Dans cet atelier, vous allez découvrir l'algorithme de fractionnement le plus simple et le plus courant, qui crée des conditions de la forme $\mathrm{feature}_i \geq t$ dans le paramètre suivant:
- Tâche de classification binaire
- Sans valeurs manquantes dans les exemples
- Sans index précalculé sur les exemples
Supposons un ensemble d'exemples $n$ avec une caractéristique numérique et un libellé binaire "orange" et "bleu". Formellement, décrivons l'ensemble de données $D$ comme suit:
où :
- $x_i$ est la valeur d'une caractéristique numérique dans $\mathbb{R}$ (l'ensemble des nombres réels).
- $y_i$ est une valeur de libellé de classification binaire dans {orange, bleu}.
Notre objectif est de trouver une valeur seuil $t$ (seuil) telle que la division des exemples $D$ en groupes $T(rue)$ et $F(alse)$ selon la condition $x_i \geq t$ améliore la séparation des étiquettes. Par exemple, plus d'exemples "oranges" dans $T$ et plus d'exemples "bleus" dans $F$.
L'entropie de Shannon est une mesure du désordre. Pour un libellé binaire:
- L'entropie de Shannon est maximale lorsque les étiquettes des exemples sont équilibrées (50% de bleu et 50% d'orange).
- L'entropie de Shannon est minimale (valeur nulle) lorsque les étiquettes des exemples sont pures (100% bleu ou 100% orange).

Figure 8. Trois niveaux d'entropie différents.
Formellement, nous voulons trouver une condition qui diminue la somme pondérée de l'entropie des distributions de libellés dans $T$ et $F$. Le score correspondant est le gain d'information, qui correspond à la différence entre l'entropie de $D$ et l'entropie de {$T$,$F$}. Cette différence s'appelle le gain d'information.
La figure suivante montre une mauvaise division, dans laquelle l'entropie reste élevée et le gain d'information faible:

Figure 9. Une mauvaise division ne réduit pas l'entropie du libellé.
À l'inverse, la figure suivante montre une meilleure répartition dans laquelle l'entropie devient faible (et le gain d'information élevé):

Figure 10. Une bonne division réduit l'entropie du libellé.
Formellement:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
où :
- $IG(D,T,F)$ est le gain d'information obtenu en divisant $D$ en $T$ et $F$.
- $H(X)$ est l'entropie de l'ensemble d'exemples $X$.
- $|X|$ est le nombre d'éléments de l'ensemble $X$.
- $t$ est la valeur du seuil.
- $pos$ est la valeur du libellé positif, par exemple "bleu" dans l'exemple ci-dessus. Choisir un autre libellé comme "libellé positif" ne modifie pas la valeur de l'entropie ni le gain d'information.
- $R(X)$ est le ratio des valeurs d'étiquette positives dans les exemples $X$.
- $D$ correspond au jeu de données (tel que défini précédemment dans ce module).
Dans l'exemple suivant, nous considérons un ensemble de données de classification binaire avec une seule caractéristique numérique $x$. La figure suivante montre, pour différentes valeurs de seuil $t$ (axe X):
- Histogramme de la caractéristique $x$.
- Ratio des exemples "bleus" dans les ensembles $D$, $T$ et $F$ en fonction de la valeur du seuil.
- Entropie dans $D$, $T$ et $F$.
- Gain d'information, c'est-à-dire delta d'entropie entre $D$ et {$T$,$F$} pondéré par le nombre d'exemples.
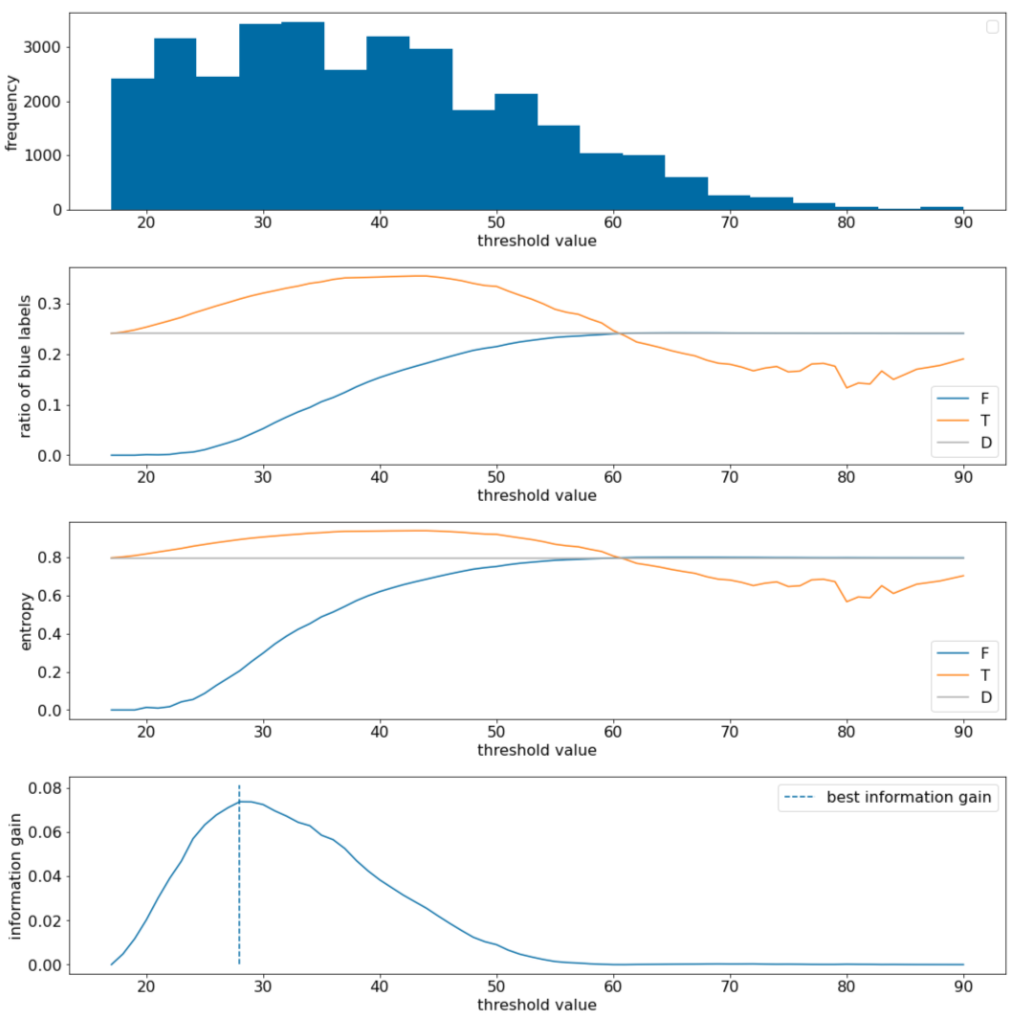
Figure 11. Quatre graphiques de seuils.
Ces graphiques montrent les éléments suivants:
- Le graphique "Fréquence" montre que les observations sont relativement bien réparties, avec des concentrations comprises entre 18 et 60. Une plage de valeurs large signifie qu'il existe de nombreuses divisions potentielles, ce qui est bon pour l'entraînement du modèle.
Le ratio des libellés "bleu" dans l'ensemble de données est d'environ 25%. Le graphique "Ratio de l'étiquette bleue" montre que pour les valeurs de seuil comprises entre 20 et 50:
- L'ensemble $T$ contient un excès d'exemples de libellés "bleu" (jusqu'à 35% pour le seuil de 35).
- L'ensemble $F$ contient un déficit complémentaire d'exemples d'étiquettes "bleu" (seulement 8% pour le seuil 35).
Les graphiques "Ratio des libellés bleus" et "Entropie" indiquent que les libellés peuvent être relativement bien séparés dans cette plage de seuil.
Cette observation est confirmée dans le graphique "Gain d'information". Nous constatons que le gain d'information maximal est obtenu avec t~=28 pour une valeur de gain d'information d'environ 0,074. Par conséquent, la condition renvoyée par le séparateur sera $x \geq 28$.
Le gain d'information est toujours positif ou nul. Il converge vers zéro à mesure que la valeur du seuil converge vers sa valeur maximale / minimale. Dans ces cas, soit $F$, soit $T$ devient vide, tandis que l'autre contient l'ensemble de données complet et affiche une entropie égale à celle de $D$. Le gain d'information peut également être nul lorsque $H(T)$ = $H(F)$ = $H(D)$. Au seuil 60, les ratios des étiquettes "bleues" pour $T$ et $F$ sont les mêmes que ceux de $D$, et le gain d'information est nul.
Les valeurs candidates pour $t$ dans l'ensemble des nombres réels ($\mathbb{R}$) sont infinies. Toutefois, étant donné un nombre fini d'exemples, il n'existe qu'un nombre fini de divisions de $D$ en $T$ et $F$. Par conséquent, seul un nombre fini de valeurs de $t$ sont pertinentes à tester.
Une approche classique consiste à trier les valeurs xi dans l'ordre croissant xs(i), de sorte que:
Ensuite, testez $t$ pour chaque valeur à mi-chemin entre les valeurs triées consécutives de $x_i$. Par exemple, supposons que vous disposiez de 1 000 valeurs à virgule flottante d'une caractéristique particulière. Après le tri, supposons que les deux premières valeurs soient 8,5 et 8,7. Dans ce cas, la première valeur de seuil à tester serait 8,6.
Formellement, nous considérons les valeurs candidates suivantes pour t:
La complexité temporelle de cet algorithme est $\mathcal{O} ( n \log n) $, où $n$ est le nombre d'exemples dans le nœud (en raison du tri des valeurs des caractéristiques). Lorsqu'il est appliqué à un arbre de décision, l'algorithme de fractionnement est appliqué à chaque nœud et à chaque caractéristique. Notez que chaque nœud reçoit environ la moitié de ses exemples parent. Par conséquent, selon le théorème principal, la complexité temporelle de l'entraînement d'un arbre de décision avec ce séparateur est la suivante:
où :
- $m$ correspond au nombre de fonctionnalités.
- $n$ correspond au nombre d'exemples d'entraînement.
Dans cet algorithme, la valeur des caractéristiques n'a pas d'importance. Seul l'ordre compte. C'est pourquoi cet algorithme fonctionne indépendamment de l'échelle ou de la distribution des valeurs des éléments géographiques. C'est pourquoi nous n'avons pas besoin de normaliser ni de redimensionner les caractéristiques numériques lors de l'entraînement d'un arbre de décision.