Um embedding é um espaço relativamente baixo em que é possível transformar vetores de alta dimensão. Com os embeddings, é mais fácil fazer o machine learning em entradas grandes, como vetores esparsos que representam palavras. O ideal é que um embedding capture algumas das semânticas da entrada colocando-as semanticamente semelhantes no espaço de embedding. Um embedding pode ser aprendizado e reutilizado em vários modelos.
Embeddings
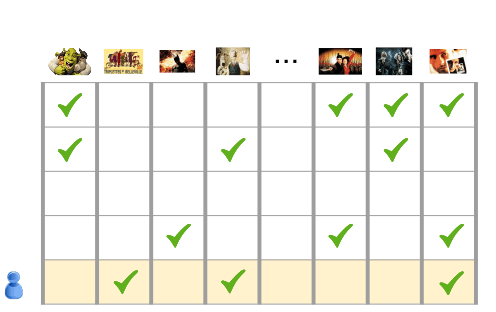
Motivação da filtragem colaborativa
- Entrada: 1 milhão de filmes que 500 mil usuários escolheram assistir.
- Tarefa: recomendar filmes para os usuários
Para solucionar esse problema, vamos adotar um método para determinar quais filmes são semelhantes entre si.
Como organizar filmes por semelhança (1d)

Como organizar filmes por semelhança (2d)

Embedding bidimensional

Embedding bidimensional

Embeddings d-dimensionais
- Supõe que o interesse do usuário em filmes pode ser explicado de forma aproximada por d aspectos
- Cada filme se torna um ponto d-dimensional em que o valor na dimensão d representa o quanto o filme se encaixa nesse aspecto
- Embeddings podem ser aprendidos com dados
Como incorporar embeddings em uma rede profunda
- Nenhum processo de treinamento separado necessário. A camada de embedding é apenas uma camada escondida com uma unidade por dimensão
- As informações supervisionadas (por exemplo, usuários assistem aos mesmos dois filmes) ajustam os embeddings aprendidos para a tarefa desejada
- As unidades ocultas descobrem como organizar os itens no espaço d-dimensional de modo a otimizar melhor o objetivo final
Representação de entrada
- Cada exemplo (uma linha nesta matriz) é um vetor esparso de recursos (filmes) que foram assistidos pelo usuário
- Representação densa desse exemplo como: (0, 1, 0, 1, 0, 0, 0, 1)
Eles não são eficientes em termos de espaço e tempo.
Representação de entrada
- Crie um dicionário que mapeie cada atributo para um número inteiro de 0, ..., # filmes - 1
- Representa o vetor esparso de maneira eficiente como apenas os filmes que o usuário assistiu. Isso pode ser representado como:


Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Problema de regressão para prever preços de vendas domésticas:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Classificação multiclasse para prever um dígito escrito à mão:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Uma camada de embedding em uma rede profunda
Filtragem colaborativa para prever filmes para recomendar:

Correspondência da visualização geométrica
Rede profunda
- Cada uma das unidades ocultas corresponde a uma dimensão (recurso atrasado)
- Os pesos de borda entre um filme e uma camada escondida são valores de coordenadas

Visualização geométrica de uma única incorporação de filme

Como selecionar o número de embeddings esmaecido
- Os embeddings de dimensões mais altas representam com mais precisão as relações entre os valores de entrada
- Mas mais dimensões aumentam a chance de overfitting e dificultam o treinamento.
- Regra de ouro empírica (um bom ponto de partida, mas deve ser ajustado usando os dados de validação): $$ dimensions \approx \sqrt[4]{possible\;values} $$
Embeddings como uma ferramenta
- Os embeddings mapeiam itens (por exemplo, filmes, texto, etc.) em vetores reais de baixa dimensão de maneira que itens semelhantes fiquem próximos uns dos outros
- Embeddings também podem ser aplicadas a dados densos (por exemplo, áudio) para criar uma métrica de semelhança significativa
- A incorporação conjunta de vários tipos de dados (por exemplo, texto, imagens, áudio etc.) define uma semelhança entre eles