Hiperparametry to zmienne, które kontrolują różne aspekty treningu. Trzy typowe hiperparametry to:
Z kolei parametry to zmienne, takie jak wagi i uśrednione wartości błędów, które są częścią samego modelu. Innymi słowy, hiperparametry to wartości, które kontrolujesz; parametry to wartości obliczane przez model podczas trenowania.
Tempo uczenia się
Szybkość uczenia się to ustawiona przez Ciebie liczba zmiennoprzecinkowa, która wpływa na szybkość konwergencji modelu. Jeśli tempo uczenia się jest za niskie, model może potrzebować dużo czasu na konwergencję. Jeśli jednak tempo uczenia się jest zbyt wysokie, model nigdy nie osiągnie konwergencji, lecz będzie się wahać wokół wag i uprzedzeń, które minimalizują stratę. Celem jest wybranie tempa uczenia się, które nie jest ani zbyt wysokie, ani zbyt niskie, aby model szybko osiągnął konwergencję.
Tempo uczenia się określa wielkość zmian, które należy wprowadzić w wagach i uśrednieniu na każdym kroku procesu schodzącego gradientu. Model mnoży gradient przez tempo uczenia się, aby określić parametry modelu (wartości wag i uprzedzeń) na potrzeby następnej iteracji. W 3 kroku spadku gradientu „mała wartość” do przesunięcia w kierunku ujemnego spadku odnosi się do szybkości uczenia.
Różnica między parametrami starego a nowego modelu jest proporcjonalna do nachylenia funkcji utraty. Jeśli na przykład nachylenie jest duże, model wykonuje duży krok. Jeśli jest mały, wystarczy mały krok. Jeśli na przykład wielkość gradientu wynosi 2,5, a tempo uczenia się 0,01, model zmieni parametr o 0,025.
Idealne tempo uczenia się pomaga modelowi osiągnąć zbieżność w rozsądnej liczbie iteracji. Na rysunku 21 krzywa strat pokazuje, że model znacznie się polepsza w ciągu pierwszych 20 iteracji, zanim zacznie się zbliżać do wartości docelowej:
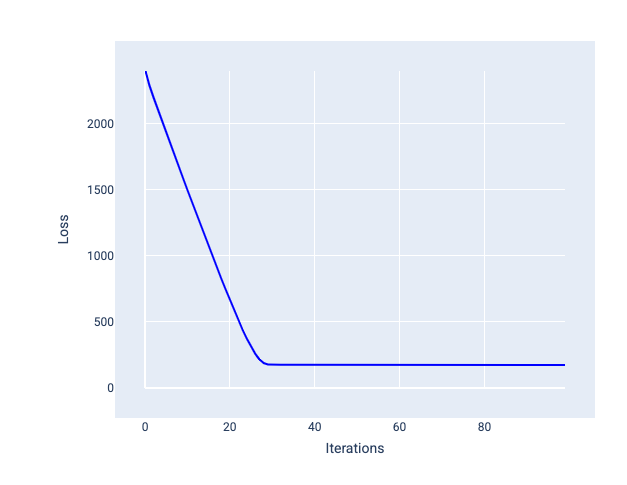
Rysunek 21. Wykres utraty pokazujący model wytrenowany z tempo uczenia się, który szybko się zbieży.
Zbyt mała szybkość uczenia się może natomiast wymagać zbyt wielu iteracji, aby osiągnąć zbieżność. Na rysunku 22 krzywa strat pokazuje, że po każdej iteracji model wprowadza tylko niewielkie ulepszenia:

Rysunek 22. Wykres utraty pokazujący model wytrenowany przy małej szybkości uczenia.
Tempo uczenia się, które jest zbyt duże, nigdy nie osiąga konwergencji, ponieważ każda iteracja albo powoduje, że utrata waha się lub stale rośnie. Na rysunku 23 krzywa strat pokazuje, że po każdej iteracji model najpierw zmniejsza, a potem zwiększa straty. Na rysunku 24 straty rosną w kolejnych iteracjach:

Rysunek 23. Wykres strat pokazujący model trenowany z za dużym tempem uczenia się, na którym krzywa straty gwałtownie się waha, podnosząc i opuszczając wraz ze wzrostem liczby iteracji.
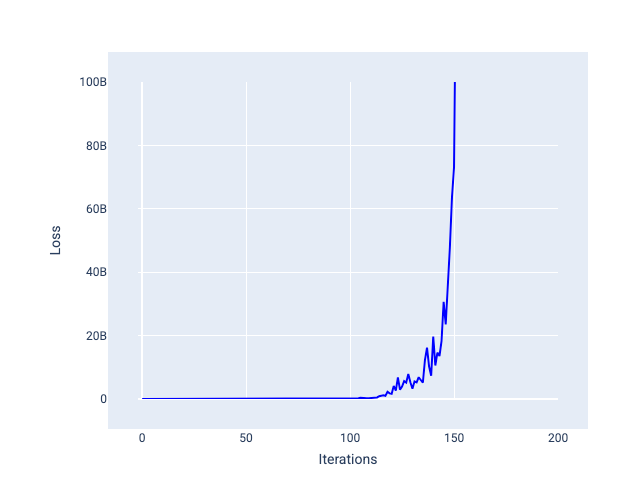
Rysunek 24. Wykres strat pokazujący model wytrenowany z za dużym tempem uczenia się, na którym krzywa straty gwałtownie wzrasta w późniejszych iteracjach.
Ćwiczenie: sprawdź swoją wiedzę
Wielkość wsadu
Rozmiar partii to parametr, który odnosi się do liczby przykładów, które model przetwarza przed zaktualizowaniem wag i uśrednienia. Możesz sądzić, że model powinien obliczyć stratę dla każdego przykładu w zbiorze danych, zanim zaktualizuje wagi i uśrednienie. Jeśli jednak zbiór danych zawiera setki tysięcy lub nawet miliony przykładów, użycie pełnej partii nie jest praktyczne.
Dwie popularne techniki uzyskiwania prawidłowego gradientu w przypadku średniej, które nie wymagają sprawdzania wszystkich przykładów w zbiorze danych przed zaktualizowaniem wag i uśrednienia to stochastyczny gradient descent i stochastyczny gradient descent w przypadku minipartii:
Stochastyczny spadek wzdłuż gradientu (SGD): stochastyczny spadek wzdłuż gradientu używa tylko jednego przykładu (wsad o wielkości 1) na iterację. Przy wystarczającej liczbie iteracji SGD działa, ale jest bardzo głośny. „Szum” to odchylenia podczas trenowania, które powodują, że strata wzrasta, a nie maleje podczas iteracji. Określenie „stochastyczny” oznacza, że pojedynczy przykład z każdej partii jest wybierany losowo.
Na poniższym obrazie widać, jak utrata nieco się waha, gdy model aktualizuje wagi i uświadczenia za pomocą SGD, co może powodować szum na wykresie utraty:
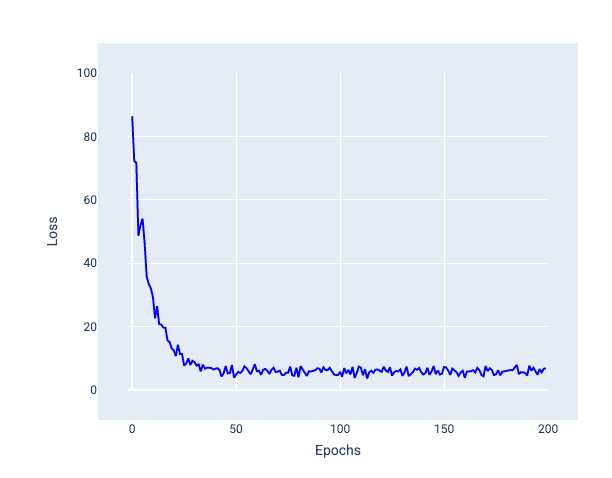
Rysunek 25. Model wytrenowany za pomocą stochastycznego spadku wzdłuż gradientu (SGD) z szumem na krzywej utraty.
Pamiętaj, że stochastyczne zstępowanie ku gradientowi może powodować szum na całej krzywej strat, a nie tylko w pobliżu punktu zbieżności.
Spadek wzdłuż stochastycznego gradientu w minipartiach (SGD w minipartiach): stochastyczny spadek wzdłuż gradientu w minipartiach to kompromis między pełnym spadkiem wzdłuż gradientu a SGD. W przypadku liczby punktów danych rozmiar partii może być dowolną liczbą większą od 1 i mniejszą od . Model wybiera przykłady zawarte w każdej partii losowo, uśrednia ich gradienty, a następnie aktualizuje wagi i uśrednia raz na iterację.
Określanie liczby przykładów w każdej partii zależy od zbioru danych i dostępnych zasobów obliczeniowych. Ogólnie małe rozmiary zbiorów danych działają jak SGD, a większe zbiory działają jak pełny zstępujący gradient.
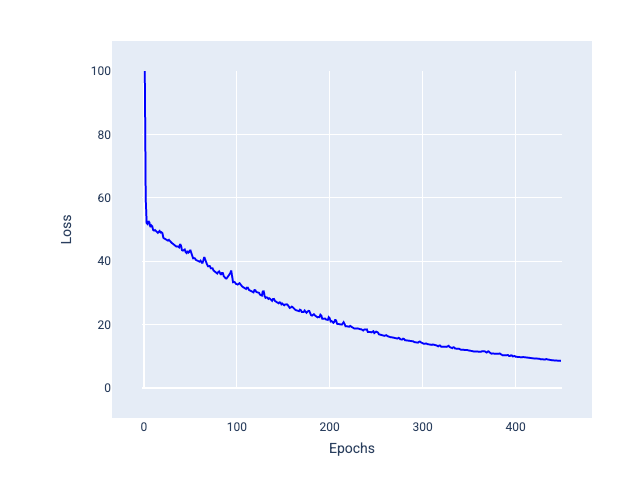
Rysunek 26. Model wytrenowany za pomocą mini-batch SGD.
Podczas trenowania modelu możesz uznać, że szum jest niepożądaną cechą, którą należy wyeliminować. Jednak pewien poziom szumów może być korzystny. W kolejnych modułach dowiesz się, jak szum może pomóc modelowi w lepszym uogólnianiu i znajdowaniu optymalnych wag i uprzedzeń w sieci neuronowej.
Epochs
Podczas trenowania epoka oznacza, że model przetworzył raz każdy przykład ze zbioru treningowego. Jeśli np. zbiór treningowy zawiera 1000 przykładów, a rozmiar miniwkładu to 100 przykładów,model będzie potrzebował 10 iterations, aby ukończyć jedną epokę.
Trening wymaga zwykle wielu epok. Oznacza to, że system musi przetworzyć każdy przykład z zbioru treningowego kilka razy.
Liczba epok to parametr, który ustawiasz przed rozpoczęciem treningu modelu. W wielu przypadkach trzeba eksperymentalnie ustalić, ile epok potrzeba, aby model osiągnął zbieżność. Ogólnie rzecz biorąc, im więcej epok, tym lepszy model, ale trenowanie zajmuje też więcej czasu.
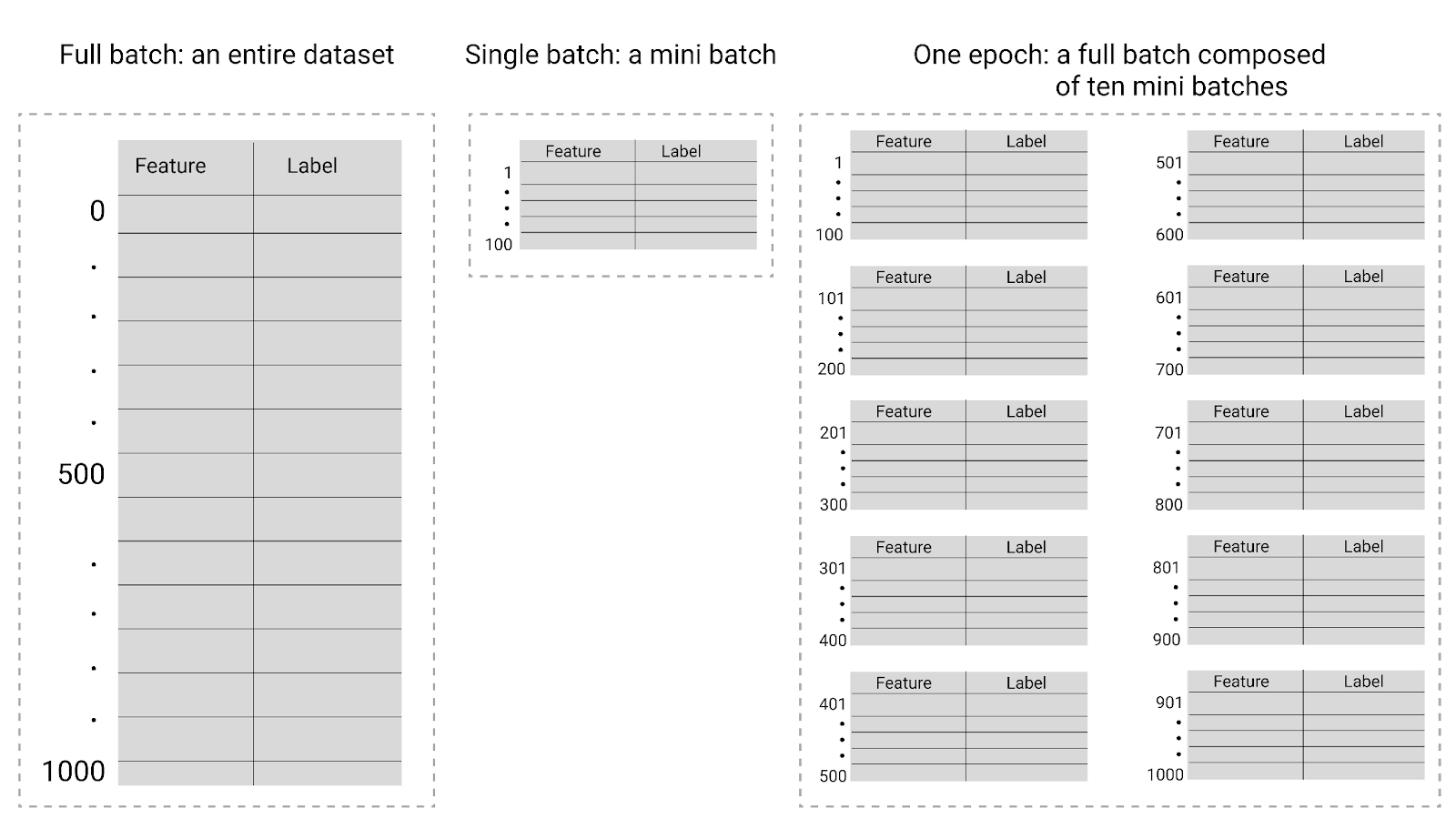
Rysunek 27. Pełna partia a mini partia.
W tabeli poniżej opisano, jak rozmiar partii i epoki wpływają na liczbę razy, ile model aktualizuje swoje parametry.
| Typ wsadu | Kiedy aktualizowane są wagi i przesunięcia. |
|---|---|
| Pełny wsad | Gdy model przejrzy wszystkie przykłady w zbiorze danych. Jeśli na przykład zbiór danych zawiera 1000 przykładów, a model trenuje się przez 20 epok, aktualizuje on wagi i uśrednione wartości błędów 20 razy, po jednej w każdej epoce. |
| Stochastyczny spadek wzdłuż gradientu | Po tym, jak model przyjrzy się jednemu przykładowi ze zbioru danych. Jeśli na przykład zbiór danych zawiera 1000 przykładów i jest trenowany przez 20 epoch, model aktualizuje wagi i uśrednione wartości błędów 20 tysięcy razy. |
| Stochastyczny spadek wzdłuż gradientu z minipartiami | Po tym, jak model przeanalizuje przykłady w każdej partii. Jeśli na przykład zbiór danych zawiera 1000 przykładów, a rozmiar partii to 100, a model trenuje przez 20 epok, aktualizuje on wagi i uśrednione błędy 200 razy. |