이 단원에서는 다음 설정에서 $\mathrm{feature}_i \geq t$ 형식의 조건을 만드는 가장 간단하고 일반적인 분할 알고리즘을 살펴봅니다.
- 이진 분류 태스크
- 예시에서 누락된 값이 없음
- 예시에서 사전 계산된 색인이 없음
숫자 특성과 '주황색' 및 '파란색'이라는 이진 라벨이 있는 $n$ 개의 예시 집합을 가정해 보겠습니다. 공식적으로 데이터 세트 $D$ 를 다음과 같이 설명합니다.
각 항목의 의미는 다음과 같습니다.
- $x_i$ 는 $\mathbb{R}$ (실수 집합)의 숫자 특성 값입니다.
- $y_i$ 는 {주황색, 파란색}의 이진 분류 라벨 값입니다.
목표는 $x_i \geq t$ 조건에 따라 예시 $D$ 를 그룹 $T (rue)$ 및 $F(alse)$ 로 나누면 라벨 분리가 개선되는 임곗값 $t$(threshold)를 찾는 것입니다. 예를 들어 $T$ 에는 '주황색' 예시가 더 많고 $F$에는 '파란색' 예시가 더 많습니다.
섀넌 엔트로피는 무질서의 척도입니다. 바이너리 라벨의 경우:
- 예시의 라벨이 균형을 이루면(파란색 50%, 주황색 50%) Shannon entropy가 최대가 됩니다.
- 예시의 라벨이 순수한 경우 (100% 파란색 또는 100% 주황색) Shannon 엔트로피는 최솟값 (값 0)입니다.

그림 8. 세 가지 엔트로피 수준
공식적으로는 $T$ 와 $F$의 라벨 분포 엔트로피의 가중치 합계를 줄이는 조건을 찾고자 합니다. 이에 상응하는 점수는 $D$의 엔트로피와 {$T$,$F$} 엔트로피의 차이인 정보 이득입니다. 이 차이를 정보 이득이라고 합니다.
다음 그림은 엔트로피가 높게 유지되고 정보 이득이 낮은 잘못된 분할을 보여줍니다.

그림 9. 잘못된 분할은 라벨의 엔트로피를 줄이지 않습니다.
반면 다음 그림은 엔트로피가 낮아지고 정보 이득이 높은 더 나은 분할을 보여줍니다.

그림 10. 적절한 분할은 라벨의 엔트로피를 줄입니다.
공식적으로:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
각 항목의 의미는 다음과 같습니다.
- $IG(D,T,F)$ 는 $D$ 를 $T$ 와 $F$로 분할할 때의 정보 이득입니다.
- $H(X)$ 는 예 집합 $X$의 엔트로피입니다.
- $|X|$ 는 집합 $X$의 요소 수입니다.
- $t$ 는 임곗값입니다.
- $pos$ 는 양성 라벨 값입니다(예: 위 예시의 '파란색'). '양성 라벨'로 다른 라벨을 선택해도 엔트로피 또는 정보 이득의 값은 변경되지 않습니다.
- $R(X)$ 는 예 $X$의 긍정적인 라벨 값의 비율입니다.
- $D$ 는 데이터 세트입니다 (이 단원의 앞부분에서 정의됨).
다음 예에서는 단일 숫자 특성 $x$가 있는 이진 분류 데이터 세트를 고려합니다. 다음 그림은 다양한 임곗값 $t$ (x축)을 보여줍니다.
- 특성 $x$의 히스토그램
- 임곗값에 따라 $D$, $T$, $F$ 세트의 '파란색' 예시의 비율입니다.
- $D$, $T$, $F$의 엔트로피입니다.
- 정보 이득. 즉, $D$ 와 {$T$,$F$} 간의 엔트로피 델타에 예시 수를 가중치로 적용한 값입니다.
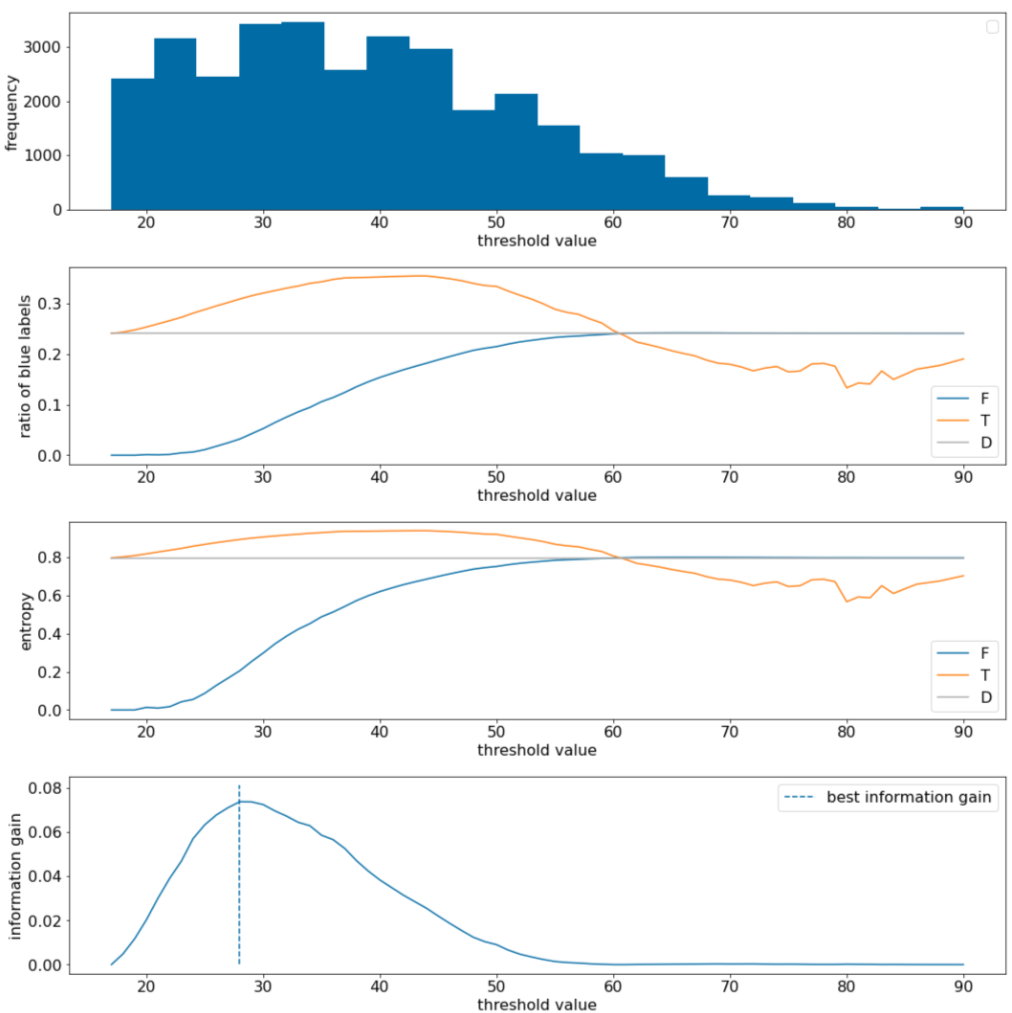
그림 11. 기준점 플롯 4개
이 플롯은 다음을 보여줍니다.
- '빈도' 플롯은 관측값이 18~60 사이의 농도로 비교적 고르게 분포되어 있음을 보여줍니다. 값 분포가 넓으면 잠재적인 분할이 많다는 의미이므로 모델 학습에 좋습니다.
데이터 세트의 '파란색' 라벨 비율은 약 25%입니다. '파란색 라벨 비율' 플롯은 기준점 값이 20~50인 경우 다음과 같이 표시됩니다.
- $T$ 세트에 '파란색' 라벨 예시가 너무 많습니다 (임곗값 35의 경우 최대 35%).
- $F$ 세트에는 '파란색' 라벨 예시의 보완적 적자가 포함되어 있습니다(기준점 35의 경우 8% 만 해당).
'파란색 라벨의 비율'과 '엔트로피' 플롯 모두 이 기준점 범위에서 라벨을 비교적 잘 구분할 수 있음을 나타냅니다.
이 관찰은 '정보 이득' 플롯에서 확인할 수 있습니다. 정보 이득 값이 ~0.074인 경우 t~=28에서 최대 정보 이득이 얻어집니다. 따라서 스플리터가 반환하는 조건은 $x \geq 28$입니다.
정보 이득은 항상 양수 또는 null입니다. 기준점 값이 최대 / 최솟값으로 수렴함에 따라 0으로 수렴합니다. 이 경우 $F$ 또는 $T$ 가 비워지고 다른 하나는 전체 데이터 세트를 포함하며 $D$의 엔트로피와 동일한 엔트로피를 보여줍니다. $H(T)$ = $H(F)$ = $H(D)$인 경우 정보 이득이 0이 될 수도 있습니다. 임곗값 60에서 $T$ 와 $F$ 의 '파란색' 라벨 비율은 $D$ 의 비율과 동일하며 정보 이득은 0입니다.
실수 집합 ($\mathbb{R}$)에서 $t$의 후보 값은 무한대입니다. 그러나 한정된 수의 예가 주어질 때 $D$ 를 $T$ 와 $F$ 로 나누는 방법은 유한 개만 존재합니다. 따라서 테스트에 의미가 있는 $t$ 값은 유한 개수입니다.
기존 접근 방식은 xi 값을 다음과 같이 xs(i) 오름차순으로 정렬하는 것입니다.
그런 다음 $x_i$ 의 연속 정렬된 값의 중간에 있는 모든 값에 대해 $t$를 테스트합니다. 예를 들어 특정 지형지물의 부동 소수점 값이 1,000개 있다고 가정해 보겠습니다. 정렬 후 첫 번째 두 값이 8.5와 8.7이라고 가정해 보겠습니다. 이 경우 테스트할 첫 번째 임곗값은 8.6입니다.
공식적으로 t의 후보 값은 다음과 같습니다.
이 알고리즘의 시간 복잡성은 $\mathcal{O} ( n \log n) $ 이며 여기서 $n$ 은 노드의 예시 수입니다 (특성 값 정렬로 인해). 분할 알고리즘은 결정 트리에 적용될 때 각 노드와 각 특성에 적용됩니다. 각 노드는 상위 예시의 약 1/2를 수신합니다. 따라서 마스터 정리에 따르면 이 스플리터를 사용하여 결정 트리를 학습하는 데 걸리는 시간 복잡도는 다음과 같습니다.
각 항목의 의미는 다음과 같습니다.
- $m$ 은 특성의 수입니다.
- $n$ 은 학습 예시의 수입니다.
이 알고리즘에서는 특성의 값이 중요하지 않으며 순서만 중요합니다. 따라서 이 알고리즘은 특성 값의 크기나 분포와 관계없이 작동합니다. 따라서 결정 트리를 학습할 때 숫자 특성을 정규화하거나 확장할 필요가 없습니다.