このユニットでは、最もシンプルで一般的な分割アルゴリズムについて説明します。このアルゴリズムは、次の設定で $\mathrm{feature}_i \geq t$ という形式の条件を作成します。
- バイナリ分類タスク
- サンプルに欠損値がない
- サンプルの事前計算インデックスなし
数値特徴量と「オレンジ」と「青」のバイナリラベルを持つ $n$ 個のサンプルセットがあるとします。正式には、データセット $D$ を次のように記述します。
ここで
- $x_i$ は、$\mathbb{R}$(実数の集合)の数値特徴量の値です。
- $y_i$ は、{orange, blue} のバイナリ分類ラベル値です。
目標は、$x_i \geq t$ の条件に従ってサンプル $D$ をグループ $T(rue)$ と $F(alse)$ に分割することで、ラベルの分離を改善するようなしきい値 $t$(しきい値)を見つけることです。たとえば、$T$ に「オレンジ色」のサンプルを多くし、$F$ に「青色」のサンプルを多くします。
シャノン エントロピーは、無秩序の尺度です。バイナリラベルの場合:
- サンプルのラベルがバランスが取れている場合(50% が青、50% がオレンジ)、シャノンのエントロピーは最大になります。
- サトス エントロピーは、例のラベルが純粋な場合(100% 青または 100% オレンジ)最小値(値 0)になります。

図 8. 3 つの異なるエントロピー レベル。
正式には、$T$ と $F$ のラベル分布のエントロピーの重み付き合計を減らす条件を見つけます。対応するスコアは情報量の増加で、$D$ のエントロピーと {$T$,$F$} エントロピーの差です。この差は情報量の増加と呼ばれます。
次の図は、エントロピーが高く、情報量が低い不適切な分割を示しています。

図 9. 不適切な分割では、ラベルのエントロピーは低下しません。
一方、次の図は、エントロピーが低く(情報量が大きい)より良い分割を示しています。

図 10. 適切な分割により、ラベルのエントロピーが低下します。
正式には:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
ここで
- $IG(D,T,F)$ は、$D$ を $T$ と $F$ に分割した場合の情報量の増加です。
- $H(X)$ は、サンプルセット $X$ のエントロピーです。
- $|X|$ は、集合 $X$ 内の要素の数です。
- $t$ はしきい値です。
- $pos$ は正のラベル値です。上記の例では「blue」です。別のラベルを「正のラベル」として選択しても、エントロピーの値や情報量の増加は変わりません。
- $R(X)$ は、例 $X$ 内の正のラベル値の比率です。
- $D$ はデータセットです(このユニットで前述のように定義されています)。
次の例では、単一の数値特徴量 $x$ を持つ二値分類データセットについて説明します。次の図は、さまざまなしきい値 $t$ 値(x 軸)を示しています。
- 特徴 $x$ のヒストグラム。
- しきい値に応じて、$D$ セット、$T$ セット、$F$ セット内の「青色」の例の比率。
- $D$、$T$、$F$ のエントロピー。
- 情報量の増加。つまり、$D$ と {$T$,$F$} のエントロピーの差を例数で重み付けしたものです。
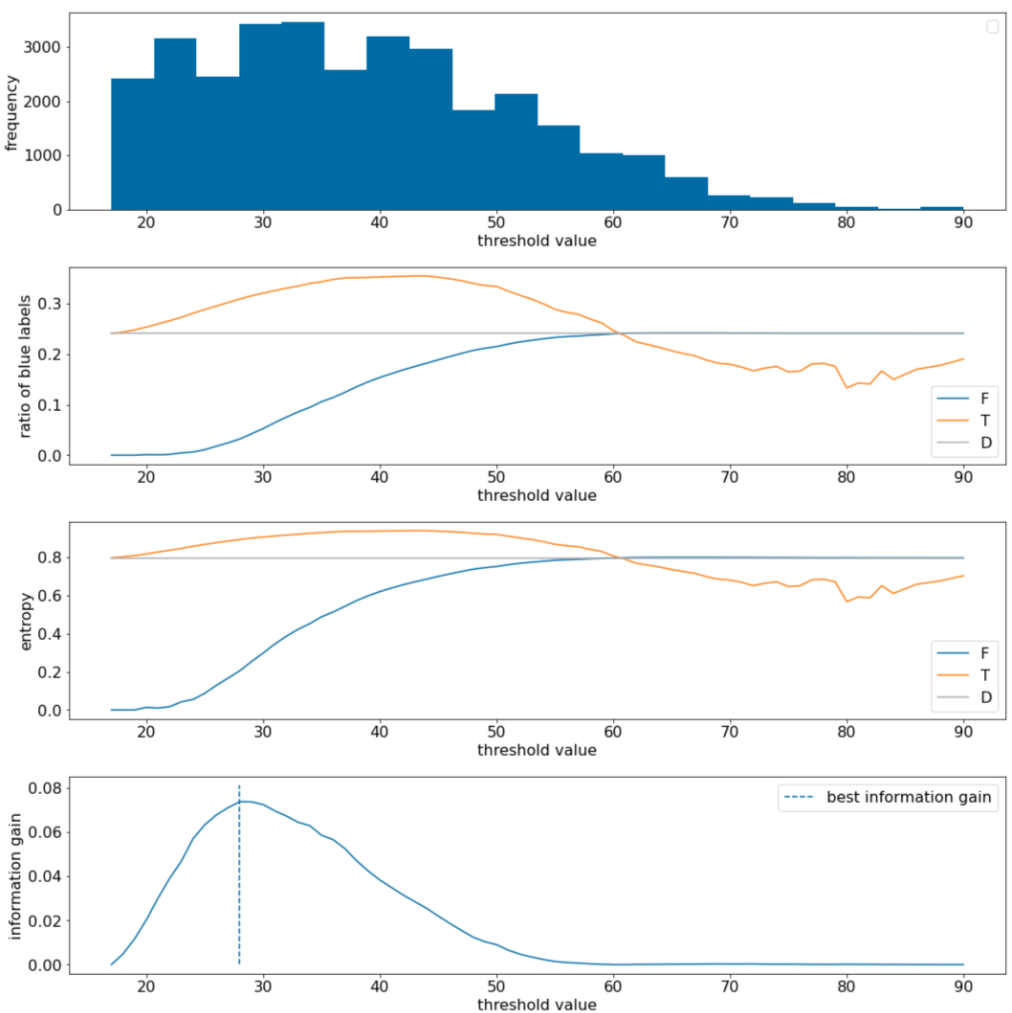
図 11. 4 つのしきい値プロット。
これらのプロットは、次のことを示しています。
- [頻度] プロットは、観測値が 18 ~ 60 の範囲で比較的均等に分布していることを示しています。値の範囲が広いということは、分割の候補が多いことを意味し、モデルのトレーニングに適しています。
データセット内の「青色」ラベルの比率は約 25% です。[青いラベルの比率] プロットは、しきい値が 20 ~ 50 の場合を示しています。
- $T$ セットに「青」ラベルの例が過剰に含まれている(しきい値 35 の場合、最大 35%)。
- $F$ セットには、「青色」ラベルの例が補完的に不足しています(しきい値 35 ではわずか 8%)。
[青色ラベルの比率] プロットと [エントロピー] プロットの両方が、このしきい値の範囲でラベルを比較的明確に分離できることを示しています。
この観察結果は、「情報量の増加」プロットで確認できます。最大の情報量の増加は、t~=28 で得られます。このときの情報量の増加値は約 0.074 です。したがって、分割ツールによって返される条件は $x \geq 28$ になります。
情報量の増加は常に正または null です。しきい値が最大値または最小値に収束するにつれて、ゼロに収束します。このような場合、$F$ または $T$ のいずれかが空になり、もう一方にはデータセット全体が含まれ、$D$ と同じエントロピーを示します。また、$H(T)$ = $H(F)$ = $H(D)$ の場合、情報量の増加はゼロになることもあります。しきい値 60 では、$T$ と $F$ の両方の「青色」ラベルの比率は $D$ と同じになり、情報量の増加はゼロになります。
実数集合($\mathbb{R}$)内の $t$ の候補値は無限です。ただし、有限数の例が与えられた場合、D を T と F に分割する方法は有限個しかありません。したがって、テストに意味があるのは有限個の $t$ の値のみです。
古典的なアプローチでは、値 xi を昇順 xs(i) で並べ替えます。
次に、$x_i$ の連続する並べ替えられた値のちょうど中間の値に対して $t$ をテストします。たとえば、特定の特徴の浮動小数点値が 1,000 個あるとします。ソート後、最初の 2 つの値が 8.5 と 8.7 であるとします。この場合、テストする最初のしきい値は 8.6 です。
正式には、t の候補値は次のとおりです。
このアルゴリズムの計算時間は $\mathcal{O} ( n \log n) $ です。ここで、$n$ はノード内の例の数です(特徴値の並べ替えのため)。分割アルゴリズムは、分類ツリーに適用されるときに、各ノードと各特徴に適用されます。各ノードは親の例の約半分を受け取ります。したがって、マスター定理によると、この分割ツールを使用してディシジョン ツリーをトレーニングする時間の複雑度は次のとおりです。
ここで
- $m$ は特徴の数です。
- $n$ はトレーニング例の数です。
このアルゴリズムでは、特徴の値は重要ではなく、順序のみが重要です。このため、このアルゴリズムは特徴値のスケールや分布に依存せずに動作します。そのため、決定木をトレーニングするときに数値特徴量を正規化またはスケーリングする必要はありません。