पेश है फ़ीचर क्रॉस
क्या कोई सुविधा क्रॉस किसी मॉडल को वाकई गैर-लीनियर डेटा में फ़िट करने के लिए सक्षम कर सकती है? इसके बारे में जानने के लिए, यह तरीका आज़माएं.
टास्क: एक ऐसा मॉडल बनाने की कोशिश करें जो नीले बिंदुओं को नारंगी बिंदुओं से अलग करता हो. इसके लिए, मैन्युअल रूप से इन तीन इनपुट सुविधाओं के महत्व में बदलाव करें:
- x1
- x2
- x1 x2 (फ़ीचर क्रॉस)
वज़न को मैन्युअल रूप से बदलने के लिए:
- उस सुविधा पर क्लिक करें जो सुविधाओं को आउटपुट में जोड़ती है. एक इनपुट फ़ॉर्म दिखेगा.
- उस इनपुट फ़ॉर्म में एक फ़्लोटिंग-पॉइंट वैल्यू टाइप करें.
- 'डालें' दबाएं.
ध्यान दें कि इस कसरत के इंटरफ़ेस में 'स्टेप' बटन नहीं है. ऐसा इसलिए है, क्योंकि यह व्यायाम किसी मॉडल को बार-बार ट्रेनिंग नहीं देता है. इसके बजाय, आप मैन्युअल रूप से मॉडल के लिए "final" वेट डाल सकते हैं.
(जवाब, कसरत के ठीक नीचे दिखते हैं.)
ज़्यादा जटिल फ़ीचर क्रॉस
आइए, अब कुछ बेहतर सुविधाओं वाले क्रॉस कॉम्बिनेशन के साथ खेलें. इस प्लेग्राउंड में सेट किया गया डेटा, डार्क्स के गेम की वजह से शोरगुल की तरह दिखता है, जिसमें बीच में नीले बिंदु और बाहरी रिंग में नारंगी बिंदु हैं.
मॉडल विज़ुअलाइज़ेशन के बारे में ज़्यादा जानकारी पाने के लिए, प्लस आइकॉन पर क्लिक करें.
खेल का हर मैदान मॉडल की मौजूदा स्थिति का विज़ुअलाइज़ेशन दिखाता है. उदाहरण के लिए, यहां एक विज़ुअलाइज़ेशन है:
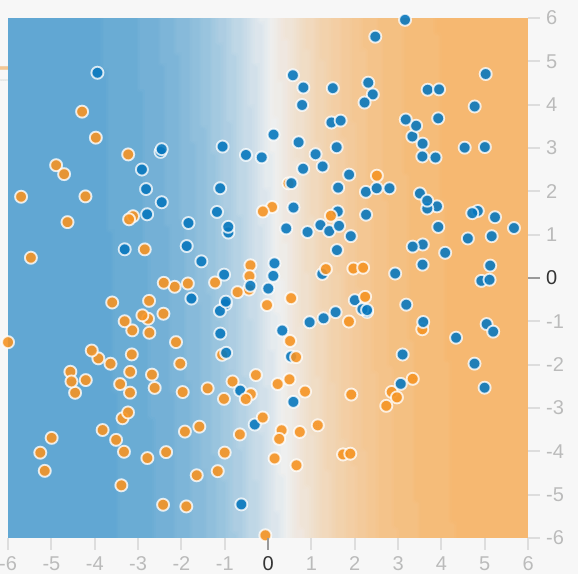
मॉडल विज़ुअलाइज़ेशन के बारे में इन बातों पर ध्यान दें:
- हर एक्सिस एक खास सुविधा के बारे में बताता है. स्पैम के मुकाबले स्पैम न होने की स्थिति में, इन शब्दों की संख्या और ईमेल पाने वालों की संख्या शामिल हो सकती है.
- हर डॉट, डेटा के एक उदाहरण को दिखाता है, जैसे कि एक ईमेल.
- बिंदु का रंग उस क्लास को दिखाता है जिससे वह उदाहरण जुड़ा है. उदाहरण के लिए, नीले बिंदु स्पैम वाले ईमेल को दिखा सकते हैं, जबकि नारंगी बिंदु स्पैम वाले ईमेल को दिखा सकते हैं.
- बैकग्राउंड का रंग, मॉडल का अनुमान दिखाता है. इससे पता चलता है कि उस रंग के उदाहरण कहां मिलने चाहिए. नीले बिंदु के आस-पास नीले बैकग्राउंड का मतलब है कि मॉडल उस उदाहरण का सही अनुमान लगा रहा है. इसके उलट, नीले बिंदु के आस-पास नारंगी रंग के बैकग्राउंड का मतलब है कि मॉडल उस उदाहरण का गलत अनुमान लगा रहा है.
- बैकग्राउंड में नीला और नारंगी रंग लगाया जाता है. उदाहरण के लिए, विज़ुअलाइज़ेशन के बाएं हिस्से का रंग नीला होता है, लेकिन विज़ुअलाइज़ेशन के बीच में धीरे-धीरे सफ़ेद रंग की तरह धुंधला दिखता जाता है. इससे, आप जान पाएंगे कि रंग का असर, मॉडल के अनुमान पर कितना भरोसा है. सॉलिड ब्लू का मतलब है कि मॉडल के लिए, अनुमान लगाना और हल्के नीले रंग का मतलब है, मॉडल पर ज़्यादा भरोसा नहीं है. (चित्र में दिखाया गया मॉडल विज़ुअलाइज़ेशन अनुमान का खराब काम कर रहा है.)
अपने मॉडल की प्रगति का आकलन करने के लिए विज़ुअलाइज़ेशन का उपयोग करें. ("बहुत बढ़िया—ज़्यादातर नीले बिंदुओं का बैकग्राउंड नीले रंग का होता है या "अरे नहीं! नीले बिंदुओं का बैकग्राउंड नारंगी हो जाता है.") रंगों के अलावा, Playground, मॉडल के मौजूदा नुकसान को भी अंकों में दिखाता है. ("अरे नहीं! गिरावट, <" के बजाय बढ़ रही है;)
टास्क 1: इस लीनियर मॉडल को जैसा बताया गया है वैसा ही चलाएं. यह देखने के लिए कि क्या आपको कोई सुधार दिख सकता है, अलग-अलग लर्निंग रेट की सेटिंग आज़माने के लिए एक या दो मिनट (लेकिन इससे ज़्यादा समय नहीं) खर्च करें. क्या लीनियर मॉडल इस डेटा सेट के लिए असरदार नतीजे दे सकता है?
टास्क 2: अब x1x2 जैसी क्रॉस-प्रॉडक्ट सुविधाएं जोड़कर, परफ़ॉर्मेंस को ऑप्टिमाइज़ करने की कोशिश करें.
- कौनसी सुविधाएं सबसे ज़्यादा मदद करती हैं?
- आपको सबसे अच्छी परफ़ॉर्मेंस क्या मिल सकती है?
टास्क 3: जब आपके पास अच्छा मॉडल हो, तो मॉडल के आउटपुट की सतह की जांच करें (बैकग्राउंड के रंग से दिखाया जाता है).
- क्या यह लीनियर मॉडल लगता है?
- इस मॉडल के बारे में आपकी क्या राय है?
(जवाब, कसरत के ठीक नीचे दिखते हैं.)