Öğrenme Oranı ve Uyum
Bu, çeşitli Playground alıştırmalarının ilki. Playground, makine öğrenimi ilkelerini öğretmek amacıyla özellikle bu kurs için geliştirilmiş bir programdır. Bu kurstaki her Playground alıştırması, hazır ayarları olan yerleşik bir oyun alanı örneği içerir.
Her Playground alıştırması bir veri kümesi oluşturur. Bu veri kümesinin etiketinde iki olası değer bulunur. Bu iki olası değeri, spam yerine spam değil, sağlıklı ağaçlar ve hasta ağaçlar olarak düşünebilirsiniz. Çoğu alıştırmanın amacı, bir etiket değerini diğerinden başarılı bir şekilde sınıflandıran (ayıran veya ayıran) bir model oluşturmak için çeşitli hiperparametrelerde ince ayar yapmaktır. Çoğu veri kümesinin, her örneğin başarıyla sınıflandırılmasını imkansız hale getirecek kadar yüksek miktarda gürültü içerdiğini unutmayın.
Model görselleştirmenin bir açıklaması için artı simgesini tıklayın.
Her Playground alıştırması, modelin mevcut durumunun bir görselleştirmesini gösterir. Örneğin, aşağıda bir görselleştirme örneği verilmiştir:
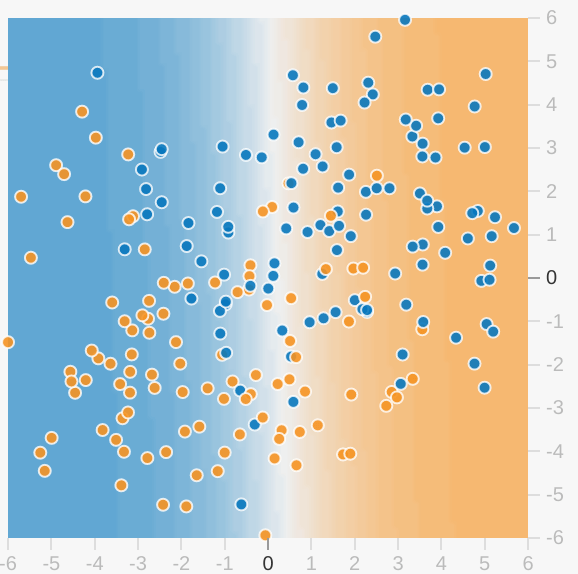
Model görselleştirmeyle ilgili olarak aşağıdakileri göz önünde bulundurun:
- Her eksen, belirli bir özelliği temsil eder. Spam veya spam değil olması durumunda özellik, e-postanın kelime sayısı ve alıcı sayısı olabilir.
- Her nokta, bir veri örneği (ör. e-posta) için özellik değerlerini gösterir.
- Noktanın rengi, örneğin ait olduğu sınıfı temsil eder. Örneğin, mavi noktalar spam olmayan e-postaları temsil ederken turuncu noktalar spam e-postaları temsil edebilir.
- Arka plan rengi, modelin söz konusu rengin örneklerinin nerede bulunduğuna dair tahminini temsil eder. Mavi noktanın çevresindeki mavi arka plan, modelin söz konusu örneği doğru şekilde tahmin ettiği anlamına gelir. Buna karşılık, mavi noktanın etrafındaki turuncu arka plan, modelin söz konusu örneği yanlış bir şekilde tahmin ettiği anlamına gelir.
- Arka plan mavi ve turuncu renkleri ölçeklendirilir. Örneğin, görselleştirmenin sol tarafı düz mavi renktedir ancak görselleştirmenin ortasında yavaş yavaş beyaza döner. Renk gücünü, modelin tahminine ne kadar güvendiğini göstermek olarak düşünebilirsiniz. Yani düz mavi, modelin tahmininden çok emin olduğunu, açık mavi ise modelin daha az güven duyduğunu gösterir. (Şekilde gösterilen model görselleştirmesi, tahmin konusunda yetersiz performans göstermektedir.)
Modelinizin ilerlemesini değerlendirmek için görselleştirmeyi kullanın. ("Mükemmel. Mavi noktaların çoğunun arka planı mavidir" veya "Hay aksi! Mavi noktaların arka planı turuncu olur.") Playground, renklerin ötesinde modelin mevcut kaybını sayısal olarak gösterir. ("Hay aksi! Kayıp, azalmak yerine artmaktadır.")
Bu alıştırmanın arayüzünde üç düğme vardır:
| Simge | Ad | Ne İşe Yarar? |
|---|---|---|
|
|
Sıfırla | Yinelemeler'i 0'a sıfırlar. Modelin önceden öğrendiği tüm ağırlıkları sıfırlar. |
|
|
Adım | Bir yineleme ilerletin. Her iterasyonda model, bazen fark etmeden, bazen önemli ölçüde değişir. |
|
|
Yeniden üret | Yeni bir veri kümesi oluşturur. Yinelemeleri sıfırlamaz. |
Bu ilk Playground alıştırmasında, iki görevi gerçekleştirerek öğrenme hızıyla deney yapacaksınız.
1. Görev: Playground'un sağ üst kısmındaki Öğrenme oranı menüsüne dikkat edin. Verilen Öğrenme oranı (3) çok yüksek. "Adım" düğmesini 10 veya 20 kez tıklayarak yüksek öğrenme oranının modelinizi nasıl etkilediğini gözlemleyin. Her erken iterasyondan sonra model görselleştirmenin nasıl önemli ölçüde değiştiğine dikkat edin. Model birleştikten sonra bile biraz istikrarsızlık görebilirsiniz. Ayrıca, x1 ve x2'den model görselleştirmeye uzanan çizgilere de dikkat edin. Bu çizgilerin ağırlıkları, modeldeki bu özelliklerin ağırlıklarını belirtir. Yani, kalın bir çizgi yüksek bir ağırlığı gösterir.
2. Görev: Aşağıdakileri yapın:
- Sıfırla düğmesine basın.
- Öğrenme hızını düşürün.
- Adım düğmesine birkaç kez basın.
Düşük öğrenme hızı, yakınsaklığı nasıl etkiledi? Modelin yakınlaşması için gereken adım sayısını ve aynı zamanda modelin ne kadar sorunsuz ve istikrarlı bir şekilde yakınlaştığını inceleyin. Daha düşük öğrenme hızı değerleriyle denemeler yapın. Sizce yararlı olamayacak kadar düşük bir öğrenme hızı var mı? (Alıştırmanın hemen altında bir tartışma yer alır.)