Vorstellung von Funktionsverknüpfungen
Kann eine Featureverknüpfung ein Modell wirklich für nicht lineare Daten aktivieren? Versuche es mit dieser Übung.
Aufgabe: Erstellen Sie ein Modell, bei dem die blauen Punkte von den orangefarbenen Punkten getrennt werden. Ändern Sie dazu die Gewichtung der folgenden drei Eingabefeatures manuell:
- x1
- x2
- x1 x2 (Funktionskreuz)
So ändern Sie eine Gewichtung manuell:
- Klicken Sie auf eine Zeile, die FEATURES mit OUTPUT verbindet. Ein Eingabeformular wird angezeigt.
- Geben Sie in dieses Eingabeformular einen Gleitkommawert ein.
- Drücken Sie die Eingabetaste.
Die Oberfläche dieser Übung hat keine Schaltfläche für den Schritt. Das liegt daran, dass in dieser Übung ein Modell nicht iterativ trainiert wird. Stattdessen geben Sie die endgültigen Gewichtungen für das Modell manuell ein.
Die Antworten werden direkt unter der Übung angezeigt.
Komplexere Funktionsverknüpfungen
Jetzt spielen wir mit einigen erweiterten Kombinationen von Funktionen. Das Dataset in diesem Playground-Training sieht ein wenig wie eine laute Zielscheibe aus einem Dartspiel aus – mit den blauen Punkten in der Mitte und den orangefarbenen Punkten in einem äußeren Ring.
Klicken Sie auf das Pluszeichen, um eine Erläuterung der Modellvisualisierung aufzurufen.
Bei jeder Playground-Übung wird eine Visualisierung des aktuellen Status des Modells angezeigt. Beispiel für eine Visualisierung:
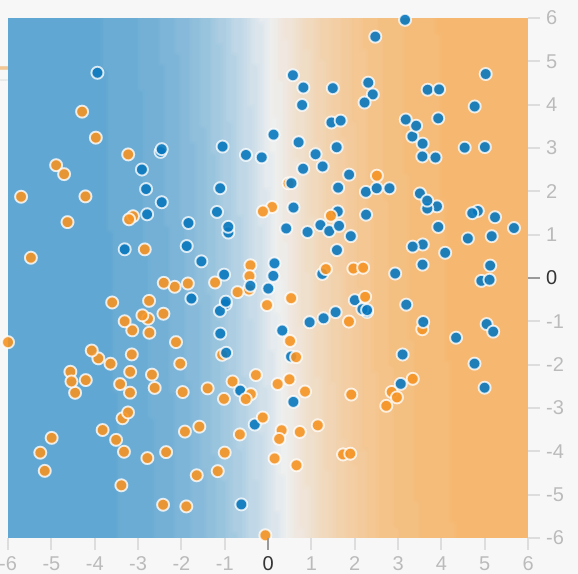
Beachten Sie Folgendes zur Modellvisualisierung:
- Jede Achse repräsentiert ein bestimmtes Merkmal. Bei Spam kann es sein, dass die Zahl der Wörter und die Anzahl der Empfänger der E-Mail nicht mit Spam übereinstimmt.
- Jeder Punkt stellt die Featurewerte für ein Beispiel der Daten dar, z. B. eine E-Mail-Adresse.
- Die Farbe des Punkts stellt die Klasse dar, zu der das Beispiel gehört. Die blauen Punkte können beispielsweise für Nicht-Spam-E-Mails stehen, die orangefarbenen Punkte für Spam-E-Mails.
- Die Hintergrundfarbe stellt die Vorhersage des Modells dar, in der Beispiele dieser Farbe zu finden sind. Ein blauer Hintergrund um einen blauen Punkt bedeutet, dass das Modell dieses Beispiel korrekt vorhersagt. Umgekehrt bedeutet ein orangefarbener Hintergrund um einen blauen Punkt, dass das Modell dieses Beispiel falsch vorhersagt.
- Die Hintergrundblaue und -orange sind skaliert. Beispielsweise ist die linke Seite der Visualisierung durchgehend blau, wird in der Mitte der Visualisierung jedoch schrittweise weiß. Sie können sich die Farbstärke so vorstellen, als würden Sie das Vertrauen des Modells in seine Vermutung nahelegen. Durchgehend blau bedeutet, dass das Modell ziemlich sicher ist. Hellblau bedeutet, dass das Modell weniger sicher ist. Die in der Abbildung gezeigte Modellvisualisierung hat eine schlechte Vorhersage.
Anhand der Visualisierung den Fortschritt des Modells beurteilen (Sehr gut) Die meisten der blauen Punkte haben einen blauen Hintergrund oder Oh nein! Die blauen Punkte haben einen orangefarbenen Hintergrund.") Abgesehen von den Farben zeigt der Playground auch den aktuellen Verlust des Modells in numerischer Form an. ("!Oh nein! Der Verlust steigt, nicht mehr nach unten.")
Aufgabe 1: Führen Sie dieses lineare Modell wie angegeben aus. Nehmen Sie sich ein bis zwei Minuten Zeit, um verschiedene Einstellungen für die Lernrate auszuprobieren. Kann ein lineares Modell effektive Ergebnisse für dieses Dataset liefern?
Aufgabe 2: Versuchen Sie nun, produktübergreifende Features wie x1x2 hinzuzufügen, um die Leistung zu optimieren.
- Welche Funktionen sind am hilfreichsten?
- Was ist die beste Leistung?
Aufgabe 3: Wenn Sie ein gutes Modell haben, prüfen Sie die Modellausgabeoberfläche (ermittelt durch die Hintergrundfarbe).
- Sieht es sich wie ein lineares Modell aus?
- Wie würden Sie das Modell beschreiben?
Die Antworten werden direkt unter der Übung angezeigt.