許多問題都需要預估機率做為輸出。邏輯迴歸是計算機率的極佳機制。簡單來說,您可以透過下列兩種方式使用傳回的可能性:
- "
- 已轉換為二進位類別。
讓我們思考一下我們該如何運用「原樣」。假設我們建立了邏輯迴歸模型,預測狗狗在半夜會醒來的機率。這就是所謂的機率:
\[p(bark | night)\]
如果邏輯迴歸模型預測到 \(p(bark | night) = 0.05\),則在一年內,狗狗和飼主應該開始喚醒約 18 次:
\[\begin{align} startled &= p(bark | night) \cdot nights \\ &= 0.05 \cdot 365 \\ &~= 18 \end{align} \]
在許多情況下,您會將邏輯迴歸輸出對應至解決方案,以對應至二元分類問題,目標就是正確預測兩種標籤之一 (例如,「垃圾郵件」或「非垃圾內容」)。而後續的模組。
您可能想知道邏輯迴歸模型如何確保輸出內容一律在 0 到 1 之間。在此情況下,sigmoid 函式 (定義如下) 會產生具備相同特性的輸出內容:
sigmoid 函式會產生以下圖表:
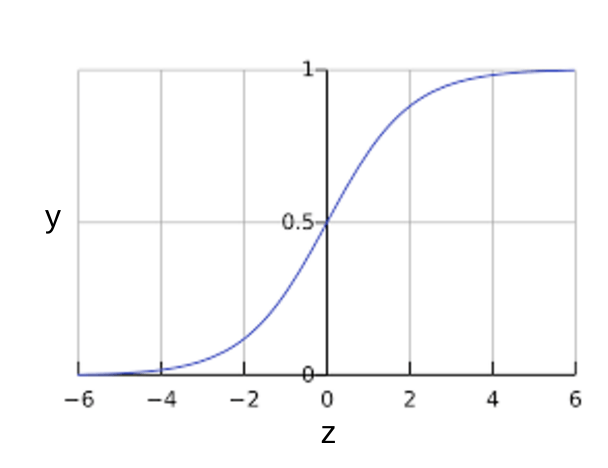
圖 1:Sigmoid 函式。
如果 \(z\) 代表使用邏輯迴歸訓練模型的模型線性輸出,則 \(sigmoid(z)\) 會產生 0 到 1 之間的值 (機率)。以數學術語表示:
其中:
- \(y'\) 是特定範例的邏輯迴歸模型輸出。
- \(z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\)
- \(w\) 值是模型學習的權重, \(b\) 是偏誤。
- \(x\) 值是特定範例的特徵值。
請注意, \(z\) 也稱為「記錄奇數」,因為 sigmoid 狀態的反轉指出, \(z\) 可以定義為 \(1\) 標籤機率的記錄 (例如"dog Barak")) 除以 \(0\)標籤的機率 (例如"dog do't bark"):
以下是具有機器學習標籤的 sigmoid 函式:

圖 2:邏輯迴歸輸出。
按一下加號圖示即可查看邏輯迴歸推論示例。
假設我們有邏輯迴歸模型,其中具有三個特徵,並學到以下偏誤和權重:
$$\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} $$進一步假設特定範例的功能值如下:
$$\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} $$因此,記錄機率:
會是:
$$(1) + (2)(0) + (-1)(10) + (5)(2) = 1$$因此,這個特定範例的迴歸預測為 0.731:

圖 3:73.1% 的機率。