Nesta unidade, você vai conhecer o algoritmo de divisão mais simples e comum, que cria condições da forma $\mathrm{feature}_i \geq t$ na seguinte configuração:
- Tarefa de classificação binária
- Sem valores ausentes nos exemplos
- Sem índice pré-calculado nos exemplos
Considere um conjunto de $n$ exemplos com um atributo numérico e um rótulo binário "laranja" e "azul". Vamos descrever formalmente o conjunto de dados $D$ como:
em que:
- $x_i$ é o valor de um atributo numérico em $\mathbb{R}$ (o conjunto de números reais).
- $y_i$ é um valor de rótulo de classificação binária em {laranja, azul}.
Nosso objetivo é encontrar um valor de limite $t$ (threshold) de modo que dividir os exemplos $D$ nos grupos $T(rue)$ e $F(alse)$ de acordo com a condição $x_i \geq t$ melhore a separação dos rótulos. Por exemplo, mais exemplos "laranja" em $T$ e mais exemplos "azul" em $F$.
A entropia de Shannon é uma medida de desordem. Para um rótulo binário:
- A entropia de Shannon está no máximo quando os rótulos nos exemplos são equilibrados (50% azul e 50% laranja).
- A entropia de Shannon é mínima (valor zero) quando os rótulos nos exemplos são puros (100% azul ou 100% laranja).

Figura 8. Três níveis diferentes de entropia.
Formalmente, queremos encontrar uma condição que diminua a soma ponderada da entropia das distribuições de rótulos em $T$ e $F$. A pontuação correspondente é o ganho de informação, que é a diferença entre a entropia de $D$ e a entropia de {$T$,$F$}. Essa diferença é chamada de ganho de informação.
A figura a seguir mostra uma divisão ruim, em que a entropia permanece alta e o ganho de informação é baixo:

Figura 9. Uma divisão incorreta não reduz a entropia do rótulo.
Por outro lado, a figura a seguir mostra uma divisão melhor em que a entropia fica baixa (e o ganho de informação é alto):

Figura 10. Uma boa divisão reduz a entropia do rótulo.
Formalmente:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
em que:
- $IG(D,T,F)$ é o ganho de informação de dividir $D$ em $T$ e $F$.
- $H(X)$ é a entropia do conjunto de exemplos $X$.
- $|X|$ é o número de elementos no conjunto $X$.
- $t$ é o valor de limite.
- $pos$ é o valor do rótulo positivo, por exemplo, "azul" no exemplo acima. Escolher um rótulo diferente para ser o "rótulo positivo" não muda o valor da entropia nem o ganho de informação.
- $R(X)$ é a proporção dos valores de rótulo positivos nos exemplos $X$.
- $D$ é o conjunto de dados (conforme definido anteriormente nesta unidade).
No exemplo a seguir, consideramos um conjunto de dados de classificação binária com um único recurso numérico $x$. A figura a seguir mostra diferentes valores de limite $t$ (eixo x):
- O histograma do atributo $x$.
- A proporção de exemplos "azuis" nos conjuntos $D$, $T$ e $F$ de acordo com o valor de limite.
- A entropia em $D$, $T$ e $F$.
- O ganho de informação, ou seja, a delta de entropia entre $D$ e {$T$,$F$} ponderada pelo número de exemplos.
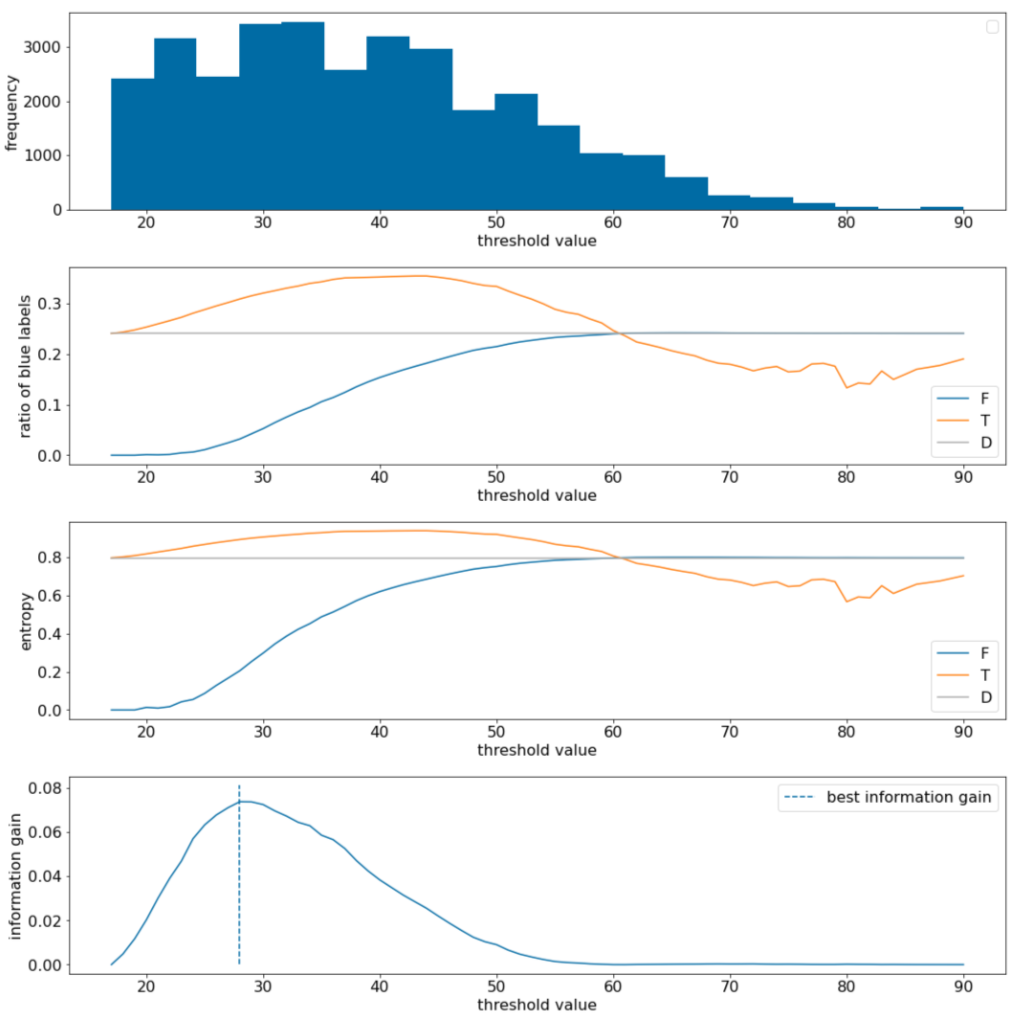
Figura 11. Quatro gráficos de limite.
Esses gráficos mostram o seguinte:
- O gráfico "frequency" mostra que as observações estão relativamente bem distribuídas com concentrações entre 18 e 60. Uma ampla distribuição de valores significa que há muitas divisões possíveis, o que é bom para treinar o modelo.
A proporção de rótulos "azuis" no conjunto de dados é de aproximadamente 25%. O gráfico "proporção de rótulo azul" mostra que, para valores de limite entre 20 e 50:
- O conjunto $T$ contém um excesso de exemplos de rótulos "azuis" (até 35% para o limite 35).
- O conjunto $F$ contém um déficit complementar de exemplos de rótulos "azuis" (apenas 8% para o limite 35).
Tanto o "proporção de rótulos azuis" quanto os gráficos de "entropia" indicam que os rótulos podem ser relativamente bem separados nesse intervalo de limite.
Essa observação é confirmada no gráfico "ganho de informação". O ganho máximo de informação é obtido com t~=28 para um valor de ganho de informação de ~0,074. Portanto, a condição retornada pelo divisor será $x \geq 28$.
O ganho de informação é sempre positivo ou nulo. Ele converge para zero à medida que o valor de limite converge para o valor máximo / mínimo. Nesses casos, $F$ ou $T$ fica vazio, enquanto o outro contém todo o conjunto de dados e mostra uma entropia igual à de $D$. O ganho de informação também pode ser zero quando $H(T)$ = $H(F)$ = $H(D)$. No limite 60, as proporções de rótulos "azuis" para $T$ e $F$ são iguais à de $D$, e o ganho de informação é zero.
Os valores candidatos para $t$ no conjunto de números reais ($\mathbb{R}$) são infinitos. No entanto, dado um número finito de exemplos, apenas um número finito de divisões de $D$ em $T$ e $F$ existe. Portanto, apenas um número finito de valores de $t$ é significativo para testar.
Uma abordagem clássica é classificar os valores xi em ordem crescente xs(i), de modo que:
Em seguida, teste $t$ para cada valor no meio entre valores ordenados consecutivos de $x_i$. Por exemplo, suponha que você tenha 1.000 valores de ponto flutuante de uma feature específica. Após a ordenação, suponha que os dois primeiros valores sejam 8,5 e 8,7. Nesse caso, o primeiro valor de limite a ser testado seria 8,6.
Formalmente, consideramos os seguintes valores candidatos para t:
A complexidade temporal desse algoritmo é $\mathcal{O} ( n \log n) $, sendo $n$ o número de exemplos no nó (por causa da classificação dos valores dos atributos). Quando aplicado a uma árvore de decisão, o algoritmo de divisão é aplicado a cada nó e a cada elemento. Cada nó recebe cerca de 1/2 dos exemplos pai. Portanto, de acordo com o teorema principal, a complexidade de tempo do treinamento de uma árvore de decisão com esse divisor é:
em que:
- $m$ é o número de recursos.
- $n$ é o número de exemplos de treinamento.
Nesse algoritmo, o valor dos recursos não importa. Só a ordem é importante. Por esse motivo, esse algoritmo funciona independentemente da escala ou da distribuição dos valores de atributos. É por isso que não precisamos normalizar ou dimensionar os atributos numéricos ao treinar uma árvore de decisão.