Introducción a las combinaciones de atributos
¿Una combinación de atributos puede realmente permitir que un modelo se ajuste a datos no lineales? Para averiguarlo, prueba este ejercicio.
Tarea: Intenta crear un modelo que separe los puntos azules de los anaranjados. Para ello, cambia manualmente los pesos de los siguientes tres atributos de entrada:
- x1
- x2.
- x1 x2 (una combinación de atributos)
Para cambiar manualmente un peso, haz lo siguiente:
- Haz clic en una línea que conecte ATRIBUTOS con RESULTADOS. Aparecerá un formulario de entrada.
- Escribe un valor de punto flotante en ese formulario de entrada.
- Presione Intro.
Tenga en cuenta que la interfaz de este ejercicio no contiene un botón Step. Esto se debe a que este ejercicio no entrena un modelo de forma iterativa. En cambio, deberás ingresar manualmente los pesos "finales" del modelo.
(Las respuestas aparecen justo debajo del ejercicio).
Combinaciones de atributos más complejas
Ahora, juguemos con algunas combinaciones de atributos avanzadas. Los datos de este ejercicio de Playground se parecen un poco al blanco de un juego de dardos, con puntos azules en el medio y puntos anaranjados en un anillo exterior.
Haz clic en el ícono de signo más para obtener una explicación de la visualización del modelo.
Cada ejercicio de Playground muestra una visualización del estado actual del modelo. Por ejemplo, esta es una visualización:
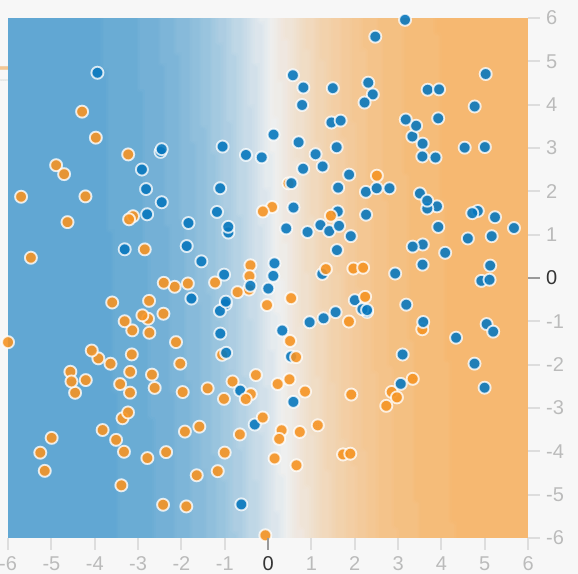
Ten en cuenta lo siguiente sobre la visualización del modelo:
- Cada eje representa una característica específica. En el caso de spam y no spam, los atributos pueden ser el recuento de palabras y la cantidad de destinatarios del correo electrónico.
- Cada punto representa los valores de los atributos de un ejemplo de los datos, como un correo electrónico.
- El color del punto representa la clase a la que pertenece el ejemplo. Por ejemplo, los puntos azules pueden representar correos electrónicos que no son spam, mientras que los puntos anaranjados pueden representarlos.
- El color de fondo representa la predicción del modelo de dónde se deben encontrar ejemplos de ese color. Un fondo azul alrededor de un punto azul significa que el modelo está prediciendo correctamente ese ejemplo. Por el contrario, un fondo naranja alrededor de un punto azul significa que el modelo no está prediciendo correctamente ese ejemplo.
- El fondo es azul y naranja. Por ejemplo, el lado izquierdo de la visualización es azul constante, pero se atenúa gradualmente a blanco en el centro de la visualización. Puedes pensar en la intensidad del color como una sugerencia de la confianza del modelo en su suposición. Por lo tanto, el color azul constante significa que el modelo está muy seguro de su suposición, mientras que el celeste significa que el modelo tiene menos confianza. (La visualización del modelo que se muestra en la figura está realizando un trabajo de predicción deficiente).
Usa la visualización para evaluar el progreso de tu modelo. Excelente. La mayoría de los puntos azules tienen un fondo azul. Los puntos azules tienen un fondo naranja. Más allá de los colores, Playground también muestra la pérdida actual del modelo de forma numérica. ("¡Oh, no! La pérdida aumenta en lugar de disminuir.")
Tarea 1: Ejecuta este modelo lineal como se muestra. Dedica uno o dos minutos (pero ya no) a probar diferentes configuraciones de tasas de aprendizaje para ver si puedes encontrar mejoras. ¿Un modelo lineal puede producir resultados eficaces para este conjunto de datos?
Tarea 2: Ahora intenta agregar atributos de productos cruzados, como x1x2, para optimizar el rendimiento.
- ¿Qué funciones son más útiles?
- ¿Cuál es el mejor rendimiento que puedes obtener?
Tarea 3: Cuando tengas un buen modelo, examina la superficie de resultados del modelo (que se muestra con el color de fondo).
- ¿Se parece a un modelo lineal?
- ¿Cómo describirías el modelo?
(Las respuestas aparecen justo debajo del ejercicio).