Bu birimde, aşağıdaki ayarda $\mathrm{feature}_i \geq t$ biçiminde koşullar oluşturan en basit ve en yaygın ayırıcı algoritmayı keşfedeceksiniz:
- İkili sınıflandırma görevi
- Örneklerde eksik değer olmamalıdır.
- Örneklerde önceden hesaplanmış dizin olmadan
Sayısal bir özellik ve "turuncu" ile "mavi" olmak üzere ikili bir etiket içeren $n$ örnekten oluşan bir veri kümesi olduğunu varsayalım. Resmi olarak, $D$ veri kümesini şu şekilde tanımlayalım:
Bu örnekte:
- $x_i$, $\mathbb{R}$ (reel sayılar kümesi) içindeki sayısal bir özelliğin değeridir.
- $y_i$, {orange, blue} içinde bir ikili sınıflandırma etiketi değeridir.
Amacımız, $D$ örneklerini $x_i \geq t$ koşuluna göre $T (doğru)$ ve $F(yanlış)$ gruplarına bölmenin etiketlerin ayrılmasını iyileştirecek bir eşik değeri $t$(eşik) bulmaktır. Örneğin, $T$ grubunda daha fazla "turuncu" örnek ve $F$ grubunda daha fazla "mavi" örnek bulunabilir.
Shannon entropisi, düzensizliğin bir ölçüsüdür. İkili etiket için:
- Örneklerdeki etiketler dengeli olduğunda (%50 mavi ve% 50 turuncu) Shannon entropisi maksimumdadır.
- Örneklerdeki etiketler saf olduğunda (%100 mavi veya% 100 turuncu) Shannon entropisi minimum düzeydedir (sıfır değer).

Şekil 8. Üç farklı entropi seviyesi.
Resmi olarak, $T$ ve $F$'deki etiket dağılımları entropilerinin ağırlıklı toplamını azaltan bir koşul bulmak istiyoruz. İlgili puan, $D$'nin entropisi ile {$T$,$F$} entropisi arasındaki fark olan bilgi kazancı'dır. Bu fark bilgi kazancı olarak adlandırılır.
Aşağıdaki şekilde, entropi yüksek ve bilgi kazancı düşük olan kötü bir bölme gösterilmektedir:

Şekil 9. Kötü bir bölme, etiketin entropisi azaltmaz.
Buna karşılık, aşağıdaki şekil entropi değerinin düşük olduğu (ve bilgi kazancının yüksek olduğu) daha iyi bir bölme göstermektedir:

Şekil 10. İyi bir bölme, etiketin entropi değerini azaltır.
Resmi olarak:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
Bu örnekte:
- $IG(D,T,F)$, $D$'nin $T$ ve $F$ olarak bölünmesiyle elde edilen bilgi kazancıdır.
- $H(X)$, $X$ örnek kümesinin entropisidir.
- $|X|$, $X$ kümesindeki öğelerin sayısıdır.
- $t$, eşik değeridir.
- $pos$, pozitif etiket değeridir (ör. yukarıdaki örnekte "mavi"). "Pozitif etiket" olarak farklı bir etiket seçmek, entropi veya bilgi kazancının değerini değiştirmez.
- $R(X)$, $X$ örneklerindeki pozitif etiket değerlerinin oranıdır.
- $D$, veri kümesidir (bu birimde daha önce tanımlandığı gibi).
Aşağıdaki örnekte, tek bir sayısal özellik ($x$) içeren ikili sınıflandırma veri kümesi ele alınmaktadır. Aşağıdaki şekilde, farklı eşik ($t$) değerleri (x ekseni) için aşağıdakiler gösterilmektedir:
- $x$ özelliğinin histogramı.
- Eşik değerine göre $D$, $T$ ve $F$ gruplarındaki "mavi" örneklerin oranı.
- $D$, $T$ ve $F$'deki entropi.
- Bilgi kazancı; yani $D$ ile {$T$,$F$} arasındaki entropi deltasının örnek sayısına göre ağırlıklandırılmış hali.
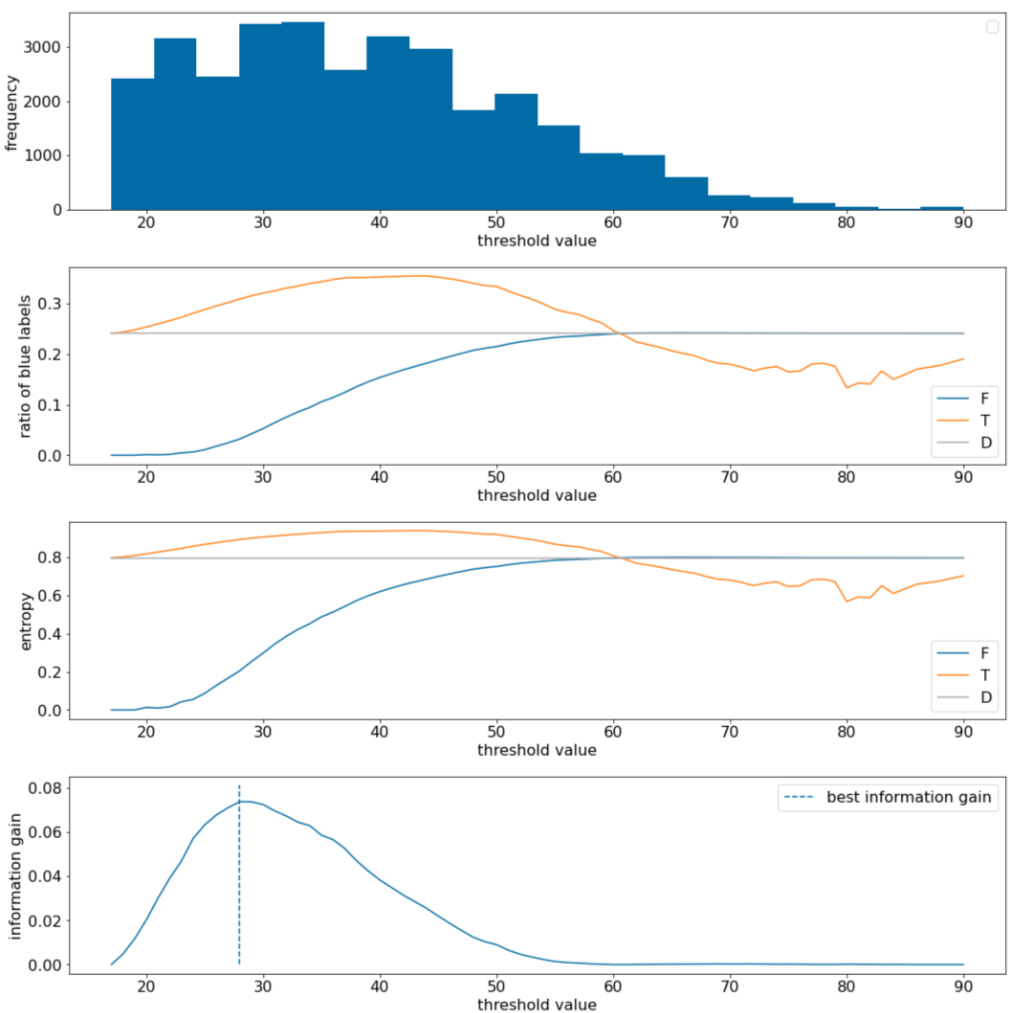
Şekil 11. Dört eşik grafiği.
Bu noktalarda aşağıdakiler gösterilir:
- "Sıklık" grafiği, gözlemlerin 18 ila 60 arasındaki konsantrasyonlarla nispeten iyi dağıldığını gösterir. Değer aralığının geniş olması, çok sayıda olası bölme olduğu anlamına gelir. Bu da modeli eğitmek için iyidir.
Veri kümesindeki "mavi" etiketlerin oranı yaklaşık %25'tir. "Mavi etiket oranı" grafiği, 20 ile 50 arasındaki eşik değerleri için şunları gösterir:
- $T$ kümesi, "mavi" etiket örneklerini aşırı derecede içeriyor (eşik 35 için% 35'e kadar).
- $F$ grubu, "mavi" etiket örnekleri için tamamlayıcı bir açıklık içerir (35 eşiği için yalnızca% 8).
Hem "mavi etiketlerin oranı" hem de "entropi" grafikleri, etiketlerin bu eşik aralığında nispeten iyi ayrılabileceğini gösterir.
Bu gözlem, "bilgi kazancı" grafiğinde onaylanmıştır. Maksimum bilgi kazancının, bilgi kazancı değeri ~0,074 için t ~=28 ile elde edildiğini görüyoruz. Bu nedenle, ayırıcı tarafından döndürülen koşul $x \geq 28$ olur.
Bilgi kazancı her zaman pozitif veya null olur. Eşik değer maksimum / minimum değerine yaklaştıkça sıfıra yakınsamaya başlar. Bu durumlarda, $F$ veya $T$ boş olurken diğeri veri kümesinin tamamını içerir ve $D$'dekiyle eşit bir entropi gösterir. $H(T)$ = $H(F)$ = $H(D)$ olduğunda bilgi kazancı da sıfır olabilir. 60 eşiğinde, hem $T$ hem de $F$ için "mavi" etiketlerin oranları $D$ ile aynıdır ve bilgi kazancı sıfırdır.
Reel sayılar kümesinde ($\mathbb{R}$) $t$ için aday değerler sonsuzdur. Ancak sonlu sayıda örnek verildiğinde, $D$'nin $T$ ve $F$ olarak bölünmesiyle ilgili yalnızca sonlu sayıda seçenek vardır. Bu nedenle, test etmek için yalnızca sonlu sayıda $t$ değeri anlamlıdır.
Klasik yaklaşım, xi değerlerini artan düzende xs(i) olacak şekilde sıralamaktır:
Ardından, $x_i$ değerlerinin art arda sıralanmış değerlerinin ortasındaki her değer için $t$ değerini test edin. Örneğin, belirli bir özelliğin 1.000 kayan nokta değerine sahip olduğunuzu varsayalım. Sıralama işleminden sonra ilk iki değerin 8,5 ve 8,7 olduğunu varsayalım. Bu durumda, test edilecek ilk eşik değeri 8,6 olur.
Resmi olarak, t için aşağıdaki aday değerlerini dikkate alırız:
Bu algoritmanın zaman karmaşıklığı, $\mathcal{O} ( n \log n) $ şeklindedir. Burada $n$, düğümdeki örnek sayısıdır (özellik değerlerinin sıralanması nedeniyle). Bölme algoritması, bir karar ağacına uygulandığında her düğüme ve her özelliğe uygulanır. Her düğümün, üst öğe örneklerinin yaklaşık yarısını aldığını unutmayın. Bu nedenle, ana teoreme göre, bu bölücüyle bir karar ağacı eğitmenin zaman karmaşıklığı şu şekildedir:
Bu örnekte:
- $m$, özellik sayısıdır.
- $n$, eğitim örneklerinin sayısıdır.
Bu algoritmada, özelliklerin değeri değil yalnızca sırası önemlidir. Bu nedenle, bu algoritma özellik değerlerinin ölçeğinden veya dağılımından bağımsız olarak çalışır. Bu nedenle, karar ağacı eğitirken sayısal özellikleri normalleştirmemiz veya ölçeklendirmemiz gerekmez.