Memperkenalkan Persilangan Fitur
Dapatkah suatu persilangan fitur benar-benar memungkinkan suatu model agar sesuai dengan data non-linear? Untuk mengetahuinya, coba latihan ini.
Tugas: Cobalah membuat model yang memisahkan titik biru dari titik oranye dengan secara manual mengubah bobot tiga fitur input berikut:
- x1
- x2
- x1 x2 (persilangan fitur)
Untuk mengubah berat secara manual:
- Klik baris yang menghubungkan FITUR ke KELUARAN. Formulir input akan muncul.
- Ketik nilai floating-point ke formulir input tersebut.
- Tekan Enter.
Perhatikan bahwa antarmuka untuk latihan ini tidak berisi tombol Langkah. Itu karena latihan ini tidak melatih model secara berulang. Namun, Anda akan memasukkan bobot "final" secara manual untuk model.
(Jawaban muncul tepat di bawah latihan.)
Persilangan Fitur yang Lebih Kompleks
Sekarang mari kita bermain dengan beberapa kombinasi silang fitur lanjutan. Set data dalam latihan Playground ini terlihat sedikit mirip dengan lingkaran panah berisik dari game panah, dengan titik biru di tengah dan titik oranye di lingkaran luar.
Klik ikon plus untuk mendapatkan penjelasan tentang visualisasi model.
Setiap latihan Playground menampilkan visualisasi status model saat ini. Misalnya, berikut adalah visualisasinya:
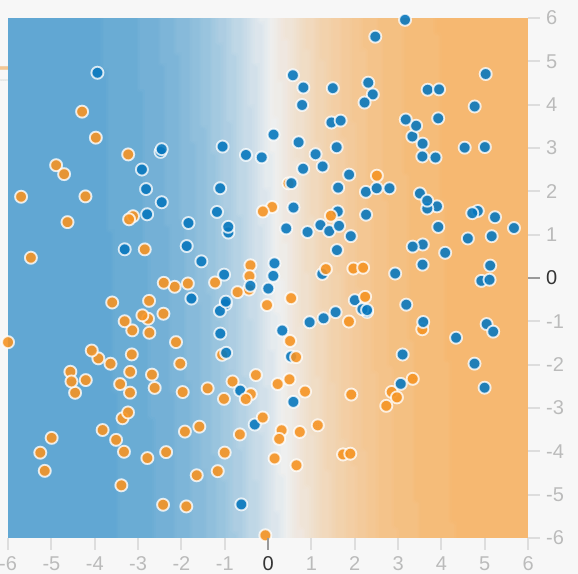
Perhatikan hal-hal berikut tentang visualisasi model:
- Setiap sumbu mewakili fitur tertentu. Untuk spam vs. bukan spam, fiturnya dapat berupa jumlah kata dan jumlah penerima email.
- Setiap titik memetakan nilai fitur untuk satu contoh data, seperti email.
- Warna titik mewakili class tempat contoh tersebut berada. Misalnya, titik biru dapat mewakili email non-spam sedangkan titik oranye dapat mewakili email spam.
- Warna latar belakang mewakili prediksi model tempat contoh warna tersebut akan ditemukan. Latar belakang biru di sekitar titik biru berarti model memprediksi contoh tersebut dengan benar. Sebaliknya, latar belakang oranye di sekitar titik biru berarti bahwa model salah memprediksi contoh tersebut.
- Skala biru dan oranye diskalakan. Misalnya, sisi kiri visualisasi berwarna biru solid, tetapi secara bertahap memudar menjadi putih di tengah visualisasi. Anda dapat menganggap kekuatan warna menunjukkan keyakinan model pada tebakannya. Jadi, biru pekat berarti bahwa model sangat yakin dengan tebakannya dan biru muda berarti bahwa model kurang yakin. (Visualisasi model yang ditunjukkan pada gambar adalah melakukan pekerjaan prediksi yang buruk.)
Gunakan visualisasi untuk menilai kemajuan model Anda. ("Luar biasa—sebagian besar titik biru memiliki latar belakang biru" atau "Oh tidak! Titik biru memiliki latar belakang oranye." Selain warna, Playground juga menampilkan kerugian model saat ini secara numerik. ("Ya ampun! Kerugian semakin naik, bukannya turun.")
Tugas 1: Jalankan model linear ini seperti yang diberikan. Luangkan waktu satu atau dua menit (tetapi tidak lebih) untuk mencoba setelan kecepatan pembelajaran yang berbeda-beda guna melihat apakah ada peningkatan. Dapatkah model linear memberikan hasil yang efektif untuk set data ini?
Tugas 2: Sekarang coba tambahkan fitur lintas produk, seperti x1x2, dengan mencoba mengoptimalkan performa.
- Fitur apa yang paling membantu?
- Apa performa terbaik yang bisa Anda dapatkan?
Tugas 3: Jika Anda memiliki model yang bagus, periksa permukaan output model (ditunjukkan dengan warna latar belakang).
- Apakah itu terlihat seperti model linear?
- Bagaimana Anda mendeskripsikan model?
(Jawaban muncul tepat di bawah latihan.)