На рисунках 1 и 2 представьте следующее:
- Синие точки обозначают больные деревья.
- Оранжевые точки обозначают здоровые деревья.
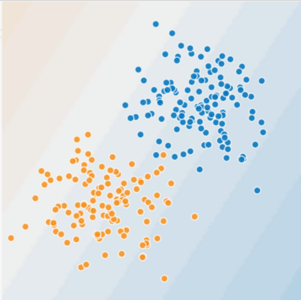
Рисунок 1. Является ли это линейной задачей?
Сможете ли вы провести линию, аккуратно отделяющую больные деревья от здоровых? Конечно. Это линейная задача. Линия не будет идеальной. Больное дерево или два могут быть на «здоровой» стороне, но ваша линия будет хорошим предсказателем.
Теперь посмотрите на следующий рисунок:
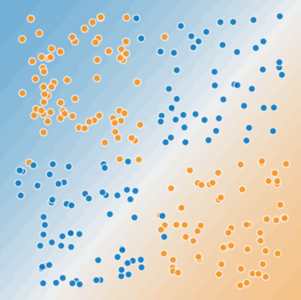
Рисунок 2. Является ли это линейной задачей?
Сможете ли вы провести одну прямую линию, аккуратно отделяющую больные деревья от здоровых? Нет, ты не можешь. Это нелинейная задача. Любая линия, которую вы нарисуете, будет плохим индикатором здоровья дерева.
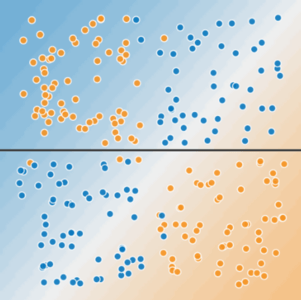
Рисунок 3. Одна линия не может разделить два класса.
Чтобы решить нелинейную задачу, показанную на рис. 2, создайте пересечение признаков. Пересечение признаков — это синтетический признак, который кодирует нелинейность в пространстве признаков путем умножения двух или более входных признаков вместе. (Термин перекрестный происходит от перекрестного произведения .) Давайте создадим перекрестный признак с именем \(x_3\) путем скрещивания \(x_1\)и \(x_2\):
Мы относимся к этой новой функции \(x_3\) , как и к любой другой функции. Линейная формула становится:
Линейный алгоритм может узнать вес для \(w_3\)точно так же, как для \(w_1\) и \(w_2\). Другими словами, хотя \(w_3\) кодирует нелинейную информацию, вам не нужно менять способ обучения линейной модели, чтобы определить значение \(w_3\).
Виды характерных крестов
Мы можем создавать множество различных типов пересечений признаков. Например:
-
[AXB]: пересечение признаков, образованное путем умножения значений двух признаков. -
[A x B x C x D x E]: пересечение признаков, образованное путем умножения значений пяти признаков. -
[A x A]: крест элементов, образованный квадратурой одного элемента.
Благодаря стохастическому градиентному спуску можно эффективно обучать линейные модели. Следовательно, дополнение масштабированных линейных моделей перекрестными признаками традиционно было эффективным способом обучения на массивных наборах данных.