Dalam unit ini, Anda akan mempelajari algoritma pemisah yang paling sederhana dan paling umum, yang membuat kondisi dalam bentuk $\mathrm{feature}_i \geq t$ dalam setelan berikut:
- Tugas klasifikasi biner
- Tanpa nilai yang hilang dalam contoh
- Tanpa indeks yang telah dihitung sebelumnya pada contoh
Asumsikan kumpulan contoh $n$ dengan fitur numerik dan label biner "oranye" dan "biru". Secara formal, mari kita jelaskan set data $D$ sebagai:
dalam hal ini:
- $x_i$ adalah nilai fitur numerik di $\mathbb{R}$ (kumpulan bilangan riil).
- $y_i$ adalah nilai label klasifikasi biner dalam {orange, blue}.
Tujuan kita adalah menemukan nilai nilai minimum $t$ (nilai minimum) sehingga membagi contoh $D$ ke dalam grup $T(rue)$ dan $F(alse)$ sesuai dengan kondisi $x_i \geq t$ akan meningkatkan pemisahan label; misalnya, lebih banyak contoh "oranye" di $T$ dan lebih banyak contoh "biru" di $F$.
Entropy Shannon adalah ukuran ketidakteraturan. Untuk label biner:
- Entropi Shannon berada pada nilai maksimum saat label dalam contoh seimbang (50% biru dan 50% oranye).
- Entropi Shannon berada pada minimum (nilai nol) saat label dalam contoh murni (100% biru atau 100% oranye).

Gambar 8. Tiga tingkat entropi yang berbeda.
Secara formal, kita ingin menemukan kondisi yang mengurangi jumlah berbobot dari entropi distribusi label di $T$ dan $F$. Skor yang sesuai adalah keuntungan informasi, yang adalah perbedaan antara entropi $D$ dan entropi {$T$,$F$}. Perbedaan ini disebut keuntungan informasi.
Gambar berikut menunjukkan pemisahan yang buruk, dengan entropi tetap tinggi dan informasi yang diperoleh rendah:

Gambar 9. Pemisahan yang buruk tidak mengurangi entropi label.
Sebaliknya, gambar berikut menunjukkan pemisahan yang lebih baik dengan entropi menjadi rendah (dan perolehan informasi tinggi):

Gambar 10. Pemisahan yang baik akan mengurangi entropi label.
Secara formal:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
dalam hal ini:
- $IG(D,T,F)$ adalah perolehan informasi dari pemisahan $D$ menjadi $T$ dan $F$.
- $H(X)$ adalah entropi dari kumpulan contoh $X$.
- $|X|$ adalah jumlah elemen dalam set $X$.
- $t$ adalah nilai minimum.
- $pos$ adalah nilai label positif, misalnya, "biru" dalam contoh di atas. Memilih label lain sebagai "label positif" tidak akan mengubah nilai entropi atau perolehan informasi.
- $R(X)$ adalah rasio nilai label positif dalam contoh $X$.
- $D$ adalah set data (seperti yang ditentukan sebelumnya dalam unit ini).
Dalam contoh berikut, kita mempertimbangkan set data klasifikasi biner dengan satu fitur numerik $x$. Gambar berikut menunjukkan untuk berbagai nilai nilai minimum $t$ (sumbu x):
- Histogram fitur $x$.
- Rasio contoh "biru" dalam set $D$, $T$, dan $F$ sesuai dengan nilai nilai minimum.
- Entropi dalam $D$, $T$, dan $F$.
- Keuntungan informasi; yaitu, delta entropi antara $D$ dan {$T$,$F$} yang diberi bobot berdasarkan jumlah contoh.
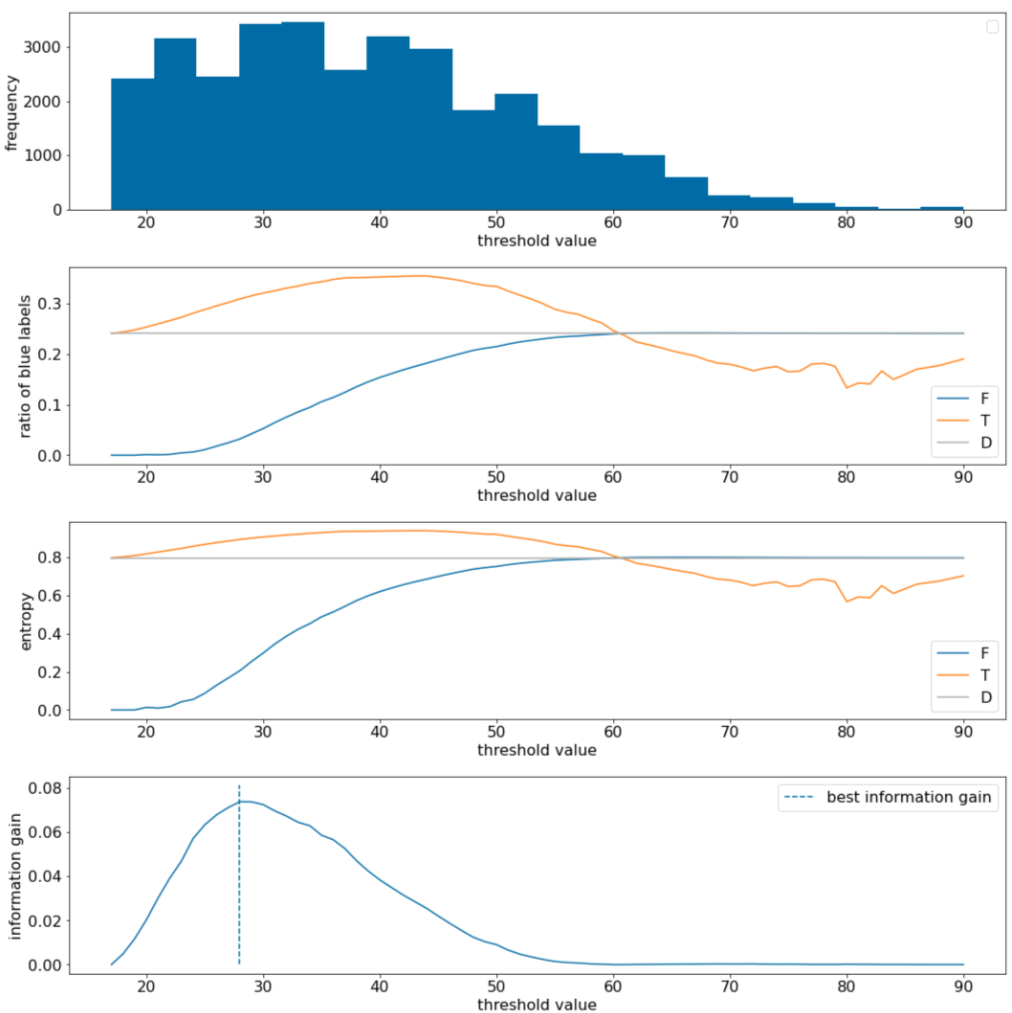
Gambar 11. Empat plot nilai minimum.
Plot ini menunjukkan hal berikut:
- Plot "frekuensi" menunjukkan bahwa pengamatan tersebar relatif baik dengan konsentrasi antara 18 dan 60. Penyebaran nilai yang luas berarti ada banyak potensi pemisahan, yang baik untuk melatih model.
Rasio label "biru" dalam set data adalah ~25%. Plot "rasio label biru" menunjukkan bahwa untuk nilai minimum antara 20 dan 50:
- Set $T$ berisi kelebihan contoh label "biru" (hingga 35% untuk nilai minimum 35).
- Set $F$ berisi defisit pelengkap contoh label "biru" (hanya 8% untuk nilai minimum 35).
Plot "rasio label biru" dan "entropi" menunjukkan bahwa label dapat dipisahkan dengan relatif baik dalam rentang nilai minimum ini.
Pengamatan ini dikonfirmasi dalam plot "informasi gain". Kita melihat bahwa keuntungan informasi maksimum diperoleh dengan t~=28 untuk nilai keuntungan informasi ~0,074. Oleh karena itu, kondisi yang ditampilkan oleh pemisah akan menjadi $x \geq 28$.
Keuntungan informasi selalu positif atau nol. Nilai ini akan konvergen ke nol saat nilai minimum konvergen ke nilai maksimum / minimumnya. Dalam kasus tersebut, $F$ atau $T$ menjadi kosong, sedangkan yang satunya lagi berisi seluruh set data dan menunjukkan entropi yang sama dengan yang ada di $D$. Pengalihan informasi juga dapat nol jika $H(T)$ = $H(F)$ = $H(D)$. Pada nilai minimum 60, rasio label "biru" untuk $T$ dan $F$ sama dengan $D$ dan perolehan informasinya nol.
Nilai kandidat untuk $t$ dalam kumpulan bilangan riil ($\mathbb{R}$) tidak terbatas. Namun, dengan jumlah contoh yang terbatas, hanya ada jumlah pembagian $D$ menjadi $T$ dan $F$ yang terbatas. Oleh karena itu, hanya sejumlah terbatas nilai $t$ yang bermakna untuk diuji.
Pendekatan klasik adalah mengurutkan nilai xi dalam urutan meningkat xs(i) sehingga:
Kemudian, uji $t$ untuk setiap nilai di tengah-tengah antara nilai berurut berturut-turut dari $x_i$. Misalnya, Anda memiliki 1.000 nilai floating point dari fitur tertentu. Setelah pengurutan, misalkan dua nilai pertama adalah 8,5 dan 8,7. Dalam hal ini, nilai nilai minimum pertama yang akan diuji adalah 8,6.
Secara formal, kita mempertimbangkan nilai kandidat berikut untuk t:
Kompleksitas waktu algoritma ini adalah $\mathcal{O} ( n \log n) $ dengan $n$ adalah jumlah contoh dalam node (karena pengurutan nilai fitur). Saat diterapkan pada hierarki keputusan, algoritma pemisah diterapkan ke setiap node dan setiap fitur. Perhatikan bahwa setiap node menerima ~1/2 contoh induknya. Oleh karena itu, menurut teorema utama, kompleksitas waktu pelatihan pohon keputusan dengan pemisah ini adalah:
dalam hal ini:
- $m$ adalah jumlah fitur.
- $n$ adalah jumlah contoh pelatihan.
Dalam algoritma ini, nilai fitur tidak penting; hanya urutan yang penting. Oleh karena itu, algoritma ini berfungsi secara independen dari skala atau distribusi nilai fitur. Itulah sebabnya kita tidak perlu menormalisasi atau menskalakan fitur numerik saat melatih hierarki keputusan.