कई समस्याओं के लिए आउटपुट के रूप में संभावना का अनुमान लगाना ज़रूरी होता है. लॉजिस्टिक रिग्रेशन करने की क्षमता, क्षमताओं को गिनने का बहुत अच्छा तरीका है. व्यावहारिक तौर पर, आप दिए गए दो तरीकों में से किसी एक का इस्तेमाल करके, लौट चुके संभावना का इस्तेमाल कर सकते हैं:
- &कोट;जैसे है"
- बाइनरी कैटगरी में बदला गया.
चलिए, देखते हैं कि हम प्रॉबेबिलिटी और कोट को कैसे इस्तेमाल कर सकते हैं;और मान लीजिए कि हम इस बात की संभावना का अनुमान लगाने के लिए, एक लॉजिस्टिक रिग्रेशन मॉडल बनाते हैं कि कुत्ते की आधी रात के दौरान भौंकने की संभावना होती है. हम उस संभावना को कॉल करेंगे:
\[p(bark | night)\]
अगर लॉजिस्टिक रिग्रेशन मॉडल का अनुमान \(p(bark | night) = 0.05\)
\[\begin{align} startled &= p(bark | night) \cdot nights \\ &= 0.05 \cdot 365 \\ &~= 18 \end{align} \]
कई मामलों में, आप लॉजिस्टिक रिग्रेशन आउटपुट को बाइनरी क्लासिफ़िकेशन समस्या के समाधान में मैप करेंगे. इसमें लक्ष्य दो संभावित लेबल में से किसी एक का सही अनुमान लगाना होगा (जैसे कि "स्पैम" या "न कि स्पैम". बाद में मॉड्यूल पर फ़ोकस किया जाता है.
शायद आप यह जानना चाहते हैं कि लॉजिस्टिक रिग्रेशन मॉडल से 0 और 1 के बीच हमेशा आउटपुट कैसे मिलता है. ऐसा होने पर, sgmoid फ़ंक्शन को इस तरह परिभाषित किया जाता है. इससे एक जैसे नतीजे मिलते हैं:
Sigmoid फ़ंक्शन नीचे दिए गए चार्ट दिखाता है:
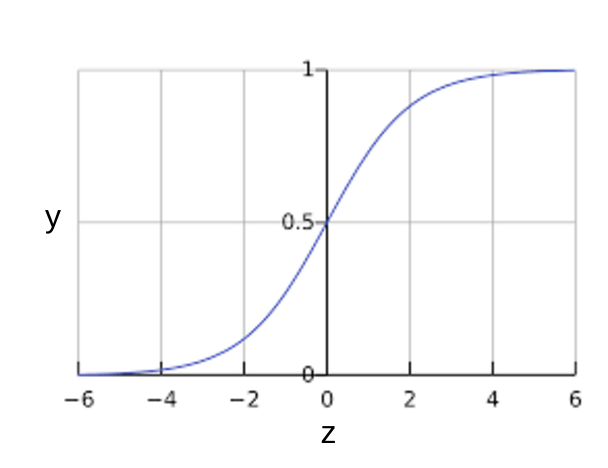
पहली इमेज: Sigmoid फ़ंक्शन.
अगर \(z\) लॉजिस्टिक रिग्रेशन से प्रशिक्षित मॉडल की लीनियर लेयर के आउटपुट को दिखाता है, तो \(sigmoid(z)\) 0 और 1 के बीच वैल्यू (एक संभावना) जनरेट करेगा. गणित के शब्दों में:
कहां:
- \(y'\) किसी खास उदाहरण के लिए लॉजिस्टिक रिग्रेशन मॉडल का आउटपुट है.
- \(z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\)
- \(w\) मान, मॉडल के'के महत्व और \(b\) मान होते हैं.
- \(x\) वैल्यू किसी खास उदाहरण के लिए सुविधा की वैल्यू होती हैं.
ध्यान दें कि \(z\) इसे लॉग-ऑड भी कहा जाता है, क्योंकि सिगमॉइड के उलट में बताया गया है कि \(z\) \(1\) के संभावना की लॉग के रूप में परिभाषित किया जा सकता है (उदाहरण के लिए, "dog Bark") को \(0\) लेबल की संभावना से भाग दिया जाता है (उदाहरण के लिए, "dog &&30;t Bark"):
यहां एमएल लेबल के लिए सिगऑइड फ़ंक्शन दिया गया है:

दूसरी इमेज: लॉजिस्टिक रिग्रेशन आउटपुट.
लॉजिस्टिक रिग्रेशन अनुमान का सैंपल देखने के लिए, प्लस आइकॉन पर क्लिक करें.
मान लें कि हमारे पास तीन सुविधाओं वाला लॉजिस्टिक रिग्रेशन मॉडल है, जिनमें इन झुकावों और महत्व की जानकारी है:
$$\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} $$इसके अलावा, दिए गए उदाहरण के लिए नीचे दी गई सुविधा के मान मानें:
$$\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} $$इसलिए, लॉग-ओड:
यह होगा:
$$(1) + (2)(0) + (-1)(10) + (5)(2) = 1$$इस वजह से, इस उदाहरण के लिए लॉजिस्टिक रिग्रेशन अनुमान 0.731 होगा:

तीसरा डायग्राम: 73.1% संभावना.