في هذه الوحدة، ستستكشف أبسط خوارزمية للفاصل وأكثرها شيوعًا، والتي تُنشئ شروطًا من النوع $\mathrm{feature}_i \geq t$ في الإعداد التالي:
- مهمة التصنيف الثنائي
- بدون قيم مفقودة في الأمثلة
- بدون فهرس محسوب مسبقًا على الأمثلة
نفترض أنّ لدينا مجموعة من n مثال تتضمّن سمة رقمية وتصنيفًا ثنائيًا، وهو "برتقالي" و "أزرق". بشكل رسمي، لنصف مجموعة البيانات $D$ على النحو التالي:
حيث:
- $x_i$ هي قيمة سمة رقمية في $\mathbb{R}$ (مجموعة الأعداد الحقيقية).
- $y_i$ هي قيمة تصنيف ثنائي في {orange, blue}.
هدفنا هو العثور على قيمة حدّ أدنى $t$ (الحدّ الأدنى) بحيث يؤدي تقسيم الأمثلة $D$ إلى مجموعتَي $T(rue)$ و$F(alse)$ وفقًا لحالة $x_i \geq t$ إلى تحسين فصل التصنيفات، على سبيل المثال، زيادة الأمثلة "البرتقالية" في $T$ وزيادة الأمثلة "الزرقاء" في $F$.
إنتروبيا Shannon هي مقياس للاضطراب. بالنسبة إلى التصنيف الثنائي:
- تكون نظرية المعلومات من نوع Shannon في أعلى مستوى لها عندما تكون التصنيفات في الأمثلة متوازنة (50% أزرق و50% برتقالي).
- تكون نظرية المعلومات من نوع Shannon في أدنى مستوياتها (القيمة صفر) عندما تكون التصنيفات في الأمثلة خالصة (أزرق بنسبة% 100 أو برتقالي بنسبة% 100).

الشكل 8: ثلاثة مستويات مختلفة من التشويش
بشكل رسمي، نريد العثور على شرط يخفض المجموع المرجح لملفه الشخصي القصور في توزيعات التصنيفات في $T$ و $F$. النتيجة المقابلة هي مكاسب المعلومات، والتي هي الفرق بين ملف التعريف الخاص بـ $D$ وملف التعريف الخاص بـ {$T$,$F$}. ويُسمّى هذا الاختلاف مكاسب المعلومات.
يعرض الشكل التالي عملية تقسيم سيئة، حيث تظلّ الانتروبيا مرتفعة وينخفض معدل اكتساب المعلومات:

الشكل 9. لا يؤدي التقسيم غير الصحيح إلى تقليل القصور المُرجّح للتصنيف.
في المقابل، يعرض الشكل التالي عملية تقسيم أفضل تصبح فيها الانتروبي منخفضة (ويكون اكتساب المعلومات مرتفعًا):

الشكل 10. إنّ التقسيم الجيد يقلل من القصور في التصنيف.
رسميًا:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
حيث:
- $IG(D,T,F)$ هو اكتساب المعلومات الناتج عن تقسيم $D$ إلى $T$ و $F$.
- $H(X)$ هو قياس نقص المعلومات لمجموعة الأمثلة $X$.
- $|X|$ هو عدد العناصر في المجموعة $X$.
- $t$ هي قيمة الحدّ الأدنى.
- $pos$ هي قيمة التصنيف موجب، على سبيل المثال، "أزرق" في المثال أعلاه. إنّ اختيار تصنيف مختلف ليكون "التصنيف الإيجابي" لا يغيّر قيمة التشويش أو معلومات المكاسب.
- $R(X)$ هي نسبة قيم التصنيفات الموجبة في الأمثلة $X$.
- $D$ هي مجموعة البيانات (كما هو محدّد سابقًا في هذه الوحدة).
في المثال التالي، نأخذ في الاعتبار مجموعة بيانات تصنيف ثنائية تحتوي على سمة رقمية واحدة هي $x$. يعرض الشكل التالي قيمًا مختلفة للحدّ $t$ (المحور x):
- المدرج التكراري للميزة $x$
- نسبة أمثلة "الأزرق" في مجموعات $D$ و$T$ و $F$ وفقًا لقيمة الحدّ
- الإنتروبيا في $D$ و$T$ و $F$
- اكتساب المعلومات، أيّ فرق القصور بين $D$ و{$T$,$F$} مركّزًا بعدد الأمثلة
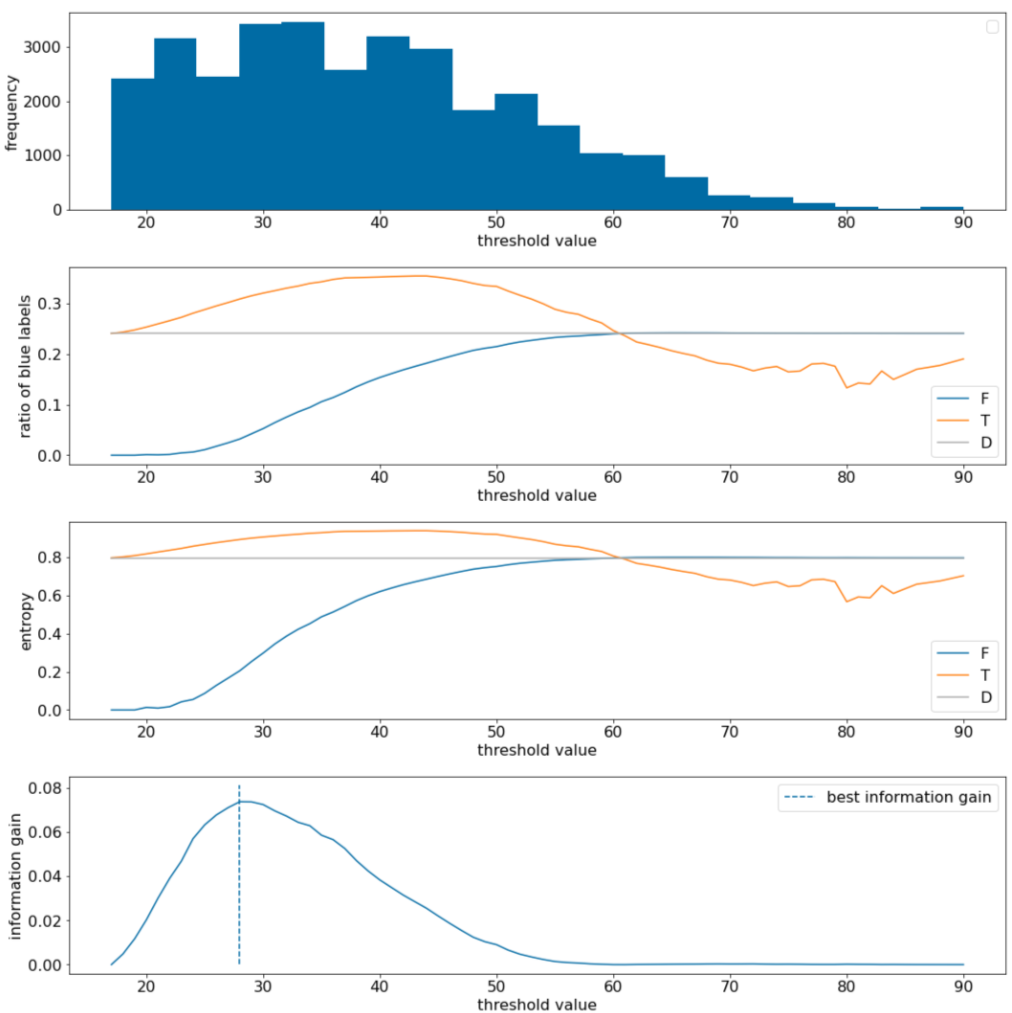
الشكل 11. أربعة مخطّطات حدود.
تعرض هذه المخططات ما يلي:
- يوضِّح مخطّط "الوتيرة" أنّ الملاحظات موزّعة بشكل جيد نسبيًا مع تركيزات تتراوح بين 18 و60. يعني نطاق القيم الواسع أنّ هناك الكثير من التقسيمات المحتملة، ما يُعدّ أمرًا جيدًا لتدريب النموذج.
تبلغ نسبة التصنيفات "الأزرق" في مجموعة البيانات 25% تقريبًا. يوضّح الرسم البياني "نسبة التصنيف الأزرق" أنّه بالنسبة إلى قيم الحدود الدنيا التي تتراوح بين 20 و50:
- تحتوي مجموعة $T$ على عدد زائد من أمثلة التصنيف "أزرق" (ما يصل إلى% 35 عند الحدّ 35).
- تحتوي مجموعة $F$ على نقص تكميلي في أمثلة التصنيف "أزرق" (%8 فقط عند الحدّ الأدنى 35).
تشير كلّ من الرسمَين البيانيَين "نسبة التصنيفات الزرقاء" و "التشتت" إلى أنّه يمكن فصل التصنيفات بشكل جيد نسبيًا في هذا النطاق من الحدود الدنيا.
يتم تأكيد هذه الملاحظة في الرسم البياني "مكاسب المعلومات". نرى أنّه يتم الحصول على الحد الأقصى من تحصيل المعلومات عند t~=28 لقيمة تحصيل المعلومات تبلغ 0.074 تقريبًا. وبالتالي، سيكون الشرط الذي يعرضه المُقسِّم هو $x \geq 28$.
يكون اكتساب المعلومات دائمًا موجبًا أو صفريًا. وتتقارب مع الصفر عندما تقارب قيمة الحدّ الأدنى / الحدّ الأقصى. في هذه الحالات، يصبح إما $F$ أو $T$ فارغًا بينما يحتوي الآخر على مجموعة البيانات بالكامل ويعرض كمية فوضى تساوي تلك الواردة في $D$. يمكن أن يكون مكاسب المعلومات أيضًا صفريًا عندما يكون $H(T)$ = $H(F)$ = $H(D)$. عند الحدّ الأدنى 60، تكون نسب التصنيفات "الأزرق" لكلّ من $T$ و $F$ متطابقة مع تلك الواردة في $D$ ويكون مكسب المعلومات صفريًا.
القيم المُحتمَلة للمتغيّر t في مجموعة الأعداد الحقيقية ($\mathbb{R}$) هي لانهائية. ومع ذلك، نظرًا لعدد محدود من الأمثلة، لا يتوفّر سوى عدد محدود من عمليات تقسيم $D$ إلى $T$ و $F$. لذلك، لا يكون سوى عدد محدود من قيم t ذات مغزى للاختبار.
من الأساليب الكلاسيكية ترتيب القيم xi بترتيب تصاعدي xs(i) على النحو التالي:
بعد ذلك، اختبِر t لكل قيمة في منتصف القيم المتسلسلة المرتبطة بـ $x_i$. على سبيل المثال، لنفترض أنّ لديك 1,000 قيمة نقطية عائمة لسمة معيّنة. بعد الترتيب، لنفترض أنّ القيمتَين الأولى والثانية هما 8.5 و8.7. في هذا السياق، ستكون قيمة الحدّ الأدنى الأولى التي سيتم اختبارها هي 8.6.
بشكل رسمي، نأخذ في الاعتبار القيم المرشحة التالية لـ t:
التعقيد الزمني لهذه الخوارزمية هو $\mathcal{O} ( n \log n) $ مع $n$ هو عدد الأمثلة في العقدة (بسبب ترتيب قيم السمات). عند تطبيقها على شجرة قرارات، يتم تطبيق خوارزمية المُقسِّم على كل عقدة وكل ميزة. يُرجى العِلم أنّ كل عقدة تتلقّى حوالي نصف الأمثلة الرئيسية. لذلك، وفقًا للنظرية الأساسية، تبلغ التعقيد الزمني لتدريب شجرة قرارات باستخدام هذا المُقسِّم:
حيث:
- $m$ هو عدد الميزات.
- $n$ هو عدد أمثلة التدريب.
في هذه الخوارزمية، لا يهمّ قيمة الميزات، بل الترتيب فقط. لهذا السبب، تعمل هذه الخوارزمية بشكل مستقل عن المقياس أو توزيع قيم السمات. لهذا السبب، لا نحتاج إلى تسويتها أو تصغيرها عند تدريب شجرة قرارات.