การฝึกโมเดลหมายถึงการเรียนรู้ (พิจารณา) ค่าที่ดีของน้ําหนักทั้งหมดและการให้น้ําหนักพิเศษจากตัวอย่างที่ติดป้ายกํากับ ในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล อัลกอริทึมแมชชีนเลิร์นนิงจะสร้างโมเดลด้วยการตรวจสอบตัวอย่างจํานวนมากและพยายามค้นหาโมเดลที่ช่วยลดการสูญเสียได้ กระบวนการนี้เรียกว่าการลดความเสี่ยงในความเสี่ยงชั่วคราว
Loss เป็นการลงโทษสําหรับการคาดการณ์ที่ไม่ถูกต้อง กล่าวคือ loss คือตัวเลขที่บ่งบอกว่าการคาดการณ์ของโมเดลนั้นแย่เพียงใดในตัวอย่างเดียว หากการคาดการณ์ของโมเดลสมบูรณ์แบบ ค่าเป็นศูนย์จะแพ้ 0 หากแพ้ ค่าดีกว่า เป้าหมายของการฝึกโมเดลคือการหาชุดของน้ําหนักและการให้น้ําหนักพิเศษที่เสียต่ําโดยเฉลี่ยในทุกๆ ตัวอย่าง เช่น รูปที่ 3 แสดง รูปแบบการแพ้ที่สูงทางซ้าย และรูปแบบสูญเสียต่ําทางด้านขวา ข้อควรทราบเกี่ยวกับตัวเลขมีดังนี้
- ลูกศรเหล่านี้หมายถึงการสูญเสีย
- เส้นสีน้ําเงินแสดงถึงการคาดคะเน
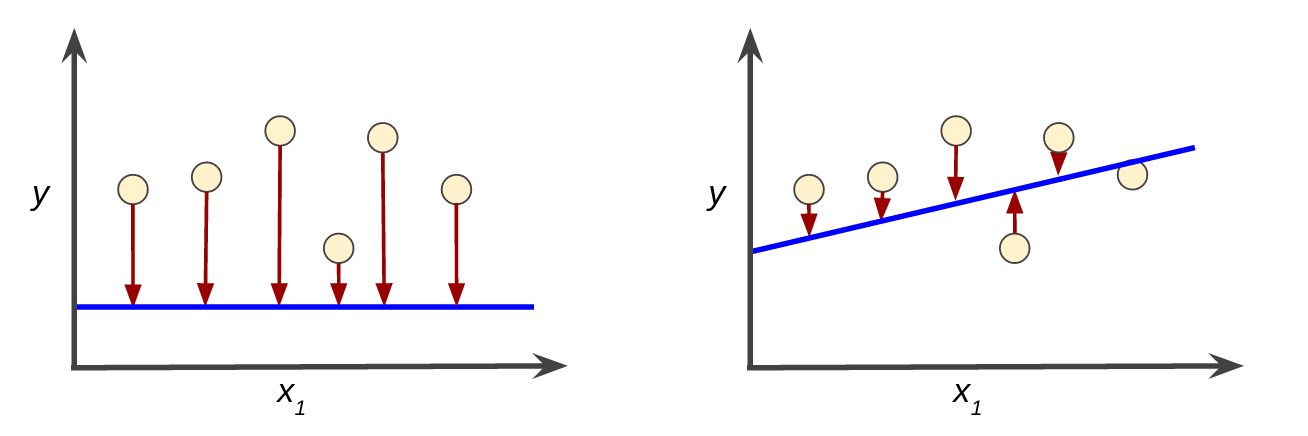
รูปที่ 3 ส่วนโมเดลด้านซ้ายจะแพ้มาก ส่วนอีกโมเดลให้เสียโอกาสน้อยลง
สังเกตพบว่าลูกศรในพล็อตซ้ายนั้นยาวกว่าส่วนพล็อตในพล็อตขวามาก เห็นได้ชัดว่าเส้นในพล็อตด้านขวาเป็นโมเดลการคาดการณ์ที่ดีกว่าเส้นในพล็อตซ้ายมาก
คุณอาจสงสัยว่าจะสร้างฟังก์ชันทางคณิตศาสตร์ หรือฟังก์ชันการสูญเสีย ซึ่งจะรวบรวมการสูญเสียทีละอย่างไว้ในรูปแบบที่มีความหมาย
การสูญเสียยกกําลังสอง: ฟังก์ชันการสูญเสียยอดนิยม
โมเดลการถดถอยเชิงเส้นที่เราจะตรวจสอบที่นี่จะใช้ฟังก์ชันการสูญเสียที่เรียกว่าการสูญเสียกําลังสอง (หรือที่เรียกว่าการสูญเสีย 2) การสูญเสียยกกําลัง 2 สําหรับตัวอย่างเดียวมีดังนี้
= the square of the difference between the label and the prediction = (observation - prediction(x))2 = (y - y')2
ข้อผิดพลาดกําลังสองเฉลี่ย (MSE) คือการสูญเสียกําลังสองเฉลี่ยต่อตัวอย่างเหนือชุดข้อมูลทั้งหมด หากต้องการคํานวณ MSE ให้สรุปการสูญเสียทั้งหมดที่ยกกําลัง 2 ของแต่ละตัวอย่างแล้วหารด้วยจํานวนตัวอย่าง
ที่ไหน:
- \((x, y)\) เป็นตัวอย่างที่
- \(x\) คือชุดของฟีเจอร์ (เช่น เสียงประสาน/นาที อายุ เพศ) ที่โมเดลใช้ในการคาดการณ์
- \(y\) เป็นป้ายกํากับของตัวอย่าง (เช่น อุณหภูมิ)
- \(prediction(x)\) เป็นฟังก์ชันของน้ําหนักและการให้น้ําหนักกับชุดฟีเจอร์ \(x\)
- \(D\) เป็นชุดข้อมูลที่มีตัวอย่างป้ายกํากับจํานวนมาก ซึ่งเป็น \((x, y)\) การจับคู่
- \(N\) คือจํานวนตัวอย่างใน \(D\)
แม้ว่า MSE จะใช้กันโดยทั่วไปในแมชชีนเลิร์นนิง แต่ก็ไม่ได้เป็นฟังก์ชันการสูญเสียการทํางานเพียงอย่างเดียวหรือฟังก์ชันการสูญเสียที่ดีที่สุดสําหรับทุกสถานการณ์