在本單元中,您將探索最簡單且最常見的分割演算法,該演算法會在下列設定中建立 $\mathrm{feature}_i \geq t$ 形式的條件:
- 二元分類任務
- 範例中沒有缺少的值
- 不對範例使用預先計算的索引
假設一組 $n$ 個示例,其中包含數值特徵和二元標籤「橘色」和「藍色」。我們正式地將資料集 $D$ 描述如下:
其中:
- $x_i$ 是 $\mathbb{R}$ (實數集) 中的數值特徵值。
- $y_i$ 是 {orange, blue} 中的二元分類標籤值。
我們的目標是找出閾值 $t$ (閾值),以便根據 $x_i \geq t$ 條件將 $D$ 示例分為 $T(rue)$ 和 $F(alse)$ 兩組,進而改善標籤的分離效果,例如 $T$ 中出現更多「橘色」示例,$F$ 中出現更多「藍色」示例。
Shannon 熵是一種混亂程度的衡量標準。二元標籤:
- 當範例中的標籤平衡 (50% 藍色和 50% 橘色) 時,Shannon 熵會達到最高值。
- 當示例中的標籤為純色 (100% 藍色或 100% 橘色) 時,Shannon 熵值會降至最低 (值為零)。

圖 8. 三種不同的熵值等級。
正式來說,我們想找出可降低 $T$ 和 $F$ 中標籤分布熵的加權總和的條件。對應的分數是資訊增益,也就是 $D$ 熵和 {$T$,$F$} 熵之間的差異。這項差異稱為資訊增益。
下圖顯示不良的分割方式,其中熵值仍高,資訊增益則偏低:

圖 9. 不當的分割方式不會降低標籤的熵。
相較之下,下圖顯示更佳的分割方式,其中熵會變低 (資訊增益會變高):

圖 10. 良好的分割方式可降低標籤的熵。
正式:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
其中:
- $IG(D,T,F)$ 是將 $D$ 分割為 $T$ 和 $F$ 的資訊增益。
- $H(X)$ 是示例集 $X$ 的熵。
- $|X|$ 是集合 $X$ 中的元素數量。
- $t$ 是閾值。
- $pos$ 是正值標籤值,例如上例中的「blue」。選取其他標籤做為「正向標籤」不會變更熵或資訊增益的值。
- $R(X)$ 是 $X$ 示例中正面標籤值的比例。
- $D$ 是資料集 (如本單元前述所定義)。
在以下範例中,我們會考慮含有單一數值特徵 $x$ 的二元分類資料集。下圖顯示不同閾值 $t$ 值 (x 軸):
- 特徵 $x$ 的直方圖。
- 根據閾值,在 $D$、$T$ 和 $F$ 集合中「藍色」示例的比例。
- $D$、$T$ 和 $F$ 中的熵。
- 資訊增益,也就是 $D$ 和 {$T$,$F$} 之間的熵差異,經過示例數量加權。
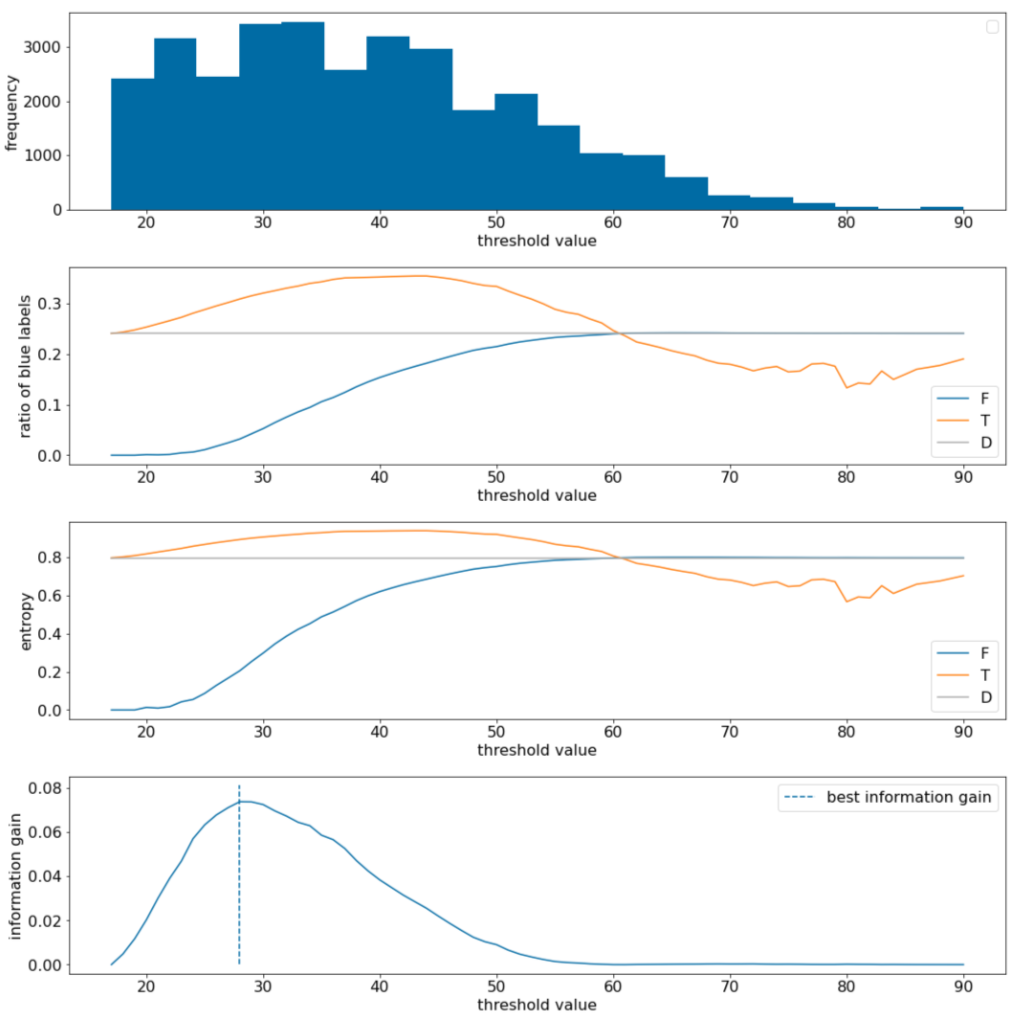
圖 11. 四個門檻圖表。
這些圖表顯示以下內容:
- 「頻率」圖表顯示觀察值分布相對均勻,濃度介於 18 到 60 之間。值分布範圍廣泛表示有許多潛在的分割方式,這對模型訓練有益。
資料集中「藍色」標籤的比例約為 25%。「藍色標籤比率」圖表顯示,如果閾值值介於 20 和 50 之間:
- $T$ 集合包含過多的「藍色」標籤範例 (上限為 35% 的閾值 35)。
- $F$ 集合包含「blue」標籤範例的補充不足 (閾值 35 僅為 8%)。
「藍色標籤比率」和「熵」圖表都顯示,在這個閾值範圍內,標籤可以相對清楚地分開。
這項觀察結果在「資訊增益」圖表中得到證實。我們發現,在資訊增益值約為 0.074 的情況下,t~=28 可獲得最大資訊增益。因此,分割器傳回的條件會是 $x \geq 28$。
資訊增益值一律為正值或空值。當閾值值趨近最大 / 最小值時,這個值會收斂至零。在這些情況下,$F$ 或 $T$ 會變成空白,而另一個變數則包含整個資料集,並顯示與 $D$ 相同的熵。當 $H(T)$ = $H(F)$ = $H(D)$ 時,資訊增益也可能為零。在閾值 60 時,$T$ 和 $F$ 的「藍色」標籤比率與 $D$ 相同,而資訊增益為零。
在實數集合 ($\mathbb{R}$) 中,$t$ 的候選值是無限的。不過,如果有有限的例子,$D$ 分為 $T$ 和 $F$ 的情況也只有有限個。因此,只有有限數量的 $t$ 值才有意義。
傳統做法是依遞增順序排序 xi 值,並以 xs(i) 排序,如下所示:
接著,針對 $x_i$ 連續排序值之間的每個值,測試 $t$。舉例來說,假設您有特定功能的 1,000 個浮點值。假設排序後,前兩個值分別為 8.5 和 8.7。在這種情況下,要測試的第一個閾值值為 8.6。
我們會將 t 的候選值設為以下值:
這個演算法的時間複雜度為 $\mathcal{O} ( n \log n) $,其中 $n$ 是節點中的示例數量 (因為特徵值會排序)。套用至決策樹時,分割器演算法會套用至每個節點和每個特徵。請注意,每個節點都會收到約 1/2 的父項範例。因此,根據主定理,使用此分割器訓練決策樹的時間複雜度為:
其中:
- $m$ 是特徵數量。
- $n$ 是訓練範例數。
在這個演算法中,特徵的值並不重要,只有順序才重要。因此,這個演算法會獨立於特徵值的規模或分布情況運作。因此,在訓練決策樹時,我們不需要將數值特徵正規化或調整規模。