Présentation des croisements de caractéristiques
Un croisement de caractéristiques peut-il vraiment permettre à un modèle de s'adapter aux données non linéaires ? Pour le savoir, essayez cet exercice.
Tâche : essayez de créer un modèle qui sépare les points bleus des points orange en modifiant manuellement la pondération des trois caractéristiques d'entrée suivantes:
- x1
- x2
- x1 x2 (croisement de caractéristiques)
Pour modifier manuellement une pondération:
- Cliquez sur une ligne reliant FEATURES à OUTPUT. Un formulaire de saisie s'affiche.
- Saisissez une valeur à virgule flottante dans ce formulaire.
- Appuyez sur Entrée.
Notez que l'interface de cet exercice ne contient pas de bouton d'étape. C'est parce que cet exercice n'entraîne pas un modèle de manière itérative. Vous devez saisir manuellement les pondérations "finales" du modèle.
(Les réponses s'affichent juste en dessous de l'exercice.)
Croisements de caractéristiques plus complexes
Jouons à présent à quelques combinaisons de croisements de caractéristiques avancés. L'ensemble de données de cet exercice sur Playground présente un peu l'effet bruyant d'un jeu de fléchettes, avec les points bleus au milieu et les points orange dans un anneau extérieur.
Cliquez sur l'icône Plus pour obtenir une explication de la visualisation du modèle.
Chaque exercice Playground affiche une visualisation de l'état actuel du modèle. Voici un exemple de visualisation:
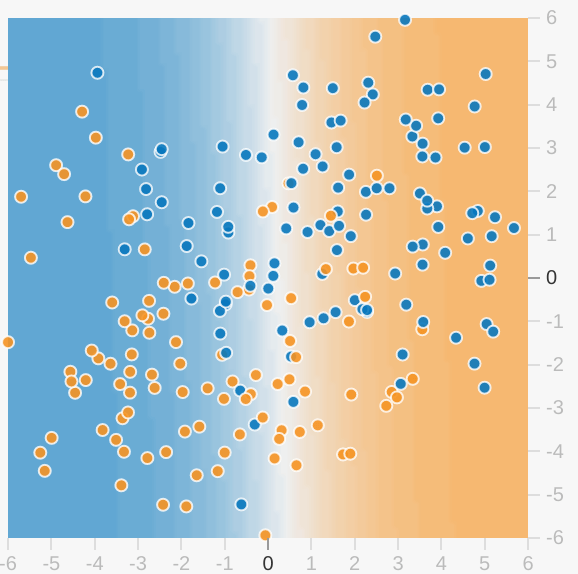
Notez les points suivants concernant la visualisation du modèle:
- Chaque axe représente une caractéristique spécifique. Dans les cas de spam ou de non-spam, les caractéristiques peuvent être le nombre de mots et le nombre de destinataires de l'e-mail.
- Chaque point représente les valeurs des caractéristiques pour un exemple de données, tel qu'un e-mail.
- La couleur du point représente la classe à laquelle appartient l'exemple. Par exemple, les points bleus peuvent représenter des e-mails légitimes, tandis que les points orange peuvent représenter des e-mails comme spam.
- La couleur de l'arrière-plan représente la prédiction d'emplacement des exemples de cette couleur par le modèle. Un point bleu autour d'un point bleu signifie que le modèle prédit correctement cet exemple. À l'inverse, un arrière-plan orange autour d'un point bleu signifie que le modèle prédit correctement cet exemple.
- L'arrière-plan bleu et orange est mis à l'échelle. Par exemple, le côté gauche de la visualisation est bleu fixe, mais s'affiche progressivement en blanc au centre de la visualisation. Vous pouvez considérer la force de la couleur comme une indication de la fiabilité du modèle. Si le bleu est plein, cela signifie que le degré de confiance du modèle est très élevé, tandis que le bleu clair indique un niveau de confiance moindre. (La visualisation du modèle illustrée dans la figure ne donne pas de bons résultats de prédiction.)
Utilisez la visualisation pour évaluer la progression de votre modèle. (Excellent : la plupart des points bleus ont un arrière-plan bleu, ou non ! Les points bleus sont sur fond orange.) Au-delà des couleurs, Playground affiche également la perte actuelle du modèle sous forme numérique. (Oh non ! La perte augmente au lieu de baisser.)
Tâche 1 : exécutez ce modèle linéaire comme indiqué. Essayez une minute ou deux (mais pas plus) d'essayer différents paramètres de taux d'apprentissage pour voir si vous pouvez trouver des améliorations. Un modèle linéaire peut-il produire des résultats efficaces pour cet ensemble de données ?
Tâche 2 : essayez à présent d'ajouter des caractéristiques de produits croisés, telles que x1x2, pour essayer d'optimiser les performances.
- Quelles fonctionnalités sont les plus utiles ?
- Quelles sont les meilleures performances possibles ?
Tâche 3 : lorsque vous disposez d'un modèle satisfaisant, examinez sa surface de sortie (affichée par la couleur d'arrière-plan).
- Ressemble-t-elle à un modèle linéaire ?
- Comment décririez-vous le modèle ?
(Les réponses s'affichent juste en dessous de l'exercice.)