. Também é possível escrever o programa usando "for-loops" para determinar se um número é um número um quadrado ou a soma de uma série. Observação: dependendo do seu computador e programa, pode demorar um pouco para encontrar esse número.
- Exercício 2
Sua livraria universitária precisa de ajuda para estimar os negócios para a próxima ano. A experiência mostrou que as vendas dependem muito da necessidade de um livro. para um curso ou apenas opcional, e se foi ou não usado no curso antes. Um livro didático novo e obrigatório é vendido para 90% das possíveis matrículas, mas se já tiver sido usado na aula antes, apenas 65% comprará. Da mesma forma, 40% das possíveis matrículas comprarão um novo livro didático opcional, mas se foi usado na classe antes de apenas 20% comprar. Observe que "usado" aqui não se refere a livros usados.)
Escrever um programa que aceite como entrada uma série de livros (até que o usuário insira uma sentinela). Para cada livro, peça: um código, o custo de uma cópia individual para o livro, o número atual de livros disponíveis, o número de matrículas em potencial, e os dados que indicam se o livro é obrigatório/opcional, novo/usado no passado. Conforme saída, mostra todas as informações de entrada em uma tela bem formatada, além de quantos livros devem ser encomendados (se houver, observe que apenas livros novos são encomendados); o custo total de cada pedido.
Em seguida, depois que toda a entrada for concluída, mostre o custo total de todos os pedidos de livros e o lucro esperado se a loja pagar 80% do preço de tabela. Como ainda não fizemos discutimos maneiras de lidar com um grande conjunto de dados que entram em um programa (permaneça ajustado!), processe um livro por vez e exiba a tela de saída dele. Então, quando o usuário terminar de inserir todos os dados, o programa deverá gerar os valores total e de lucro.
Antes de começar a escrever o código, reserve um tempo para pensar no design desse programa. Decomponha-se em um conjunto de funções e crie uma função main() que seja semelhante a um esboço da solução para o problema. Certifique-se de que cada função realize uma tarefa.
Este é um exemplo de saída:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Projeto de banco de dados
Neste projeto, criamos um programa em C++ totalmente funcional que implementa uma aplicativo de banco de dados.
Com nosso programa, poderemos gerenciar um banco de dados de compositores e informações relevantes sobre eles. Os recursos do programa incluem:
- Possibilidade de adicionar um novo compositor
- Capacidade de classificar um compositor (ou seja, indicar o quanto gostamos ou não gostamos) a música do compositor)
- A capacidade de visualizar todos os compositores no banco de dados
- Possibilidade de visualizar todos os compositores por classificação
"Há duas maneiras de construir um no design de software. Uma maneira é simplificar a criação e sem deficiências, e a outra maneira é complicar tudo a fim de que não haja não há deficiências óbvias. O primeiro método é muito mais difícil." — C.A.R. Hoare
Muitos de nós aprendemos a projetar e codificar usando um "procedural" abordagem humilde. A pergunta central com que começamos é "O que o programa precisa fazer?". Qa decompor a solução de um problema em tarefas, e cada uma delas resolve uma parte o problema. Essas tarefas mapeiam funções do nosso programa que são chamadas sequencialmente de main() ou de outras funções. Essa abordagem passo a passo é ideal para alguns problemas que precisamos resolver. Mas, na maioria das vezes, nossos programas não são apenas lineares. sequências de tarefas ou eventos.
Com uma abordagem orientada a objetos (OO), começamos com a pergunta: objetos que estou modelando?” Em vez de dividir um programa em tarefas conforme descrito acima, dividimos em modelos de objetos físicos. Esses objetos físicos têm um estado definido por um conjunto de atributos e um conjunto de comportamentos ou ações que que eles podem realizar. As ações podem mudar o estado do objeto ou invocar ações de outros objetos. A premissa básica é que um objeto "sabe" como para fazer as coisas sozinha.
No design OO, definimos objetos físicos em termos de classes e objetos. atributos e comportamentos dos usuários. Geralmente, há um grande número de objetos em um programa OO. Muitos desses objetos, no entanto, são essencialmente os mesmos. Considere o seguinte.
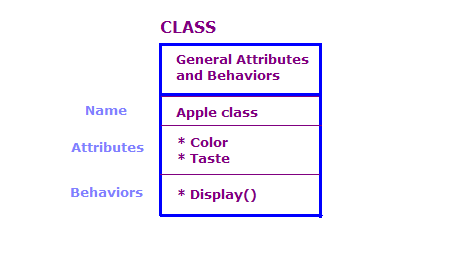
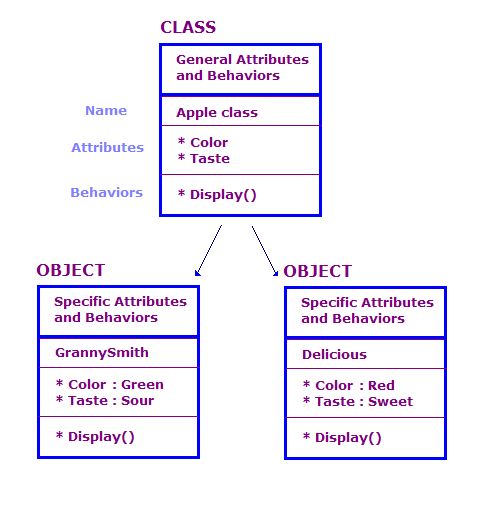
Neste diagrama, definimos dois objetos que são da classe Apple. Cada objeto tem os mesmos atributos e ações que a classe, mas o objeto define os atributos de um tipo específico de maçã. Além disso, o Display exibe os atributos desse objeto específico, por exemplo, "Verde" e "Azedo".
Um design OO consiste em um conjunto de classes, os dados associados a essas classes, e o conjunto de ações que as classes podem realizar. Também precisamos identificar maneiras de interagir com diferentes classes. Essa interação pode ser realizada por objetos de uma classe invocando as ações de objetos de outras classes. Por exemplo, nós poderia ter uma classe AppleOutputer que gere a cor e o sabor de uma matriz. de objetos da Apple, chamando o método Display() de cada objeto Apple.
Aqui estão as etapas que realizamos no design OO:
- Identificar as classes e definir em geral o que é um objeto de cada classe armazena como dados e o que um objeto pode fazer.
- Definir os elementos de dados de cada classe
- Definir as ações de cada classe e como algumas delas podem ser
implementados usando ações de outras classes relacionadas.
Em sistemas grandes, essas etapas ocorrem de maneira iterativa em diferentes níveis de detalhes.
Para o sistema de banco de dados do Composer, precisamos de uma classe do Composer que encapsular todos os dados que queremos armazenar em um compositor individual. Um objeto dessa classe pode promover ou se rebaixar (mudar a classificação) e exibir os atributos dele.
Também precisamos de uma coleção de objetos do Composer. Para isso, definimos uma classe de banco de dados que gerencia os registros individuais. Um objeto dessa classe pode adicionar ou recuperar do Composer e exibir objetos individuais invocando a ação de exibição do um objeto do Composer.
Por fim, precisamos de uma interface do usuário para fornecer operações interativas no banco de dados. Esta é uma classe de espaço reservado, ou seja, não sabemos o que interface do usuário ainda será, mas sabemos que vamos precisar de uma. Talvez ele será gráfico, talvez baseado em texto. Por enquanto, definimos um espaço reservado que que podemos preencher mais tarde.
Agora que identificamos as classes do aplicativo de banco de dados do Composer, a próxima etapa é definir os atributos e as ações para as classes. Em uma aplicativo complexo, nos juntamos a lápis e papel ou UML ou cartões de CRC ou OOD para mapear a hierarquia de classes e como os objetos interagem.
Para o banco de dados do Composer, definimos uma classe do Composer que contém as os dados que queremos armazenar em cada compositor. Ele também contém métodos para manipular classificações e exibição de dados.
A classe Database precisa de algum tipo de estrutura para armazenar objetos do Composer. Precisamos adicionar um novo objeto do Composer à estrutura, bem como recuperar um objeto específico do Composer. Também gostaríamos de exibir todos os objetos seja por ordem de entrada ou por classificação.
A classe de interface do usuário implementa uma interface orientada por menus, com manipuladores que na classe Database.
Se as aulas forem facilmente compreendidas e seus atributos e ações estiverem claros, assim como no aplicativo Compositor, é relativamente fácil projetar as classes. Mas se tiver alguma dúvida sobre como as classes se relacionam e interagem, é melhor desenhá-lo primeiro e trabalhar nos detalhes antes de começar ao código.
Assim que tivermos uma imagem clara do design e o avaliarmos (mais sobre isso em breve), definimos a interface de cada classe. Não nos preocupamos com a implementação detalhes neste ponto: quais são os atributos e as ações e quais partes de uma classe" estado e ações estão disponíveis para outras classes.
Em C++, normalmente fazemos isso definindo um arquivo de cabeçalho para cada classe. O Composer tem membros de dados privados para todos os dados que queremos armazenar em um compositor. Precisamos de acessadores ("métodos get") e mutadores ("métodos set"), bem como ações principais para a classe.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
A classe Database também é simples.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Observe como encapsulamos os dados específicos do compositor em um separador . Poderíamos ter colocado um struct ou classe na classe Database para representar o Composer e o acessou diretamente de lá. Mas isso seria “sub-objeção”, ou seja, não estamos modelando tanto com objetos quanto possível.
Quando começar a trabalhar na implementação das APIs do Composer e do Database, classes, porque é muito mais simples ter uma classe do Composer separada. Especificamente, ter operações atômicas separadas em um objeto do Composer simplifica muito a implementação dos métodos Display() na classe Database.
Claro, também existe "excesso de objetificação" em que tentamos transformar tudo em uma classe ou temos mais classes do que o necessário. Leva prática para encontrar o equilíbrio certo, e você descobrirá que os programadores individuais terão opiniões diferentes.
Determinar se você está subestimando ou superando o objetivo muitas vezes pode ser definido com cuidado diagramando suas classes. Como mencionado antes, é importante organizar uma aula antes de começar a programar, e isso pode ajudar a analisar a abordagem. Um erro comum usada para esse propósito é Linguagem de modelagem unificada (UML, na sigla em inglês) Agora que temos as classes definidas para os objetos Composer e Database, precisamos uma interface que permite ao usuário interagir com o banco de dados. Um menu simples é possível:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Podemos implementar a interface do usuário como uma classe ou como um programa processual. Não tudo em um programa em C++ precisa ser uma classe. Na verdade, se o processamento for sequencial ou orientadas a tarefas, como neste programa de menu, não há problema em implementá-la de maneira processual. É importante implementá-la de forma que continue sendo um "marcador", ou seja, se quisermos criar uma interface gráfica do usuário em algum momento, devemos sem precisar mudar nada no sistema, apenas a interface do usuário.
A última coisa que precisamos para concluir a inscrição é um programa para testar as classes. Para a classe Composer, queremos um programa main() que receba entrada, preencha uma composer e, em seguida, o exibe para verificar se a classe está funcionando corretamente. Também queremos chamar todos os métodos da classe Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Precisamos de um programa de teste parecido para a classe Database.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Observe que esses programas de teste simples são um bom primeiro passo, mas eles exigem para inspecionar manualmente a saída e garantir que o programa esteja funcionando corretamente. Conforme um sistema fica maior, e a inspeção manual das saídas rapidamente se torna impraticável. Em uma lição posterior, introduziremos programas de testes de autoverificação no formulário de testes de unidade.
O design do nosso aplicativo está completo. A próxima etapa é implementar os arquivos .cpp para as classes e para a interface do usuário.Para começar, siga em frente e copie/cole o .h e o código do driver de teste acima nos arquivos e compile-os.Usar os drivers para testar suas classes. Em seguida, implemente a seguinte interface:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Use os métodos definidos na classe do banco de dados para implementar a interface do usuário. Deixe seus métodos à prova de erros. Por exemplo, uma classificação deve estar sempre no intervalo 1 a 10. Também não permita que ninguém adicione 101 compositores, a menos que você pretenda alterar o na classe Database.
Todo o código precisa seguir nossas convenções, que são repetidas aqui para sua conveniência:
- Todo programa que escrevemos começa com um comentário no cabeçalho, que fornece o nome do o autor, as informações de contato, uma breve descrição e o uso (se relevante). Cada função/método começa com um comentário sobre a operação e o uso.
- Adicionamos comentários explicativos usando frases completas sempre que o código não se documente, por exemplo, se o processamento for complicado, não óbvio, interessantes ou importantes.
- Sempre use nomes descritivos: as variáveis são palavras em minúsculas separadas por _, como em my_variable. Nomes de funções/métodos usam letras maiúsculas para marcar palavras, como em MyExcitingFunction(). Constantes começam com um "k" e usar letras maiúsculas para marcar palavras, como em kDaysInWeek.
- O recuo está em múltiplos de dois. O primeiro nível tem dois espaços. se mais recuo é necessário, usamos quatro espaços, seis espaços etc.
Bem-vindo ao mundo real!
Neste módulo, vamos conhecer duas ferramentas muito importantes usadas na maioria das operações organizações. O primeiro é uma ferramenta de build, e o segundo é uma ferramenta de gerenciamento sistema. Ambas as ferramentas são essenciais na engenharia de software industrial, em que muitos engenheiros costumam trabalhar em um sistema grande. Essas ferramentas ajudam a coordenar controlar alterações na base de código e fornecer um meio eficiente de compilar e vinculando um sistema a partir de muitos arquivos de programa e cabeçalho.
Makefiles
O processo de criação de um programa geralmente é gerenciado com uma ferramenta de build, que compila e vincula os arquivos necessários na ordem correta. Muitas vezes, os arquivos C++ têm dependências, por exemplo, uma função chamada em um programa reside em outro neste programa. Ou talvez um arquivo de cabeçalho seja necessário para vários arquivos .cpp diferentes. Um Build descobre a ordem de compilação correta dessas dependências. Ele vai compilar somente arquivos que foram alterados desde o último build. Isso pode salvar um muito tempo em sistemas compostos de várias centenas ou milhares de arquivos.
Uma ferramenta de build de código aberto chamada make é comumente usada. Para saber mais, leia por meio deste artigo. Verifique se é possível criar um gráfico de dependência para o aplicativo de banco de dados do Composer. e depois traduzi-lo em um makefile.Aqui está nossa solução.
Sistemas de gerenciamento de configurações
A segunda ferramenta usada na engenharia de software industrial é o Configuration Management (gerente de comunidade). Isso é usado para gerenciar mudanças. Digamos que Bob e Susan sejam escritores de tecnologia e ambas estão trabalhando em atualizações de um manual técnico. Durante uma reunião, atribui a cada um deles uma seção do mesmo documento para atualizar.
O manual técnico é armazenado em um computador que Bob e Susan podem acessar. Sem nenhuma ferramenta ou processo de gerenciamento de conteúdo implementado, vários problemas podem surgir. Um isso é possível é que o computador que armazena o documento esteja configurado de modo que Bob e Susana não podem trabalhar no manual ao mesmo tempo. Isso atrasaria diminuí-los consideravelmente.
Uma situação mais perigosa surge quando o computador de armazenamento permite que o documento ser aberto por Bob e Susan ao mesmo tempo. Veja o que pode acontecer:
- Bob abre o documento no computador e trabalha na seção.
- Susana abre o documento no computador e trabalha na seção.
- Bob conclui as alterações e salva o documento no computador de armazenamento.
- Susana conclui as alterações e salva o documento no computador de armazenamento.
Esta ilustração mostra o problema que pode ocorrer se não houver controles na cópia única do manual técnico. Quando Susan salva suas alterações, ela substitui os feitos por Bob.
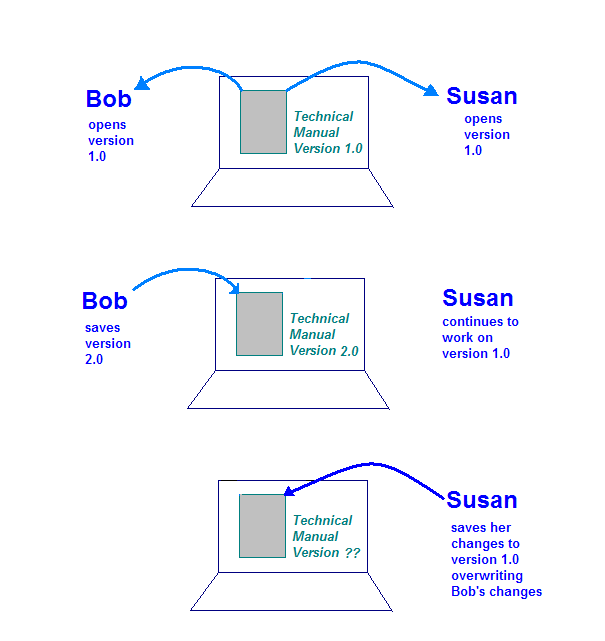
Esse é exatamente o tipo de situação que um sistema de CM pode controlar. Com um gerente de comunidade do YouTube, Bob e Susana fazem "check-out" uma cópia própria da documentação técnica manual e trabalhar neles. Quando Bob verifica as alterações novamente, o sistema sabe que Susan recebeu uma cópia. Quando Susan faz check-in em sua cópia, o sistema analisa as mudanças que Bob e Susan fizeram e cria uma nova versão que mescla os dois conjuntos de alterações.
Os sistemas de CM têm uma série de recursos que vão além do gerenciamento de alterações simultâneas, conforme descrito acima. Muitos sistemas armazenam arquivos de todas as versões de um documento, desde o primeiro momento em que foi criado. No caso de um manual técnico, isso pode ser muito útil quando um usuário tem uma versão antiga do manual e está fazendo perguntas a um redator de tecnologia. Um sistema CM permitiria que o redator de tecnologia acessasse a versão antiga e pudesse para ver o que o usuário está vendo.
Os sistemas de CM são especialmente úteis para controlar as alterações feitas no software. Essas são chamados de sistemas de Gerenciamento de configuração de software (SCM). Se você considerar o grande número de arquivos de código-fonte individuais em uma grande empresa de engenharia organização e ao grande número de engenheiros que devem fazer alterações nelas, fica claro que um sistema SCM é fundamental.
Gerenciamento de configuração de software
Os sistemas SCM são baseados em uma ideia simples: as cópias definitivas de seus arquivos são mantidos em um repositório central. As pessoas conferem as cópias de arquivos do repositório trabalhar nessas cópias e, em seguida, verificá-las novamente quando terminarem. SCM os sistemas gerenciam e rastreiam revisões de várias pessoas em relação a um único mestre definido.
Todos os sistemas SCM oferecem os seguintes recursos essenciais:
- Gerenciamento de simultaneidade
- Controle de versões
- Sincronização
Vamos conferir mais detalhes de cada um desses recursos.
Gerenciamento de simultaneidade
Simultaneidade refere-se à edição simultânea de um arquivo por mais de uma pessoa. Com um repositório grande, queremos que as pessoas possam fazer isso, mas pode levar a a alguns problemas.
Considere um exemplo simples no domínio de engenharia: suponha que permitimos que engenheiros modificar o mesmo arquivo simultaneamente em um repositório central de código-fonte. Client1 e Client2 precisam fazer alterações em um arquivo ao mesmo tempo:
- Client1 abre bar.cpp.
- Client2 abre bar.cpp.
- Client1 altera e salva o arquivo.
- O Client2 altera o arquivo e o salva substituindo as alterações do Client1.
Obviamente, não queremos que isso aconteça. Mesmo se controlássemos a situação fazer com que os dois engenheiros trabalhem em cópias separadas em vez de diretamente em um mestre definido (como na ilustração abaixo), as cópias precisam ser reconciliadas de alguma forma. Mais frequentes Os sistemas SCM lidam com esse problema, permitindo que vários engenheiros verifiquem um arquivo ("sincronizar" ou "atualizar") e faça as alterações conforme necessário. SCM o sistema executa algoritmos para mesclar as alterações à medida que os arquivos são verificados ("enviar" ou "confirmar") ao repositório.
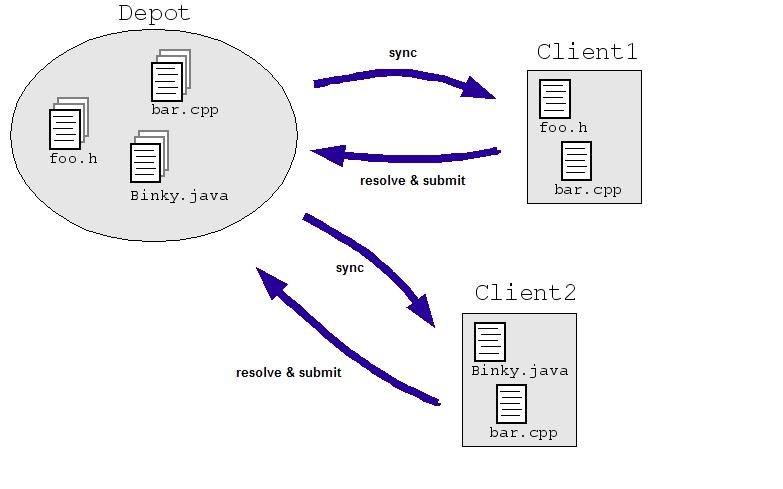
Esses algoritmos podem ser simples (peça para os engenheiros resolverem alterações conflitantes) ou não tão simples (determinar como mesclar as alterações conflitantes de forma inteligente e pergunte a um engenheiro se o sistema realmente fica travado).
Controle de versões
O controle de versões é o acompanhamento das revisões de arquivos, o que possibilita recriar ou reverter para uma versão anterior do arquivo. Isso é feito fazendo uma cópia de cada arquivo quando ele é verificado no repositório, ou salvando todas as alterações feitas em um arquivo. A qualquer momento, podemos usar os arquivos ou altere as informações para criar uma versão anterior. Os sistemas de controle de versões criar relatórios de registro de quem fez check-in das alterações, quando eles foram atualizados e o que em que foram feitas as mudanças.
Sincronização
Em alguns sistemas SCM, é feito o check-in e o check-out de arquivos individuais no repositório. Sistemas mais avançados permitem que você verifique mais de um arquivo por vez. Engenheiros confira uma cópia completa e completa do repositório (ou parte dele) e do trabalho nos arquivos conforme necessário. Em seguida, eles fazem commit de suas alterações no repositório mestre periodicamente e atualizam as próprias cópias pessoais para ficarem por dentro das alterações que outras pessoas fizeram. Esse processo é chamado de sincronização ou atualização.
Subversão
O Subversion (SVN) é um sistema de controle de versões de código aberto. Ele tem todos os os recursos descritos acima.
A SVN adota uma metodologia simples quando ocorrem conflitos. Um conflito é quando dois mais engenheiros façam alterações diferentes na mesma área da base de código e e os dois enviam as alterações. O SVN apenas alerta os engenheiros de que há um conflito, cabe aos engenheiros resolvê-lo.
Usaremos o SVN ao longo deste curso para ajudá-lo a se familiarizar com o gerenciamento de configurações. Esses sistemas são muito comuns na indústria.
A primeira etapa é instalar o SVN no seu sistema. Clique em aqui para instruções. Encontre seu sistema operacional e faça o download do binário adequado.
Algumas terminologias de SVN
- Revisão: uma alteração em um arquivo ou conjunto de arquivos. Uma revisão é uma "instantâneo" em um projeto em constante mudança.
- Repositório: a cópia mestre em que o SVN armazena o histórico completo de revisões de um projeto. Cada projeto tem um repositório.
- Cópia de trabalho: é a cópia na qual um engenheiro faz alterações em um projeto. podem ser muitas cópias de um determinado projeto, cada uma de propriedade de um engenheiro individual.
- Check-out: para solicitar uma cópia de trabalho do repositório. Uma cópia de trabalho é igual ao estado do projeto quando foi feito o check-out.
- Confirmação: para enviar alterações da cópia de trabalho para o repositório central. Também conhecido como check-in ou envio.
- Atualizar: para trazer os alterações do repositório para sua cópia de trabalho, ou para indicar se a sua cópia de trabalho tem alguma alteração não confirmada. Esta é a é igual à sincronização, conforme descrito acima. Portanto, a atualização/sincronização leva sua cópia de trabalho atualizados com a cópia do repositório.
- Conflito: a situação em que dois engenheiros tentam confirmar alterações no mesmo área de um arquivo. O SVN indica conflitos, mas os engenheiros precisam resolvê-los.
- Mensagem de registro: um comentário que você anexa a uma revisão ao confirmá-la, o que descreve suas alterações. O registro fornece um resumo do que está acontecendo em um projeto.
Agora que você tem o SVN instalado, executaremos alguns comandos básicos. A a primeira coisa a fazer é configurar um repositório em um diretório especificado. Estes são os comandos:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
O comando import copia o conteúdo do diretório mytree para a projeto de diretório no repositório. Podemos dar uma olhada no diretório repositório com o comando list
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
A importação não cria uma cópia de trabalho. Para isso, é preciso usar o comando checkout. Isso cria uma cópia de trabalho da árvore de diretórios. Vamos faça isso agora:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Agora que você tem uma cópia de trabalho, pode fazer alterações nos arquivos e diretórios ali. Sua cópia de trabalho é como qualquer outra coleção de arquivos e diretórios é possível adicionar novos, editar, mover e até mesmo excluir toda a cópia de trabalho. Observe que, se você copiar e mover arquivos em sua cópia de trabalho, é importante usar vpc copy e oauth move em vez dos valores comandos do sistema operacional. Para adicionar um novo arquivo, use oauth add e para excluir em um arquivo, use oauth delete. Se quiser apenas editar, basta abrir o o arquivo com seu editor e edite-o.
Existem alguns nomes de diretórios padrão usados com frequência com o Subversion. O "tronco" diretório contém a linha principal de desenvolvimento do seu projeto. Uma "ramificações" diretório contém qualquer versão de ramificação em que você esteja trabalhando.
$ svn list file:///usr/local/svn/repos /trunk /branches
Então, digamos que você fez todas as alterações necessárias em sua cópia de trabalho e você quer sincronizá-lo com o repositório. Se muitos engenheiros estiverem trabalhando nesta área do repositório, é importante manter sua cópia de trabalho atualizada. Você pode usar o comando oauth status para visualizar as alterações que você feitas.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Observe que há muitas sinalizações no comando status para controlar essa saída. Para visualizar as alterações específicas em um arquivo modificado, use oauth diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Por fim, para atualizar sua cópia de trabalho do repositório, use o comando oauth update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
Esse é um lugar em que pode ocorrer um conflito. Na saída acima, o "U" indica nenhuma mudança foi feita nas versões do repositório desses arquivos, e uma atualização foi feito. O "G" significa que uma mesclagem ocorreu. A versão do repositório tinha foram alteradas, mas elas não entraram em conflito com as suas. O "C" indica um conflito. Isso significa que as alterações do repositório se sobrepuseram às suas, e agora você precisa escolher entre elas.
Para cada arquivo que tem um conflito, o Subversion coloca três arquivos em seu arquivo de trabalho cópia:
- file.mine: este é seu arquivo como ele existia em sua cópia de trabalho antes de você atualizou sua cópia de trabalho.
- file.rOLDREV: Este é o arquivo que você verificou do repositório antes de fazer as alterações.
- file.rNEWREV: este arquivo é a versão atual no repositório.
Você pode escolher uma destas três opções para resolver o conflito:
- Analise os arquivos e faça a mesclagem manualmente.
- Copie um dos arquivos temporários criados pelo SVN sobre sua versão da cópia de trabalho.
- Execute oauth revert para descartar todas as suas alterações.
Depois de resolver o conflito, informe ao SVN executando relevantes resolvedos. Isso remove os três arquivos temporários e o SVN não exibe mais o arquivo em um estado de conflito.
A última coisa a fazer é confirmar a versão final no repositório. Isso é feito com o comando aprender a fazer o commit. Quando você confirma uma mudança, precisa para fornecer uma mensagem de registro, que descreve suas alterações. Esta mensagem de registro está anexada à revisão criada.
svn commit -m "Update files to include new headers."
Há muito mais a aprender sobre o SVN e como ele oferece suporte a grandes projetos de engenharia. Existem diversos recursos disponíveis na Web - apenas faça uma pesquisa no Google sobre "Subversion".
Para praticar, crie um repositório para seu sistema de banco de dados do Composer e importe todos os seus arquivos. Em seguida, verifique uma cópia de trabalho e execute os comandos descritos acima.
Referências
Aplicação: um estudo em anatomia
Confira a página eSkeletons da Universidade do Texas em Austin